《Python星球日记》 第46天:决策树与随机森林
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:《Python星球日记》,限时特价订阅中ing
目录
- 一、前言
- 二、决策树算法原理
- 1. 决策树简介
- 2. 决策树的分裂准则
- (1) 信息熵与信息增益
- (2) 基尼不纯度
- 三、随机森林算法
- 1. 集成学习思想
- 2. 随机森林的优势
- 四、使用Scikit-learn实现决策树与随机森林
- 1. 决策树的实现
- 2. 随机森林的实现
- 3. 随机森林的超参数调优
- 五、实战案例:泰坦尼克生存预测
- 1. 数据加载与探索
- 2. 数据预处理
- 3. 训练决策树和随机森林模型
- 4. 模型评估与特征重要性分析
- 5. 结果分析与讨论
- 六、总结与拓展
- 1. 学习要点回顾
- 2. 实际应用场景
- 3. 拓展学习方向
- 4. 练习挑战
- 七、参考资料
👋 专栏介绍: Python星球日记专栏介绍(持续更新ing)
✅ 上一篇: 《Python星球日记》 第45天:KNN 与 SVM 分类器
欢迎来到Python星球的第46天!🪐
一、前言
今天我们将深入机器学习的森林世界,学习两个强大的分类与回归算法:决策树与随机森林。这两种算法凭借其直观性和高效性,在机器学习领域占据着重要地位。无论你是想预测客户行为,还是分析复杂数据模式,这些工具都将成为你数据科学工具箱中的得力助手!
让我们用一张图来直观感受决策树与随机森林的关系:
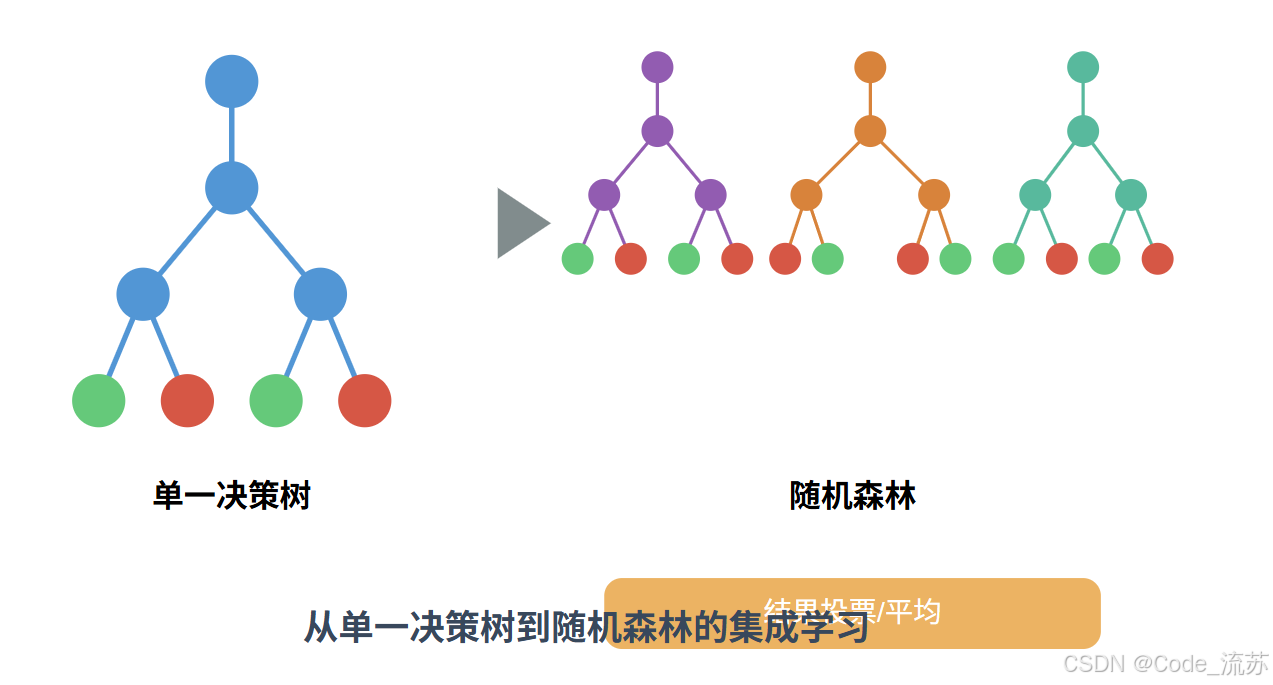
二、决策树算法原理
1. 决策树简介
决策树是一种树形结构的监督学习模型,它通过一系列问题将数据划分为不同类别。就像我们玩"20个问题"猜物品游戏一样,决策树通过提问来缩小可能性范围,最终给出预测结果。
决策树的核心思想可以用以下流程图表示:
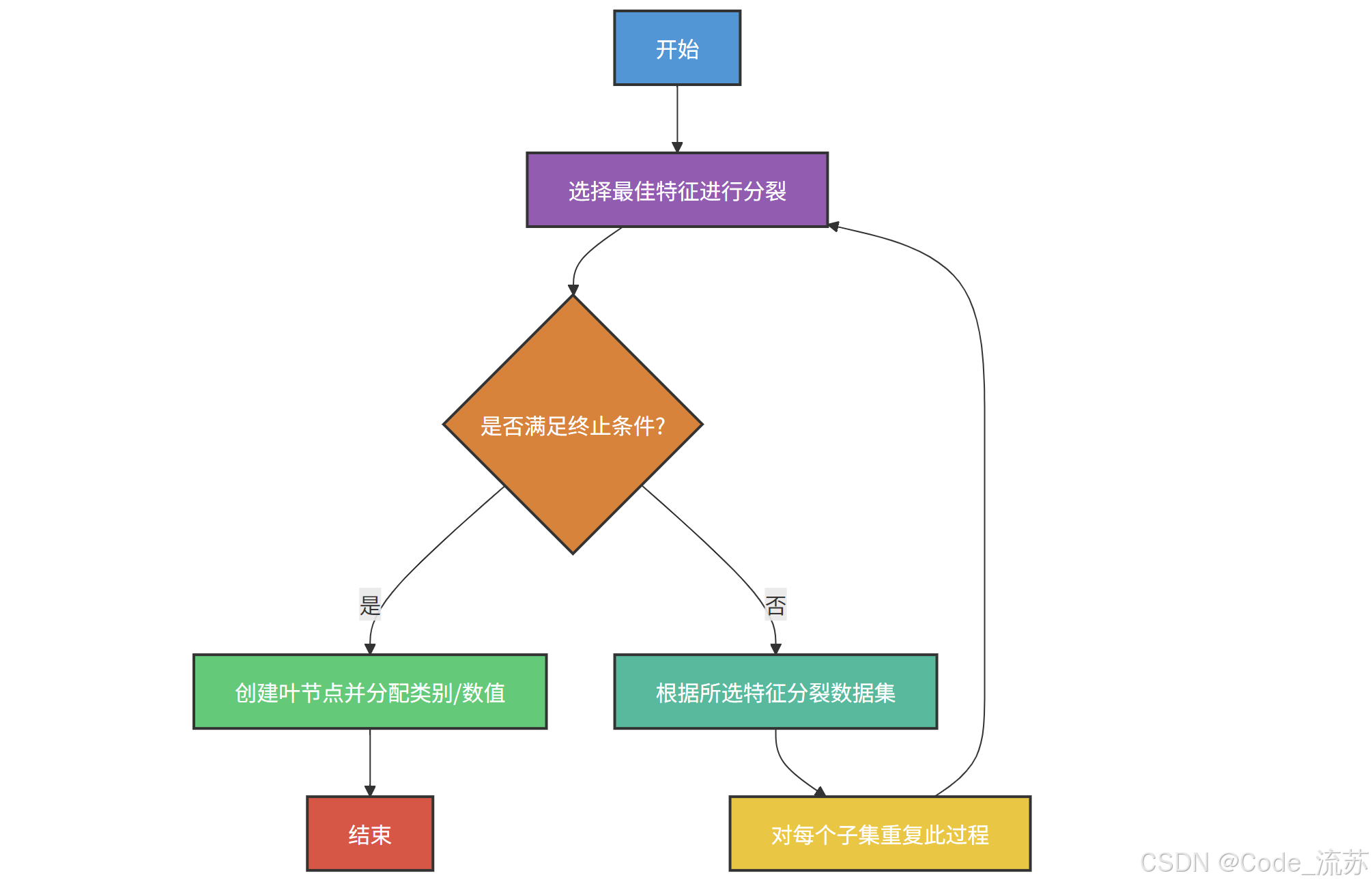
2. 决策树的分裂准则
决策树构建的关键问题是:如何选择最佳特征进行分裂?这就需要用到分裂准则。
(1) 信息熵与信息增益
信息熵(Information Entropy)是衡量数据集不确定性的指标。熵越高,数据的不确定性越大。
对于分类问题,信息熵的计算公式为:
Entropy(S) = -∑(pi * log2(pi))
其中,pi 是类别 i 在数据集中的比例。
信息增益(Information Gain)是父节点的熵与子节点熵的加权平均之间的差值,表示分裂后不确定性的减少程度:
Gain(S, A) = Entropy(S) - ∑((|Sv|/|S|) * Entropy(Sv))
其中,A 是用于分裂的特征,Sv 是特征 A 取值为 v 时的子集。
让我们通过一个视觉化说明来理解信息增益:
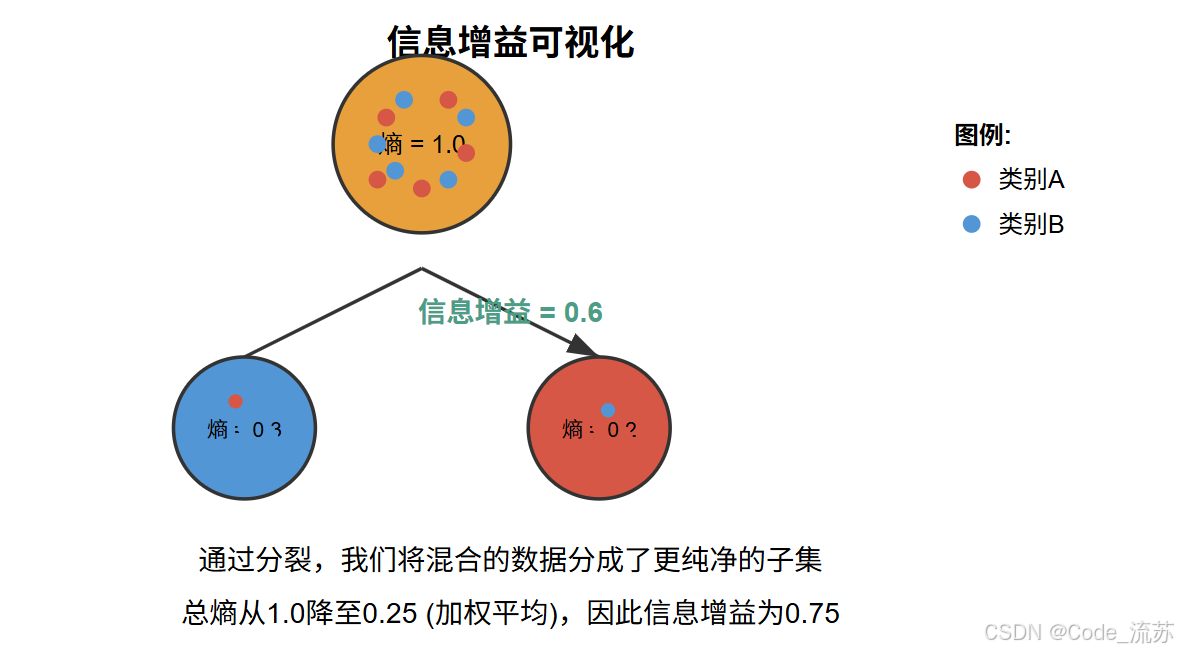
(2) 基尼不纯度
另一个常用的分裂准则是基尼不纯度(Gini Impurity),它衡量随机选择的样本被错误分类的概率。基尼不纯度越小,数据集的纯度越高。
对于分类问题,基尼不纯度的计算公式为:
Gini(S) = 1 - ∑(pi²)
其中,pi 是类别 i 在数据集中的比例。
基尼系数与信息增益的比较:
- 计算效率:基尼系数计算速度更快(不需要计算对数)
- 分裂倾向:信息增益更倾向于创建不平衡的树,基尼系数更倾向于创建平衡的树
- 使用场景:实际应用中差异往往不大,scikit-learn默认使用基尼系数
三、随机森林算法
1. 集成学习思想
集成学习(Ensemble Learning)是一种将多个基学习器(弱分类器)组合成一个更强大的学习器的方法。就像"三个臭皮匠,顶个诸葛亮",多个简单模型的组合往往能获得比单个复杂模型更好的性能。
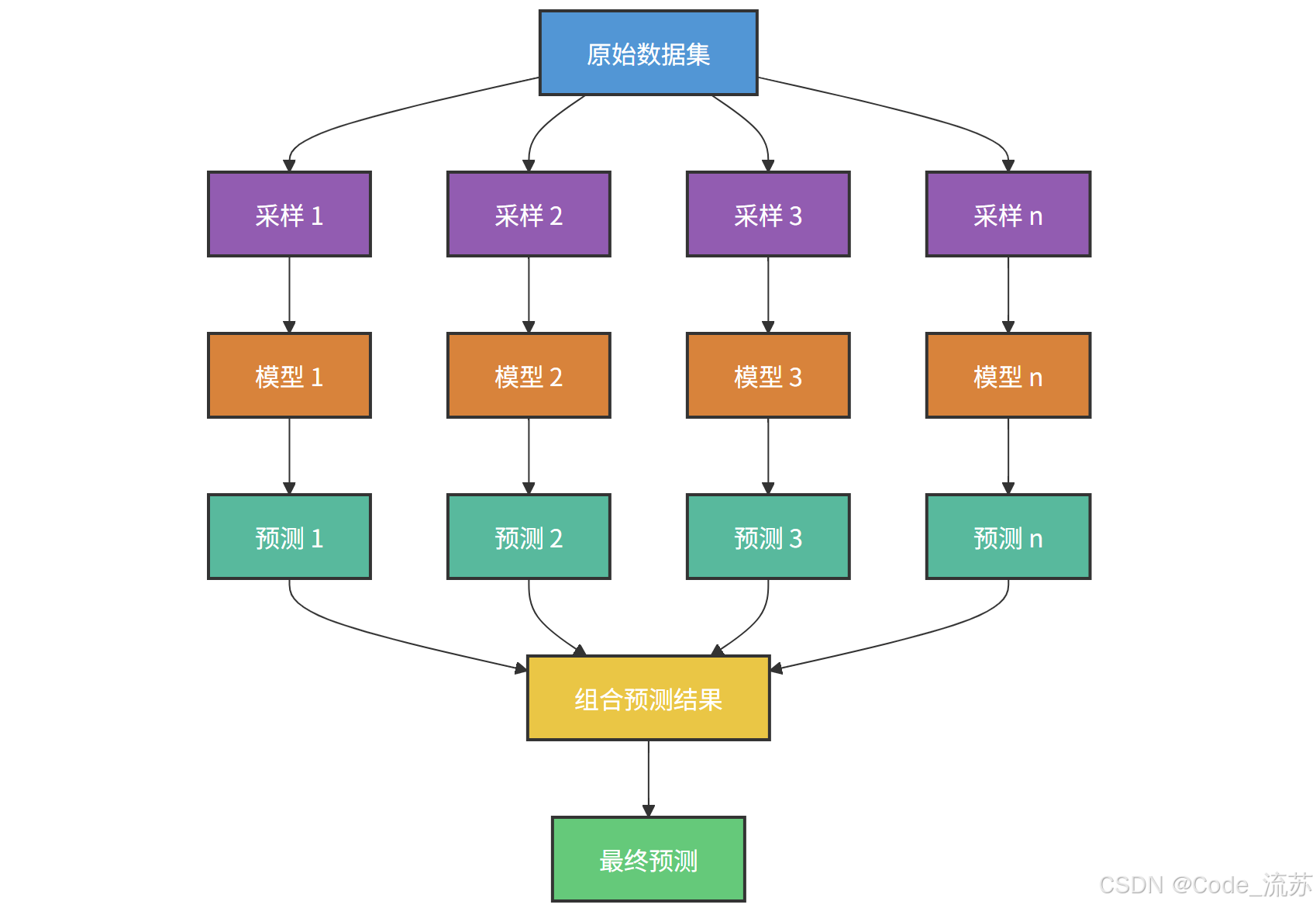
2. 随机森林的优势
随机森林(Random Forest)是一种基于决策树的集成学习方法,它通过构建多棵决策树,并将它们的结果进行整合(分类问题通过投票,回归问题通过平均)来得到最终预测。
随机森林具有以下优势:
- 准确性高:通过集成多个决策树的结果,降低了过拟合风险
- 鲁棒性强:对噪声和异常值不敏感
- 特征重要性:可以评估特征的重要程度
- 无需特征缩放:对特征的尺度不敏感
- 可处理高维数据:能够处理有大量特征的数据集
- 并行计算:各个决策树可以并行训练,提高效率
随机森林通过两种主要的随机性来确保多样性:
- 自助采样(Bootstrap Sampling):随机抽取样本构建每棵树
- 特征随机选择:在每个节点随机选择特征子集来寻找最佳分裂点

四、使用Scikit-learn实现决策树与随机森林
1. 决策树的实现
在Scikit-learn中,我们可以使用DecisionTreeClassifier和DecisionTreeRegressor分别实现分类和回归任务。下面是一个基本的分类决策树示例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建决策树分类器
clf = DecisionTreeClassifier(criterion='gini', # 使用基尼系数max_depth=3, # 树的最大深度min_samples_split=2, # 分裂内部节点所需的最小样本数random_state=42)# 训练模型
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"决策树准确率: {accuracy:.4f}")
2. 随机森林的实现
随机森林在Scikit-learn中通过RandomForestClassifier和RandomForestRegressor实现:
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, # 树的数量max_depth=3, # 树的最大深度min_samples_split=2, # 分裂内部节点所需的最小样本数random_state=42)# 训练模型
rf_clf.fit(X_train, y_train)# 预测
rf_y_pred = rf_clf.predict(X_test)# 计算准确率
rf_accuracy = accuracy_score(y_test, rf_y_pred)
print(f"随机森林准确率: {rf_accuracy:.4f}")# 特征重要性
feature_importance = rf_clf.feature_importances_
for i, importance in enumerate(feature_importance):print(f"特征 {iris.feature_names[i]}: {importance:.4f}")
3. 随机森林的超参数调优
随机森林有多个重要的超参数,可以通过网格搜索等方法进行调优:
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'n_estimators': [50, 100, 200],'max_depth': [None, 5, 10],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4]
}# 创建网格搜索对象
grid_search = GridSearchCV(RandomForestClassifier(random_state=42),param_grid=param_grid,cv=5,scoring='accuracy')# 执行网格搜索
grid_search.fit(X_train, y_train)# 最佳参数
print("最佳参数:", grid_search.best_params_)# 最佳模型
best_rf = grid_search.best_estimator_# 使用最佳模型预测
best_pred = best_rf.predict(X_test)
best_accuracy = accuracy_score(y_test, best_pred)
print(f"调优后的随机森林准确率: {best_accuracy:.4f}")
五、实战案例:泰坦尼克生存预测
接下来,我们将使用泰坦尼克号乘客数据集,构建一个能够预测乘客是否能够在这场灾难中幸存的模型。
1. 数据加载与探索
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 加载数据
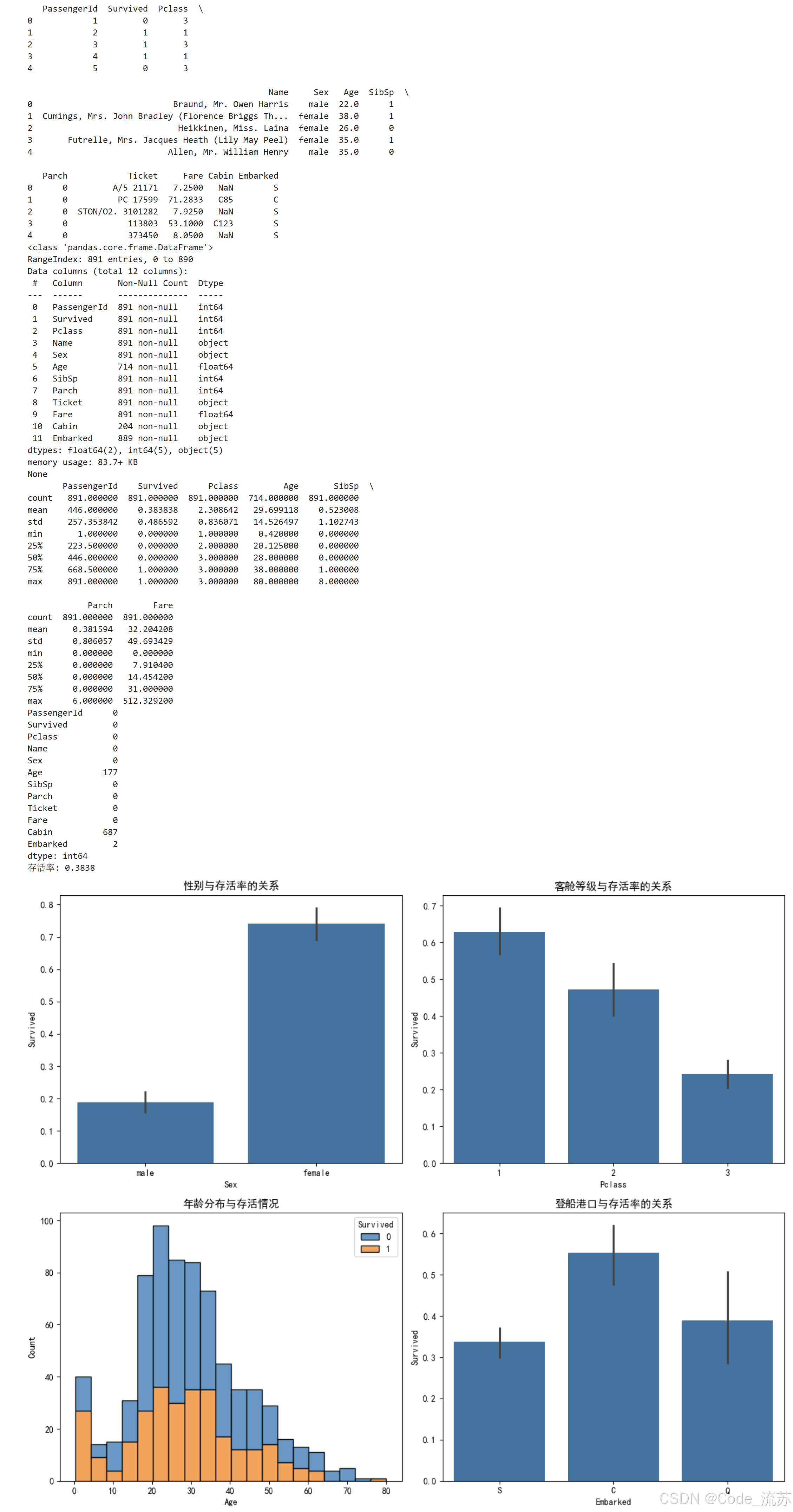
titanic_data = pd.read_csv('https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv')# 查看数据前几行
print(titanic_data.head())# 数据基本信息
print(titanic_data.info())# 统计描述
print(titanic_data.describe())# 检查缺失值
print(titanic_data.isnull().sum())# 查看存活率
print(f"存活率: {titanic_data['Survived'].mean():.4f}")# 可视化不同特征与存活率的关系
plt.figure(figsize=(12, 10))# 性别与存活率
plt.subplot(2, 2, 1)
sns.barplot(x='Sex', y='Survived', data=titanic_data)
plt.title('性别与存活率的关系')# 客舱等级与存活率
plt.subplot(2, 2, 2)
sns.barplot(x='Pclass', y='Survived', data=titanic_data)
plt.title('客舱等级与存活率的关系')# 年龄分布与存活情况
plt.subplot(2, 2, 3)
sns.histplot(data=titanic_data, x='Age', hue='Survived', multiple='stack')
plt.title('年龄分布与存活情况')# 登船港口与存活率
plt.subplot(2, 2, 4)
sns.barplot(x='Embarked', y='Survived', data=titanic_data)
plt.title('登船港口与存活率的关系')plt.tight_layout()
plt.show()
2. 数据预处理
# 选择特征
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked']
X = titanic_data[features].copy()
y = titanic_data['Survived']# 处理缺失值
# 年龄缺失值用中位数填充
X['Age'].fillna(X['Age'].median(), inplace=True)
# 登船港口缺失值用最频繁值填充
X['Embarked'].fillna(X['Embarked'].mode()[0], inplace=True)# 类别特征编码
X['Sex'] = X['Sex'].map({'male': 0, 'female': 1})
# 创建登船港口的独热编码
embarked_dummies = pd.get_dummies(X['Embarked'], prefix='Embarked')
X = pd.concat([X, embarked_dummies], axis=1)
X.drop('Embarked', axis=1, inplace=True)# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
3. 训练决策树和随机森林模型
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
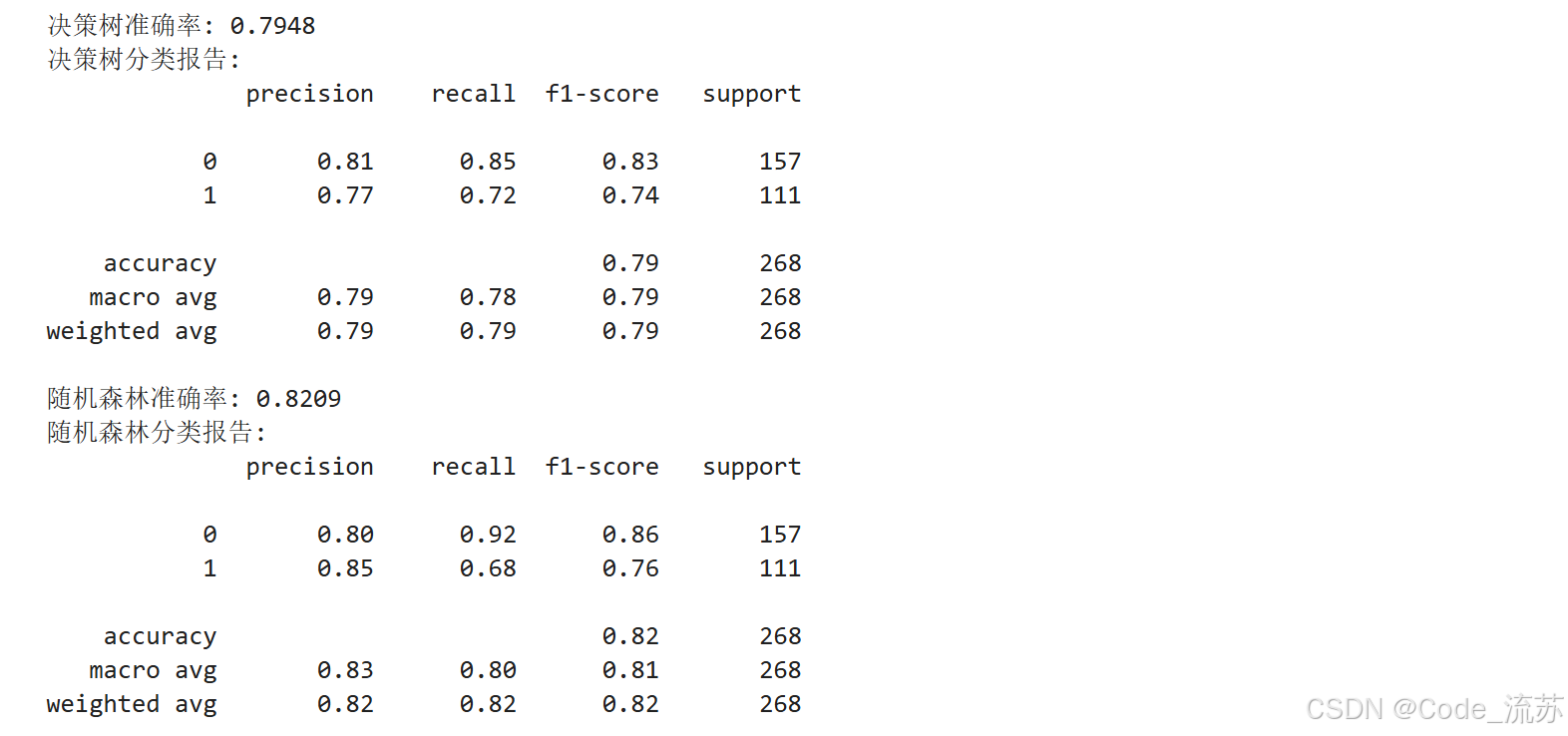
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix# 训练决策树模型
dt_model = DecisionTreeClassifier(max_depth=5, random_state=42)
dt_model.fit(X_train, y_train)# 决策树预测
dt_y_pred = dt_model.predict(X_test)
dt_accuracy = accuracy_score(y_test, dt_y_pred)
print(f"决策树准确率: {dt_accuracy:.4f}")
print("决策树分类报告:")
print(classification_report(y_test, dt_y_pred))# 训练随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=42)
rf_model.fit(X_train, y_train)# 随机森林预测
rf_y_pred = rf_model.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_y_pred)
print(f"随机森林准确率: {rf_accuracy:.4f}")
print("随机森林分类报告:")
print(classification_report(y_test, rf_y_pred))
4. 模型评估与特征重要性分析
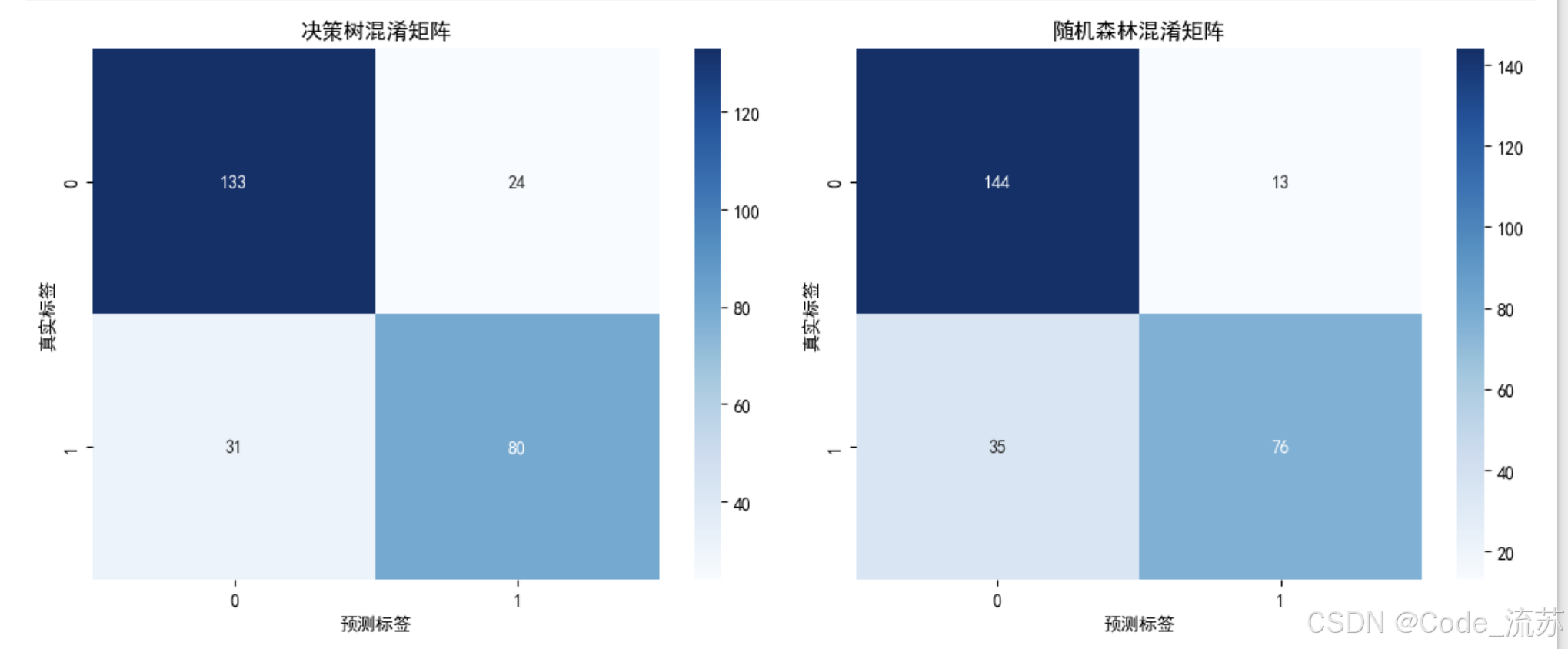
# 混淆矩阵可视化
plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)
cm = confusion_matrix(y_test, dt_y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('决策树混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')plt.subplot(1, 2, 2)
cm = confusion_matrix(y_test, rf_y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('随机森林混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')plt.tight_layout()
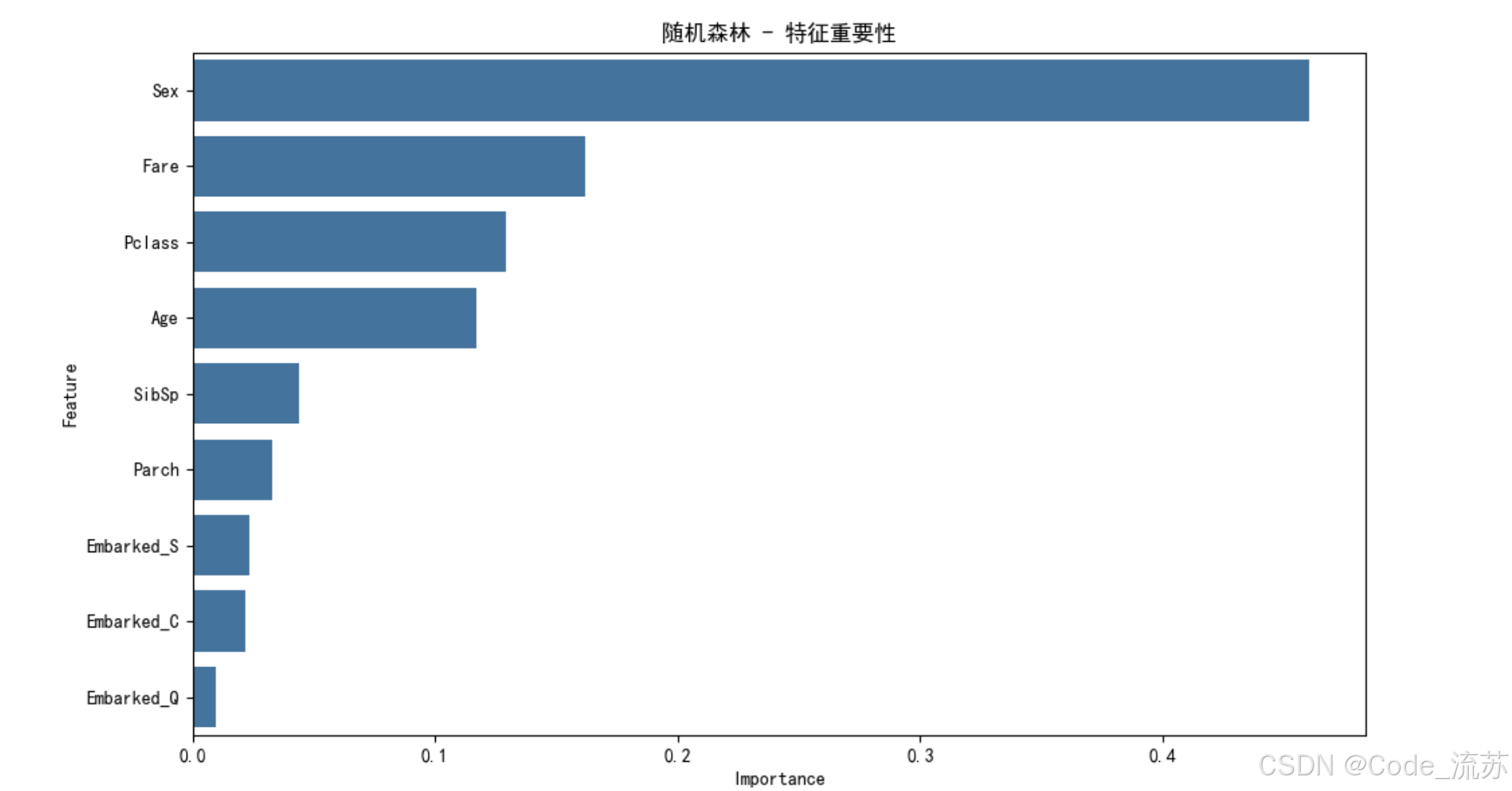
plt.show()# 特征重要性分析
feature_names = X.columns
feature_importance = rf_model.feature_importances_# 创建特征重要性DataFrame
importance_df = pd.DataFrame({'Feature': feature_names,'Importance': feature_importance
})
importance_df = importance_df.sort_values('Importance', ascending=False)# 可视化特征重要性
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('随机森林 - 特征重要性')
plt.tight_layout()
plt.show()print("特征重要性排名:")
for index, row in importance_df.iterrows():print(f"{row['Feature']}: {row['Importance']:.4f}")

5. 结果分析与讨论
通过上述分析,我们可以发现几个有趣的结论:
- 随机森林的准确率通常高于单一决策树,这证实了集成学习的优势。
- 性别(Sex)和客舱等级(Pclass)是最重要的特征,与历史记载"妇女和儿童优先"的救生原则相符。
- 年龄(Age)也是一个重要特征,儿童的生存率较高。
- 客舱票价(Fare)反映了乘客的社会地位,票价高的乘客通常有更多获救机会。
这些发现与泰坦尼克号沉船事件的历史记载高度一致,表明我们的模型成功捕捉到了影响乘客生存的关键因素。
六、总结与拓展
1. 学习要点回顾
在本文中,我们学习了:
- 决策树的原理与分裂准则(信息增益和基尼系数)
- 随机森林的集成学习思想与优势
- 使用Scikit-learn实现决策树和随机森林模型
- 通过泰坦尼克号数据集进行实战演练
2. 实际应用场景
决策树和随机森林在实际中有广泛应用:
- 金融风险评估:预测贷款违约风险
- 医疗诊断:辅助医生进行疾病诊断
- 推荐系统:预测用户偏好
- 图像分类:识别图像中的物体
- 异常检测:识别欺诈交易
3. 拓展学习方向
如果你对决策树和随机森林感兴趣,可以进一步探索:
- 提升法(Boosting):如 AdaBoost, Gradient Boosting, XGBoost 等
- 剪枝技术:防止决策树过拟合的方法
- 特征工程:如何为树模型选择和创建更好的特征
- 不平衡数据处理:处理类别不平衡数据集的策略
4. 练习挑战
- 尝试使用其他数据集(如Iris, Wine等)应用决策树和随机森林
- 实现交叉验证来更准确地评估模型性能
- 对比决策树、随机森林和其他机器学习算法的性能
- 尝试可视化一个简单的决策树结构,理解其决策路径
七、参考资料
- Scikit-learn官方文档:决策树和随机森林
- 《机器学习》,周志华著,清华大学出版社
- 《Python机器学习》,Sebastian Raschka著
- Kaggle泰坦尼克号竞赛:Titanic - Machine Learning from Disaster
在机器学习的旅程中,决策树和随机森林是非常直观且强大的工具。希望通过今天的学习,你已经掌握了这些算法的核心概念和实践技能。理论知识结合实际练习才能真正提升你的数据科学能力。继续探索,在Python星球上的旅程才刚刚开始!
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
如果你对今天的内容有任何问题,或者想分享你的学习心得,欢迎在评论区留言讨论!