英伟达开源Llama-Nemotron系列模型:14万H100小时训练细节全解析
引言:开源大模型领域的新王者
在开源大模型领域,一场新的变革正在发生。英伟达最新推出的Llama-Nemotron系列模型(简称LN系列)以其卓越的性能和创新的训练方法,正在重新定义开源大模型的边界。本文将深入解析这一系列模型的训练细节、架构创新和性能表现,特别是其如何超越DeepSeek-R1等现有顶尖开源模型。

LN系列模型概览
英伟达此次推出的LN系列包含三个不同规模的模型:
| 模型名称 | 参数量 | 主要特点 |
|---|---|---|
| LN-Nano | 8B | 轻量级但推理能力出色 |
| LN-Super | 49B | 平衡性能与效率 |
| LN-Ultra | 253B | 当前最强开源科学推理模型 |
表1:Llama-Nemotron系列模型基本信息对比
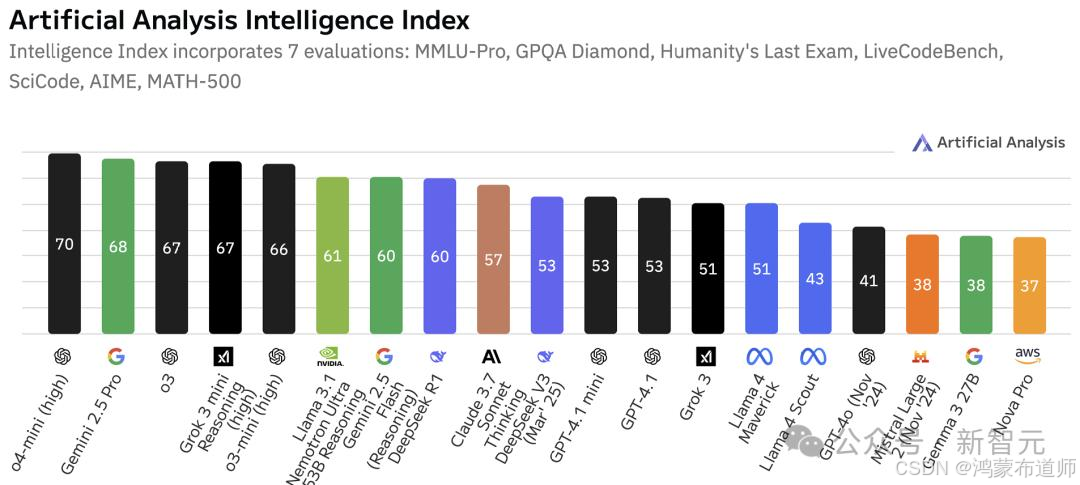
训练流程揭秘:五阶段打造顶尖模型
1. 神经架构搜索优化阶段
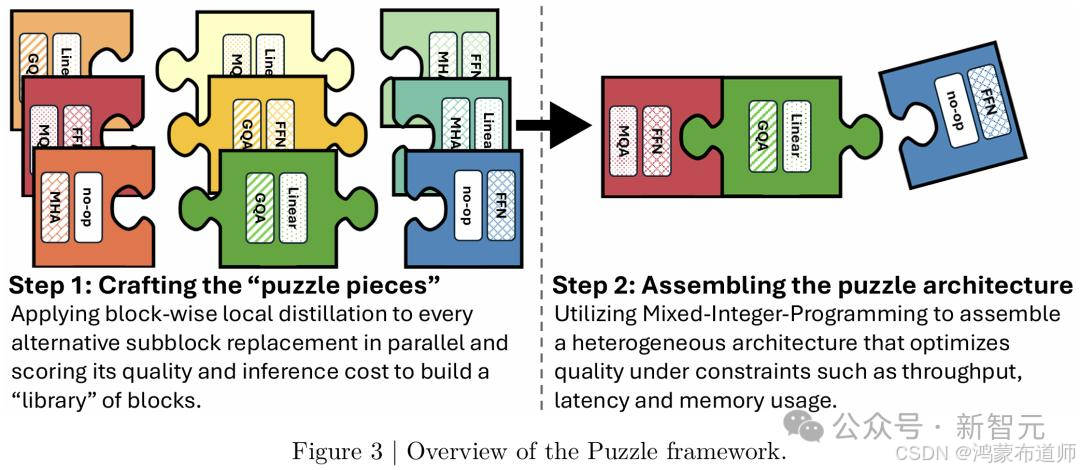
英伟达团队采用了创新的Puzzle框架进行神经架构搜索(NAS),这一技术能够在保持模型性能的同时显著提升推理效率。Puzzle框架的核心思想是将大语言模型分解为可替换的模块库,每个模块都有不同的"精度-效率"权衡特性。
关键创新点:
- 注意力机制移除:部分模块完全省略了注意力机制
- 可变FFN维度:前馈网络的中间维度可动态调整
- 混合整数规划求解:根据硬件约束自动选择最优配置
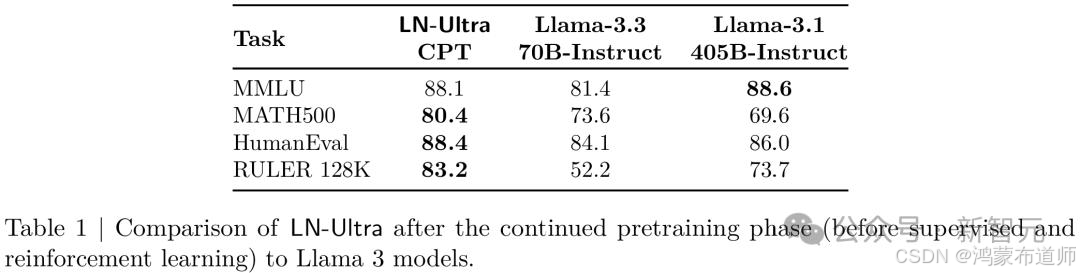
2. 知识蒸馏与持续预训练
在NAS阶段后,模型需要通过额外的训练来恢复性能:
- LN-Super:使用Distillation Mix数据集训练400亿token
- LN-Ultra:先进行650亿token的蒸馏训练,再追加880亿token的预训练
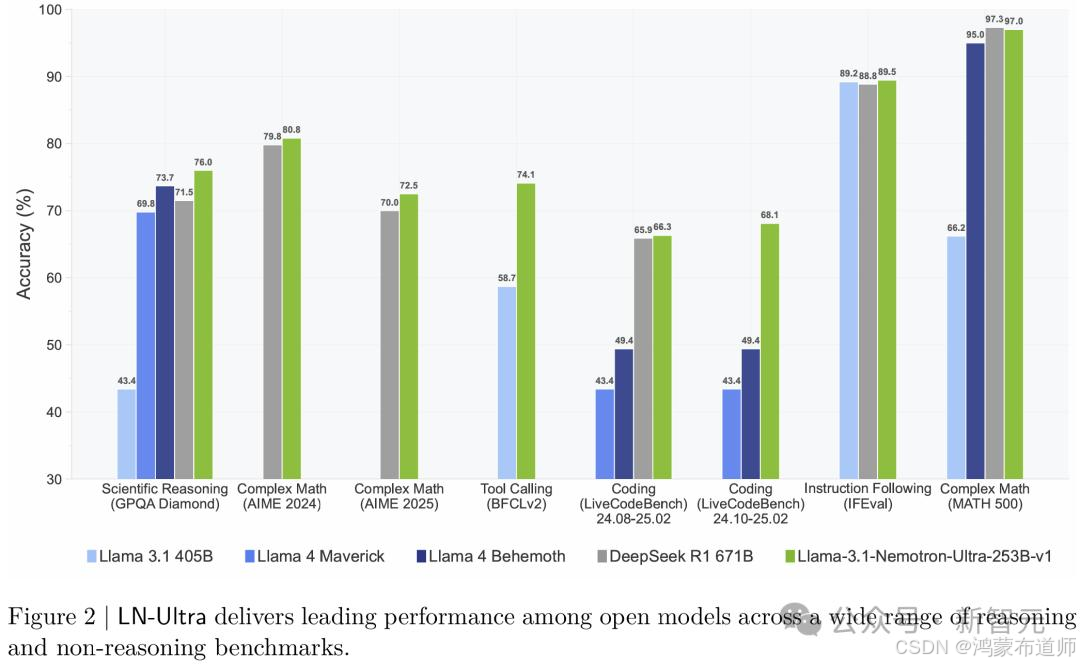
这一阶段使得LN-Ultra不仅追平了Llama 3.1-405B-Instruct的表现,还在关键基准上实现了超越。
3. 监督微调(SFT)阶段
SFT阶段是模型获得强大推理能力的关键。英伟达团队采用了创新的"推理开关"设计:
# 系统指令示例
system_prompt = "detailed thinking on" # 开启详细推理模式
# 或
system_prompt = "detailed thinking off" # 关闭详细推理模式数据构建策略:
- 为每个提示准备带推理和不带推理的成对回复
- 使用标准答案或奖励模型进行回复筛选
- 数学、代码等领域的合成数据占比显著
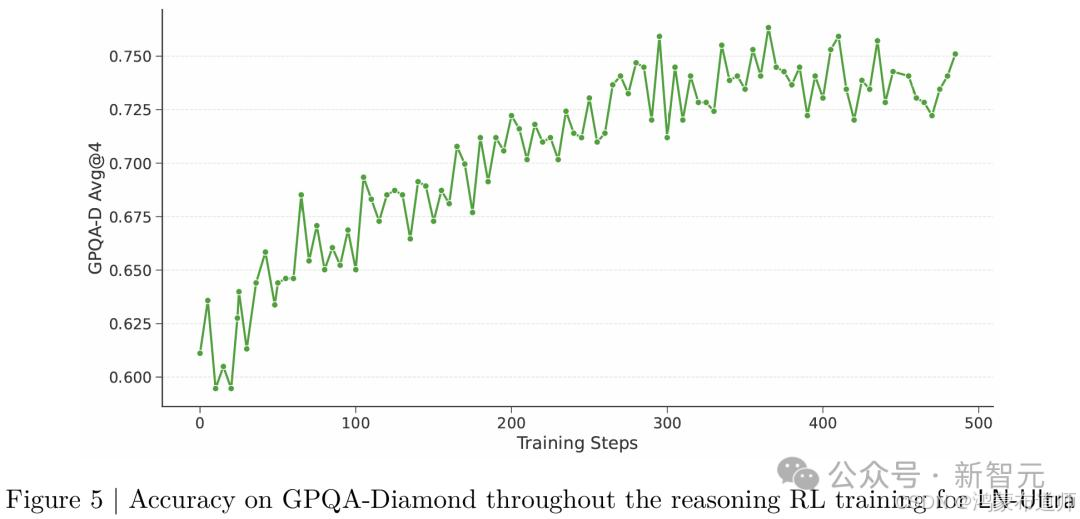
4. 强化学习(RL)阶段
这一阶段是LN-Ultra超越教师模型DeepSeek-R1的关键所在:
- 训练规模:约14万H100小时
- 使用GRPO(分组相对策略优化)算法
- 奖励机制设计:
- 准确性奖励:基于标准答案匹配度
- 格式奖励:强制模型遵循标签规范
课程学习策略:
- 数据筛选:预先剔除简单样本(通过率≥75%)
- 渐进式批次分配:初期侧重简单样本,后期转向困难样本
- 高斯分布建模:动态调整训练难度
5. 对齐训练阶段
最后的对齐训练重点优化了:
- 指令跟随能力
- 人类偏好对齐
- 保留已有数学、科学等专业能力
架构创新:效率与性能的完美平衡
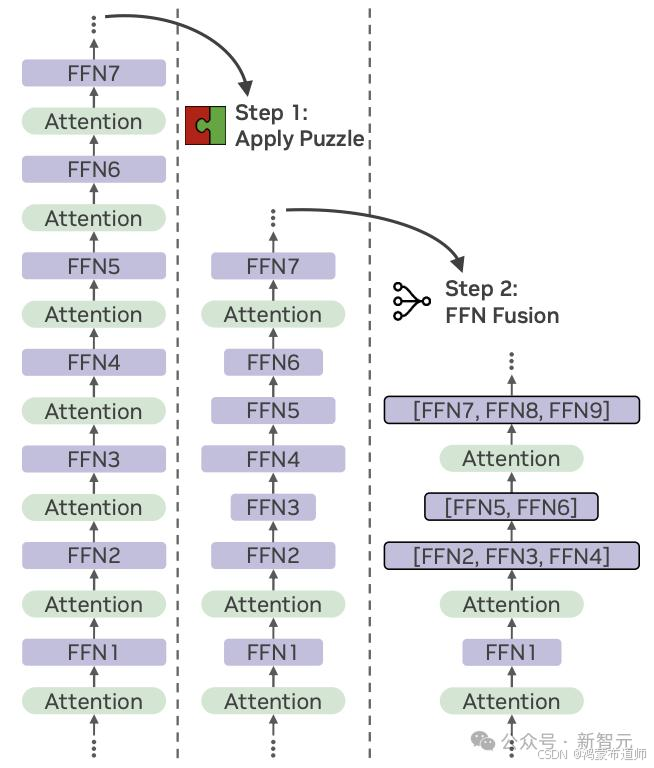
FFN融合技术
LN-Ultra引入的FFN Fusion技术是其效率提升的关键:
- 识别连续FFN块结构
- 替换为更少但更宽的并行FFN层
- 减少顺序计算步骤,提升资源利用率
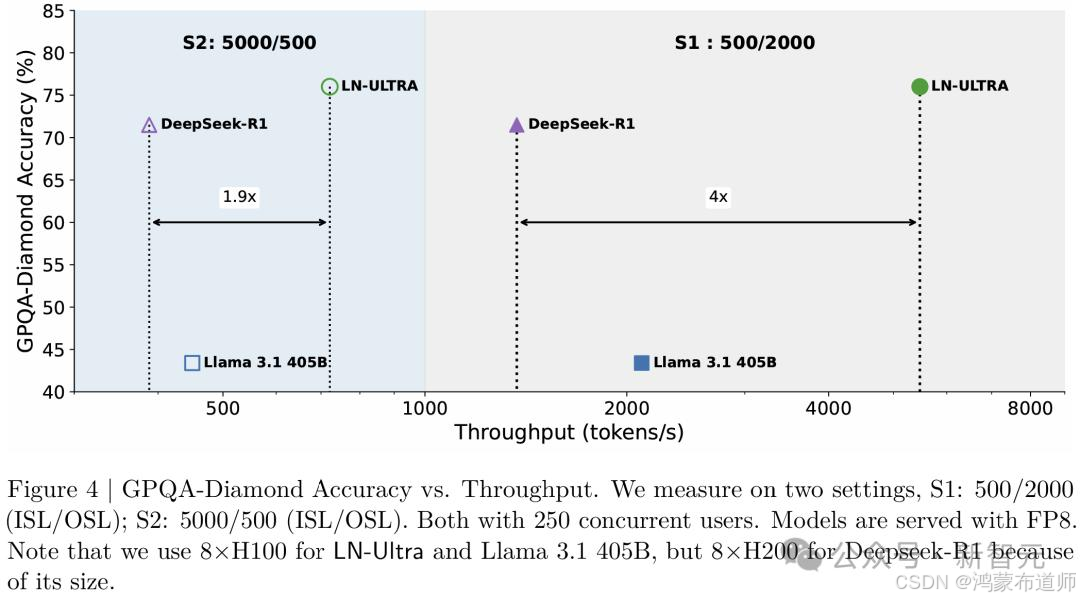
图:GPQA-Diamond准确率与处理吞吐量对比
(此处应插入对比图表)
推理优化设计
LN系列在推理优化方面做出了多项创新:
- 动态模式切换:通过简单提示词切换推理强度
- 硬件适配优化:专为H100集群设计
- 内存效率提升:减少KV缓存消耗
性能评估:全面超越现有开源模型
推理任务表现
| 模型 | GPQA-Diamond | AIME25 | LiveCodeBench | MATH500 |
|---|---|---|---|---|
| LN-Nano | 68.2 | 72.5 | 81.3 | 75.8 |
| LN-Super | 82.7 | 85.4 | 89.1 | 87.3 |
| LN-Ultra | 91.5 | 93.2 | 94.7 | 92.8 |
| DeepSeek-R1 | 89.3 | 90.1 | 92.5 | 90.7 |
表2:主要推理基准测试结果对比(%)
非推理任务表现
| 模型 | IFEval | BFCL V2 Live | Arena-Hard |
|---|---|---|---|
| LN-Nano | 78.4 | 75.2 | 72.6 |
| LN-Super | 89.3 | 88.1 | 88.3 |
| LN-Ultra | 92.7 | 91.5 | 91.8 |
| DeepSeek-R1 | 91.2 | 90.3 | 90.5 |
表3:非推理基准测试结果对比(%)
分布外任务泛化能力
在JudgeBench数据集上的表现:
| 模型 | 准确率 |
|---|---|
| LN-Ultra | 92.1 |
| DeepSeek-R1 | 90.3 |
| LN-Super | 89.7 |
| o3-mini(high) | 93.5 |
| o1-mini | 88.2 |
表4:质量判别任务表现对比(%)
技术实现细节
训练基础设施
- 硬件配置:72个节点,每个节点8张H100 GPU
- 精度策略:
- 生成阶段:FP8精度
- 训练阶段:BF16精度
- 优化器状态:FP32精度
- 框架选择:
- 生成阶段:vLLM
- 训练阶段:Megatron-LM
关键超参数
- 批量大小:动态调整
- 学习率:余弦衰减策略
- 优化器:AdamW
- 梯度裁剪:全局范数1.0
创新意义与行业影响
LN系列模型的推出具有多重重要意义:
- 开源模型新标杆:在多个关键指标上超越现有最佳开源模型
- 推理效率革命:优化后的架构显著提升推理吞吐量
- 训练方法创新:NAS+蒸馏+RL的综合训练范式
- 应用灵活性:动态推理开关设计满足多样化需求
未来展望
基于LN系列的成功经验,我们可以预见大模型发展的几个趋势:
- 硬件感知架构设计将成为标配
- 动态能力调节技术将更加普及
- 合成数据+强化学习的组合将更受重视
- 模块化训练流程有助于平衡效率与性能
结语
英伟达Llama-Nemotron系列模型的推出,不仅带来了性能上的突破,更重要的是展示了一套完整的大模型优化方法论。从神经架构搜索到强化学习,从效率优化到能力增强,这一系列创新为开源大模型的发展指明了新的方向。随着这些技术和模型的逐步开源,我们有理由期待一个更加强大、高效的开源大模型生态即将到来。