MapReduce架构-打包运行
(一)maven打包
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序(例如:jar包),并发运行在一个Hadoop集群上。
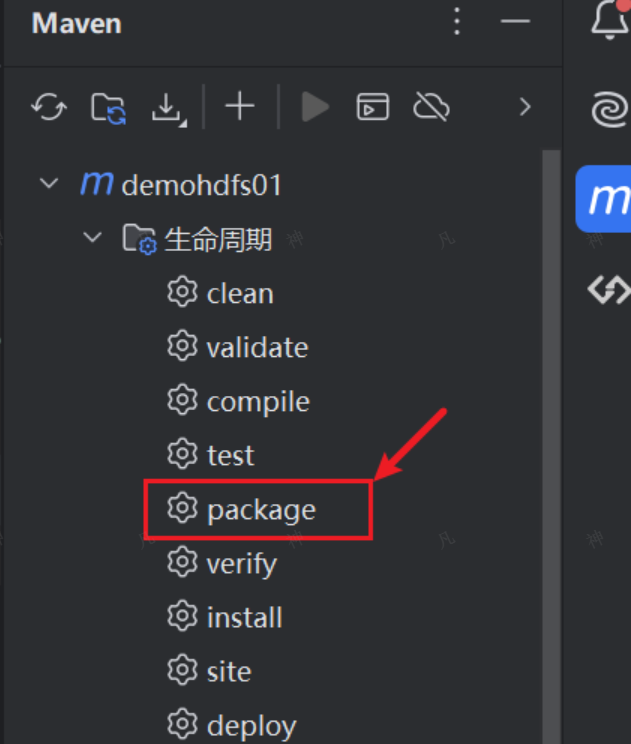
在pom.xml中,补充如下配置,它用来设置打包的java 版本。
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
打包成功之后的效果如下:
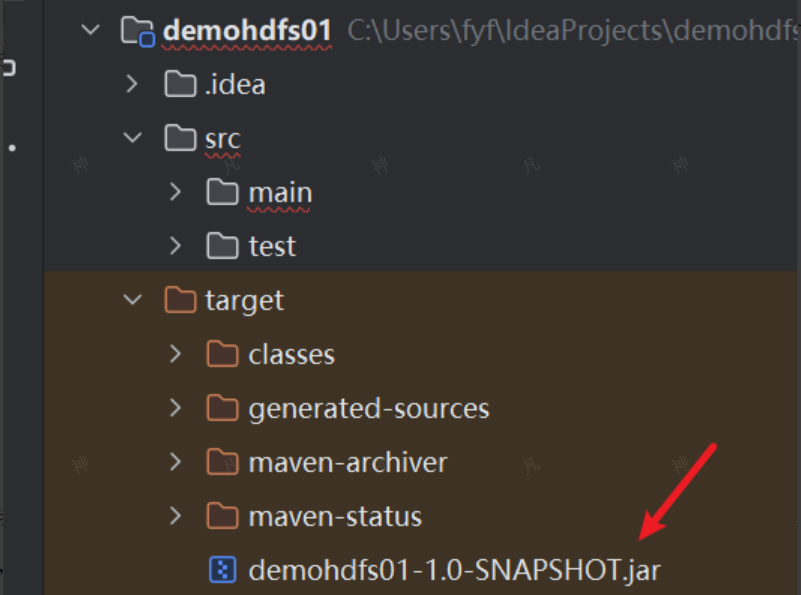
(二)设置编译版本
我们集群上安装的java环境是1.8的,那么我们生成的代码也必须是这个版本的,否则,就会无法运行。
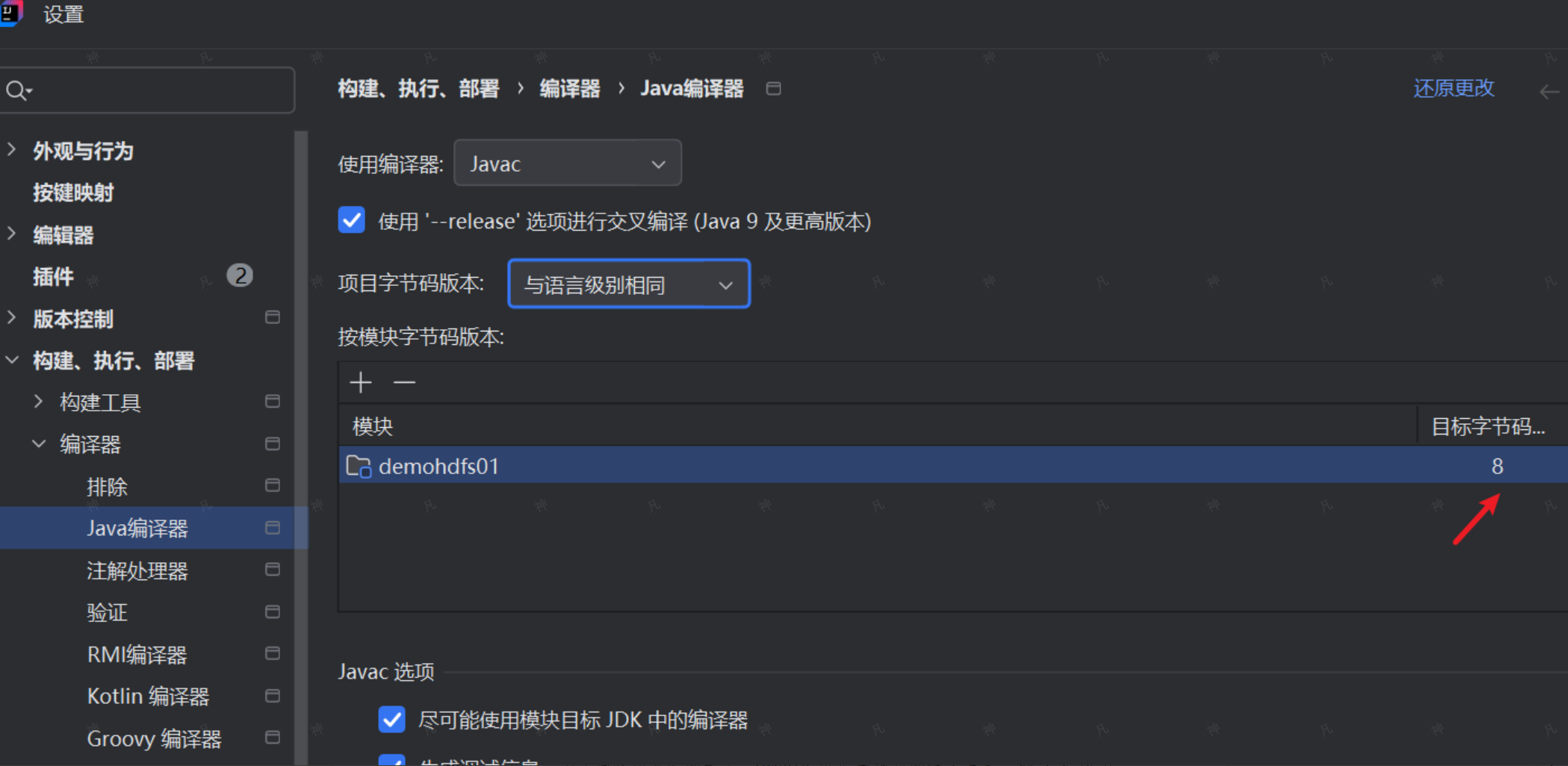
关于java版本的说明如下:
在 Java 7 之前,Java 的版本命名一直是 1.x 的形式,例如 1.6、1.7。从 Java 7 开始,为了简化版本号的表示,Oracle 开始采用新的命名方式,将 1.x 改为 x。所以Java 8 和 1.8 是同一个版本,只是命名方式不同。
从 Java 9 开始,版本号的命名方式完全统一为 x,例如 Java 9、Java 11、Java 17 等,不再使用 1.x 的形式。
如果你看到 Java 8 或 1.8,它们指的是同一个版本,没有任何区别。
(三)修改代码,设置执行环境和文件路径
我们集群上安装的java环境是1.8的,那么我们生成的代码也必须是这个版本的,否则,就会无法运行。
打开代码,找到driver类,并修改如下:
conf.set("fs.defaultFS", "hdfs://hadoop100:8020"); // 新增加一句
FileInputFormat.setInputPaths(job, new Path("/wcinput")); // 修改
FileOutputFormat.setOutputPath(job, new Path("/output1"));
确保集群中有/wcinput目录,并且下面有记事本文件中的单词。
确保集群中没有output1这个目录,因为它应该是要被动态创建出来的。
(四)上传到节点运行
使用finalshell上到任意节点,例如hadoop100上的/opt下,。
然后通过命令来执行执行WordCount程序,注意要写Driver类的全名
$ hadoop jar /opt/wc.jarcom.root.mapreduce.wordcount.WordCountDriver
运行结束之后,在ui中查看yarn运行效果。
第二课时
(五)修改执行参数
在上面的代码中,我们的程序只能完成固定目录下的功能。现在希望它能处理不同的目录。
修改代码,让程序能指定要执行的输入目录和要保存结果的输出目录。
修改driver类的代码,更新输入和输入路径。
// 6. 设置输入和输出路径
路径为程序的第一个参数,第二个参数
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
这里的args[0]和args[1]是程序运行时的两个参数。
改完代码之后,要重新打包,并上传到某台节点上运行。