AI视觉质检的落地困境与突破路径
摘要
人工智能(AI)视觉质检技术凭借其在提升效率、降低成本和优化质量控制方面的巨大潜力,正成为现代制造业转型升级的关键驱动力。然而,尽管前景广阔,AI视觉质检在实际落地过程中仍面临诸多严峻挑战,主要集中在数据获取与质量、算法模型的泛化能力与精度平衡、系统部署的复杂性与成本效益以及整个产业生态的成熟度等方面。本文旨在深入剖析AI视觉质检在工业界应用的具体困境,并系统梳理当前及未来可行的技术与策略突破路径。克服数据瓶颈(如小样本学习、合成数据生成)、提升算法鲁棒性(如成本敏感学习、持续学习)、优化边缘计算硬件与部署方案、加强行业标准建设与生态协作,是推动AI视觉质检技术从"可用"迈向"好用"并最终实现大规模普及的核心。本文将结合各行业(如电子、汽车、纺织)的实际案例,为企业决策者、技术研发者和行业观察者提供战略性的参考与指引,共同推动AI视觉质检技术赋能制造业高质量发展。
1. AI视觉质检的变革潜力与发展现状
1.1 AI视觉质检的定义:核心技术与固有优势
AI视觉质检,作为人工智能在工业自动化领域的核心应用之一,本质上是利用计算机视觉模拟人类视觉功能,并通过机器学习,特别是深度学习算法,对采集到的图像或视频数据进行分析,以自动识别和判断产品、部件或生产过程中的缺陷、异常或特定特征。其核心系统通常由图像采集单元(工业相机、镜头)、照明系统、图像处理软件以及AI推理模型构成。
核心技术主要包括:
- 机器视觉:作为基础,机器视觉技术使计算机具备"看见"和初步解析图像的能力,包括图像的获取、预处理(如去噪、增强)以及基础特征提取。
- 深度学习与神经网络:这是AI视觉质检区别于传统机器视觉(AOI)的关键。通过构建深度神经网络(尤其是卷积神经网络CNNs),系统能够从大量标注数据中自动学习缺陷的复杂模式和抽象特征,而无需人工设计繁琐的检测规则。这使得AI系统能够像经验丰富的管理人员一样,具备足够的工艺知识,判断操作或产品是否符合标准。
相较于传统的人工目检或自动化光学检测(AOI),AI视觉质检展现出显著的固有优势:
- 提升准确性与一致性:AI系统能够以超越人类的精度检测微小缺陷,并提供客观、可重复的检测结果,有效避免了人工检测因疲劳、主观判断差异等因素导致的漏检和误判。部分先进系统的缺陷检测准确率可超过95%。
- 提高速度与效率:AI视觉质检能够实现24/7全天候不间断运行,并以极高的速度完成检测任务,大幅提升生产线的检测节拍和整体运营效率。
- 降低成本:通过自动化检测,企业可以显著降低对人工检测员的依赖,从而节省大量人力成本。同时,早期、准确的缺陷发现有助于减少废品率、返工率以及因缺陷产品流出市场而产生的保修和召回成本,实现物料和资源的节约。据称,AI视觉质检可带来30-50%的成本降低。
- 数据驱动的洞察与流程优化:AI系统在检测过程中会产生并记录海量的生产数据和图像信息。这些数据不仅用于缺陷追溯,还可以通过进一步分析,为生产管理者提供有价值的洞察,帮助其理解缺陷产生的根本原因,优化生产工艺,甚至实现预测性维护。例如,通过影像追溯发现产品刮伤是由于工人掉落螺丝刀造成的。
- 增强生产安全性:在某些检测环境恶劣或存在安全隐患的场景(如高温、有毒环境),AI视觉质检可以替代人工,保障员工安全。此外,它还可以用于监控工人的安全规范操作,如是否佩戴个人防护设备。
表:AI视觉质检的固有优势总结
| 优势类别 | 描述 | 示例/效益 |
|---|---|---|
| 提升准确性与一致性 | 超越人类精度检测微小缺陷,提供客观、可重复结果,避免人工疲劳和主观差异。 | 缺陷检测准确率可超95% |
| 提高速度与效率 | 24/7不间断高速运行,大幅提升检测节拍和运营效率。 | 显著缩短检测时间 |
| 降低成本 | 减少对人工检测员的依赖,降低人力成本;早期发现缺陷减少废品、返工、保修召回成本。 | 可带来30-50%的成本降低 |
| 数据驱动的洞察 | 产生海量数据用于缺陷追溯、根本原因分析、工艺优化和预测性维护。 | 通过影像追溯发现缺陷成因 |
| 增强生产安全性 | 替代人工在恶劣或危险环境下作业,保障员工安全;监控安全规范操作。 | 例如高温、有毒环境下的检测 |
1.2 当前采纳格局与初步成效
AI视觉质检的市场正在经历显著增长,表明其在各行业的采纳度不断提升。这项技术已广泛应用于电子制造(如PCB、SMT检测)、汽车制造(零部件缺陷、装配质量)、纺织、钢铁、电池生产、医药、食品饮料等多个领域。
初步的应用成效已在多个行业得到验证。例如,富士康(Foxconn)通过引入AI视觉质检,将检测时间缩短了30%,同时准确率提升了80%;通用电气(GE)则利用该技术检测航空发动机等关键部件,使检测时间减少25%,制造成本降低30%。尽管AI工业质检整体尚处于起步阶段,但其在提升产品质量、优化生产管理方面的成功案例,已清晰展示了其巨大的应用价值和广阔的发展前景。
尽管早期成功案例令人鼓舞,它们往往集中在那些数据相对容易获取、缺陷特征较为明确的"低垂果实"型应用场景。这些初步的成功主要体现在替代部分人工检测,识别较为明显的缺陷。然而,AI视觉质检的真正变革性潜力在于解决更复杂、更细微的缺陷检测难题,并从单纯的"缺陷检测"向深层次的"缺陷预防"和"流程优化"拓展。这意味着AI系统不仅要能准确识别已知缺陷,更要能理解缺陷产生的根本原因,为工艺改进提供数据支持,从而实现从被动检测到主动质量控制的转变。这一深层次的整合对数据质量、算法鲁棒性以及系统集成能力都提出了更高的要求,预示着企业在AI视觉质检的道路上,需要从初期的试点成功,逐步规划向更复杂应用场景和更深度流程融合的演进路径。
表:不同行业AI视觉质检应用情况及初步成效
| 行业 | 主要应用场景 | 典型检测对象 | 初步成效案例 | 面临的挑战 |
|---|---|---|---|---|
| 电子制造 | SMT生产线、PCB制造、电池生产 | 元器件焊接(虚焊、少锡、多锡)、PCB缺陷(断路、短路、污渍) | 富士康检测时间缩短30%,准确率提升80% | 元器件微小化、缺陷种类多样 |
| 汽车制造 | 车身焊接、零部件检查、装配线质量控制 | 焊缝、螺栓紧固、零件装配、表面缺陷 | 通用电气检测时间减少25%,制造成本降低30% | 高安全标准、复杂表面光学特性 |
| 医疗器械 | 医疗器械组装、药品包装 | 无菌包装完整性、器械表面缺陷、标签印刷 | 不良品率降低40-60%,监管合规性显著提升 | 严格的法规要求、缺陷标准精确 |
| 纺织工业 | 织物生产、染色、成品检验 | 织物疵点(断线、污渍、颜色偏差) | 检出率比人工提高30%,一等品率提升3-5% | 材质/纹理/花型多样性、高速生产线 |
| 钢铁制造 | 钢板表面质量、卷材检测 | 裂纹、气泡、划痕、凹陷 | 缺陷检出率提高25%,人工检查工作量减少70% | 高温环境、金属表面反光 |
| 食品饮料 | 包装完整性、产品外观 | 封口缺陷、异物混入、标签错误 | 检验速度提升50%,误检率降低15% | 多变的产品外观、高速生产线 |
2. AI视觉质检面临的关键落地困境
尽管AI视觉质检展现出巨大的应用前景,但在实际推广和深化应用的过程中,企业普遍面临一系列严峻的挑战。这些困境涉及数据、技术、部署成本以及组织和生态等多个层面,共同构成了当前AI视觉质检落地的主要障碍。
2.1 数据瓶颈:稀缺性、质量与标注负担
深度学习模型,尤其是驱动AI视觉质检的复杂神经网络,其性能高度依赖于大规模、高质量且经过精确标注的训练数据。然而,在工业视觉质检领域,获取满足这些要求的数据本身就是一个巨大的挑战。
| 瓶颈类型 | 具体表现 | 影响 |
|---|---|---|
| 缺陷数据稀缺 | 生产线合格率高,缺陷样本少且形态多样 | 模型泛化能力弱,对罕见缺陷检测差 |
| 数据质量问题 | 数据孤岛、光照视角变化、图像质量不一致 | 模型学习无关特征,环境适应性差 |
| 标注负担重 | 耗时耗力、需专业知识、易出错 | 增加成本与周期,降低训练数据质量 |
| 共享意愿不足 | 安全与知识产权顾虑,缺乏统一标准 | 行业技术进步缓慢,重复投入 |
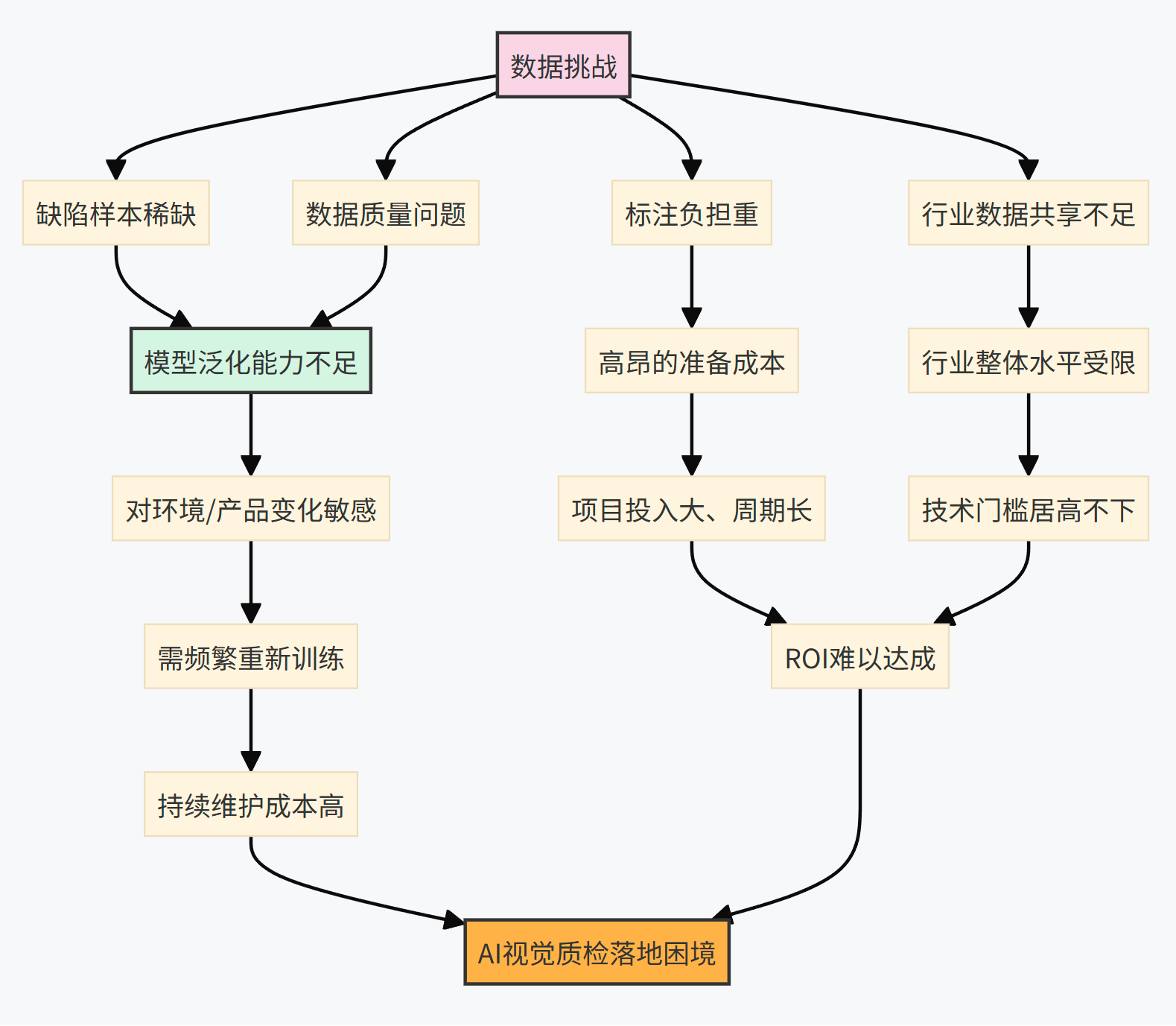
首先,缺陷数据的稀缺性是一个普遍存在的问题。在高效的现代化生产线上,产品合格率通常较高,这意味着缺陷样本本身就是稀有事件。这种"好消息"对于生产效率而言是积极的,但对于AI模型的训练数据收集却是"坏消息"。由于生产过程中的非受控因素,缺陷的形态、尺寸、位置和严重程度往往呈现出极大的多样性,难以收集到覆盖所有可能情况的完整样本集,这极大地限制了深度学习模型的泛化能力和在复杂场景下的应用。
其次,数据质量问题同样突出。企业内部的数据孤岛可能导致数据集不完整或碎片化,使得模型在不同场景下的表现不一致。训练数据中的偏差和不均衡(例如,某些类型的缺陷样本远多于其他类型,或者正常样本远多于缺陷样本)会导致模型产生有偏见的预测,甚至引发伦理问题。更重要的是,如果训练数据未能充分反映真实生产环境中的各种变化,如光照波动、相机角度变化、产品表面材质差异(特别是高反光金属表面)、背景噪声等,模型的泛化能力将大打折扣。图像质量本身,如清晰度、对比度,也会受到采集设备(相机分辨率、镜头质量)和环境因素(如生产线上的粉尘、震动)的影响,直接影响AI学习的效果。
再次,数据标注的成本和工作量是另一个沉重的负担。为AI模型训练准备数据,尤其是进行像素级分割标注(用于精确定位缺陷轮廓),是一项极其耗时、耗力且需要专业领域知识的工作。人工标注不仅成本高昂,还容易引入主观错误和不一致性。据统计,如果数据集中存在10%的错误标注,那么为了达到同等模型精度,需要额外1.88倍的数据量;如果错误标注达到30%,则需要8.4倍的数据量。这无疑加剧了数据获取的难度。一些AI中台(AI Platform)开始提供智能标注工具以减轻标注工作量,但根本性的挑战依然存在。
最后,数据共享的意愿不足也制约了行业整体水平的提升。尽管如阿里等企业和高校已构建了一些面向特定行业(如钢铁、纺织)的公开缺陷数据集,但出于对数据安全、知识产权保护和商业机密的担忧,多数企业对于共享其宝贵的工业数据仍持谨慎态度,这使得构建更大规模、更多样化的行业级共享数据集进展缓慢。
缺陷数据稀缺性与模型泛化能力之间存在着紧密的内在联系。模型是在训练数据中学习规律的,如果缺陷样本本身就稀少且缺乏多样性,模型就无法构建对所有潜在缺陷类型的鲁棒认知。当这样的模型部署到实际生产中,面对训练时未曾见过的新缺陷类型或产品外观、生产环境的细微变化时,其性能就会显著下降,即泛化能力不足。更深一层看,数据瓶颈并非仅仅是模型初次训练时面临的一次性问题,而是贯穿模型整个生命周期的持续挑战。制造业环境是动态变化的:新产品不断推出,生产工艺持续改进,新的缺陷类型也可能随之出现。这就要求AI模型具备持续学习和适应能力。然而,如果新出现的缺陷类型依然是小概率事件,那么数据稀缺的问题就会再次浮现,形成一个"数据持续饥饿"的循环。因此,AI视觉质检的成功实施,不仅需要在项目初期投入大量精力进行数据采集与准备,更需要建立一套长效的数据管理和迭代机制,以支持模型的持续优化和对生产变化的快速响应。这凸显了发展如小样本学习、持续学习以及高效数据生成等技术的重要性。
2.2 技术与算法前沿的挑战
除了数据层面的制约,AI视觉质检在技术和算法层面也面临一系列待突破的瓶颈,主要体现在模型泛化能力、误报与漏报的平衡以及计算资源需求与实时性要求的矛盾。
2.2.1 泛化差距:适应真实世界的易变性
模型泛化能力,即模型在训练集之外的未见过数据上的表现好坏,是衡量AI视觉质检系统实用性的核心指标。然而,工业现场的复杂性和多变性往往导致模型难以从训练环境完美迁移到实际应用场景,形成"泛化差距"。
导致泛化能力不足的因素主要包括:
-
环境因素的多样性:生产车间的光照条件(强度、色温、方向)可能随时间、天气或人工干预而变化;产品在传送带上的位置、姿态也可能存在差异;背景噪声、相机震动等因素都会干扰图像质量。传统基于规则的视觉系统对此尤为敏感。
-
产品本身的可变性:不同批次的产品可能在原材料、表面光洁度(如高反光金属件)、纹理、颜色等方面存在细微差异。即使是同种产品,其几何形状也可能存在公差范围内的波动。
-
缺陷形态的异质性:如前所述,缺陷的表观特征(大小、形状、严重程度、位置)变化万千,难以穷举。
-
过拟合 Overfitting 是导致泛化能力差的一个常见原因。当模型过于复杂或训练数据不足(尤其是缺乏多样性)时,模型可能会学习到训练数据中的噪声和偶然特征,而不是普适性的规律,从而在测试数据上表现不佳。此外,"伪缺陷"的识别也是一大挑战,即模型可能将并非质量问题的正常表面特征(如灰尘、轻微划痕、在合格标准内的微小变异)误判为缺陷,这同样源于训练数据未能充分覆盖所有可接受的正常变异。
仅仅增加数据量并不总能解决泛化问题,特别是当新增数据未能有效覆盖关键的变异维度,或者模型架构本身不具备良好的适应性时。有效的泛化能力提升需要一个多方面策略:首先是战略性的数据采集与生成,重点关注那些能够体现真实世界易变性的数据和边缘案例;其次是采用鲁棒的数据增强技术,模拟各种潜在变化;最后,还需要选择或设计具备良好适应性的模型架构和训练策略,例如迁移学习、领域自适应以及后续将讨论的持续学习等。
2.2.2 精度平衡的钢丝绳:权衡误检(过杀)与漏检(错放)
在AI视觉质检中,系统的准确性并非单一指标,而是需要在两种关键错误类型之间取得平衡:
- 误检(False Positive, FP),也称过杀率:指将合格品错误地判定为不合格品。
- 漏检(False Negative, FN),也称错放率或漏检率:指将不合格品错误地判定为合格品。
这两类错误往往此消彼长。例如,为了尽可能捕获所有缺陷(降低漏检率),系统可能会变得过于敏感,从而将一些合格品也标记为缺陷(提高过杀率)。传统AOI系统就常因过杀率过高而受到诟病。
表:误检(过杀)与漏检(错放)的后果对比
| 错误类型 | 定义 | 主要后果 | 关注点 |
|---|---|---|---|
| 误检 (过杀) | 将合格品判定为不合格品 | 增加生产浪费 (废弃/返工),降低产出效率,可能需额外人工复检。 | 成本、效率 |
| 漏检 (错放/漏检率) | 将不合格品判定为合格品 | 缺陷产品流入市场,引发客户投诉、保修索赔、品牌受损,甚至在关键领域造成安全事故和法律责任。 | 风险、声誉、安全 |
不同类型的错误会带来不同的后果:
- 高过杀率:导致合格品被不必要地废弃或返工,增加生产浪费和成本,降低生产线的整体产出效率,并可能需要额外的人工复检。
- 高漏检率:使得缺陷产品流入市场,可能引发客户投诉、保修索赔、品牌声誉受损,甚至在关键应用领域(如汽车、医疗)造成严重的安全事故和法律责任。
因此,评估AI视觉质检系统性能时,不能仅看总体准确率,更要关注精确率(Precision)、召回率(Recall)和F1分数(F1-score)等能够反映这种平衡的指标。混淆矩阵(Confusion Matrix)是可视化这些权衡的有效工具。不同行业对过杀率和漏检率的容忍度也不同,例如3C行业的目标可能是过杀率10-20%,漏检率1-2%;而其他工业领域可能要求过杀率低于10%,漏检率低于0.5%。联想笔记本装配线的螺丝缺陷检测系统实现了漏检率小于0.2%,过杀率小于3%的优秀表现。UnitX Labs的系统据称能将误检率减半,同时将漏检率降低至人工的十分之一。
如何在这两者之间取得"最佳"平衡,并非纯粹的技术调优问题,而是一个与业务紧密相关的战略决策。不同行业、不同产品、不同缺陷类型及其相关的潜在成本和风险,决定了对这两类错误的容忍度各不相同。例如,汽车或航空航天部件的关键缺陷漏检,其后果远比消费品外观的轻微瑕疵被误检要严重得多。AI模型可以通过调整决策阈值或其他参数来改变其敏感性,从而在精确率和召回率之间进行取舍。但若缺乏对各类错误所对应商业影响(成本、安全、声誉等)的清晰界定,技术团队可能会为了一个通用指标(如F1分数)进行优化,而这个指标未必与企业的核心业务目标完全一致。因此,在模型调优之前,一个至关重要的步骤是跨部门(质量、生产、业务)合作,明确定义不同类型缺陷的误检和漏检所带来的具体成本,形成一份"成本矩阵"或清晰的错误权重。这正是成本敏感学习(Cost-Sensitive Learning)所要解决的核心问题,它将直接指导模型训练和阈值设定的技术策略。
2.2.3 计算需求与实时性要求的矛盾
许多工业视觉质检任务,特别是在高速生产线上的在线检测,对系统的响应速度有着极为苛刻的要求,通常需要在毫秒级别内完成从图像采集到缺陷判断的整个过程,以匹配生产节拍。单个产品的检测周期可能不足一秒。
然而,深度学习模型,尤其是那些为了追求高精度而设计的复杂网络,其训练和推理过程都需要巨大的计算资源(如图形处理器GPU或张量处理器TPU)和相应的能耗。
这就引出了**边缘计算(Edge AI)与云计算(Cloud AI)**的选择问题:
表:边缘计算 vs. 云计算在AI视觉质检中的对比
| 特性 | 边缘计算 (Edge AI) | 云计算 (Cloud AI) |
|---|---|---|
| 部署位置 | 靠近数据源 (生产线旁、设备端) | 远程数据中心 |
| 数据处理 | 本地处理 | 数据上传至云端处理 |
| 主要优势 | 低延迟、实时性高、节省带宽、增强数据隐私 | 强大的计算能力、高可扩展性、集中化管理 |
| 主要劣势 | 计算/存储资源受限、功耗限制 | 延迟较高、依赖网络连接、数据传输带宽和安全顾虑 |
| 典型延迟 | 15-50ms (复杂任务可达200ms内) | 取决于网络和处理,通常不适用于毫秒级实时决策 |
| 适用场景 | 在线实时检测、即时决策、数据敏感场景 | 模型训练、离线分析、对延迟不敏感的批量处理、海量数据存储与计算 |
- 边缘计算:将AI模型的推理部署在靠近数据源(如生产线旁的相机或嵌入式设备)的本地硬件上。其主要优势在于极低的延迟(通常在15-50毫秒,对于复杂任务可能在200毫秒以内),能够满足实时控制的需求,同时减少了数据传输带宽的压力,并增强了数据隐私性。
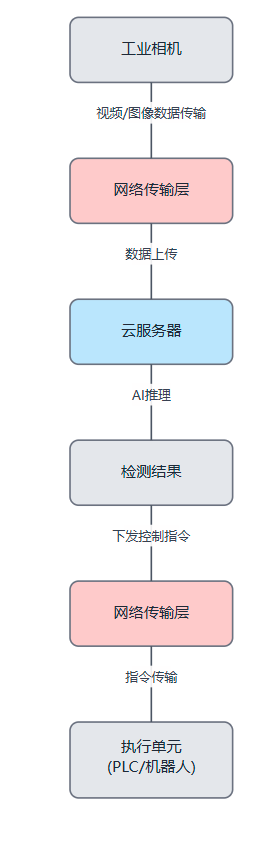
- 云计算:利用远程数据中心强大的计算能力和可扩展性进行模型推理。但数据上传、云端处理再到结果下载的过程会引入不可避免的延迟,使其不适用于大多数需要即时决策的在线检测任务。
尽管边缘计算是实时检测的必然选择,但边缘设备本身在处理能力、内存容量和功耗方面相比云端服务器存在固有的局限性。这要求对部署在边缘的AI模型进行深度优化,如量化(Quantization)、剪枝(Pruning)等,以减小模型体积、降低计算复杂度,并需审慎选择与之匹配的边缘计算硬件。
对于在线检测而言,"边缘优先"已成为共识,这意味着AI模型的开发从一开始就不能脱离其最终将部署的边缘硬件环境。模型的架构设计、尺寸大小、优化策略等,都必须充分考虑到目标边缘设备的具体计算能力和功耗限制。这构成了一个硬件与软件协同设计的挑战。如果一个在云端GPU上训练出来的大型复杂模型,不经过针对性的适配和优化,或者没有选择合适的硬件平台,那么它在边缘设备上很可能无法高效运行,甚至根本无法满足实时性的要求。因此,一个有效的AI视觉质检方案,必须在模型选型/设计阶段就将目标硬件的约束条件纳入考量,这可能涉及到对模型大小、量化方案、剪枝策略的选择,以及利用硬件厂商提供的专用优化工具(如NVIDIA的TensorRT)进行深度优化。
2.3 部署、集成与经济可行性
将AI视觉质检系统成功部署到实际生产环境中,并确保其经济上的可行性,是技术之外的另一大挑战。这包括了复杂的系统集成工作、硬件选型的优化,以及对总体拥有成本(TCO)和投资回报率(ROI)的审慎评估。
2.3.1 攻克系统集成的复杂性
AI视觉质检系统并非孤立存在,它需要与工厂现有的自动化基础设施(如PLC可编程逻辑控制器、SCADA监控与数据采集系统、MES制造执行系统)以及更上层的IT系统(如ERP企业资源规划系统)进行有效集成,才能发挥最大效用。这种集成过程往往充满挑战:
- 接口多样性:现有设备可能采用不同的通信协议和数据格式,需要开发定制化的接口或适配器。
- 数据流协同:确保从相机采集的图像数据能够顺畅、低延迟地流向AI处理单元,并将检测结果及时反馈给控制系统(如触发剔除动作)或数据记录系统,需要周密的网络规划和数据通路设计。
- 软硬件兼容性:不同厂商的硬件组件(相机、光源、计算单元)与软件(操作系统、AI框架、特定供应商的视觉软件)之间可能存在兼容性问题,需要细致的选型和调试。
- 定制化与标准化方案的权衡:市面上的标准化AI视觉质检产品可能部署迅速,但在满足特定工艺需求或与老旧系统集成方面灵活性不足。而完全定制化的解决方案虽然能精准匹配需求,但开发周期长,集成难度大,初期投入也更高。
- 专业技能的缺乏:成功的系统集成往往需要跨领域的专业知识,包括运营技术(OT)、信息技术(IT)以及人工智能,这类复合型人才在市场上相对稀缺。
系统集成的复杂性往往是项目中一个主要的"隐性成本"和风险来源。许多企业在项目初期可能过分关注AI模型的精度,而低估了将该模型无缝融入现有生产环境所需投入的精力与资金。如果集成不当,AI系统可能无法实时获取高质量数据,或者其产生的检测结果无法被及时有效地应用于生产决策,从而沦为一个与生产流程脱节的"自动化孤岛",其价值也将大打折扣。因此,企业在规划AI视觉质检项目时,必须从一开始就为系统集成预留充足的预算和资源,并考虑引入经验丰富的系统集成商。这些集成商通常具备AI和工业自动化的双重经验,能够更好地驾驭集成过程中的技术难题。同时,行业内如OPC UA等标准化通信协议的推广和应用,也有助于降低异构系统间的集成壁垒。
2.3.2 硬件迷局:优化选型与成本控制
AI视觉质检系统的硬件构成主要包括图像采集单元(工业相机、镜头)、照明系统、计算单元(边缘设备、服务器)以及相应的网络设施。每一环节的选型都直接影响系统性能和总体成本。
- 相机选型:关键参数包括分辨率(高分辨率能捕捉更细微特征,但数据量也更大)、帧率(需匹配生产线速度)、传感器类型(CCD与CMOS各有优劣)、接口类型(如GigE Vision、USB3.0)以及对特定缺陷和检测环境的适应性。
- 光源选型:合适的照明是保证图像质量、凸显缺陷特征的核心。常用的照明技术包括明场、暗场、背光、穹顶光、同轴光以及结构光等。LED光源因其稳定性好、寿命长、可控性强等优点而被广泛应用。光源的选择需根据被检物体的表面特性(如高反光、曲面、透明等)和目标缺陷类型来决定。
- 计算单元选型:需要在性能、功耗、成本和尺寸之间进行权衡。常见的选项有:
- 边缘AI模块/开发板:如NVIDIA Jetson系列(Nano, NX, AGX Orin等)、华为Atlas系列(Atlas 200模块, Atlas 500边缘站点等),它们专为端侧AI推理设计,功耗和尺寸相对较小。
- 工业PC (IPC):可配置不同性能的CPU,并可选配GPU加速卡,灵活性较高,但成本和功耗可能也相应增加。
- 服务器:主要用于模型训练,或在对延迟要求不高的场景下进行集中式推理。
硬件成本是AI视觉质检项目中的一项重大前期投入。例如,基础的2D AOI系统可能数千美元起,而先进的3D系统可能高达50万元以上。安装调试费用、系统集成费用也可能非常可观。单个工业相机的价格从几百到数万元不等,光源的价格也因类型和规格而异。边缘计算单元的价格同样区间较大,NVIDIA Jetson Orin Nano开发套件约3000元,而Orin NX系列模块或开发套件价格更高,华为Atlas 200模块和Atlas 500边缘站点的价格也因配置而异。
对于年产量50万件这类具体生产规模,硬件选型的优化尤为重要。首先需要根据生产节拍(例如,50万件/年,若按250个工作日,每天8小时连续生产,则约每14秒处理一件,但实际在线检测速度要求可能远高于此,需按产线速度具体计算每秒需检测的部件数量)来确定相机帧率和AI模型的推理速度要求。然后,根据缺陷的精细程度选择合适的相机分辨率和光源方案。最后,在满足性能的前提下,综合考虑计算单元的成本、功耗和可扩展性。
硬件选型并非简单追求低价或高配,而是一个在当前需求、未来可扩展性与总体拥有成本之间寻求平衡的战略过程。仅仅关注组件的初期采购成本,可能会忽略其在长期运行中对系统性能、可靠性、维护成本及升级潜力的影响。例如,选择价格最低的相机或计算单元,如果其性能或稳定性不足,可能导致检测精度下降、系统频繁故障,反而增加运营成本。反之,过度配置硬件则会造成不必要的初期投资浪费。因此,一个更具战略性的硬件选型方法,应始于对具体检测任务(缺陷类型、检测速度、工作环境等)的详尽分析,仔细评估数据处理需求(模型复杂度、实时性要求),并全面考量总体拥有成本(TCO),包括硬件本身的采购成本、安装调试成本、后期的维护费用、能耗以及潜在的升级路径。在这个过程中,模块化设计和开放式架构的硬件往往能提供更好的长期价值和灵活性。例如,采用可更换镜头或模块化计算单元的系统,未来在升级或调整时可能更为便捷和经济。进行小规模的试点项目,在真实生产环境下验证硬件组合的性能和可靠性,也是降低选型风险的有效手段。
2.3.3 TCO迷思:证明投资合理性与实现ROI最大化
评估AI视觉质检项目的经济可行性,不能仅看初期的采购成本,而应采用总体拥有成本 Total Cost of Ownership, TCO 的视角,并清晰地规划投资回报率(Return on Investment, ROI)的实现路径。
表:AI视觉质检TCO构成要素与评估方式
| TCO构成要素 | 主要项目 | 评估考量点 |
|---|---|---|
| 初期投资 | 硬件采购(相机、镜头、光源、计算单元) 软件许可 开发成本 集成成本 安装调试与培训 | 硬件规格与需求匹配 开源vs商业软件 内部开发vs外包开发 与现有系统兼容性 |
| 运营成本 | 能源消耗 维护与支持 数据存储与管理 人力成本 | 功耗优化 商业支持vs内部支持 数据流量与存储周期 操作人员配置 |
| 升级再训练 | 模型再训练 软硬件升级 | 新产品/缺陷的适应性 硬件寿命与技术迭代速度 |
| 无形效益 | 品质提升 客户满意度 决策优化 工人安全 | 质量改进数据 客户投诉减少 基于AI数据的工艺改进 安全事故减少 |
TCO的主要构成要素包括:
- 初期投资:
- 硬件成本:相机、镜头、光源、计算单元(边缘设备或服务器)、网络设备等。
- 软件成本:操作系统许可、AI开发框架/库的许可(若为商业版)、专用视觉软件或AI平台许可(如Cognex VisionPro等商业软件的许可费用可能在4万元至15万元以上)。
- 开发成本:数据采集与标注、自定义算法开发(若采用开源方案,则主要是人力成本,可能涉及数个"人月"的投入)、模型训练。
- 集成成本:与现有PLC、MES、ERP等生产和管理系统的接口开发与集成,这部分的人力投入也可能达到数个"人月"。
- 安装调试与初始培训成本。
- 运营成本:
- 能源消耗:尤其是高性能计算单元的电力成本。
- 维护成本:硬件的定期维护、维修或更换,软件的更新与补丁,商业软件的年度维护合同或订阅费。对于开源方案,则主要是内部支持人员的维护工作。
- 数据存储与管理成本。
- 人力成本:系统操作、监控及日常管理人员的薪资。
- 升级与再训练成本:
- 模型再训练:当引入新产品、出现新型缺陷或生产环境发生显著变化时,需要对AI模型进行再训练或调整,这涉及到新数据的采集、标注和额外的计算资源。
- 软硬件升级:为保持系统性能或兼容性,可能需要进行软件版本升级或硬件更新换代。
ROI的关键驱动因素包括:
- 可量化的有形收益:
- 降低人工成本:自动化检测替代或辅助人工,减少检测人员数量。
- 减少废品与返工:早期、准确发现缺陷,避免不合格品继续加工或流入下一环节,从而降低材料浪费和返工成本。
- 提高产出率(Throughput):检测速度加快,生产线瓶颈环节可能得到缓解。
- 减少保修与召回成本:防止缺陷产品出厂,降低因质量问题导致的售后成本。
- 提升良品率(Yield):通过快速反馈和数据分析,帮助优化工艺,从源头减少缺陷产生。
- 难以直接量化的无形收益:
- 提升产品质量与一致性:确保出厂产品符合更高标准。
- 增强品牌声誉与客户满意度:高质量产品赢得市场信任。
- 优化生产决策:AI系统产生的数据为工艺改进和管理决策提供依据。
- 改善工人工作环境与安全性:减少人工在重复、枯燥或危险环境下的作业。
ROI论证面临的挑战:
- 高昂的初期投入可能成为,特别是中小型企业(SMEs)采纳AI视觉质检的障碍。
- 无形收益难以精确量化并纳入财务模型。
- ROI的实现可能需要较长时间,投资回收期较长,考验企业的战略耐心。
- 缺乏清晰的绩效基线数据和有效的衡量指标,难以客观证明AI系统带来的改进。
开源方案与商业方案的TCO对比是一个核心议题:
- 开源方案(如OpenCV/PyTorch部署于Jetson/Atlas平台):初期软件成本极低(通常免费),但对企业内部的技术能力要求较高,或者需要依赖系统集成商。开发、集成、定制化以及后续的维护和支持,主要体现为高昂的人力成本和时间成本。
- 商业方案(如Cognex VisionPro, Keyence等):初期软件许可费和专用硬件成本较高,但通常包含专业的技术支持、维护服务、更成熟易用的开发配置工具以及更完善的文档和培训体系。这可能缩短项目周期,降低对内部顶尖AI人才的依赖,从而在某些情况下,尽管初期投入大,但长期TCO可能更优,特别是对于缺乏强大自研能力的企业。
AI视觉质检的TCO构成具有欺骗性的复杂性,仅仅关注软件或硬件的采购价格是远远不够的,这极易导致对项目总成本的低估。企业常常在初期被"免费的"开源软件或某个硬件模块的低价所吸引,却忽略了随之而来的、可能更为庞大的隐性成本,如系统集成、数据管理、模型维护、专业人才的招聘与培养,以及长期的运营和升级开销,这些对于开源解决方案尤为突出。一个全面的TCO分析必须贯穿AI视觉质检系统的整个生命周期,不仅要比较软件许可或硬件的"标价",更要评估实现并持续维持预期检测性能所需的全部资源投入,包括资金、人力和时间。商业闭源解决方案虽然初期投资可能较高,但其提供的集成化工具、专业技术支持和维护服务,有时反而能通过减少内部研发和集成的工作量、缩短项目上线时间,从而在特定条件下实现更低的TCO。相比之下,开源方案若要真正实现成本效益,则需要企业具备强大的内部技术实力,或者与经验丰富的系统集成商建立紧密的合作关系。因此,决策者在选择开源或商业AI视觉质检方案时,应基于一个结构化的TCO框架(如下表1所示的TCO分析框架示例)进行审慎评估,并对企业自身的技术储备与外部支持的依赖程度做出切合实际的判断。最终的ROI计算,也必须建立在这样全面而真实的TCO分析基础之上。
表1: AI视觉质检系统TCO分析框架示例
| 成本类别 | 子类别 | 开源方案 (示例估算) | 商业方案 (示例估算) | 备注 |
|---|---|---|---|---|
| 初期投资成本 | ||||
| 硬件 (相机, 镜头, 光源) | $500 - $5,000+ | $1,000 - $10,000+ | 取决于精度、速度要求 | |
| 计算单元 (边缘设备如Jetson/Atlas, 或IPC+GPU) | $300 - $2,000+ | $1,000 - $5,000+ | ||
| 软件许可 | $0 (核心库免费) | $5,000 - $20,000+ | 商业软件可能包含开发工具、运行时许可 | |
| AI模型开发/获取 | $10,000 - $100,000+ | $5,000 - $50,000+ | 开源需大量定制开发人力;商业方案可能提供预训练模型或简化训练工具 | |
| 数据采集与标注 | $5,000 - $50,000+ | $2,000 - $20,000+ | 标注成本高昂,商业方案可能提供更高效标注工具 | |
| 系统集成 (与PLC/MES等) | $10,000 - $80,000+ | $5,000 - $50,000+ | 开源集成复杂度高,商业方案接口可能更成熟 | |
| 安装调试与初始培训 | $2,000 - $10,000+ | $1,000 - $15,000+ | ||
| 运营成本 (年) | ||||
| 电力消耗 | $100 - $1,000+ | $200 - $1,500+ | 高性能计算单元能耗较高 | |
| 维护与支持 | $5,000 - $30,000+ | $1,000 - $10,000+ | 开源依赖内部或高价第三方支持;商业方案通常含支持合同 | |
| 数据存储与管理 | $500 - $2,000+ | $500 - $2,000+ | ||
| 运维人力 (监控、调整) | $20,000 - $60,000+ | $10,000 - $30,000+ | 开源系统运维可能更复杂 | |
| 升级与再训练成本 (按需) | ||||
| 模型再训练 (新产品/缺陷) | $2,000 - $20,000+ | $1,000 - $10,000+ | 商业方案可能提供更便捷的再训练流程 | |
| 软硬件升级 | 视具体情况而定 | 视具体情况而定 | ||
| 预估TCO (3年) | 加总各项 | 加总各项 | 以上数值仅为示意性估算,实际成本因项目规模和复杂度差异巨大 |
注:上表示例估算基于假设的中等复杂度项目,实际数值会因具体应用场景、精度要求、集成复杂度、人力成本等因素显著变化。开源方案的人力成本(开发、集成、维护)是其TCO的主要组成部分,而商业方案则更侧重于许可和硬件费用。
2.4 组织与生态系统的惯性
AI视觉质检的成功落地不仅取决于技术和经济因素,同样受到组织内部能力、文化以及外部产业生态成熟度的深刻影响。
2.4.1 人的因素:技能鸿沟与变革管理**
- 技能鸿沟:企业普遍缺乏具备AI、机器学习、数据科学以及将这些技术应用于制造环境的复合型人才。这不仅包括算法开发和模型训练,也包括系统的部署、集成、运维和持续优化。
- 变革阻力:员工可能对AI取代其工作岗位产生担忧,或对学习和适应新的、复杂的技术系统感到抵触。获得一线工人和基层管理者的理解与支持,对于AI项目的顺利实施至关重要。例如,在Might Electronics的案例中,公司特意调整摄像头角度以不记录工人面部,并强调AI的引入是为了提升质量而非加强监管,以缓解员工顾虑。
- 培训需求:无论是AI系统的开发者、部署者,还是最终的操作和维护人员,都需要接受针对性的培训,以掌握必要的知识和技能。
- 变革管理:引入AI视觉质检往往伴随着对现有工作流程、岗位职责甚至组织结构的调整。有效的变革管理策略,包括清晰的沟通、员工参与、以及对新流程的持续辅导,是确保变革成功的关键。
即便拥有最顶尖的AI技术,如果企业员工队伍未能做好相应的技能准备,或者对新技术心存疑虑甚至抵制,项目的成功也将大打折扣。克服组织层面的惯性,需要的不仅仅是技术培训,更是一种主动的、以人为本的变革管理方略。这包括向员工清晰、透明地传达引入AI视觉质检的目标和预期影响(例如,AI如何帮助他们减轻重复枯燥的工作、提升工作安全性、或者创造新的高价值岗位),提供针对不同角色的定制化培训方案,并鼓励员工参与到AI系统的设计、验证和优化过程中。将AI定位为增强人类能力的工具,而非简单的替代者,有助于建立人机协作的积极文化,从而显著提升AI项目的接受度和最终成效。
2.4.2 标准化需求与互操作性挑战**
- 标准不统一:目前,全球范围内有多个标准化组织(如ISO, IEEE, NIST)和行业协会(如VDMA)在分别制定与AI及机器视觉相关的标准,但这些标准在范围、侧重点和具体要求上往往存在差异,导致市场缺乏统一的指导框架。
- 互操作性难题:由于缺乏公认的通用标准,不同供应商提供的硬件组件(相机、光源、AI芯片)和软件系统(AI框架、视觉库、控制软件)之间往往难以实现无缝对接和数据交换,这给系统集成带来了巨大挑战,也限制了用户选择最佳组件的灵活性。
- 数据格式与质量标准缺失:行业内尚未形成统一的工业图像数据格式、缺陷标注规范以及数据质量评估标准,这使得跨企业、跨平台的数据共享、模型迁移和性能对比变得非常困难。ISO/IEC 5259系列标准正致力于解决机器学习的数据质量问题。
- 性能评估与基准测试的困境:由于评估方法和指标体系不一,不同AI视觉质检方案的性能报告往往缺乏可比性,用户难以客观判断何种方案最适合自身需求。ISO/IEC TS 4213等标准开始关注机器学习分类性能的评估方法。
- 行业特定指南的探索:一些行业组织,如德国机械设备制造业联合会(VDMA)推出的VDMA 2632系列机器视觉指南,旨在为用户和供应商在项目实施(如术语定义、需求规范制定、系统验收测试)中提供指导,并已开始考虑AI在机器视觉中的应用。OPC UA(开放平台通信统一架构)及其机器视觉配套规范(OPC Machine Vision)也是推动工业自动化领域(包括AI视觉应用)互操作性的重要力量。
- AI对现有标准体系的冲击与重塑:AI技术的融入,特别是深度学习在视觉检测中的广泛应用,对原有的机器视觉标准体系提出了新的要求,促使其必须更新以覆盖AI模型的训练、验证、生命周期管理等特有环节。
当前AI视觉质检领域呈现出一种碎片化的状态,各种专有解决方案林立,缺乏通用的框架和接口,这无疑阻碍了技术的规模化推广和深度应用。随着AI视觉质检系统日益复杂,并深度嵌入到关键的制造流程中,建立和遵循统一的、强有力的行业标准,其意义已从最初的技术层面(如确保不同厂商设备间的兼容性)上升到战略层面。这些标准不仅关乎技术互操作性,更是确保系统安全性、可靠性、数据治理有效性以及满足日益严格的法规要求(如欧盟AI法案)的基石。一个完善的标准化体系将有助于增强市场对AI视觉质检技术的信任度,降低企业采纳新技术的风险,并最终促进整个产业生态的健康发展。因此,无论是技术提供商(为确保其解决方案的竞争力与互操作性)还是最终用户(为降低投资风险、确保系统的可扩展性和可维护性),积极参与并采纳新兴的行业标准都将是至关重要的。这些标准的演进方向,无疑将深刻塑造AI视觉质检的未来图景。
政策法规、行业标准深化与产业链协同的战略意义
除了技术层面的互操作性标准,AI视觉质检的规模化应用和健康发展还日益受到宏观政策、法律法规以及整个产业链生态成熟度的深刻影响。这些因素共同作用,对降低应用门槛、优化成本效益以及推动关键技术突破具有至关重要的战略意义。
-
政策法规的引导与规范:
- 数据隐私与安全:随着欧盟《通用数据保护条例》(GDPR)、中国《个人信息保护法》等法规的实施,工业数据的采集、存储、处理和跨境流动面临更严格的监管。AI视觉质检系统在处理可能涉及工人影像或敏感生产数据时,必须确保合规性,这推动了对边缘计算、联邦学习等隐私保护技术的需求。
- AI伦理与责任:对于AI决策的公平性、透明度和可问责性的要求日益提高。例如,欧盟正在制定的《人工智能法案》(AI Act) 将AI系统根据风险等级进行划分和监管,高风险AI应用(某些工业自动化场景可能涉及)需要满足严格的评估和认证要求。这促使企业在设计和部署AI视觉质检系统时,必须考虑其潜在的社会和伦理影响,并建立相应的风险管理机制。
- 行业激励与支持政策:许多国家和地区出台了支持制造业数字化转型和人工智能应用的产业政策,例如提供研发补贴、税收优惠、建立创新中心等。这些政策能够鼓励企业投入AI视觉质检等新技术的研发和应用,加速技术迭代和产业升级。
- 安全生产与质量标准:特定行业(如汽车、航空、医疗器械)的严格安全和质量法规,也间接推动了对高精度、高可靠性AI视觉质检技术的需求,以替代或增强传统检测手段,确保产品符合法规要求。
-
行业标准的深化与拓展:
- 超越互操作性:未来的行业标准不仅要解决不同厂商设备和软件间的兼容问题,更需要覆盖AI视觉质检的全生命周期。这包括:统一的工业图像数据格式和元数据规范,以方便数据共享和模型训练;标准化的缺陷库和标注指南,以提升数据质量和标注效率;AI模型性能评估基准和测试认证流程,以确保不同解决方案间的可比性和可靠性;以及针对特定工业场景的AI安全和安防标准。
- 性能与可靠性认证:建立权威的第三方认证机制,对AI视觉质检系统的检测精度、鲁棒性、实时性以及在特定工业环境下的长期稳定性进行评估和认证,有助于用户建立信任,降低选择风险。
- 中小企业标准与指南:针对中小企业在技术能力、资金投入和人才储备方面的局限,制定更具操作性的AI视觉质检应用指南和轻量级标准,降低其应用门槛。
-
产业链上下游的协同创新与生态构建:
- 算法提供商与硬件制造商的深度融合:AI算法的优化需要与底层硬件(如AI芯片、传感器)的特性紧密结合。算法公司与硬件厂商加强合作,共同进行软硬件协同设计和优化,能够最大化发挥边缘AI的性能潜力,降低功耗。
- 系统集成商的角色演进:系统集成商不再仅仅是"搭积木",而是需要具备更深的行业知识(Know-How)和AI专业能力,能够为最终用户提供从需求分析、方案设计、数据治理、模型定制、系统集成到后期运维和持续优化的端到端解决方案。他们是连接技术与应用的关键桥梁。
- 最终用户企业的积极参与:制造企业作为AI视觉质检技术的最终用户和受益者,应更积极地参与到技术研发和标准制定过程中,提供真实的工业场景需求、高质量的行业数据以及宝贵的应用反馈。这种深度参与有助于确保技术发展方向与实际应用需求保持一致。
- 开放创新平台的建设:鼓励建立行业级的AI视觉质检开源社区、开放数据集、共享算法库和测试平台,促进知识共享、技术交流和协同创新,降低中小企业的研发成本,加速整个产业的技术进步。
- 产学研合作:加强高校、研究机构与企业之间的合作,共同攻克AI视觉质检领域的基础理论和关键技术难题,培养复合型人才,促进科研成果向实际生产力的转化。
总体而言,积极的政策引导、完善的行业标准体系以及紧密的产业链协同,是AI视觉质检技术从实验室走向工厂、从"可用"迈向"好用"、从"盆景"变为"风景"的关键外部驱动力。这些因素的成熟将有效降低企业的试错成本和应用门槛,提升投资回报的可预期性,并最终推动AI视觉质检技术在更广泛的工业领域实现规模化普及,赋能制造业的整体质量提升和智能化转型。
3. 突破路径探索:创新技术与战略应对
面对AI视觉质检在落地过程中遇到的种种困境,学术界和产业界正积极探索一系列创新技术和战略方法,旨在从数据、算法、部署等多个维度寻求突破,推动AI视觉质检技术向更高效、更可靠、更易用的方向发展。
3.1 以数据为中心的解决方案:从稀缺到丰裕
数据是AI的"燃料",解决数据瓶颈是AI视觉质检成功的首要任务。以下策略旨在缓解数据稀缺、提升数据质量,并降低数据获取成本。
3.1.1 驾驭小数据:小样本、零样本与迁移学习**
针对工业场景中缺陷样本难以大量获取的痛点,小样本学习(Few-Shot Learning, FSL)、零样本学习(Zero-Shot Learning, ZSL)和迁移学习(Transfer Learning)等技术应运而生,它们的核心目标是使模型能够从有限的标注数据中进行有效学习,从而大幅减轻对大规模数据集的依赖。
- 小样本学习(FSL):旨在训练模型使其能够从极少数(例如,少于等于5个样本)新类别或新缺陷类型的示例中快速学习并进行泛化。这对于处理偶发性缺陷,或在产品型号频繁更新、新型缺陷不断出现的动态产线中尤为关键。FSL的方法论通常涉及学习一种通用的相似性度量函数或鲁棒的特征表示,使其能够轻松适应少量样本的新任务。一个新兴且潜力巨大的方向是结合视觉语言模型(Vision-Language Models, VLM)进行上下文学习(In-Context Learning, ICL)。VLM预训练于海量图文数据,具备丰富的跨模态知识。ICL允许在不更新模型参数的情况下,通过向VLM提供少量"输入-输出"示例(如缺陷图片及其文字描述的检测标准)作为提示(prompt),来引导模型执行新的检测任务。这种方法极大地简化了针对每种新产品或新缺陷的重新训练过程,在一项基于MVTec AD数据集的单样本(one-shot)实验中,基于VLM和ICL的模型取得了高达0.804的MCC(马修斯相关系数)和0.950的F1分数。
- 零样本学习(ZSL):更进一步,ZSL致力于让模型能够识别在训练阶段从未见过的缺陷类别。这通常通过利用辅助信息(如缺陷的文本描述、属性定义或与其他已知缺陷的语义关联)来实现,VLM同样在此领域展现出应用潜力。
- 迁移学习:这是一种广泛应用且行之有效的策略。其核心思想是将在大规模通用数据集(如ImageNet)上预训练好的模型(通常是其学到的特征提取层)作为基础,然后在特定工业场景的小规模、有针对性的数据集上进行微调(fine-tuning)。通过利用预训练模型已经掌握的通用视觉特征,可以显著减少对目标任务特定数据的需求量,加速模型收敛,并提升在小数据集上的性能。领域自适应(Domain Adaptation)和领域泛化(Domain Generalization)是与迁移学习相关的技术,旨在解决源域(如实验室数据)和目标域(如工厂实际数据)之间数据分布不一致的问题。
这些"小数据"学习技术,特别是小样本学习,正从学术研究的前沿阵地逐步走向工业应用的实际场景,为实现更敏捷、更经济的AI视觉质检提供了可能。在产品种类繁多、生产批次小、更新换代快,或者某些关键缺陷发生率极低的行业,FSL能够显著降低AI系统部署和维护的门槛。当FSL与强大的预训练基础模型(如VLM)以及ICL等高效学习范式相结合时,AI视觉质检系统有望从过去那种"一次训练,长期部署"的静态模式,转变为一种能够对生产变化做出快速响应的、更具动态性和适应性的智能化品控工具。这意味着企业在引入新产品或发现新型缺陷时,不再需要耗费大量时间与资源去收集海量样本并进行完整的模型再训练,而是可以通过提供少量代表性样本和清晰的检测标准,就能快速"教会"AI系统应对新的检测任务。这无疑将极大提升AI视觉质检系统的灵活性和经济性,加速其在更广泛工业场景中的普及。
3.1.2 合成数据的兴起:利用GANs等技术生成缺陷样本**
面对真实缺陷数据难以获取的挑战,利用人工智能技术生成合成数据(Synthetic Data)已成为一种极具前景的解决方案。其核心目标是创造出足够逼真且多样化的人工缺陷样本,用以扩充有限的真实数据集,从而改善AI模型的训练效果和泛化能力,尤其对于罕见缺陷的检测至关重要。
- 生成对抗网络(GANs):是当前合成数据生成领域最受关注的技术之一。GAN由一个生成器(Generator)和一个判别器(Discriminator)组成。生成器负责凭空创造或在良品图像基础上"绘制"出缺陷,而判别器则努力区分哪些是真实图像,哪些是生成器伪造的图像。通过两者之间的持续"博弈"和迭代优化,生成器最终能学会产生与真实缺陷在视觉上高度相似的合成图像。
- GAN的类型与应用:根据是否需要人工指导,GAN可分为全自动生成(如DCGAN, WGAN,可根据少量真实缺陷图自动生成更多缺陷图)和半自动/条件生成(如CGAN, CVAE, Pix2Pix,可根据用户给定的缺陷类别、形状等条件信息生成特定类型的缺陷)。例如,Neurocle公司的Neuro-T视觉平台就支持用户通过GAN从少量样本生成大量缺陷图像。
- 显著的性能提升:多项研究和案例表明,将GAN生成的合成缺陷数据加入训练集,能够显著提升AI视觉质检模型的准确率。例如,Neurocle通过添加50张GAN生成的电池极耳断连合成图像,将检测模型的准确率从78%提升至99%。另一项研究中,DG-GAN(一种改进的GAN)生成的合成缺陷使YOLOX检测模型在NEU钢材表面缺陷数据集上的准确率提升了6.1%,在自建的绝缘隔板缺陷数据集(IP-def)上提升了高达20.4%。利用GAN生成的图像增强钢材表面缺陷检测的Fast R-CNN和YOLOv3模型,其PmA指标也获得了约3%-5%的提升。
- 其他缺陷生成方法:除了GAN,还存在其他生成缺陷样本的途径,例如:
- 基于物理或统计模型的仿真:如基于高斯过程模型在良品图像上叠加噪声或特定形状图案来模拟缺陷。
- 基于图像编辑和修复的技术:例如DefectFill方法,利用精调的图像修复(inpainting)扩散模型,仅需少量参考缺陷图像就能生成逼真的缺陷,并将其无缝融合到良品图像中。
- 3D建模与渲染:通过构建产品的三维数字模型,在模型上以参数化方式(可控制缺陷的大小、形状、位置、严重程度等)引入各种缺陷,然后在不同的虚拟光照、相机角度等条件下渲染生成大量的二维缺陷图像。这种方法对缺陷的可控性和多样性生成具有独特优势。
尽管合成数据生成技术发展迅速,但也面临一些挑战,例如确保生成数据的足够真实性和多样性,避免模型学到合成数据特有的"人造痕迹"(artifacts)而对真实缺陷泛化能力下降,以及训练复杂生成模型(尤其是GAN和扩散模型)本身所需的计算资源和时间。目前,多数GAN模型仍对初始训练样本的数量和质量有一定要求,且尚不存在一种能够完美适用于所有工业场景和缺陷类型的通用生成算法。
然而,合成数据生成技术正从简单的"数据增广"手段,演变为构建鲁棒AI视觉质检系统的基石。其价值远不止于弥补样本数量的不足。更深层次的意义在于,它赋予了开发者对训练数据前所未有的控制力。通过合成数据,可以针对性地生成那些在现实中极为罕见但一旦发生后果严重的关键缺陷样本,从而确保模型对这些"长尾"场景具备识别能力。可以系统性地探索缺陷在尺寸、严重程度、位置等维度上的各种变异,让模型学习到更全面的缺陷表征。更可以通过领域随机化(Domain Randomization)技术,在生成图像时主动引入光照、视角、纹理、背景等环境因素的广泛变化,从而训练出对这些无关变量不敏感、泛化能力更强的AI模型。此外,合成数据天然带有精确的像素级标注信息(因为缺陷是按预设参数"画"上去的),这极大地节省了传统人工标注所需的高昂成本和漫长时间。因此,对于致力于部署高性能AI视觉质检系统的企业而言,投资于发展或获取先进的合成数据生成能力(无论是自研还是寻求专业服务商合作),将是一项具有高度战略价值的举措。其核心目标应是生成不仅数量充足,而且在真实性、多样性上均能满足模型训练需求,并能有效覆盖关键边缘案例的高质量合成数据集。
案例分析:光纤生产中的小样本缺陷检测增强
以光纤制造为例,生产过程中可能出现一些微小的、偶发的缺陷,如气泡、划痕或涂层不均。这些缺陷样本量少,但对产品质量至关重要。假设某光纤企业(模拟场景,非特指真实企业)在光纤表面缺陷检测中面临此类小样本问题,传统方法难以训练出鲁棒的模型。
运用GAN生成缺陷样本的实践:
该企业可以采用基于GAN的策略来扩充其缺陷数据集。具体步骤可能如下:
- 收集少量真实缺陷样本:即使数量不多,也需要尽可能收集具有代表性的真实缺陷图像(例如,50-100张各类微小缺陷的清晰图像)。
- 选择或设计合适的GAN架构:
- 对于图像生成任务,常用的GAN变体有DCGAN (Deep Convolutional GAN)、WGAN (Wasserstein GAN) 或更先进的StyleGAN等。考虑到工业缺陷的精细特征,可能需要选择能够生成高分辨率、细节丰富的图像的GAN模型。
- 如果希望对生成的缺陷类型、位置或严重程度有所控制,可以采用条件GAN (Conditional GAN, cGAN),将缺陷的类别标签或其他属性作为条件输入到生成器和判别器中。
- 训练GAN模型:
- 生成器学习从随机噪声(或良品图像结合噪声)生成逼真的缺陷图像。
- 判别器学习区分真实缺陷图像和生成器生成的假图像。
- 通过对抗训练,生成器不断提升其伪造能力,判别器不断提升其鉴别能力,最终达到一个平衡,生成器能够产生高质量的合成缺陷。
- 筛选与验证生成的样本:并非所有GAN生成的样本都完美。需要人工或通过额外的质量评估模型筛选出那些视觉上逼真且与真实缺陷特征相似的合成图像。
- 扩充训练集并训练检测模型:将筛选后的高质量合成缺陷图像与原有的少量真实缺陷图像合并,形成一个规模更大、多样性更丰富的训练集。然后,利用这个扩充后的数据集来训练AI视觉质检模型(如YOLO系列、Faster R-CNN或专为表面缺陷设计的CNN架构)。
预期效果与准确率提升:
通过这种方式,即使初始真实缺陷样本很少(例如,仅能使传统模型达到87%的识别准确率),通过GAN扩充数据集后,AI检测模型有望学习到更鲁棒的缺陷特征,减少对特定样本的过拟合,从而显著提升识别准确率。例如,准确率可能提升至95%甚至更高,尤其是在识别那些罕见但已通过GAN生成的缺陷类型时,漏检率有望大幅降低。
PyTorch代码实现思路 (简化版DCGAN示例):
以下为一个简化的DCGAN生成器和判别器的PyTorch实现思路,用于生成模拟的缺陷图像块。实际应用中需要根据具体缺陷特征和图像尺寸进行调整和优化。
import torch
import torch.nn as nn# 定义生成器 (Generator)
class Generator(nn.Module):def __init__(self, nz, ngf, nc): # nz: 潜空间向量维度, ngf: 生成器特征图数量, nc: 输出图像通道数super(Generator, self).__init__()self.main = nn.Sequential(# input is Z, going into a convolutionnn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False),nn.BatchNorm2d(ngf * 8),nn.ReLU(True),# state size. (ngf*8) x 4 x 4nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 4),nn.ReLU(True),# state size. (ngf*4) x 8 x 8nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf * 2),nn.ReLU(True),# state size. (ngf*2) x 16 x 16nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),nn.BatchNorm2d(ngf),nn.ReLU(True),# state size. (ngf) x 32 x 32nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),nn.Tanh()# state size. (nc) x 64 x 64 (假设生成64x64的图像))def forward(self, input):return self.main(input)# 定义判别器 (Discriminator)
class Discriminator(nn.Module):def __init__(self, nc, ndf): # nc: 输入图像通道数, ndf: 判别器特征图数量super(Discriminator, self).__init__()self.main = nn.Sequential(# input is (nc) x 64 x 64nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf) x 32 x 32nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 2),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*2) x 16 x 16nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 4),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*4) x 8 x 8nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),nn.BatchNorm2d(ndf * 8),nn.LeakyReLU(0.2, inplace=True),# state size. (ndf*8) x 4 x 4nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),nn.Sigmoid() # 输出单一标量,表示输入为真实图像的概率)def forward(self, input):return self.main(input)# 训练循环的伪代码思路:
# 1. 初始化生成器G和判别器D
# 2. 定义损失函数 (如Binary Cross Entropy Loss) 和优化器 (如Adam)
# 3. for each epoch:
# 4. for each batch of real_images:
# 5. // 训练判别器D
# 6. D.zero_grad()
# 7. // 用真实图像训练D
# 8. output_real = D(real_images)
# 9. loss_real = criterion(output_real, real_label) # real_label通常为1
# 10. loss_real.backward()
# 11. // 用G生成的假图像训练D
# 12. noise = torch.randn(batch_size, nz, 1, 1) # 生成潜空间噪声
# 13. fake_images = G(noise)
# 14. output_fake = D(fake_images.detach()) # .detach()避免梯度传到G
# 15. loss_fake = criterion(output_fake, fake_label) # fake_label通常为0
# 16. loss_fake.backward()
# 17. loss_D = loss_real + loss_fake
# 18. optimizer_D.step()
# 19.
# 20. // 训练生成器G
# 21. G.zero_grad()
# 22. output_G_fake = D(fake_images) # 此时fake_images的梯度会传给G
# 23. loss_G = criterion(output_G_fake, real_label) # G的目标是让D认为假图像是真图像
# 24. loss_G.backward()
# 25. optimizer_G.step()
#
# 注意:实际的GAN训练需要仔细调整超参数,并可能采用更复杂的损失函数 (如WGAN-GP) 和网络结构以保证训练稳定性和生成图像质量。
# 此外,针对特定工业缺陷,可能需要对GAN进行定制化设计,例如结合注意力机制关注缺陷区域,或者使用分割网络辅助生成像素级精确的缺陷。
3.1.3 智能数据增强与AI中台赋能**
在拥有了一定量的原始数据(无论是真实的还是合成的)之后,如何进一步提升数据利用效率,加速AI模型的开发与迭代,是AI视觉质检落地的又一关键环节。智能化的数据增强手段和集约化的AI平台(常被称为"AI中台")为此提供了有力支持。
- 数据增强(Data Augmentation):这是一种通过对现有训练图像施加各种变换(如旋转、缩放、裁剪、翻转、色彩抖动、亮度/对比度调整、噪声注入等)来人为扩充数据集规模和多样性的技术。其主要目的是帮助模型学习到对这些变换的不变性,减少对特定图像属性的过度依赖,从而防止过拟合,提升模型在真实场景中面对不同光照、角度、遮挡等情况时的鲁棒性和泛化能力。然而,传统的基于简单图像处理的数据增强方法,在模拟复杂缺陷的形状、纹理以及真实物理世界的光影变化方面能力有限,往往只能作为一种基础性的补充手段。更高级的数据增强策略,如结合GAN生成更真实的变换,或利用物理仿真引擎模拟成像过程,正成为新的研究方向。此外,一些技术如"图像特征增强"和"多维度特征提取"也被用于自动筛选和加权训练集中的有效特征信息,以提升检测准确度。
- AI中台(AI Platform / AI Middle Platform):这是一种旨在将企业内分散的AI能力(数据、算法、算力、工具)进行整合、沉淀、共享和复用的平台化基础设施。它通常提供一站式的AI应用开发与管理服务,包括:
- 统一数据管理与智能标注:集成数据湖/数据仓库,提供数据接入、清洗、版本控制等功能。更重要的是,AI中台通常内置高效的数据标注工具,甚至引入"智能标注"(如利用预训练模型辅助标注或主动学习推荐标注样本),以期大幅减轻人工标注的负担,缩短标注周期。
- 算法库与模型训练:提供丰富的预置算法库(涵盖机器学习、深度学习的多种经典和前沿模型),支持可视化建模或低代码/无代码模型训练界面,使得不具备深厚AI编程背景的业务人员也能参与到模型构建中。同时,也为专业算法工程师提供灵活的开发环境和强大的算力支持。
- 模型管理与迭代:实现对已训练模型的版本控制、性能监控、效果可视化以及持续迭代优化。能够兼容多种产品线、多种缺陷类型的检测需求,并支持定制化开发专属算法。
- 快速部署与云边协同:提供标准化的模型部署方案,支持将训练好的模型快速部署到云端或边缘设备上,并具备云边协同管理能力,实现模型和应用的统一分发与更新。
- 能力共享与资产沉淀:通过AI中台,企业可以将成功的AI应用案例、成熟的算法模型、高质量的标注数据集等作为核心AI资产沉淀下来,供不同业务部门复用,从而打破数据和技术壁垒,避免重复投入,降低整体开发成本,加速AI在各类工业场景的智能化落地。
AI中台的出现,标志着企业AI应用正从过去的"作坊式"单点开发,向着"工业化"的规模生产演进。对于AI视觉质检这类需要处理大量图像数据、涉及复杂模型训练与部署、且可能在多个产线或工厂推广的应用而言,AI中台的价值尤为突出。它不仅是工具的集合,更是一种组织和管理AI能力的战略性基础设施。通过集中化管理数据资源、标准化开发流程、推广可复用的AI组件,AI中台能够显著提升AI项目的开发效率和成功率,降低技术门槛,使得企业能够更快、更经济、更大规模地部署AI视觉质检系统,并持续优化其性能。例如,一个AI中台可以帮助企业将质检良率从95%提升至98%,并减少人力成本开支。
3.2 算法的鲁棒性与可信度提升
除了数据层面的优化,算法本身的创新也是推动AI视觉质检突破瓶颈的关键。这包括提升模型对动态环境的适应能力、使AI决策与业务影响更紧密地结合、增强模型的可解释性以便人类理解和信任,以及发展能够持续学习和协同工作的智能系统。
3.2.1 实现真正的泛化:适应动态多变的环境**
如前所述,模型在训练数据上表现良好,但在实际生产环境中由于光照、材质、缺陷形态甚至产品型号的变动而性能下降,是AI视觉质检面临的核心挑战之一。实现真正的泛化,意味着模型需要具备对这些动态变化的鲁棒性。
提升模型鲁棒性的技术路径包括:
- 高级数据增强:超越简单的几何变换,采用能够模拟真实环境变化的增强方法,例如模拟不同光照条件、阴影效果、相机噪声、运动模糊等。
- 领域随机化(Domain Randomization):在训练模型时,故意在非常广泛的视觉参数范围内(如光照强度与方向、物体纹理、相机位姿、背景图案等)随机生成训练样本。通过让模型"见多识广",使其学会关注与任务相关的本质特征,而忽略那些易变的、非本质的视觉因素,从而提升对真实世界变化的适应能力。
- 领域自适应(Domain Adaptation):当源领域(如实验室采集的数据或合成数据)与目标领域(如实际工厂环境的数据)存在明显的数据分布差异时,领域自适应技术试图学习一种变换,使得在源领域训练好的模型能够很好地迁移到目标领域,而无需在目标领域进行大量的重新标注和训练。
- 鲁棒特征学习:设计特定的神经网络架构或损失函数,引导模型学习那些对无关扰动不敏感,但对缺陷特有信息敏感的深层特征表示。
- 集成学习(Ensemble Methods):将多个独立训练(可能基于不同数据子集、不同初始化参数或不同模型架构)的模型的预测结果进行融合。由于不同模型可能在不同方面存在优势或对某些扰动有不同的抵抗力,集成往往能带来比单一模型更稳定和鲁棒的整体性能。
- 持续学习(Continual Learning):这是应对环境和产品持续变化的关键(详见3.2.4)。它使模型能够在不遗忘旧知识的前提下,从新数据中学习新知识,适应新的缺陷类型或产品特征。
过去,当AI模型因环境变化导致性能下降时,主要的应对措施往往是收集新的数据并进行大规模的重新训练。然而,这种"反应式"的维护方式成本高昂且效率低下。当前的趋势是向"主动式"的设计理念转变,即在模型构建之初就充分考虑到未来可能遇到的各种变异,并通过上述技术手段(特别是领域随机化和高级数据增强)来训练出对这些预期内的变化具有先天免疫力的模型。这种主动设计旨在让模型学会从数据中提取真正与缺陷相关的本质特征,而非那些容易受到环境因素干扰的表面特征。由此产生的模型,在面对生产环境中的常规波动时,能够保持更稳定的性能,从而减少频繁重训的需求。当然,对于那些真正意义上的、全新的、未曾预料到的变化(如全新的产品线或前所未见的缺陷类型),则需要结合持续学习机制来确保模型的长期适应性。这种"主动设计鲁棒性 + 持续学习适应性"的结合,是实现AI视觉质检系统在动态环境中长期稳定、高效运行的关键。
3.2.2 成本敏感学习:让AI决策与业务影响对齐**
在工业质检中,不同类型的检测错误(误检与漏检)以及对不同类别缺陷的错误判断,其所带来的经济损失或安全风险往往存在巨大差异。例如,漏检一个可能导致严重安全事故的关键部件缺陷,其代价远高于误检一个仅影响外观的微小瑕疵。然而,标准的机器学习分类器在训练时通常以最小化总体错误率或优化某个通用评估指标(如准确率、F1分数)为目标,并未直接考虑这些差异化的错误成本。
成本敏感学习(Cost-Sensitive Learning):正是为了解决这一问题而提出的。其核心思想是在模型训练或决策过程中显式地引入不同错误的"成本"信息,引导模型做出能够最小化总体预期成本(而非仅仅是错误数量)的决策。
实现成本敏感学习的主要方法包括:
- 定义成本矩阵(Cost Matrix):这是成本敏感学习的基础。成本矩阵是一个表格,它为每一种可能的预测结果(真阳性、真阴性、假阳性、假阴性)分配一个具体的成本值,特别是针对不同缺陷类别之间的混淆进行细化。例如,可以将缺陷划分为关键缺陷(影响安全或核心功能)、主要缺陷(影响性能或重要外观)和次要缺陷(轻微外观问题),并为漏检关键缺陷赋予极高的成本,而误检次要缺陷的成本则相对较低。成本值的设定可以基于领域专家的经验判断、历史数据分析(如返修成本、客户索赔金额、停线损失等),或者根据不同错误对业务目标的相对影响来确定。
- 加权损失函数(Weighted Loss Functions):在模型训练过程中,通过修改损失函数,为那些与高成本错误相关的样本或类别分配更大的权重。例如,在CS-YOLOv5模型中,研究者根据预定义的成本矩阵,通过一种"标签-成本向量选择法"重构了YOLOv5的分类损失函数,使得模型在训练时直接受到不同误分类成本的影响。类似地,动态加权平衡损失(DWB Loss)会根据类别频率和模型对真实类别的预测概率来动态调整样本权重,从而更关注难分的少数类样本。此外,还有一些平衡损失函数致力于同时解决类别不平衡、难易样本不平衡以及边界区域像素点分类模糊等问题。
- 调整决策阈值(Threshold Adjustment):对于输出类别概率的分类器,可以通过调整将概率映射为离散类别标签的决策阈值,来优化系统在特定成本结构下的整体表现,而不是简单地以0.5作为默认阈值。通过在验证集上搜索能够最小化总成本的阈值,可以使模型的最终决策更符合业务需求。
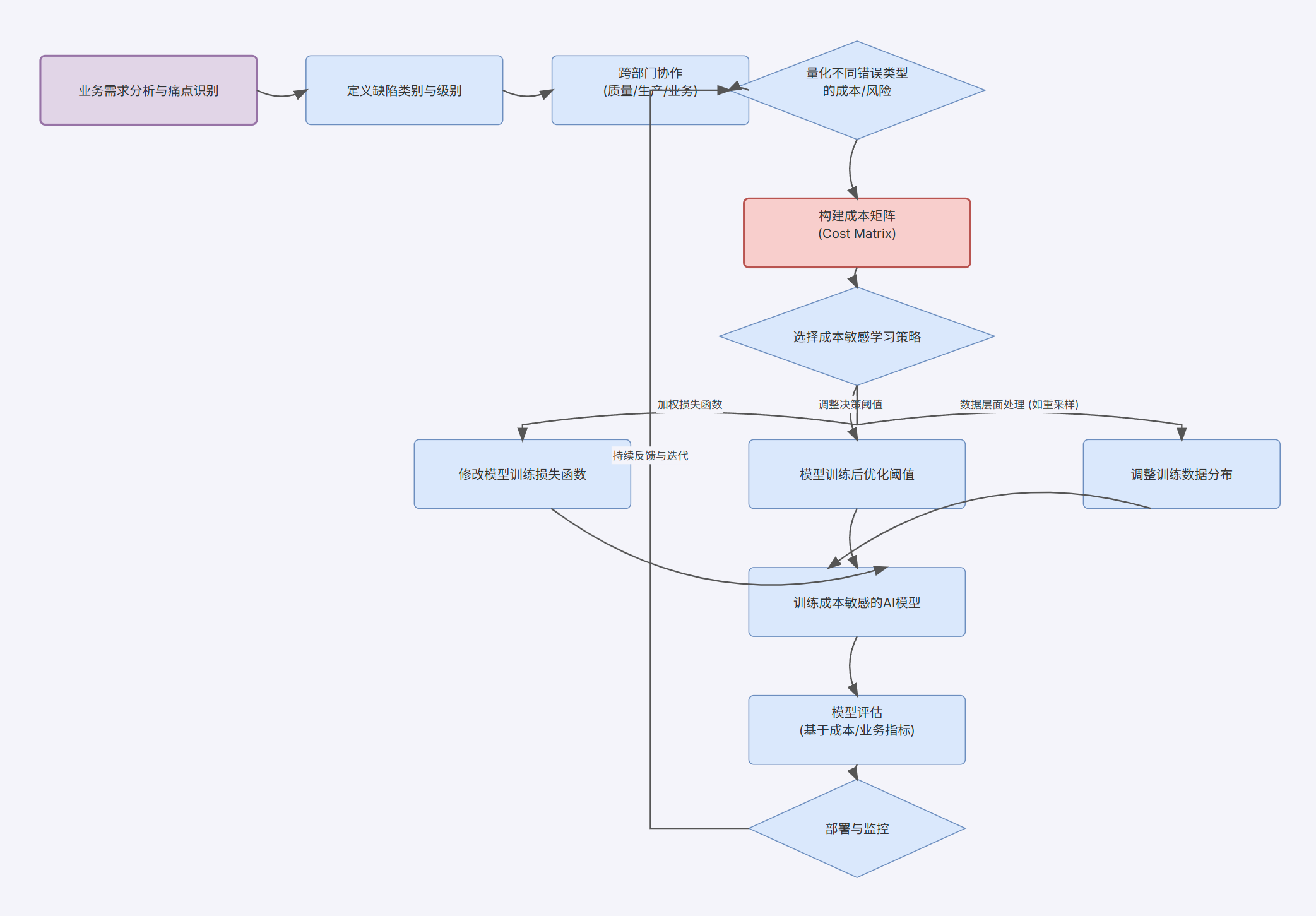
成本敏感学习的引入,使得AI视觉质检系统能够将制造业者对不同缺陷和错误的直观理解(即它们各自的"代价")系统性地融入AI模型的学习和优化过程中。这超越了传统上在模型训练完成后再通过调整阈值等方式进行的事后补救,而是让模型在训练阶段就"学会"优先避免那些代价高昂的错误。例如,如果成本矩阵明确指出漏检"裂纹"缺陷的成本远高于误检"污点"缺陷,那么经过成本敏感训练的模型,在面对一个模糊的、可能是裂纹也可能是污点的图像时,会更倾向于将其判断为"裂纹"(即使这可能增加对污点的误检),因为它"知道"漏掉一个真裂纹的"惩罚"更大。这种机制使得AI的决策逻辑与企业的风险管理和经济效益目标高度统一。成功实施成本敏感学习,需要AI团队与质量工程师、生产管理者等领域专家的紧密合作,共同定义一个能够真实反映业务优先级的成本矩阵。尽管这需要额外的前期投入,但其带来的AI系统决策的经济合理性,将对提升整体质检效益产生深远影响。
3.2.3 解密"黑箱":可解释AI(XAI)在质量控制中的应用**
深度学习模型,尤其是复杂的神经网络,常被喻为"黑箱",因为其内部决策过程高度复杂,难以被人类直观理解。可解释人工智能(Explainable AI, XAI) 技术旨在打开这个"黑箱",提供关于模型为何做出特定预测的洞察。
在AI视觉质检领域,XAI的重要性体现在:
- 建立信任与促进采纳:当操作员和工程师能够理解AI系统做出缺陷判断的依据时,他们更容易信任并接受这项新技术,从而更有效地将其融入日常工作流程。
- 模型调试与性能提升:XAI工具可以帮助开发者分析模型产生错误(如误检或漏检)的原因。例如,通过可视化模型在做决策时关注了图像的哪些区域,可以判断模型是否学到了正确的缺陷特征,还是受到了背景噪声或无关因素的干扰。这为针对性地改进训练数据、调整模型结构或优化训练参数提供了依据。
- 缺陷根本原因分析:XAI不仅解释模型的预测,有时还能揭示与缺陷相关的关键图像特征或生产参数。这些信息对于质量工程师追溯缺陷产生的源头,进而改进生产工艺,具有重要价值。
- 满足合规与审计要求:在某些对安全性、可靠性要求极高的行业(如医疗器械、航空航天),对AI系统的决策过程进行解释和记录,对于满足法规要求和通过审计审查可能至关重要。
常用的XAI技术包括:
- LIME (Local Interpretable Model-agnostic Explanations):通过在单个预测点附近用一个简单的、可解释的模型(如线性模型)来近似复杂模型的局部行为,从而解释该预测为何做出。
- SHAP (SHapley Additive exPlanations):借鉴博弈论中的夏普利值概念,为每个输入特征(如图像中的像素块或超像素)对特定预测的贡献度进行量化打分。
- CAM (Class Activation Mapping) 及其变种(如Grad-CAM):主要用于卷积神经网络,通过生成"类激活热力图"来可视化网络在做出分类决策时,图像的哪些区域对其贡献最大。
尽管XAI技术带来了透明度,但也存在一些挑战,如某些解释方法本身的计算开销较大,可能不适用于实时性要求极高的场景;解释结果的保真度和完整性有时也难以保证;以及如何将复杂的解释信息有效地呈现给不同背景的用户等。
XAI在AI视觉质检中的应用,正从最初满足"透明度"和"建立信任"的需求,发展成为一个贯穿模型开发、部署和优化全生命周期的、不可或缺的诊断、改进和知识发现工具。在实践中,XAI的价值更多地体现在帮助工程师和数据科学家诊断模型为何会做出某种特定的预测(无论是正确的还是错误的)。例如,当模型产生误检时,CAM或Grad-CAM可以清晰地显示出模型是关注了图像中的真实缺陷区域,还是受到了无关背景纹理的干扰。如果后者,则表明训练数据可能存在偏差,或者模型未能学习到足够鲁棒的缺陷特征。同样,LIME或SHAP可以揭示哪些抽象的图像特征对模型的某个具体判断贡献最大。如果这些特征是与缺陷无关的偶然相关性,那么模型就需要进一步优化。通过理解这些模型决策背后的"逻辑",工程师可以更有针对性地去收集和标注那些容易让模型混淆的样本,设计更有效的数据增强策略,调整模型结构,或者改进训练方法。这个过程不仅能提升模型的最终性能和鲁棒性,有时还能帮助人类专家发现一些他们以往可能忽略的、与缺陷相关的细微特征或规律,从而深化对生产过程和缺陷机理的理解。因此,XAI工具不应仅仅被视为模型部署后的一个附加"解释"模块,而应作为一种主动的诊断和探索工具,深度融入到AI视觉质检系统的整个研发与迭代流程中。
3.2.4 持续适应:利用持续学习应对演变的缺陷与产品**
制造环境并非一成不变。新的产品型号会不断推出,现有产品的设计可能发生变更,生产工艺会持续优化,同时,新的、 ранее未曾见过的缺陷类型也可能随着这些变化而出现。如果AI视觉质检模型不能适应这些动态变化,其性能会逐渐衰退,最终变得不再可靠。
持续学习(Continual Learning 或 Lifelong Learning) 旨在赋予AI模型一种能力,使其能够从接踵而至的新数据流中不断学习新知识、适应新任务,同时尽可能不遗忘(或称"灾难性遗忘",Catastrophic Forgetting)已经学到的旧知识。这对于AI视觉质检系统在真实生产环境中保持长期有效性至关重要。
灾难性遗忘是持续学习面临的核心挑战:当一个在任务A上训练好的神经网络接着在任务B上训练时,它可能会完全丧失执行任务A的能力,因为学习任务B的过程中,网络中对任务A重要的权重参数被覆盖或修改了。
主流的持续学习策略包括:
- 基于回放(Replay-based)的方法:在学习新任务时,从过去的任务中抽取一小部分有代表性的样本(或其某种形式的"记忆")与新任务的样本混合在一起进行训练,以"温故知新"。
- 基于正则化(Regularization-based)的方法:在损失函数中加入额外的正则化项,惩罚那些对先前任务重要的网络权重的剧烈改变,从而保护旧知识不被轻易覆盖。
- 基于参数隔离/模型扩展(Architecture-based)的方法:为新任务分配独立的模型参数或动态扩展网络结构(如增加新的神经元、层或模块),使得新知识的学习主要在新增的部分进行,从而减少对旧知识存储区域的干扰。例如,SEMA(Self-Expansion of pre-trained models with Modularized Adaptation)方法就是一种通过按需自动扩展预训练模型并模块化适配来应对持续学习中分布变化的策略。
持续学习的成功应用,可以显著减少在生产环境发生变化(如引入新型号产品、发现新型缺陷)时,对AI模型进行完全从头重新训练的需求,从而节省大量的标注时间、计算资源和人力成本,并使AI系统能够更快地适应变化,保持高效运行。
在制造业中,产品迭代、工艺调整是常态。一个在特定时间点、基于特定数据集训练出来的AI视觉质检模型,如果缺乏适应能力,其性能会随着时间的推移和生产条件的变化而必然下降。传统的应对方式是定期或在性能显著下降后,重新收集大量数据进行模型的全面再训练,这不仅成本高昂,而且会导致质检系统在模型更新期间的"空窗期"或性能不佳期。持续学习技术则为AI系统提供了一种"与时俱进"的进化机制。它使得模型能够像经验丰富的工人一样,在遇到新的产品类型或新的缺陷特征时,不是将过去的经验全部抛弃,而是在原有知识基础上,增量式地学习和吸收新信息,同时努力保留对旧有产品和缺陷的识别能力。这种"活到老,学到老"的能力,是确保AI视觉质检系统长期保持其价值,避免因环境变化而迅速"过时"的关键。因此,企业在选择或开发AI视觉质检解决方案时,应将是否具备持续学习能力或清晰的持续学习技术路线图,作为一项重要的考量因素。这对于保障系统的长期投资回报率和运营效率至关重要。
3.2.5 协同智能:利用联邦学习保护隐私并提升泛化**
在许多大型制造企业中,数据可能分散在不同的工厂、生产线甚至不同的供应商处。每个地点的数据量可能有限,或者只包含特定类型的缺陷信息。如果能将这些分散的数据汇集起来训练一个全局AI模型,无疑能极大提升模型的鲁棒性和泛化能力。然而,数据的直接共享往往受到严格的隐私法规(如GDPR)、商业秘密保护以及数据安全等因素的制约。
联邦学习(Federated Learning, FL) 为这一困境提供了一种创新的解决方案。它是一种分布式的机器学习范式,允许多个参与方(如不同的工厂或设备)在不共享其本地原始数据的前提下,共同训练一个全局共享的AI模型。其基本流程是:
- 中央服务器初始化一个全局模型,并将其分发给各个参与方(客户端)。
- 每个客户端利用其本地数据对收到的模型进行训练,计算出模型参数的更新量(如梯度或权重变化)。
- 客户端将这些模型更新量(而非原始数据)上传给中央服务器。
- 中央服务器对收集到的来自所有(或部分被选中的)客户端的模型更新进行聚合(如加权平均),以更新全局模型。
- 重复步骤1-4,直至全局模型收敛或达到预设的训练轮次。
在AI视觉质检领域的应用价值:
- 数据隐私与安全保护:核心优势在于原始图像数据保留在本地,不离开工厂或企业的数据边界,有效解决了数据共享的合规性和安全性顾虑,使得企业敢于参与到更大范围的数据协作中。
- 提升模型泛化能力:通过聚合来自不同生产环境、不同产品批次、甚至不同地域工厂的"经验"(以模型更新的形式体现),全局模型能够学习到更广泛的缺陷模式和背景变化,从而在面对新的、未曾见过的场景时表现出更好的泛化性。这对于识别罕见缺陷尤其有价值,因为单个工厂可能缺乏足够的样本,但多个工厂的"知识"汇集起来,就可能让模型学会识别这些稀有事件。
- 减少通信开销:相比于传输海量的原始图像数据,仅传输模型参数更新量可以显著降低网络带宽需求和通信成本。
- 应对数据异构性(Non-IID Data):不同工厂的数据在缺陷分布、图像质量、背景环境等方面往往存在显著差异(即非独立同分布)。联邦学习框架及其优化算法(如FLAME,或通过引入互信息正则化)正致力于解决这种数据异构性对全局模型性能带来的负面影响。
联邦学习在制造业的应用场景包括跨工厂的生产过程优化、设备预测性维护以及协同质量控制等。例如,FLAME (Federated Learning with Adaptive Multi-Model Embeddings) 被提出用于无监督的缺陷检测,旨在解决分布式环境下数据稀缺、预训练模型适应性有限以及数据异构的问题。
尽管联邦学习前景广阔,但也面临一些技术挑战,如客户端间的系统和硬件异构性(计算能力、网络状况不一)、通信效率的进一步优化、如何保证联邦过程中的公平性(确保所有参与方都能从全局模型中受益)、以及防范针对联邦学习过程本身的潜在安全攻击(如模型投毒、梯度泄露等)。
联邦学习为破解多工厂或供应链上下游企业间因数据壁垒而难以实现AI模型协同优化的难题,提供了一条切实可行的技术路径。单个工厂的缺陷数据往往是有限的、片面的。通过联邦学习,可以将这些"孤岛"上的数据价值间接地汇聚起来,训练出一个"见多识广"的全局质检模型,而无需牺牲各方的数据主权和商业机密。这种"不出数据出模型(参数)"的协作方式,使得整个制造网络能够从集体智慧中受益,共同提升对各类缺陷的识别能力和对生产波动的适应能力。这对于提升整个产业链的质量水平,建立更具韧性的供应链,具有重要的战略意义。当然,成功实施联邦学习不仅需要解决上述技术挑战,还需要在参与方之间建立信任机制、制定清晰的数据治理和利益共享规则,并构建相应的技术平台来支撑联邦训练流程。
3.3 优化部署:硬件、边缘计算与经济性考量
AI视觉质检系统的成功部署,不仅依赖于先进的算法和充足的数据,还需要在硬件选型、边缘计算策略以及总体经济效益方面进行精心规划和优化。
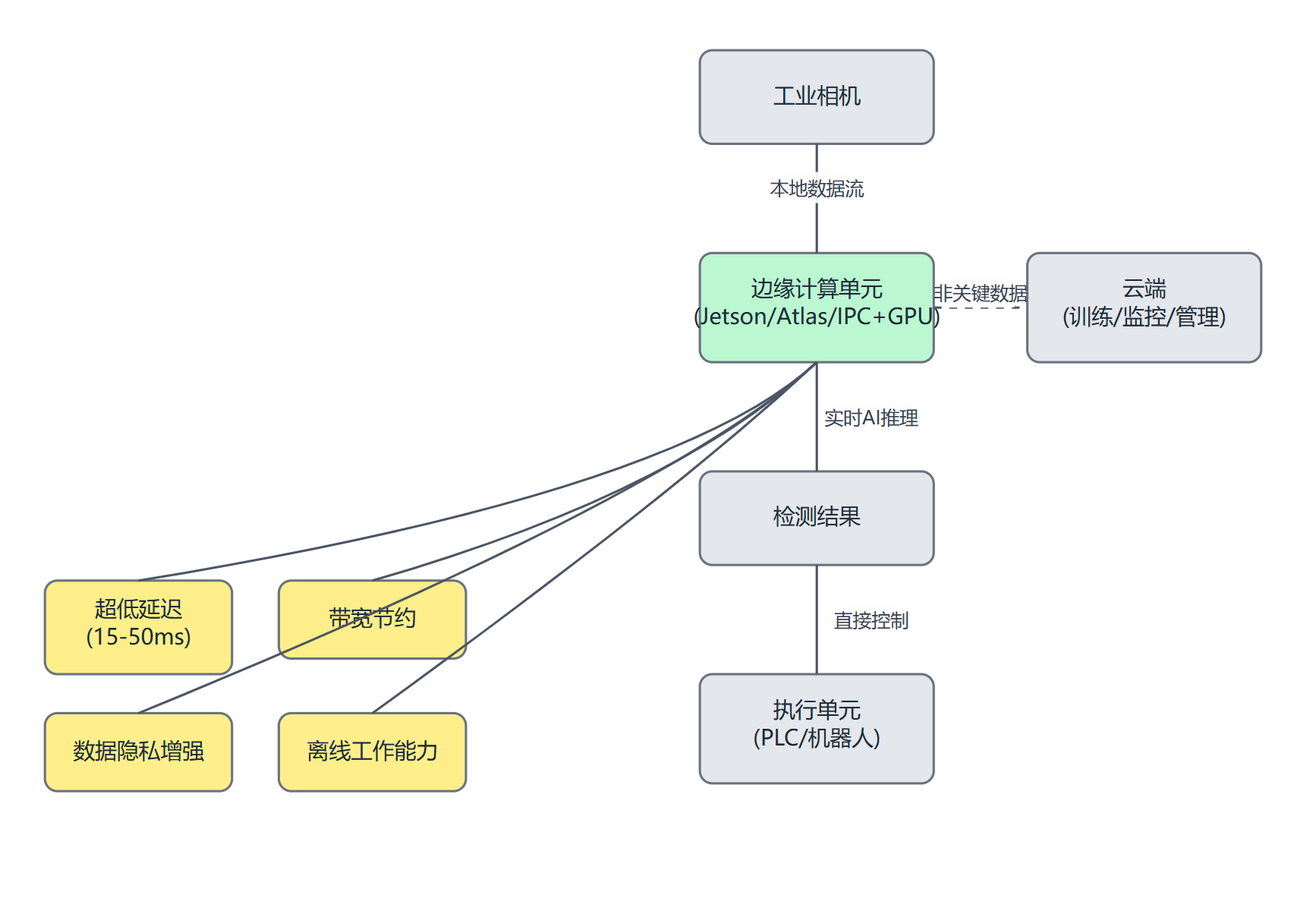
3.3.1 边缘计算的优势:利用NVIDIA Jetson、华为Atlas及工业PC实现实时处理**
边缘计算方案
云计算方案
对于大多数生产线上的AI视觉质检任务,尤其是那些需要与高速产线同步、在毫秒级时间内做出判断的应用,**边缘计算(Edge AI)**已成为必然选择,而非可选项。其核心优势在于能够将AI模型的推理过程直接部署在靠近数据源(如生产线旁的相机)的本地硬件上,从而实现:
- 超低延迟:数据无需远传至云端处理,大大缩短了从图像采集到获得检测结果的时间。典型的边缘AI推理延迟可以控制在15-50毫秒,对于更复杂的模型或任务,目标也通常在200毫秒以内,完全能够满足大多数工业实时控制的需求。
- 带宽节约:大量的原始图像或视频数据在本地处理,仅将必要的检测结果或少量异常数据上传,极大地减轻了工厂网络的带宽压力和数据传输成本。
- 数据隐私与安全增强:敏感的生产数据保留在企业内部,不离开物理边界,降低了数据泄露和被攻击的风险,更易于满足数据合规性要求。
- 离线运行能力:即使在网络连接不稳定或中断的情况下,边缘AI系统仍能独立完成检测任务,保证了生产的连续性。
当前市场上主流的边缘AI计算平台主要包括:
- NVIDIA Jetson系列:这是一系列广受欢迎的嵌入式AI计算模块(System-on-Modules, SoMs),专为边缘AI和机器人应用设计,提供了从入门级到高性能的多种选择。
- Jetson Orin家族(Nano, NX, AGX):作为最新一代产品,Orin系列在AI算力(如Orin Nano最高可达67 TOPS,Orin NX可达157 TOPS,AGX Orin可达275 TOPS)、能效比和接口丰富性方面均有显著提升,并支持灵活的功耗配置以适应不同场景。
- 完善的软件生态:NVIDIA为其Jetson平台提供了强大的JetPack SDK,包含CUDA(并行计算架构)、TensorRT(用于模型推理优化和加速)、DeepStream SDK(用于构建智能视频分析流应用)等一系列开发工具和库,极大地便利了AI应用的开发和部署。
- 广泛的社区与硬件支持:Jetson拥有庞大的开发者社区和丰富的第三方硬件生态,包括各种载板、相机模组、外设等(例如研华等厂商提供的工业级边缘计算设备)。
- 性能参考:在Jetson Orin NX 16GB上运行YOLOv8s模型的推理时间约7.94毫秒;在Jetson Xavier NX上运行YOLOv5s(640x640输入)的推理时间,FP32精度下约33毫秒,INT8量化后约16.7毫秒;在更早的Jetson Nano上结合TensorRT运行YOLOv5n,推理时间约37毫秒(约27 FPS)。最新的Jetson Orin Nano在运行YOLOv11等模型时,其性能甚至可以媲美未开启超级模式的Orin NX 16GB。Mobileye EyeQ6H与Jetson AGX Orin的对比测试显示,在ResNet-50图像分类任务上,Orin(MaxQ模式)单流延迟为1.64毫秒,(MAXN无约束模式)为0.64毫秒。
- 华为Atlas/昇腾(Ascend)系列:这是华为面向端、边、云全场景的AI计算解决方案,基于其自研的昇腾AI处理器和CANN(异构计算架构神经网络)软件栈。
- Atlas边缘智能产品:
- Atlas 200 AI加速模块(型号3000):集成了昇腾310 AI处理器,可提供高达22 TOPS的INT8算力(不同资料显示8 TOPS 或16 TOPS),功耗极低(典型功耗5.5W-8W)。支持多达16路1080p30的H.264/H.265视频硬件解码,适用于智能摄像头、无人机等边缘设备。该模块常被集成于Atlas 500系列边缘站点中。基于Atlas 200I DK A2(开发者套件)的YOLOv8缺陷检测速度可达83 FPS(约12毫秒/帧)。
- Atlas 500 AI边缘小站(型号3000):通常内置Atlas 200 AI加速模块,提供约16 TOPS的INT8算力。能够处理16至20路高清视频流(1080p 25/30 FPS)。具备强大的环境适应性(如无风扇设计,支持-40°C至+70°C宽温工作),并支持云边协同管理。
- Atlas 500 Pro AI边缘服务器(型号3000):性能更强,可支持多达4块Atlas 300I推理卡,搭载鲲鹏920处理器,能够处理高达320路高清视频分析(1080p 25 FPS)。Atlas 300I推理卡单卡功耗约67W。
- 软件与生态:华为提供MindSpore(全场景AI框架)、MindStudio(一站式开发工具链)、以及支持ONNX等开放模型的CANN执行提供程序,并积极构建其昇腾AI产业生态。
- Atlas边缘智能产品:
- 工业PC(IPC)+ GPU方案:对于需要更高计算性能或特定接口需求的场景,采用坚固型工业PC搭载NVIDIA等厂商的专业级或消费级GPU(如RTX A2000)也是一种常见的边缘计算部署方式。这类方案通常具有更好的扩展性和环境耐受性(如宽温、抗震动),但成本和功耗也相对较高。
选择合适的边缘计算平台,需要综合考量AI模型的计算复杂度、实时性要求(如每秒需处理的图像帧数或部件数量)、功耗预算、物理空间限制、环境条件以及总体拥有成本。NVIDIA Jetson平台以其强大的GPU性能、成熟的软件生态和广泛的开发者社区,在机器人和复杂视觉任务中占据优势。华为Atlas系列则凭借其自研昇腾处理器的能效比和针对特定应用场景(如多路视频分析)的优化,以及在中国市场的本土化优势,构成了有力的竞争。而基于IPC的方案则提供了更高的灵活性和可定制性。无论选择何种平台,都需要进行充分的性能评估和软硬件协同优化,以确保AI视觉质检系统能够在边缘端高效、稳定地运行。
分布式推理方案对比:NVIDIA Jetson + Azure IoT Edge vs. 华为昇腾平台
在构建AI视觉质检的边缘计算解决方案时,除了选择边缘硬件本身,如何有效地管理、部署和协同这些边缘设备及AI应用也至关重要。以下将对比两种主流的分布式推理方案:NVIDIA Jetson平台结合Microsoft Azure IoT Edge,以及华为昇腾(Ascend)平台及其云边协同能力。
1. NVIDIA Jetson平台 + Microsoft Azure IoT Edge
- 概述:
- NVIDIA Jetson系列(如Orin Nano, Orin NX, AGX Orin)作为强大的边缘AI硬件,提供了从几TOPS到数百TOPS的算力。
- Microsoft Azure IoT Edge是一个完全托管的服务,构建在Azure IoT Hub之上。它允许将云工作负载(如Azure Functions, Azure Stream Analytics, Azure Machine Learning模型以及自定义容器化应用)部署到边缘设备上。Jetson设备可以作为Azure IoT Edge设备运行。
- 部署细节与硬件配置:
- 硬件:选择合适的NVIDIA Jetson模块(如Jetson Orin NX 16GB),搭载于兼容的载板上,连接工业相机和必要的传感器。
- 软件:Jetson设备上运行NVIDIA JetPack SDK(包含L4T Linux、CUDA、cuDNN、TensorRT)。在此基础上安装Azure IoT Edge运行时。
- 模型部署:
- 在Azure云端训练AI视觉检测模型(例如使用Azure Machine Learning服务,或在本地/其他云平台训练后上传至Azure Model Registry)。
- 使用TensorRT对模型进行优化和量化,以适应Jetson平台的性能和功耗要求。
- 将优化后的模型打包成Docker容器。
- 通过Azure IoT Hub,将该容器化模型作为IoT Edge模块部署到已注册的Jetson设备上。
- 可以同时部署其他模块,如负责图像采集、数据预处理、结果上报、本地存储或与PLC通信的模块。
- 软件栈与算法兼容性:
- Jetson端:JetPack SDK支持主流AI框架(TensorFlow, PyTorch, MXNet等)通过ONNX导入并由TensorRT优化。DeepStream SDK可用于构建高效的视觉AI流水线。
- Azure IoT Edge:支持部署Linux容器(通常是Docker容器)。模块可以用多种语言开发(Python, C#, Node.js, Java, C)。与Azure云服务(如Azure ML, Azure Functions, Azure Stream Analytics, Azure Blob Storage)有良好集成。
- 算法兼容性:只要AI模型能被TensorRT优化并容器化,就能部署。常用的目标检测(YOLO, SSD, Faster R-CNN)、分类(ResNet, MobileNet)、分割(U-Net)等算法均可兼容。
- 实际性能表现:
- 延迟:Jetson Orin NX 16GB在运行优化后的YOLOv5s等模型时,推理延迟通常在10-30毫秒范围内。结合Azure IoT Edge的模块间通信和数据处理,端到端的检测延迟(从图像采集到输出结果)通常可以控制在200ms以内,具体取决于模型复杂度、图像分辨率和流水线设计。
- 吞吐量:取决于具体Jetson型号和模型优化程度,可以满足多数工业实时检测需求。
- 功耗:
- Jetson Orin Nano功耗模式可在5W-15W间配置;Orin NX系列可在10W-25W间配置;AGX Orin可在15W-75W间配置。整体方案功耗主要由Jetson模块决定。
- 成本效益:
- 硬件成本:Jetson模块本身价格从几百到上千美元不等。
- 软件成本:Azure IoT Edge运行时本身免费,但其依赖的Azure IoT Hub及其他Azure服务(如存储、ML服务、容器注册表)会产生费用,通常按用量计费。
- 开发与集成成本:需要熟悉NVIDIA Jetson开发和Azure云服务及IoT Edge的技能。对于已有Azure生态的企业,集成相对顺畅。
- 生态系统支持:
- NVIDIA拥有强大的开发者社区、丰富的SDK和工具链。
- Microsoft Azure拥有成熟的云平台和广泛的企业级服务支持。
- 两者结合提供了从云端模型训练、管理到边缘端安全部署和监控的端到端解决方案。
2. 华为昇腾(Ascend)平台及其云边协同
- 概述:
- 华为昇腾AI硬件包括Atlas系列边缘产品(如Atlas 200 AI加速模块、Atlas 500/500 Pro边缘站点)和服务器端推理/训练卡(如Atlas 300I/V Pro)。
- 华为云提供了IEF(Intelligent EdgeFabric)智能边缘平台,用于实现云边协同,管理边缘节点、下发AI应用、监控设备状态等。华为私有云解决方案(如FusionCube for AI)也支持边缘部署。
- 部署细节与硬件配置:
- 硬件:选择Atlas边缘设备,如内置Atlas 200 AI加速模块(提供8-22 TOPS INT8算力)的Atlas 500 AI边缘小站。
- 软件:边缘设备运行华为EulerOS(基于Linux),搭载CANN(Compute Architecture for Neural Networks)异构计算架构软件栈。
- 模型部署:
- 在华为云ModelArts一站式AI开发平台训练模型,或者使用MindSpore等框架在本地/其他平台训练。
- 通过CANN的ATC(Ascend Tensor Compiler)工具将原始框架模型(如Caffe, TensorFlow, ONNX, MindSpore)转换为昇腾处理器支持的.om离线模型。
- 在华为云IEF平台上将AI应用(包含.om模型及业务逻辑)打包成边缘应用。
- 通过IEF将边缘应用下发到已注册的Atlas边缘节点上。
- 软件栈与算法兼容性:
- 昇腾端:CANN是核心,支持MindSpore(华为自研AI框架)、TensorFlow、PyTorch(通过ONNX转换)等。AscendCL(Ascend Computing Language)提供应用开发接口。
- 华为云IEF:提供应用管理、设备管理、消息路由、AI模型按需加载等功能。
- 算法兼容性:主流的CV算法在转换后均可在昇腾平台上运行。华为也针对特定场景提供了预置的技能包。
- 实际性能表现:
- 延迟:Atlas 200 AI加速模块在运行典型视觉模型时,推理延迟可以做到较低水平。例如,基于Atlas 200I DK A2的YOLOv8缺陷检测速度可达83 FPS(约12毫秒/帧)。对于年产50万件,每秒处理1-5个部件(200-1000毫秒/部件)的需求,Atlas 500这类边缘站点通常能够满足,确保检测延迟在200ms以内。
- 吞吐量:Atlas 500 Pro等更高配置的边缘服务器能处理更多路视频或更复杂的模型。
- 功耗:
- Atlas 200 AI加速模块典型功耗约5.5W-8W,能效比较高。Atlas 500边缘小站的整体功耗也控制在较低水平(如几十瓦),适合工业现场部署。
- 成本效益:
- 硬件成本:Atlas边缘模块和设备的价格需具体咨询华为或其合作伙伴。
- 软件成本:华为云IEF及ModelArts等服务按使用量和规格计费。对于希望构建自主可控AI基础设施的企业,华为也提供私有云和边缘计算的整体解决方案。
- 开发与集成成本:需要熟悉昇腾CANN架构和华为云服务。华为在国内市场拥有较强的技术支持和服务网络。
- 生态系统支持:
- 华为正积极构建其昇腾AI产业生态,提供从芯片、硬件、软件框架到云服务的全栈能力。
- MindSpore社区在不断壮大,CANN的兼容性和工具链也在持续完善。
对比总结与选型考量:
| 特性 | NVIDIA Jetson + Azure IoT Edge | 华为昇腾 + IEF/ModelArts |
|---|---|---|
| 核心硬件 | NVIDIA Jetson系列 (Orin Nano, Orin NX, AGX Orin) | 华为Atlas系列 (Atlas 200, Atlas 500/500 Pro) |
| 云平台集成 | 紧密集成Microsoft Azure (IoT Hub, ML, Functions等) | 紧密集成华为云 (IEF, ModelArts, OBS等) 或私有云解决方案 |
| AI框架支持 | 广泛支持 (TF, PyTorch, MXNet等),通过TensorRT优化 | 支持MindSpore, TF, PyTorch (需ONNX转.om模型 via ATC) |
| 性能(延迟) | 取决于Jetson型号,高端型号性能强劲,可满足<200ms | 取决于Atlas型号,能效比较高,可满足<200ms |
| 功耗 | Jetson Orin系列功耗灵活可配,覆盖范围广 | Atlas 200模块功耗极低,边缘站点整体功耗控制良好 |
| 软件生态 | 成熟的NVIDIA SDK (JetPack, TensorRT, DeepStream) 和 Azure生态 | 持续发展的昇腾CANN和MindSpore生态,华为云服务支持 |
| 优势 | 强大的GPU算力,成熟的全球生态,灵活的Azure云服务集成 | 端到端自主技术栈,高能效比,强大的本土市场支持和服务 |
| 成本结构 | Jetson硬件 + Azure服务订阅 | Atlas硬件 + 华为云服务订阅或整体解决方案采购 |
| 适用场景 | 对GPU性能要求高,已采用或计划采用Azure云服务的企业,全球化部署 | 对自主可控有要求,关注能效比,国内市场为主,或采用华为云的企业 |
选择建议:
- 如果企业已经深度使用Microsoft Azure生态系统,或者项目需要利用Azure提供的特定云服务(如高级分析、全球部署能力),且对NVIDIA GPU的强大算力和成熟的CUDA生态有较高依赖,那么NVIDIA Jetson + Azure IoT Edge方案是一个自然的选择。其灵活性和广泛的第三方软硬件支持也是优势。
- 如果企业更侧重于自主可控的技术栈,对能效比有较高要求,或者主要市场在中国并希望获得更紧密的本土技术支持和服务,华为昇腾平台及其云边协同方案值得重点考虑。华为提供的从芯片到云的全栈能力,以及针对特定行业的优化解决方案,是其独特优势。
- 成本效益的评估需要综合考虑硬件采购、软件订阅/许可、开发集成人力、长期运维以及潜在的供应商锁定风险。
- 无论选择哪种方案,确保AI模型能够被高效优化并部署到目标边缘硬件上,同时满足实际生产的实时性(如200ms以内延迟)、稳定性和可靠性要求,是最终成功的关键。进行小规模PoC(Proof of Concept)验证是降低选型风险的有效手段。
4. 真实世界的实践:案例研究与最佳实践
理论的探讨最终需要落实到产业实践中。本章节将通过分析AI视觉质检在电子制造、汽车零部件和纺织等关键行业的具体应用案例,揭示其在应对小样本数据挑战、设计高效边缘计算部署方案(参考3.3.1节和3.5.2节的平台与选型分析)、精细控制成本与实现投资回报(参考3.5节的TCO与ROI策略),以及努力平衡误检(过杀)与漏检(参考3.4节的代价敏感学习思路)等方面的实际策略与具体成效。这些来自一线的经验将为后来者提供宝贵的借鉴。
4.1 电子制造业(SMT、PCB检测)
电子制造业,特别是表面贴装技术(SMT)和印刷电路板(PCB)的生产,是AI视觉质检应用最早、也最为成熟的领域之一。其生产特点是对缺陷检测的精度和速度要求极高,常见的缺陷包括元件(电阻、电容、芯片等)的缺失、错位、反向、立碑、侧立,焊点的开路、短路、虚焊、多锡、少锡,以及PCB板本身的划痕、污渍、断线、铜箔残留等。
-
面临的共性挑战与行业特性:
- 缺陷微小化与多样化:随着电子产品集成度的提高,元器件尺寸越来越小,缺陷也日益微小化,对检测系统的分辨率和精度提出极高要求。同时,缺陷种类繁多,形态各异。
- 高速生产节拍:SMT产线通常是高速自动化流水线,要求检测系统具备极高的实时处理能力,往往需要在几十到几百毫秒内完成单个视野的检测和判断。
- 小批量多品种趋势:部分电子制造(如工控、医疗电子)呈现小批量、多品种的生产模式,频繁换线对AI模型的快速适应和小样本学习能力提出挑战。
- 高价值密度:PCB和SMT组装板的价值较高,漏检导致的后续成本(如整机报废或市场召回)巨大;而过高的过杀率则直接增加生产浪费。
-
案例分析与策略借鉴:
-
案例1:某大型EMS(电子制造服务)企业的PCB缺陷检测优化
- 核心痛点:传统AOI设备误报率(过杀率)偏高,导致大量人工复判成本;对于某些复杂背景下的微小缺陷,漏检率仍不理想。新品导入时,AOI程序调整和优化耗时较长。
- 小样本数据应对:
- 策略:在新品导入初期,缺陷样本稀缺。企业采用迁移学习策略,将在大量相似PCB板上训练好的深度学习基础模型(如基于ResNet或EfficientNet的特征提取器)在新产品线上进行微调。同时,大力投入数据增强技术,对少量真实缺陷图像进行旋转、缩放、亮度调整、噪声注入等变换,扩充训练集。对于极罕见但关键的缺陷,尝试使用GAN生成合成缺陷样本(参考3.1.2节),模拟其特征,补充到训练数据中。
- 成效:通过这些方法,在仅有几十个新缺陷样本的情况下,模型也能较快达到可接受的初始性能,显著缩短了新品的AI检测导入周期。
- 边缘计算部署:
- 方案:在SMT线尾或AOI复判工位部署搭载NVIDIA Jetson Xavier NX或Orin NX的边缘计算单元。图像由高速工业相机采集后,直接在边缘端进行AI推理。检测结果(OK/NG及缺陷类型、位置)通过工业以太网实时反馈给PLC,控制NG品的分拣,或提示复判人员。部分系统结合Azure IoT Edge进行边缘模块管理和模型更新。
- 性能:优化后的YOLOv5或定制化的轻量级CNN模型,在Jetson NX平台上对单张PCB图像(约5MP-12MP,可能分块处理)的推理时间控制在100-300毫秒,满足产线节拍。
- 成本效益控制:
- TCO考量:虽然初期在边缘计算硬件和AI模型研发/采购上有投入(部分采用商业AI视觉平台进行二次开发),但通过大幅降低人工复判工作量(据称减少了50%-70%的复判人力)、减少因AOI误判导致的产线停顿、以及提升对真实缺陷的捕获率(降低了约5%-10%的缺陷流出),综合ROI在12-18个月内实现。
- 开源与商业结合:底层图像采集和预处理可能使用OpenCV,AI模型训练和推理基于PyTorch/TensorFlow并用TensorRT优化,但上层应用和产线集成可能借助了部分商业软件或系统集成商的服务。
- 漏检/过杀率优化:
- 策略:首先,通过更高质量的数据标注和更精细的模型训练(如使用Focal Loss处理类别不平衡)来提升模型的原始判别能力。其次,引入代价敏感学习的理念(参考3.4.2节),在模型评估和阈值调整时,根据不同缺陷(如开路/短路这类严重缺陷 vs. 轻微划痕)对下游工序或最终产品的影响程度,赋予不同的"错误成本"。对于关键缺陷,宁可接受一定的过杀,也要极力降低漏检。
- 成效:系统整体的F1分数得到提升,更重要的是,关键缺陷的漏检率得到有效控制(例如,从原来的0.5%降低到0.1%以下),同时将整体过杀率维持在可接受的水平(如从AOI的15%-20%降低到AI辅助下的5%-8%)。
-
案例2:中小型电子厂的SMT元件贴装质量检测
- 核心痛点:缺乏资金购买昂贵的进口AOI/SPI设备,人工目检效率低、易疲劳、一致性差。
- 小样本数据应对:
- 策略:由于产线和产品相对固定,缺陷类型也较为集中(如元件偏移、立碑、缺件)。主要依靠持续的数据积累和标注。在系统上线初期,即使准确率不高,也坚持使用并记录所有检测结果和人工判断,形成闭环的数据反馈,逐步迭代优化模型。
- 边缘计算部署:
- 方案:采用性价比较高的NVIDIA Jetson Nano或Jetson Orin Nano配合USB工业相机,搭建简易的在线或半自动检测工位。模型轻量化是关键,例如使用YOLOvNano或MobileNet-SSD。
- 性能:检测速度可能不如大型EMS厂,但对于中低速产线或抽检工位已足够。
- 成本效益控制:
- TCO考量:硬件成本控制在极低水平(例如单检测点硬件总成本1000-2000美元)。主要依赖企业内部工程师(可能非AI专业,但有一定编程和自动化基础)利用开源工具(如OpenCV、LabelImg)和网上教程进行学习和开发,或者寻求低成本的本地集成服务。
- ROI实现:通过替代部分人工目检岗位,提升检测速度和一致性,减少明显错漏导致的返修,也能在1-2年内看到投资回报,对中小企业而言吸引力较大。
- 漏检/过杀率优化:
- 策略:可能无法实现非常精细的代价敏感调整,但会根据主要缺陷的危害程度,在模型训练后,通过调整不同缺陷类别的检测置信度阈值来进行经验性的平衡。例如,对于"缺件"这种严重缺陷,设置较低的阈值以提高召回率。
- 成效:虽然不能完全消除错误,但相比纯人工目检,检测的稳定性和效率有显著提升。
-
-
电子制造业最佳实践提炼:
- 数据是王道:持续投入高质量数据的采集、清洗和精细化标注是模型性能的基石。
- 小样本是常态,组合拳应对:迁移学习、数据增强、合成数据生成(逐步探索)是应对新品导入和罕见缺陷的有效手段。
- 边缘计算是标配:根据实时性、复杂度和成本要求,灵活选择Jetson系列、IPC+GPU或国产AI芯片方案。模型轻量化和硬件加速(如TensorRT)必不可少。
- 成本与效益的动态平衡:既要关注初期投入,更要算清长期运营成本和综合ROI。开源方案需警惕隐性人力成本,商业方案则需评估其带来的效率提升和风险降低。
- 漏检/过杀的精细化管理:从数据、算法到决策阈值,系统性地引入代价敏感的理念,并结合业务知识进行优化,是提升质检系统实用价值的关键。
- 从"检测"到"预防":利用AI系统积累的缺陷数据,进行 SPC(统计过程控制)分析,追溯缺陷根源,指导工艺改进,实现闭环的质量管理。
4.2 汽车零部件制造业(铸件、焊缝、装配缺陷)
汽车行业对零部件的质量和安全性要求极为严苛,AI视觉质检在此领域扮演着越来越重要的角色。其应用范围广泛,涵盖发动机缸体、缸盖、曲轴、连杆等精密铸件的内部及表面缺陷检测(如气孔、裂纹、疏松、夹杂),车身结构件的焊缝质量检测(如焊透、未焊透、烧穿、气孔、咬边、焊偏),以及内外饰件、电子模块、动力总成等部件在装配过程中的缺陷检测(如错装、漏装、反向、螺丝浮高、扭矩不足、间隙异常、划痕、压伤等)。
-
面临的共性挑战与行业特性:
- 零缺陷的高要求:汽车零部件,特别是涉及安全的部件(如转向、制动、发动机关键件),对缺陷的容忍度极低,漏检可能导致灾难性后果和巨额召回成本。
- 复杂缺陷形态与恶劣检测环境:铸件内部缺陷的不可见性(常需X光或超声波配合视觉判读),金属表面的高反光、油污,焊缝的不规则形态和烟尘干扰,都给图像采集和AI分析带来巨大挑战。
- 大批量与柔性生产并存:部分零部件产量巨大,要求高速在线检测;同时,汽车型号更新快,零部件种类繁多,要求AI系统具备良好的迁移和快速适应能力。
- 严格的可追溯性要求:对每一个关键零部件的检测结果和图像数据,通常需要完整记录并长期保存,以备质量追溯和审计。
-
案例分析与策略借鉴:
-
案例1:某发动机缸体铸造厂的X光底片AI辅助判读
- 核心痛点:传统人工X光底片阅片强度大、效率低、易疲劳,且对阅片师经验依赖度高,不同阅片师之间判读标准一致性难以保证。内部缺陷(如气孔、疏松、裂纹)的漏检可能导致发动机严重故障。
- 小样本数据应对:
- 策略:针对特定类型的内部缺陷,初期由资深阅片专家对少量典型X光底片进行精细标注(像素级分割或缺陷区域包围框)。采用迁移学习,将在大规模医学影像数据集(如LUNA, DeepLesion)上预训练的分割或检测模型(如U-Net, Mask R-CNN)作为基础,在标注的X光底片数据上进行微调。积极运用数据增强技术(如旋转、平移、对比度调整、添加模拟噪声)扩充数据集。
- 成效:AI辅助判读系统能够初步筛查出可疑缺陷区域,并给出缺陷类型的概率,显著降低了人工阅片的负担,提升了对微小和非典型缺陷的关注度。虽然不能完全替代人工,但将平均阅片时间缩短了30%-50%,并提高了判读的一致性。
- 边缘计算与协同架构 (此案例更偏向工作站AI辅助,但可延伸至产线边缘部署的潜力):
- 方案:目前主要在阅片工作站(高性能PC+GPU)上运行AI判读软件。未来趋势是将部分预筛选模型部署到X光成像设备旁的边缘计算单元(如IPC + NVIDIA RTX A4000/A5000 GPU),对原始图像进行初步快速处理,仅将高度可疑的图像或区域传输给专家系统或云端进行进一步分析和复核,实现云边协同。
- 成本效益控制:
- TCO考量:主要投入在AI模型开发(或采购专业医学影像AI软件)、高性能工作站以及持续的数据标注和模型迭代。
- ROI实现:通过提升检测效率、降低因人工疲劳导致的漏检风险、以及积累标准化的缺陷知识库来实现。更重要的是,通过提升早期缺陷发现能力,避免了缺陷缸体流入后续加工或装配环节,减少了更大的制造成本损失。
- 漏检/过杀率优化:
- 策略:此场景下,漏检的代价极高。因此,在模型设计和阈值设定上,会倾向于**“宁可错杀三千,不可放过一个”**(即容忍较高的过杀率以追求极低的漏检率)。通常采用两阶段判读:AI系统高敏感度筛选可疑区域,再由人工对AI标记的区域进行最终确认。代价敏感学习的思想体现在对不同类型内部缺陷(如裂纹 vs. 单个小气孔)赋予不同的风险权重。
- 成效:关键内部缺陷的漏检率得到显著降低,虽然可能增加了人工复核AI预警的工作量,但整体质量风险得到有效控制。
-
案例2:某汽车总装厂的机器人视觉引导与装配缺陷检测
- 核心痛点:人工进行大量紧固件(螺丝、螺母、卡扣)的安装和检查,易出错(漏装、错装、未拧紧),且效率难以提升。某些关键装配位置的缺陷直接影响车辆安全。
- 小样本数据应对:
- 策略:对于常见的错漏装类型,样本相对容易获取。对于偶发的、非典型的装配错误,通过场景仿真和合成数据生成(例如,在CAD模型中模拟螺丝浮高、卡扣未完全扣合等状态,并渲染生成不同光照和视角的图像)来补充训练数据。
- 边缘计算部署:
- 方案:在机器人手臂末端或关键工位安装集成光源的智能相机(如康耐视In-Sight系列或Keyence VS系列,内置AI处理能力),或将标准工业相机连接到工位旁的边缘控制器(如西门子SIMATIC Edge PC,或搭载华为Atlas模块的边缘设备)。AI模型在边缘端实时分析图像,判断装配质量,并将结果(OK/NG,或具体参数如螺丝扭矩、间隙大小)反馈给机器人控制系统或产线PLC,实现即时纠错或报警。
- 性能:要求极高的实时性,通常需要在100毫秒内完成检测和反馈。边缘设备的算力和优化至关重要。
- 成本效益控制:
- TCO考量:商业智能相机或集成视觉的机器人系统初期投资较高。但通过实现"机器换人",大幅提升装配精度和一致性,减少因装配错误导致的返工和质量事故,长期ROI可观。
- 标准化方案:汽车主机厂倾向于选择有成熟行业应用、支持标准化工业通讯协议(如Profinet, EtherCAT)的商业视觉解决方案,以保证系统的稳定性和可维护性。
- 漏检/过杀率优化:
- 策略:对于涉及安全的装配项(如刹车系统螺丝),漏检是不可接受的。系统设计时会采用多重冗余检测(如视觉+扭矩传感器)。AI模型的报警阈值会设置得非常保守,以确保所有可疑情况都被标记。后续可能有人工抽检或自动复检站。
- 成效:关键装配错误的漏检率接近于零。过杀的缺陷(如将轻微的螺丝表面划痕误判为未拧紧)会由后续流程处理,或通过持续优化模型和调整判定逻辑来减少。
-
-
汽车零部件制造业最佳实践提炼:
- 安全第一,质量至上:在汽车行业,AI视觉质检的首要目标是确保安全和质量,对漏检的容忍度极低,这深刻影响着技术选型和优化方向。
- 拥抱复杂性:勇于挑战金属表面、复杂结构、恶劣环境下的缺陷检测难题,综合运用多种传感技术(视觉、X光、超声、力反馈等)和AI算法。
- 边缘智能与实时闭环:边缘计算是实现在线检测、即时反馈和机器人协同的关键,对延迟和可靠性要求高。
- 数据驱动的全生命周期追溯:AI系统不仅要检测,还要记录详细的检测数据和图像,支持从零部件到整车的全生命周期质量追溯。
- 小样本与合成数据的战略价值:对于种类繁多、迭代快速的汽车零部件,以及偶发但严重的关键缺陷,小样本学习和高质量合成数据的生成能力至关重要。
- TCO与"质量成本"的权衡:不能仅看AI系统的采购成本,更要评估其在降低"不良质量成本"(如内部故障成本、外部故障成本、预防成本、鉴定成本)方面的巨大潜力。
4.3 纺织行业(织物及图案缺陷检测)
纺织品的外观质量直接影响其最终售价和品牌形象,因此,织物缺陷检测是纺织生产过程中至关重要的环节。AI视觉质检技术正被越来越多地应用于检测纺纱、织造(如坯布)、染整(如印花布、色织布)等各环节产生的各种疵点,例如断纱、粗纬、稀纬、破洞、污渍、油渍、色差、条痕、横档、异物织入、图案歪斜、漏印、花纹不清等。
-
面临的共性挑战与行业特性:
- 缺陷种类繁多且形态细微、复杂:纺织品缺陷种类多达数百种,许多缺陷(如细微的断纱、轻微的色差、不规则的污渍)与背景纹理对比度低,形态不固定,检测难度大。
- 织物材质、纹理和图案多样性:不同纤维(棉、毛、丝、麻、化纤)、不同织法(平纹、斜纹、缎纹)、不同图案(几何、花卉、抽象)导致织物表面特征千变万化,对AI模型的泛化能力要求极高。
- 高速连续生产:现代织布机和印染设备速度非常快,要求检测系统能够进行高速、实时的在线检测。
- 小批量、快时尚趋势:尤其在服装行业,小批量、多品种、快翻单的生产模式,使得为每种产品重新训练模型的数据和时间成本成为主要障碍。
- 成本敏感性:纺织行业整体利润率不高,对AI视觉质检系统的投入成本和投资回报周期较为敏感。
-
案例分析与策略借鉴:
-
案例1:某大型印染企业的印花布缺陷在线检测
- 核心痛点:人工"灯检"劳动强度大,效率低下,易受主观因素影响导致标准不一,且无法适应高速印染生产线。漏检的印花缺陷(如漏印、套色不准、图案变形、拖浆等)会导致整匹布降等或报废,损失较大。
- 小样本数据应对:
- 策略:针对特定客户和订单的"首件"或小批量试产,缺陷样本非常有限。企业采用**"一次学习 + 持续学习"的模式。首先,基于历史积累的各类印花布缺陷数据,训练一个通用的缺陷特征提取基础模型。对于新花型,仅需提供少量(甚至几米)的合格品样布和标注少量典型缺陷(如果存在),通过小样本学习(Few-Shot Learning)** 技术(如基于原型网络或注意力机制的模型)对基础模型进行快速适配。同时,重点应用基于GAN的合成数据生成技术,模拟生成各种真实印花过程中可能产生的瑕疵,如颜色漂移、图案轻微错位等,以增强模型对细微变化的鲁棒性。系统在运行过程中,会自动收集可疑缺陷图像,经人工确认后加入训练集,实现模型的持续优化。
- 成效:新品导入的AI模型准备时间从数天缩短到几小时。对于常见花型,缺陷检出率达到95%以上,显著优于人工。
- 边缘计算部署:
- 方案:在印染线末端或验布机上安装线阵相机(配合高亮度LED线光源),图像数据实时传输到产线旁的边缘计算服务器(如配置NVIDIA Tesla T4或RTX 30系列GPU的工业服务器)。考虑到数据量和处理速度要求,可能会采用多GPU并行处理或分布式边缘节点。部分轻量级预警模型也可部署在集成处理能力的智能相机上。
- 性能:系统需处理高速运动的布匹(速度可达60-120米/分钟),要求AI模型在极短时间内完成缺陷识别和定位,延迟需控制在几十毫秒级别。
- 成本效益控制:
- TCO考量:初期硬件投入(高性能线阵相机、光源、边缘服务器)和AI软件平台(可能是商业平台或基于开源深度定制)成本较高。但通过大幅减少人工验布员数量(例如,一条产线可减少80%的验布工)、显著降低因漏检导致的次品和废品(例如,废品率降低5%-15%),以及提高验布速度和一等品率,综合ROI可在1.5-2.5年内实现。
- 能耗优化:选择低功耗的边缘计算硬件,并对算法进行优化,以降低长期运营成本。
- 漏检/过杀率优化:
- 策略:根据不同缺陷对织物等级和价值的影响,建立缺陷分级和对应的成本矩阵。例如,大面积的漏印或严重色差属于一级品킬러缺陷,其漏检成本极高。在模型训练中使用代价敏感的加权损失函数,对这些关键缺陷的检测更为敏感。同时,针对纺织品纹理复杂易导致过杀的问题,采用基于正常样本学习的异常检测算法(Anomaly Detection),让模型主要学习"什么是正常的布料",从而更好地识别"不正常"的缺陷,以期在保证召回率的同时降低误报。
- 成效:一级品率提升约3%-5%,关键缺陷的漏检得到有效控制,整体经济效益显著。
-
案例2:某中小型织造厂的坯布表面疵点检测
- 核心痛点:坯布疵点(如断经、断纬、油污、破洞)检测依赖人工,效率低,且易因视觉疲劳和标准不一导致漏检和错检。
- 小样本数据应对:
- 策略:由于资金和技术能力有限,主要采用基于大量正常样本的无监督或半监督学习方法。例如,使用自动编码器(Autoencoder)或VAE(Variational Autoencoder)学习正常坯布的特征表示,当检测到与正常模式偏差较大的图像块时,判定为缺陷。对于少量已知的典型缺陷,可以作为"引导样本"辅助模型学习。
- 边缘计算部署:
- 方案:采用成本较低的工业面阵相机+NVIDIA Jetson TX2/Xavier NX或同等级别的国产AI计算卡搭建检测模块,安装在织布机落布处或专用的验布小车上。
- 性能:处理速度和精度可能不及大型印染厂的高端系统,但足以替代大部分人工粗检工作。
- 成本效益控制:
- TCO考量:严格控制硬件成本和软件开发成本。可能选择成熟的开源检测算法(如基于OpenCV的传统图像处理结合简单的CNN分类器)或低成本的AI视觉模块。
- ROI实现:通过减少对高成本人工验布的依赖,提升疵点发现的及时性(避免缺陷布匹继续加工),减少浪费,实现较快的投资回报。
- 漏检/过杀率优化:
- 策略:无监督方法对未知缺陷有一定检出能力,但误报率可能偏高。通常会设定一个缺陷大小或严重程度的阈值,对AI报警的缺陷再进行快速的人工确认。
- 成效:能够有效检出大部分明显疵点,减轻了人工劳动强度,提升了整体质检效率。
-
-
纺织行业最佳实践提炼:
- 拥抱数据多样性是关键:针对纺织品材质、纹理、花型的高度多样性,必须建立强大的数据采集、管理和增强能力。小样本学习和合成数据技术在此领域潜力巨大。
- 无监督/半监督学习的探索:鉴于标注成本高和缺陷类型不确定性,基于正常样本学习的异常检测方法是重要的补充手段,尤其适用于坯布等大批量、纹理相对单一的场景。
- 速度与精度的平衡:高速产线对实时性要求极高,需在模型复杂度和边缘计算能力之间仔细权衡。线阵相机和专用光源是常用配置。
- 成本敏感与分级处理:根据不同疵点对产品价值的影响进行分级,并采取差异化的检测策略和成本考量,是实现经济效益最大化的有效途径。
- 与生产工艺的结合:AI视觉检测不仅是"事后把关",更应与纺纱、织造、染整等前道工序联动,通过缺陷数据的快速反馈,帮助优化工艺参数,从源头控制疵点产生。
- 行业知识的融入:成功的纺织AI质检系统需要深度融合纺织工艺知识和AI技术,例如理解不同织物结构对缺陷形态的影响,或特定染料对颜色检测的挑战等。
5. 未来发展轨迹:新兴趋势与战略展望
AI视觉质检技术并非静止不前,它正处在一个由算法创新、硬件迭代、行业需求深化以及跨界技术融合共同驱动的加速演进时期。洞察这些新兴趋势,并据此制定前瞻性的技术研发与应用战略,对于企业在日益激烈的市场竞争中抓住机遇、保持领先至关重要。本章节将聚焦AI算法的未来演进、新兴硬件与部署范式、以及智能化与自动化的新高度,展望它们如何重塑AI视觉质检的边界,并为解决现有痛点(如小样本学习、边缘智能的局限性、检测平衡的精细化以及成本效益的持续优化)带来新的曙光。
5.1 AI算法的演进:迈向更鲁棒、可解释和自适应的系统
未来的AI视觉质检算法将不再仅仅满足于"看见"和"判断",而是朝着更深层次的"理解"、"解释"和"自主适应"进化。这不仅意味着更高的检测精度和更广的适用场景,更预示着AI系统将成为工业质量管理中更能动、更可信赖的伙伴。
-
极致的鲁棒性与泛化能力——应对永恒的挑战:
- 从数据驱动到知识与数据联合驱动:虽然高质量数据依然重要,但未来的算法将更加注重融入先验知识(如物理成像原理、材料光学特性、缺陷形成机理等)。通过知识图谱、因果推断等技术,使模型不仅从数据中学习相关性,更能理解缺陷产生的因果链条,从而在面对训练数据中未曾覆盖的全新场景或微小环境变化时,展现出更强的零样本或少样本泛化能力。
- 超越领域自适应(Domain Adaptation)与领域泛化(Domain Generalization):现有技术在处理源域和目标域之间显著差异时仍有局限。未来的研究方向可能包括更强大的解耦表示学习(Disentangled Representation Learning),将图像中与任务相关的本质特征(如缺陷本身)和与任务无关的干扰因素(如光照、视角、背景纹理)彻底分离,使得模型仅依赖本质特征进行判断。此外,元学习(Meta-Learning)或"学会学习" 将扮演更重要角色,使模型能够从少量多样化的任务中快速学习到通用的学习策略,从而在面对全新的产品型号或缺陷类别时,仅需极少样本就能快速掌握检测要领。
- 对抗性鲁棒性的内化:针对蓄意或非蓄意的对抗性攻击(如微小的、人眼难以察觉的图像扰动可能导致模型误判),未来的算法将更加注重提升自身的对抗鲁棒性,例如通过对抗训练的改进、鲁棒优化技术以及开发能够检测和抵抗对抗样本的防御机制,确保AI系统在复杂甚至潜在恶意环境中的可靠性。
-
深度可解释性(XAI)的成熟与普及——从"黑箱"到"透明助手":
- 超越事后解释,迈向事前可控与事中交互:当前的XAI技术(如LIME, SHAP, Grad-CAM,已在3.2.3节讨论)主要提供事后解释。未来的XAI将更侧重于:
- 事前可控性:在模型设计阶段就融入可解释性约束,使得模型的决策逻辑本身就更符合人类的认知习惯。
- 事中交互式解释:允许用户在模型决策过程中进行"提问"或"假设分析"(What-if Analysis),例如"如果这个区域的光照变化,你会如何判断?",从而动态理解模型的行为。
- 面向不同用户的多层次、多模态解释:XAI的输出不应仅仅是技术性的热力图或特征重要性排序,而应能根据用户的背景(如一线操作员、质量工程师、管理者)提供不同深度和形式的解释(如自然语言描述、可视化图表、关键规则提取)。
- 基于XAI的知识发现与工艺优化:通过深度分析模型关注的图像区域和学到的缺陷模式,XAI不仅能帮助调试模型,更有潜力揭示一些以往被人类专家忽略的、与缺陷产生相关的细微图像特征或生产参数组合,为工艺改进和缺陷根源分析提供全新的数据驱动洞察,真正实现从"缺陷检测"到"缺陷预防"的跨越。
- 超越事后解释,迈向事前可控与事中交互:当前的XAI技术(如LIME, SHAP, Grad-CAM,已在3.2.3节讨论)主要提供事后解释。未来的XAI将更侧重于:
-
持续学习与自适应能力的飞跃——打造永不"过时"的AI:
- 克服灾难性遗忘的根本性突破:如3.2.4节所述,灾难性遗忘是持续学习的核心障碍。未来的算法有望通过更接近生物大脑学习机制的创新(如更有效的记忆回放与整合机制、动态网络结构调整、稀疏表示与神经元选择性激活等),在学习新知识(如新产品、新缺陷类型)的同时,更高效地保留甚至增强旧知识,实现真正的"终身学习"。
- 主动学习与自我进化的闭环:AI系统将具备更强的主动学习能力,能够自动识别出当前模型最不确定的、或对提升性能最有价值的未标注样本,并主动请求人工标注(Human-in-the-Loop)。更进一步,系统甚至可以基于历史经验和当前性能反馈,进行一定程度的自我参数调整和模型结构优化,形成一个不断自我完善的智能进化闭环。
- 与环境的动态交互和自适应标定:未来的AI视觉质检系统可能具备与生产环境(如PLC、传感器网络)更深度的交互能力。例如,当光照传感器检测到环境光发生显著变化时,AI系统可以主动触发模型的自适应调整或重新标定程序,而无需人工干预,确保在动态环境下的检测稳定性。
-
联邦学习的深化与可信联邦——构建安全的协同智能生态:
- 解决数据异构性与统计异质性的挑战:如3.2.5节所述,不同工厂或产线的数据分布往往存在显著差异(Non-IID)。未来的联邦学习算法将更加专注于提升在高度异构数据环境下的全局模型性能和收敛速度,例如通过个性化联邦学习(Personalized Federated Learning,为每个参与方生成定制化的模型变体)、联邦元学习(Federated Meta-Learning)等。
- 增强隐私保护与安全性:除了基本的"数据不出本地",更高级的隐私增强技术(如差分隐私的优化应用、同态加密的实用化、安全多方计算)将被集成到联邦学习框架中,以应对更复杂的隐私泄露风险和潜在的恶意攻击(如模型投毒、成员推理攻击)。"可信联邦学习"将成为重要方向,确保联邦过程的公平性、透明度和可审计性。
- 联邦学习与边缘计算的无缝融合:联邦学习天然适合边缘计算场景。未来的趋势是将联邦学习的客户端训练和模型聚合过程更高效地部署在资源受限的边缘设备上,并优化通信协议,减少带宽消耗和延迟。
这些算法层面的演进,将共同推动AI视觉质检系统从一个相对静态、被动响应的检测工具,转变为一个能够主动学习、自我优化、与环境动态交互、并且其决策过程高度透明、值得信赖的智能化质量控制核心。这将极大地拓展AI视觉质检的应用边界,并为解决小样本、高泛化、检测平衡以及成本效益等核心痛点提供更强大的技术武器。
5.2 新兴硬件与部署范式:从边缘智能到云边端协同的跃迁
AI视觉质检的效能不仅取决于算法的先进性,同样依赖于底层硬件的支撑以及高效灵活的部署架构。未来的硬件将向着更高算力、更低功耗、更小尺寸以及更集成化的方向发展,而部署范式也将从孤立的边缘节点向着云、边、端深度协同的智能网络演进。
-
边缘AI硬件的持续进化:
- 更高能效比的AI芯片:NVIDIA Jetson系列、华为昇腾系列、Intel Movidius、Qualcomm AI芯片等将持续迭代,通过更先进的制程工艺、专门的AI加速核心(如NPU)以及存内计算(In-Memory Computing)等创新,在指甲盖大小的芯片上实现数十甚至数百TOPS的算力,同时将功耗控制在极低水平。这将使得更复杂的AI模型可以直接在相机、传感器或小型边缘设备上本地运行。
- 异构计算与专用加速器:除了通用的AI芯片,针对特定视觉任务(如高速图像预处理、特定类型的特征提取、3D点云处理)的专用硬件加速器(FPGA、ASIC)也将扮演重要角色,与主AI处理器协同工作,实现系统整体性能的最优。
- 事件相机(Event Cameras)与新型传感器:传统相机以固定帧率采集图像,可能产生大量冗余数据或在高速运动下产生模糊。事件相机(也称动态视觉传感器DVS)仅在像素亮度发生变化时才产生异步事件流,具有极高的时间分辨率、宽动态范围和低数据冗余,非常适合高速、高动态范围的质检场景。结合神经拟态计算(Neuromorphic Computing),有望带来颠覆性的视觉处理方案。此外,高光谱相机、热成像相机、偏振相机等多模态传感器的集成和成本下降,将为AI提供更丰富的缺陷信息维度。
- 集成AI的智能相机与传感器:越来越多的工业相机和传感器将内置强大的AI处理单元和预置算法,实现"采集即分析",进一步简化系统集成难度和部署成本,推动AI视觉在更多小型化、分布式场景的应用。
-
云边端协同(Cloud-Edge-Device Synergy)的深化:
- 分层智能与任务动态卸载:未来的AI视觉质检系统将是一个分层协同的智能网络。简单的、对实时性要求极高的任务(如快速剔除)在最靠近数据源的端设备(如智能相机)上完成;较复杂的模型推理和产线级数据分析在边缘服务器(Edge Server)上进行;而大规模模型训练、跨工厂数据分析、长期趋势预测、以及需要海量计算资源的复杂仿真则在云端(Cloud)进行。任务可以根据网络状况、计算负载和业务需求在云、边、端之间动态迁移和卸载。
- 统一的云边协同管理平台:如Azure IoT Edge, AWS IoT Greengrass, 华为云IEF等平台将更加成熟,提供从模型开发、优化、容器化封装、安全分发、边缘节点管理、应用部署、远程监控、故障诊断到OTA(Over-the-Air)更新的全生命周期管理能力,大幅降低大规模边缘AI部署的复杂性和运维成本。
- 边缘数据湖与分布式数据治理:大量的工业数据产生于边缘,并非所有数据都需要或适合上传到云端。边缘数据湖(Edge Data Lake)的概念将兴起,允许在边缘进行数据的初步存储、处理和分析,仅将有价值的洞察或聚合数据上传。结合联邦学习等技术,实现分布式数据的安全合规治理和价值挖掘。
-
AIoT(人工智能物联网)与5G的赋能:
- 海量设备互联与实时通信:AIoT将视觉检测节点、传感器、PLC、机器人等海量工业设备连接起来,形成一个感知、分析、决策、执行的闭环。5G技术(特别是uRLLC特性)提供的超低延迟、高带宽和海量连接能力,将为边缘AI设备之间以及边云之间的数据高速传输和协同控制提供网络基础,使得更复杂的分布式AI视觉应用成为可能(例如,多相机协同进行大尺寸物体三维重建与缺陷检测)。
- 无线化与移动化部署:5G的普及将推动AI视觉检测设备摆脱有线束缚,实现更灵活的无线化、移动化部署,例如在AGV(自动导引车)、巡检机器人上搭载AI视觉系统,进行动态环境下的质量检测。
这些硬件与部署架构的革新,将为AI视觉质检带来更高的性能、更低的成本、更强的灵活性和更广阔的应用空间,为解决大规模、分布式、高要求的工业质检难题提供坚实的基础设施支撑。
5.3 智能化与自动化的新高度:迈向自主决策与流程"黑灯工厂"
随着算法、硬件和部署架构的不断成熟,AI视觉质检的应用将从单一的"辅助检测"工具,向着更深层次的"自主决策"、"流程优化"乃至"黑灯工厂"的智能化生产新范式迈进。这不仅仅是技术的进步,更是对传统制造理念的深刻变革。
-
多模态AI融合与情境感知:
- 超越单一视觉:未来的AI质检系统将不再局限于可见光图像,而是融合来自X光、红外、高光谱、激光雷达(LiDAR)、声音、振动、温度、压力等多种传感器的多模态数据,形成对产品状态和生产环境更全面、更立体的感知。例如,通过融合视觉图像和设备振动数据,可以更准确地判断某个加工缺陷是否由设备异常引起。
- 情境感知与动态决策:AI系统将具备更强的情境理解能力,能够结合当前的生产批次、工艺参数、物料信息、历史缺陷数据、甚至上下游工序的状态,动态调整检测标准和判别逻辑。例如,在物料更换初期,系统可能会自动提高对特定潜在缺陷的敏感度。
-
数字孪生(Digital Twin)驱动的虚拟检测与预测性质量控制:
- 物理世界的数字镜像:通过为产线、设备甚至产品构建高保真的数字孪生体,AI视觉质检系统可以在虚拟空间中进行缺陷模拟、检测算法验证、工艺参数优化实验,而无需中断实际生产,大幅降低试错成本和时间。
- 从"事后检测"到"事前预测":结合数字孪生和实时生产数据(包括视觉检测结果、设备状态参数、环境数据等),AI模型可以预测未来可能发生的缺陷类型和概率,提前发出预警,并建议调整工艺参数以避免缺陷的实际发生,实现真正的预测性质量控制。例如,通过分析当前批次产品的微小表面纹理变化和历史数据,预测下一批次可能出现的严重裂纹。
-
AI驱动的自主决策与闭环控制:
- 从"辅助"到"主导":在一些成熟的应用场景,AI视觉质检系统将逐渐从辅助人工决策,过渡到在预设规则和置信度范围内进行自主的缺陷判定、分级、以及控制分拣剔除等动作,甚至直接调整上游设备的工艺参数,形成快速的质量控制闭环。
- 人机协同的进化:即使在高度自动化的场景,人的角色依然重要,但会从重复性的检测操作,转变为对AI系统的监控、维护、异常处理、以及对复杂疑难缺陷的最终仲裁。人机界面将更加友好和智能化,支持自然语言交互和远程协作。
-
迈向"黑灯工厂"的终极愿景:
- 全流程自动化与智能化:AI视觉质检作为智能制造的关键一环,将与其他自动化技术(如机器人、AGV、智能仓储、MES、ERP)深度集成,共同构成"黑灯工厂"(即无需人工干预的全自动化工厂)的感知和决策核心。
- 自适应、自学习、自优化的生产系统:在"黑灯工厂"中,整个生产系统能够根据市场需求、物料供应、设备状态等动态变化,通过AI进行自主调度、自主优化和自主维护,AI视觉质检在其中持续监控产品质量,并将信息实时反馈给控制系统,驱动整个生产流程的持续改进和效率提升。
当然,实现上述愿景并非一蹴而就,仍需克服诸多技术、成本、标准、安全以及伦理方面的挑战。但可以预见的是,AI视觉质检正朝着更智能、更自主、更深度融入制造全流程的方向快速发展,其最终目标是帮助制造业实现前所未有的质量水平、生产效率和运营韧性。
6. 总结与建议:直面挑战,拥抱变革,加速AI视觉质检赋能制造升级
本文通过深入剖析AI视觉质检的变革潜力、落地困境、技术突破路径以及未来发展趋势,特别聚焦于小样本学习、边缘计算部署、漏检/过杀平衡、成本效益控制等关键实践环节。综合以上研究,我们可以总结出AI视觉质检当前面临的核心挑战,并据此提出具有实践指导意义的技术突破路径、部署策略和发展建议,以期加速其在制造业的规模化应用,赋能产业高质量发展。
6.1 核心挑战再聚焦
尽管AI视觉质检前景广阔,但其规模化落地仍需直面以下核心挑战:
表:AI视觉质检核心挑战聚焦
| 挑战领域 | 核心挑战描述 | 相关章节参考 |
|---|---|---|
| 数据与泛化 | 小样本学习实效性与模型泛化能力鸿沟,高质量标注数据稀缺,合成数据真实性与过拟合风险。 | 3.1, 3.2.1 |
| 边缘计算与性能 | 边缘计算方案选型困境(性能、功耗、成本、生态),边缘设备算力瓶颈,模型优化与硬件协同,端到端延迟达标。 | 3.3.1, 3.5.2 |
| 成本效益与ROI | 高昂初期投入(硬件、软件、开发集成人力),TCO评估复杂,ROI论证难,开源方案隐性成本,商业方案许可费高。 | 2.3.3, 3.5 (表1) |
| 检测精度平衡 | 漏检(错放)与过杀(误检)的平衡艺术,根据业务场景和缺陷风险定义错误成本,代价敏感学习的实践落地。 | 2.2.2, 3.4 |
| 集成与人才 | AI视觉模块与现有自动化产线(PLC, MES等)的复杂系统集成,接口、协议、数据流问题;既懂AI又熟悉工业Know-How的复合型人才短缺。 | 2.3.1, 2.4.1 |
| 标准与生态 | 缺乏统一行业标准(数据格式、性能评估、安全规范等),阻碍技术互操作、规模化推广和用户信任;产业链各环节(算法、硬件、集成、应用)协同不足,生态系统碎片化。 | 2.4.2, 政策法规部分 |
6.2 技术突破路径与部署策略建议
针对上述挑战,企业在规划和实施AI视觉质检项目时,可考虑以下技术路径和部署策略:
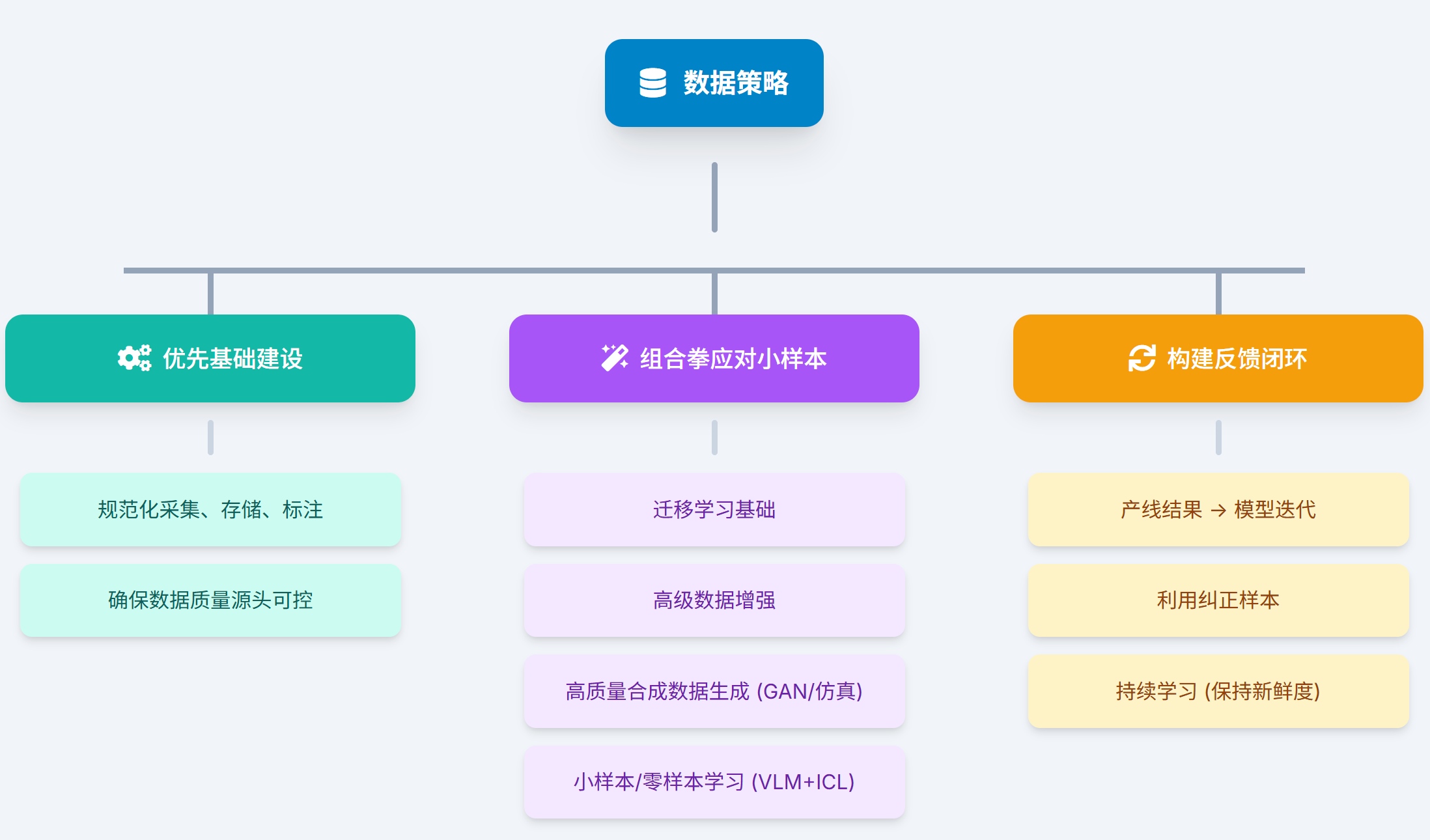
1. 数据策略:多管齐下,拥抱"小数据"智慧:
- 优先基础建设:建立规范化的数据采集、存储、标注流程,确保数据质量源头可控。
- 组合拳应对小样本:将迁移学习作为基础,积极运用高级数据增强,审慎探索高质量合成数据生成(尤其是利用GAN或仿真技术生成罕见/关键缺陷),并逐步尝试引入小样本/零样本学习算法,特别是结合预训练大模型(如VLM)的上下文学习(ICL)能力(参考3.1.1节),提升模型对新产品/缺陷的快速适应力。
- 构建反馈闭环:建立从产线检测结果到模型迭代的持续反馈机制,利用在线运行中积累的数据(尤其是被人工纠正的误判样本)进行模型的持续学习(参考3.2.4节),保持模型"新鲜度"。
2. 边缘计算:按需选型,云边协同,软硬优化:
- 需求驱动选型:根据具体任务的实时性要求(延迟指标)、模型复杂度、功耗预算和环境耐受性,理性选择边缘计算平台(参考3.3.1和3.5.2节)。对于中低复杂度任务,高性价比的Jetson Orin Nano/NX或同级国产平台是优选;对于高性能需求,可考虑Jetson AGX Orin或IPC+GPU;对于特定生态或自主可控需求,可考虑华为Atlas等。进行PoC验证是关键。
- 深度模型优化:必须将模型量化(INT8是常态)、剪枝、知识蒸馏等优化技术作为标准流程,并充分利用目标硬件平台的专用加速库(如TensorRT, CANN ATC, OpenVINO)。
- 拥抱云边协同:利用成熟的云边协同平台(Azure IoT Edge, AWS IoT Greengrass, 华为IEF等)实现模型的远程部署、管理、监控和更新,降低运维复杂度。将模型训练、大数据分析放在云端,推理和服务部署在边缘,实现资源最优配置。
- 探索联邦学习:对于多工厂或供应链协同场景,积极评估和试点联邦学习(参考3.2.5节),在保护数据隐私的前提下,提升全局模型的泛化能力。
3. 成本控制:精算TCO,价值驱动,灵活选择:
- 全面TCO评估:超越初期采购成本,使用结构化框架(参考表1及3.5.1节)评估包含人力、时间、维护、升级在内的全生命周期TCO。
- 价值优先原则:优先将AI视觉质检应用于那些能够带来最高价值(如减少重大质量损失、替代高成本人工、突破效率瓶颈)的场景,确保ROI最大化。
- 开源 vs. 商业的理性权衡:根据自身技术实力、项目周期要求、风险承受能力和对长期支持的需求,在开源和商业方案间做出明智选择。考虑混合方案(如底层开源,上层应用或集成借助商业服务)。
- 标准化与模块化:采用标准化硬件接口和模块化软件设计,提升系统的可复用性、可扩展性和可维护性,降低长期成本。
4. 精度平衡:业务导向,代价敏感,持续迭代:
- 量化错误成本:推动跨部门协作,尽可能量化或分级评估不同类型漏检和过杀所带来的业务成本或风险,形成指导性的成本矩阵。
- 引入代价敏感学习:在模型训练(如使用加权损失)和决策(如调整最优阈值)阶段,显式融入成本信息(参考3.4.2节),使AI决策与业务目标对齐。
- 建立多指标评估体系:除了准确率、F1分数,更要关注Precision, Recall以及根据成本矩阵计算的预期总成本等更能反映实际需求的指标。
- 结合XAI与人工经验:利用可解释AI(参考3.2.3节)理解模型判断依据,结合领域专家的经验,对模型的决策逻辑和阈值进行精细调整和持续优化。
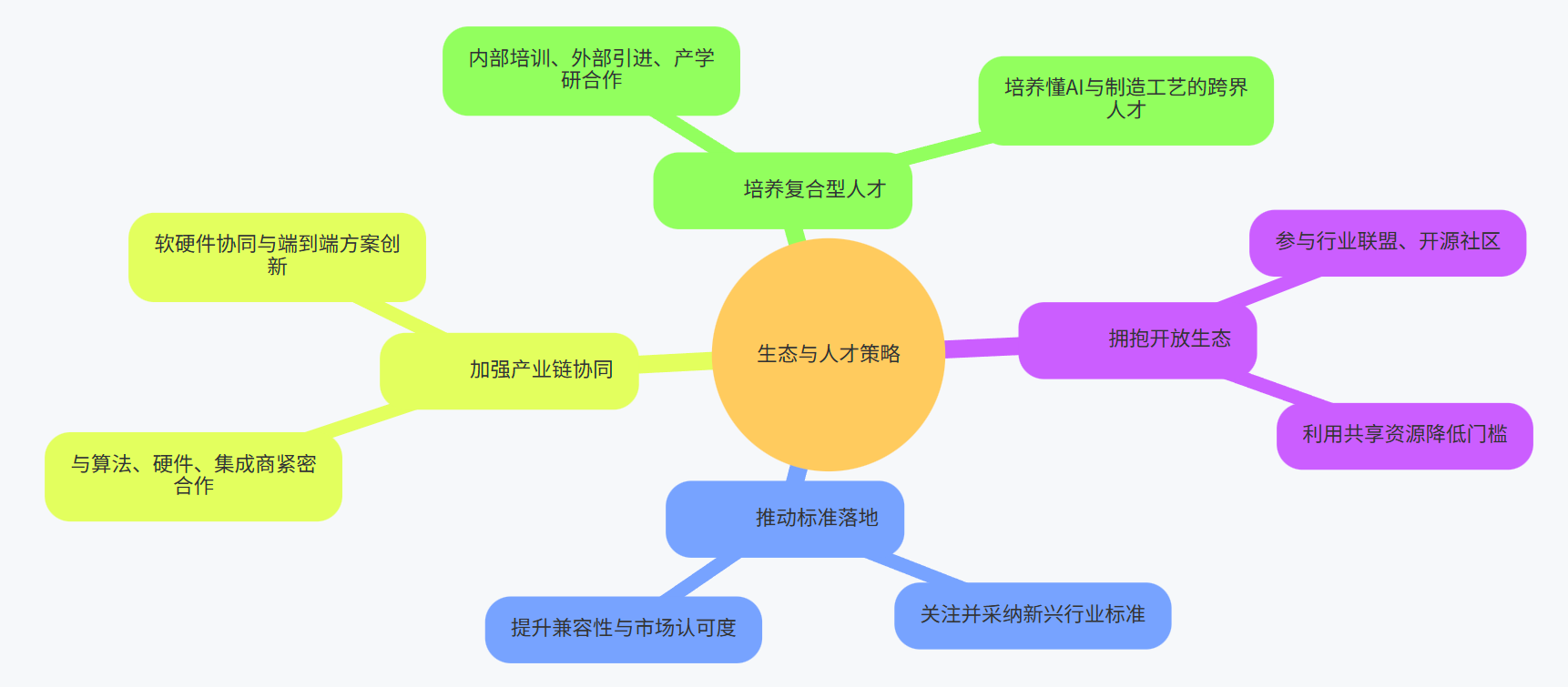
5. 生态与人才:开放合作,标准共建,人才培养:
- 拥抱开放生态:积极参与行业联盟和开源社区,利用共享资源(数据集、预训练模型、工具库)降低研发门槛。
- 推动标准落地:关注并采纳新兴的行业标准(数据、接口、性能、安全),提升方案的兼容性和市场认可度。
- 加强产业链协同:与算法提供商、硬件厂商、系统集成商建立紧密的合作关系,进行软硬件协同优化和端到端解决方案创新。
- 培养复合型人才:通过内部培训、外部引进、产学研合作等多种途径,培养既懂AI技术又熟悉制造工艺的跨界人才。
6.3 发展建议与展望
表:AI视觉质检发展建议与不同主体的行动方向
| 主体 | 建议方向 | 关键行动 |
|---|---|---|
| 政府 | 政策激励与生态构建 | 出台支持政策、引导标准制定、构建公平市场环境、完善AI伦理与数据安全法规 |
| 技术提供商 | 技术研发与产品优化 | 提升算法鲁棒性/可解释性/适应性、优化软硬件协同性能、降低产品使用门槛 |
| 系统集成商 | 行业深耕与方案创新 | 提升行业Know-How、增强AI整合能力、提供端到端解决方案 |
| 用户企业 | 数据基础与应用思维 | 投入数据建设、明确业务痛点、参与技术验证、建立长期AI策略 |
| 学术界 | 基础研究与产学合作 | 探索前沿技术、加强产业合作、加速科研成果转化 |
AI视觉质检作为赋能制造业智能化转型的关键技术,其发展需要政府、产业界、学术界的共同努力:
- 对政府而言:应继续出台支持AI在制造业应用的激励政策,引导行业标准的制定与推广,构建公平开放的市场环境,并关注AI伦理与数据安全法规的完善。
- 对产业界而言:
- 技术提供商应持续投入研发,提升算法的鲁棒性、可解释性和自适应能力,优化软硬件协同性能,降低产品使用门槛和成本。
- 系统集成商应提升行业Know-How和AI整合能力,提供更贴近用户需求的端到端解决方案。
- 最终用户企业应以更开放的心态拥抱AI技术,积极投入数据基础建设,明确业务痛点和价值诉求,并参与到技术验证和应用推广中。
- 对学术界而言:应加强基础理论研究(如小样本学习、持续学习、可信AI的底层机制),探索前沿技术(如多模态融合、神经拟态视觉),并与产业界紧密合作,加速科研成果转化。
展望未来(参考5.1-5.3节),随着AI算法的持续突破、边缘计算能力的指数级增长、云边端协同的日益成熟以及与5G、数字孪生等技术的深度融合,AI视觉质检必将超越当前的应用范畴,从单一的检测工具进化为驱动整个制造流程智能化、柔性化、自优化的核心引擎,为实现更高质量、更低成本、更具韧性的未来制造贡献关键力量。抓住这一历史机遇,积极布局和投入,将是制造企业在未来竞争中赢得优势的必然选择。