AI系列:智能音箱技术简析
AI系列:智能音箱技术简析
智能音箱工作原理详解:从唤醒到执行的AIPipeline-CSDN博客
挑战真实场景对话——小爱同学背后关键技术深度解析 - 知乎 (zhihu.com)
AI音箱的原理,小爱同学、天猫精灵、siri。_小爱同学原理-CSDN博客
智能音箱执行步骤解析
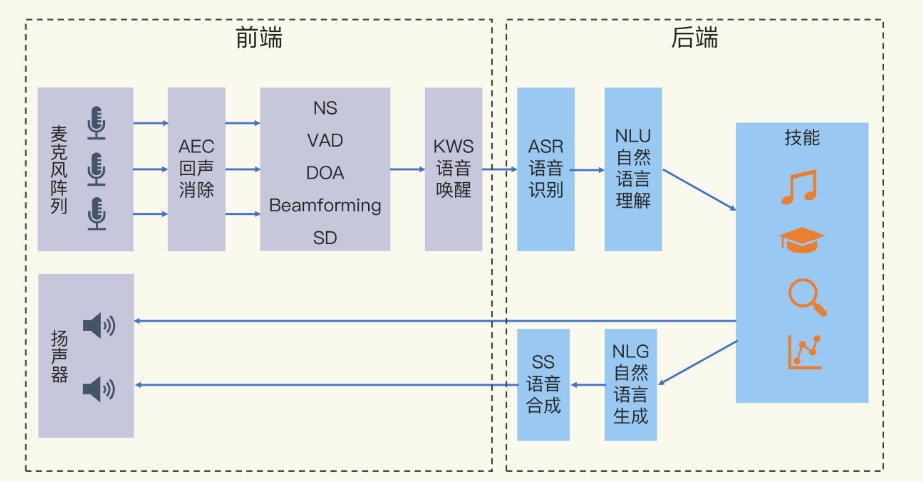
AEC技术详解(Acoustic Echo Cancellation,声学回声消除)
这里的回声主要是指设备本身发出的声音,又被设备自身采集到了。比如,人声询问小爱同学,小爱同学回答之后,小爱把自己的回答又采集去了,这就形成了回声采集,这是一种需要避免的行为。
实时通信(VoIP/视频会议)
如Zoom、腾讯会议等依赖AEC避免回声。
智能音箱/语音助手
消除设备自身播放声音对语音指令的干扰(如天猫精灵、Alexa)。
车载通话系统
解决车内封闭空间的复杂声学回声。
等等。
VAD技术(Voice Activity Detection,语音活动检测)是一种用于识别音频信号中语音段落的技术。它的核心目标是区分语音段(有声部分)和非语音段(无声或噪声部分),广泛应用于语音通信、音频处理、语音识别等领域。以下是关于VAD技术的详细解析:
什么是VAD技术?
VAD技术通过分析音频信号的特征,判断当前信号是否包含语音内容。它的输出通常是二元的:
语音段(Voice):检测到语音活动。
非语音段(Non-voice):未检测到语音活动(如静音、噪声或背景音)。
VAD技术的应用场景
语音通信:在电话或视频会议中,检测语音活动以触发传输或录音,节省带宽和存储资源。
语音识别:在语音识别系统中,去除无声段,减少处理负担并提高识别效率。
音频处理:在录音或直播中,自动分割语音片段,便于后期编辑。
智能设备:如语音助手(如Siri、Alexa),检测用户是否在说话,触发唤醒或响应。
安全监控:在监控系统中,检测异常声音(如呼喊、警报)并触发报警。
VAD技术的实现方法
(1)基于能量的检测
原理:语音信号的能量通常高于背景噪声。通过计算音频信号的短时能量,与预设阈值比较,判断是否为语音段。
优点:简单易实现,适用于信噪比较高的环境。
缺点:对低能量语音或高噪声环境敏感。
(2)基于零交叉率的检测
原理:语音信号的零交叉率(即信号穿过零点的频率)通常高于噪声。通过统计零交叉率,判断是否为语音段。
优点:对低能量语音有一定鲁棒性。
缺点:对某些噪声(如白噪声)可能误判。
(3)基于频谱特征的检测
原理:语音信号和噪声在频谱上有不同的分布特征。通过分析信号的频谱(如MFCC、频谱平坦度),区分语音和噪声。
优点:对复杂噪声环境有较好的鲁棒性。
缺点:计算复杂度较高。
(4)基于机器学习的检测
原理:利用机器学习模型(如SVM、神经网络)学习语音和噪声的特征,实现更精准的检测。
优点:适应复杂环境,准确率高。
缺点:需要大量训练数据,计算复杂度较高。
(5)混合方法
结合多种特征(如能量、零交叉率、频谱特征),提高检测的准确性和鲁棒性。
VAD用于定位语音段,NS用于提升语音质量。
NS技术通常指噪声抑制(Noise Suppression)技术
在声学领域,NS技术通常指噪声抑制(Noise Suppression)技术。它是一种通过算法或硬件手段,减少或消除背景噪声,提升语音或音频信号质量的技术。以下是关于声学中NS技术的详细解析:
什么是噪声抑制(NS)技术?
噪声抑制技术是一种信号处理技术,主要用于从音频信号中分离出有用信号(如语音)和背景噪声,并尽可能降低噪声对有用信号的干扰。它广泛应用于语音通信、音频录制、会议系统等领域。
噪声抑制技术的应用场景
语音通信:如电话、视频会议、VoIP(网络语音通话)等,用于提升语音清晰度。
音频录制:在录音棚或嘈杂环境中,减少背景噪声对录音质量的影响。
智能设备:如智能手机、智能音箱等,用于提高语音识别的准确性。
汽车音响:降低车内噪音,提升通话或音乐播放质量。
医疗领域:如听力检测设备,用于过滤环境噪声。
噪声抑制技术的实现方法
(1)基于硬件的噪声抑制
麦克风阵列:通过多个麦克风采集声音信号,利用信号到达时间差或相位差,抑制来自非目标方向的噪声。
主动降噪耳机:通过发射与噪声相位相反的声波,抵消背景噪声。
(2)基于软件的噪声抑制
谱减法:通过分析音频信号的频谱,减去噪声频谱成分。
维纳滤波:基于统计特性,优化滤波器以最小化噪声影响。
自适应滤波:根据实时环境噪声动态调整滤波参数。
深度学习方法:利用神经网络(如RNN、CNN)学习噪声特征,实现更高效的噪声抑制。
噪声抑制技术的关键技术指标
降噪增益:噪声被抑制的程度,通常以分贝(dB)表示。
语音保真度:在抑制噪声的同时,尽可能保留原始语音的自然性。
延迟:处理音频信号时产生的延迟,需控制在可接受范围内。
鲁棒性:在不同噪声环境(如白噪声、风噪、机械噪声)下的适应能力。
噪声抑制技术的挑战
非平稳噪声:如风噪、机械噪声等,其特性随时间变化,难以完全抑制。
语音与噪声的频谱重叠:当噪声频率与语音频率接近时,可能误伤语音信号。
实时性要求:在语音通信等场景中,需保证低延迟处理。
常见的噪声抑制算法和工具
Speex:开源的语音编码和噪声抑制库。
RNNoise:基于神经网络的实时噪声抑制算法。
WebRTC:谷歌的开源项目,包含噪声抑制模块。
MATLAB/Python:通过信号处理工具箱实现自定义噪声抑制算法。
未来发展趋势
人工智能驱动:利用深度学习模型(如卷积神经网络、循环神经网络)实现更精准的噪声抑制。
多模态融合:结合视觉、环境传感器等信息,提升噪声抑制的鲁棒性。
低复杂度算法:在保证性能的同时,降低算法的计算复杂度,适用于嵌入式设备。
如果你有更具体的应用场景或问题,可以进一步探讨!
DOA技术(Direction of Arrival,到达方向估计)是一种用于确定声源或信号源在空间中方向的技术。它广泛应用于雷达、声呐、无线通信、语音处理、安防监控等领域。以下是关于DOA技术的详细解析:
什么是DOA技术?
DOA技术通过分析信号在多个接收器(如麦克风阵列、天线阵列)上的相位差、时间差或强度差,推断出信号源的方向。其核心目标是确定信号源相对于接收阵列的方位角(Azimuth)和俯仰角(Elevation)。
DOA技术的应用场景
语音处理:在智能音箱、会议系统中,定位说话人的方向,实现声源分离或波束成形。
雷达与声呐:在军事、航海、航空领域,用于目标定位和跟踪。
无线通信:在基站中,通过DOA估计优化信号传输方向,提高通信质量。
安防监控:通过摄像头或麦克风阵列,定位异常声音或运动的方向。
虚拟现实(VR):在AR/VR设备中,通过DOA技术实现3D音效或用户定位。
例如在智能音箱中,VAD检测语音活动,DOA定位说话人方向,NS抑制噪声,最终实现精准的语音交互。
BeamForming技术(波束成形技术)是一种通过调整信号的相位和幅度,使信号在特定方向上增强或抑制的技术。它广泛应用于雷达、声呐、无线通信、语音处理等领域,旨在提高信号的方向性和抗干扰能力。
例如在智能音箱中,VAD检测语音活动,DOA定位说话人方向,BeamForming增强目标声音,NS抑制噪声,最终实现精准的语音交互。
在声学中,SD技术通常指声学信号解码(Speech Decoding)或声学特征提取(Sound Feature Extraction)技术。它的核心目标是从原始声音信号中提取有用的信息(如语音内容、情感、方向等),并将其转化为可分析或可处理的形式。
KWS(Keyword Spotting,关键词唤醒)技术是一种用于检测特定关键词或短语的技术,广泛应用于语音助手(如Siri、Alexa、小爱同学)、智能家居、安防监控等领域。它的核心目标是在持续的音频流中实时检测目标关键词,并触发相应的操作(如唤醒设备、执行指令)。
ASR(Automatic Speech Recognition,自动语音识别)技术是一种将人类语音转换为文本或计算机可理解指令的技术。ASR技术通过分析语音信号的特征(如音调、频率、节奏等),将其转化为文字或指令。其核心目标是让计算机“听懂”人类的语言,并准确输出对应的文本或执行相关操作。
NLP(Natural Language Processing,自然语言处理) 是人工智能的一个重要分支,涉及计算机对人类语言的理解、生成和交互。在NLP领域,NLU(Natural Language Understanding,自然语言理解) 和 NLG(Natural Language Generation,自然语言生成) 是两个核心子任务,分别负责语言的理解和生成。
SS(Speech Synthesis,语音合成)是TTS(Text-to-Speech,文本转语音)的另一种表述,指通过技术手段生成人类语音的过程。它与TTS是同一概念,只是名称不同。
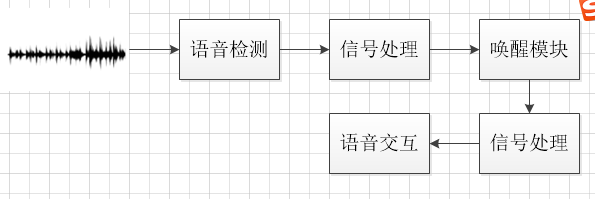
简单的说,音箱工作的时,麦克风阵列始终处于拾音状态(对声音进行采样,量化)。进过基本的信号处理(静音检测、降噪等),唤醒模块会判断是否出现唤醒词,是的话就进行更复杂的语音信号处理,开始真正的语音交互流程。
1.前端信号的处理
1.1语音检测(VAD voice activity detection)
准确的检测音频信号的语音段起始位置,从而分离出语音段和非语音段
1.2降噪
现实环境中存在噪声,通过降低噪声的干扰,降低语音识别难度。
常用的有LMS和维纳滤波。
1.3声学回声消除(AEC)
麦克风收集声音的时候,去除自身播放的声音。否则在播放音乐的时候,人的声音可能被掩盖。
1.4去混响处理
避免声音的反射对音箱的干扰。
1.5声源定位
确定人的位置。
1.6波束形成
降噪去混响的作用
2唤醒
经过语音检测后的信息,只能音箱会在检测到唤醒词之后才开始复杂的信号处理(声源定位等)和后续的交互。
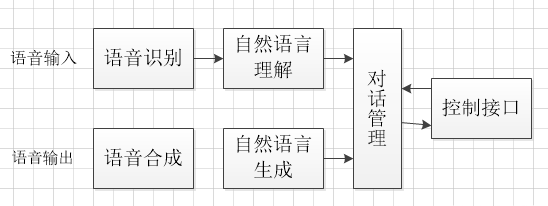
3语音交互
语音输入-语音识别-自然语言的理解-对话管理控制借口-对话管理-自然语言生出-语音合成-语音输出。
3.1语音识别(ASR)
将语音信号转化成文本。
3.2自然语言理解(NLU)
要结合特定的使用场景和现有技术。
领域分类:根据识别命令所属领域,领域是封闭的集合。
意图分类:在相应的领域,识别用户的意图。
实体抽取:确定意图的参数。比如歌手名字和歌曲名称。
3.3对话管理:
对一些追加性的问题的优化。比如明天上海天气怎么样?北京呢?
3.4自然语音的生成(NLG)
采用预先设计的文本模块生成文本输出。
即将为您播放的歌曲是谁的什么歌。
3.5语音合成
TTS使机器能够像人一样朗读给定的文本。
小米的小爱同学AI是开源的吗?
小米的小爱同学AI并不是完全开源的。小爱同学是小米公司自主研发的人工智能助手,其核心技术(如语音识别、自然语言处理、语音合成等)属于小米的知识产权,并未对外公开源代码。
不过,小米在一些技术领域(如智能家居、物联网)提供了部分开源工具和SDK,供开发者使用。以下是相关情况的详细说明:
小爱同学的核心AI技术
语音识别(ASR):小爱同学的语音识别技术基于小米自研的模型,结合第三方技术(如百度、科大讯飞等),但具体实现细节和模型并未开源。
自然语言处理(NLP):小爱同学的语义理解和对话管理能力是小米的核心技术,未对外开源。
语音合成(TTS):小爱同学的语音合成技术也是小米自研的,未开源。
小米的开源资源
尽管小爱同学的核心AI技术未开源,但小米在以下领域提供了开源资源:
MACE(Mobile AI Compute Engine):
小米开源的移动端AI推理框架,支持将深度学习模型部署到移动设备上。
GitHub地址:MACE
MiAI:
小米的人工智能平台,提供了一些AI开发工具和SDK,但核心算法未开源。
IoT平台:
小米的智能家居平台(如MIoT)提供了开源的SDK和开发文档,方便开发者接入小米生态。
小爱同学的开发工具
小米为开发者提供了一些小爱同学相关的开发工具和API,但核心AI技术仍然封闭:
小爱开放平台:
小米为开发者提供了小爱同学的技能开发平台,允许开发者创建自定义技能(如控制智能家居、查询天气等)。
官网:小爱开放平台
小爱同学SDK:
小米提供了一些小爱同学的SDK,供开发者在应用中集成语音交互功能,但核心AI模型未开源。
为什么小爱同学不开源?
商业竞争:AI技术是小米的核心竞争力之一,开源可能会削弱其技术优势。
知识产权保护:小爱同学的语音识别、NLP等技术涉及大量专利和知识产权,开源可能引发侵权风险。
安全性考虑:AI技术涉及用户隐私和数据安全,开源可能增加安全风险。
如何获取类似小爱同学的功能?
如果希望开发类似的语音助手功能,可以使用以下开源或第三方技术:
语音识别(ASR):
Kaldi:开源的语音识别工具包。
DeepSpeech:Mozilla开源的端到端语音识别引擎。
自然语言处理(NLP):
Rasa:开源的对话管理和NLP框架。
Transformers:Hugging Face提供的预训练语言模型库。
语音合成(TTS):
Tacotron 2:Google开源的端到端语音合成模型。
WaveNet:DeepMind开源的高质量语音合成模型。
总结
小爱同学的核心AI技术(如语音识别、NLP、TTS)并未开源,但小米提供了部分开发工具和SDK,方便开发者接入其生态系统。如果需要类似的功能,可以使用开源的AI技术(如Kaldi、Rasa、Tacotron等)进行开发。