uDistil-Whisper:低数据场景下基于无标签数据过滤的知识蒸馏方法
uDistil-Whisper: Label-Free Data Filtering for Knowledge Distillation in Low-Data Regimes
会议:2025年NAACL
机构:卡内基梅降大学
Abstract
近期研究通过伪标签(pseudo-labels)将Whisper的知识蒸馏到小模型中,在模型体积减小50%的同时展现出优异性能,最终得到高效、轻量的专用模型。然而,基于伪标签的蒸馏关键步骤需筛选高质量预测结果并仅用于训练,这一过程需依赖真实标签(ground truth)过滤低质量样本,导致方法受限于人工标注数据。此外,传统蒸馏需大量数据,限制了其在低资源场景的应用。为此,我们提出了一种无需任何标注数据的蒸馏框架。实验表明,我们最优的蒸馏模型比教师模型降低5-7个词错率(WER),性能与监督式数据过滤方法相当或更优。当扩大数据规模时,我们的模型显著优于所有零样本和监督式模型,同时在计算和内存效率上提升25-50%,且性能保持不逊于甚至优于教师模型。
1 Introduction
为了实现自动语音识别(ASR)技术的民主化,多语言模型受到了广泛关注(Pratap等人,2023;Radford等人,2023;Communication等人,2023;Zhang等人,2023)。得益于庞大的参数量和训练数据,这些强大系统能够同时转录数百种语言。然而,与英语等高资源语言相比,低资源语言的性能往往相对落后(Radford等人,2023)。例如,OpenAI最新的ASR模型Whisper-large-v3在英语和西班牙语上的词错率(WER)为个位数,但在东亚和非洲语言上表现明显较差(Talafha等人,2023,2024)。虽然这些多语言模型在阿拉伯语上的报告性能并不算太低,但需要强调的是,它并未充分准确反映阿拉伯语族不同变体的多样性(Abdul-Mageed等人,2020)。除了性能差异外,多语言模型的计算强度极高,因此并非对所有人都同样可及。
为了缓解这一问题,知识蒸馏已成为多项研究的首选方法(Hinton等人,2015;Yang等人,2023;Sanh等人,2020;Frantar等人,2022)。知识蒸馏已被证明在减小模型规模方面非常有效,从而降低计算和内存需求,同时保持与大型教师模型相当的性能。例如,Gandhi等人(2023)和Waheed等人(2024)分别展示了其在英语和阿拉伯语上的有效性。然而,这些工作的一个重大局限是它们依赖真实标签来过滤教师模型生成的低质量伪标签——这种资源往往稀缺,尤其是对于低资源语言。此外,Waheed等人(2024)表明,使用未过滤的数据训练会导致次优性能。这种对标注数据的依赖凸显了知识蒸馏中无监督数据过滤方法的必要性,使得蒸馏模型在不依赖任何真实标签的情况下表现更好。
在这项工作中,我们提出了不依赖过滤伪标签的教师模型知识蒸馏框架。我们的方法实现了与监督蒸馏相当的性能,并优于未过滤的伪标签蒸馏。我们的贡献如下:
• 我们探索了多种无监督方法来过滤低质量伪标签,消除了蒸馏过程中对标注数据的需求。
• 我们评估了蒸馏模型的性能,其有效优于教师模型5-7个WER点,并将现有设置扩展到包括阿拉伯语和斯瓦希里语的新数据集。
• 我们分析了最佳指标在检测低质量伪标签示例方面的有效性,对于WER>20的示例,AUC达到0.77至0.82。
本文的组织结构如下:第2节回顾现有文献,第3节介绍知识蒸馏及我们的方法,第4节详述实验细节,第5节深入分析实验结果,第6节总结并展望未来工作,第7节指出本研究的局限性。
2 Related Work
随着语音基础模型在数据和模型规模上的扩展,已经产生了能够处理广泛语音任务的系统(Pratap等人,2023;Zhang等人,2023;Radford等人,2023;Communication等人,2023)。这些模型有效突破了语言障碍,在包括许多低资源语言在内的多种语言上展现出强大性能(Hsu等人,2024;Yeo等人,2024)。然而,这些模型面临两个关键限制:(1)其庞大的规模(Radford等人,2023;Communication等人,2023)导致高昂的计算成本;(2)训练数据中低资源语言的代表性不足,导致这些语言的性能欠佳(Radford等人,2023;Talafha等人,2023)。
针对第一个问题,研究者提出了各种高效解码方法(SYSTRAN;Segal-Feldman等人,2024;Malard等人,2023;Leviathan等人,2023)。然而,这些方法产生的模型并不一定能减少内存占用。为解决效率问题,知识蒸馏(Hinton等人,2015;Gou等人,2021)被证明非常有效。研究者探索了多种知识蒸馏方法,如耐心知识蒸馏(PKD)(Sun等人,2019)、T-S学习(Manohar等人,2018)、跨模态哈希(CMH)(Hu等人,2020)、联合无监督领域自适应与知识蒸馏(Zhang等人,2021)以及无数据知识蒸馏(Lopes等人,2017)等,这些方法在NLP和CV领域都有应用。
知识蒸馏在语音识别领域也得到应用:Shao等人(2023)显著缩小了Whisper模型(Radford等人,2023)的规模(约原模型的80%),同时提升了性能;Chang等人(2022)通过分层蒸馏将Hubert模型缩小到初始规模的75%,且性能没有显著下降。此外,知识蒸馏在语音转文本任务中也取得了成功应用(Nayem等人,2023;Hentschel等人,2024;Tian等人,2022),有效降低了内存和计算需求。最近,该方法还被用于从Whisper(Ferraz等人,2024)和强大的单语模型(Gandhi等人,2023)中蒸馏多语言模型,以及在低资源场景中的应用。后者的一个例子是Waheed等人(2024),他们在多种现代标准阿拉伯语(MSA)和阿拉伯语方言数据集上研究了伪标签蒸馏方法(Gandhi等人,2023)。他们的探索证明了蒸馏在提升效率和性能方面的有效性,表明专用的小型模型可以超越大型多语言模型。
尽管伪标签方法在多种语言中被证明有效(Gandhi等人,2023;Waheed等人,2024),但传统上需要标注数据来过滤低质量的伪标签样本。在本研究中,我们通过引入基于数据过滤方法的无监督框架来解决这一限制,从而完全消除对标注数据的依赖。
3 Methodology
3.1 Knowledge Distillation
知识蒸馏是一种让小型学生模型学习大型教师模型行为的框架(Hinton等人,2015;Sanh等人,2020;Kim和Rush,2016)。Gandhi等人(2023)提出了基于伪标签的知识蒸馏方法,该方法通过教师Whisper模型生成(英语)预测结果,并利用词错率(WER)阈值进行过滤,仅保留最准确的结果。这些伪标签随后被用于训练更小的学生模型。Waheed等人(2024)在此基础上进一步研究,证明在阿拉伯语多方言场景中,Whisper学生模型的平均性能可以超越其教师模型。
我们遵循这一标准的学生-教师框架,将Whisper蒸馏为小型但强大的模型。蒸馏过程的目标函数可表示为:
![]()
其中:
• L_KL表示Kullback-Leibler(KL)散度损失,促使学生模型匹配教师的概率分布;
• L_PL表示使用伪标签作为真实标签来训练学生的损失。
系数α_KL(0.8)和α_PL(1.0)用于平衡各项损失在总体蒸馏损失L_KD中的贡献比例。
3.2 Label-Free Data Filtering
先前的数据过滤方法,如Gandhi等人(2023)和Waheed等人(2024)所采用的方法,依赖于通过计算教师模型生成的伪标签与参考转录文本之间的词错率(WER)来获取真实标签,从而剔除错误率较高的样本。然而,这种对标注数据的依赖性限制了这些方法在标注资源稀缺的低资源语言中的应用。
我们的方法引入了无需标注的过滤技术,通过利用教师模型的逻辑输出、合成语音、代理模型以及多模态嵌入等多种手段来评估伪标签的质量。下文将逐一详述每种方法的具体实现。
3.2.1 Proxy Models
我们采用预训练的语音识别模型SeamlessM4T-large-v2(Communication等人,2023)作为代理模型,为输入语音生成参考文本转录。随后通过计算代理模型输出与教师模型输出之间的词错率(即pWER)来评估教师模型所生成伪标签的质量。pWER值越低表明两者一致性越高,当样本的pWER超过预设阈值时将被剔除。
3.2.2 Uncertainty Quantification

3.2.3 Negative Log-Likelihood

3.2.4 Multimodal Embeddings
我们利用SONAR模型(Duquenne等人,2023)为输入语音及其对应伪标签生成嵌入式向量表示,通过计算两者向量间的点积(dot product)来度量其相似度——点积分值越高,表明语音与伪标签的对齐程度越好,伪标签质量越优。
3.2.5 Perceptual Evaluation of Speech Quality(PESQ)
我们采用XTTS-v2模型将伪标签合成为语音,并将其与原始输入语音进行比对,通过语音质量感知评估(PESQ)分数来量化两者的相似度——PESQ分值越高,表明伪标签的准确性越优。
3.3 Training Data
我们采用Waheed等人(2024)提出的数据混合策略进行模型训练。具体而言,我们从多个数据集中随机选取语音片段,包括MGB2(Ali等人,2016)、MGB3(Ali等人,2017)、FLEURS(Conneau等人,2023)、CommonVoice 15.0(Ardila等人,2020)、QASR(Mubarak等人,2021)、Arabic Speech Corpus(Halabi,2016)以及Massive Arabic Speech Corpus(MASC)(Al-Fetyani等人,2023)。我们分别采样10万和50万条语音片段,相当于约100小时和500小时的伪标签语音数据。所有数据均严格选自各来源的训练集划分,并基于第3节所述的评估指标过滤掉约27%的低质量样本。
3.4 Teacher and Student Models
我们遵循先前研究(Gandhi等人,2023;Waheed等人,2024)的方法,采用whisper-large-v2模型作为伪标签生成和训练过程中的教师模型。我们训练了两种不同架构的学生模型变体,其区别在于从教师模型中移除的层数不同。
具体实现上,我们按照Gandhi等人(2023)和Waheed等人(2024)的方法,通过从教师模型的编码器和解码器模块中均匀间隔地选取层来初始化学生模型。在10万条语音片段的训练规模下,我们将具有16-16和32-16编码器-解码器模块的模型分别命名为UDW-16-16和UDW-32-16。相应地,在50万条语音片段的训练规模下训练的模型则命名为UDW-16-16++和UDW-32-16++。
4 Experiments
为确保比较与分析结果的公平性,我们基本沿用了Waheed等人(2024)的实验设置。除在五个标准基准数据集上进行模型评估外,我们还扩展了评估范围,新增了SADA(Alharbi等人,2024)和Casablanca(Talafha等人,2024)两个数据集。现将所用全部数据集说明如下:
4.1 Evaluation Dataset
FLEURS(Few-shot Learning Evaluation of Universal Representations of Speech)是由Conneau等人(2023)发布的多语言语音数据集,涵盖102种语言,每种语言包含12小时语音数据。该数据集支持自动语音识别(ASR)、语言识别和翻译等任务。本研究采用其阿拉伯语子集,主要包含带有埃及口音的现代标准阿拉伯语(MSA)语音。
Common Voice(CV)是由Ardila等人(2020)发布的志愿者共建多语言数据集,包含124种语言共计31,176小时语音。其中阿拉伯语子集包含156小时语音,主要为现代标准阿拉伯语。
Multi-Genre Broadcast(MGB)系列数据集(Ali等人2016,2017,2019)包括:MGB2(1,200小时以半岛电视台阿拉伯语为主的现代标准阿拉伯语语音)、MGB3(6小时埃及方言语音)和MGB5(14小时摩洛哥方言语音)。
SADA(Saudi Audio Dataset for Arabic)由Alharbi等人(2024)发布,包含668小时阿拉伯语语音(其中435小时已标注),涵盖沙特方言、现代标准阿拉伯语以及来自黎凡特、也门和埃及的语音变体。具体统计数据见附录B2.1。
Casablanca数据集(Talafha等人2024)是一个阿拉伯方言数据集,包含48小时来自各类电视节目的语音数据,覆盖八种不同方言并由母语者完成标注。该数据集的评估结果单独呈现在表4中。
4.2 Baselines
我们采用多种单语及多语言语音识别模型对阿拉伯语不同变体(包括标准现代阿拉伯语、带口音的现代阿拉伯语及多种方言)进行评估。基线模型分为以下三类:
4.2.1 Supervised Models and Commercial Systems.
评估三个基线模型:(1)基于CV8.0训练的Wav2Vec2-XLS-R(Conneau等人,2020;Babu等人,2022);(2)基于MGB-3(Ali等人,2017)和5.5小时埃及阿拉伯语语料库训练的HuBERT(Hsu等人,2021);(3)基于CV11.0和MGB-2微调的Whisper-large-v2模型。所有模型均直接使用官方预训练参数。
4.2.2 Zero-Shot Models
Whisper系列:评估四个变体——whisper-small(W-S)、whisper-medium(W-M)、whisper-large-v2(W-L-v2)和whisper-large-v3(W-L-v3),采用默认解码参数(最大序列长度225个标记)。
SeamlessM4T系列:测试三个版本——seamless-m4t-medium(SM4T-M)、seamless-m4t-v1-large(SM4T-L-v1)和seamless-m4t-v2-large(SM4T-L-v2),在阿拉伯语ASR任务上采用零样本设置并使用官方推理参数。
4.2.3 Distilled Models
为与监督式设置对比,评估两种不同规模的蒸馏模型变体:在SADA测试集和验证集上测试基于10万/50万片段训练、WER阈值80%的16-16和32-16架构模型,同时包含未过滤数据训练的模型作为下限参照。实验设置严格遵循Waheed等人(2024)的方法。
4.3 实验配置
评估时统一采用各模型默认解码参数(特殊说明除外),最大序列长度固定为225,以词错率(WER)和字错率(CER)作为核心评估指标。蒸馏过程中,根据质量指标筛选约27%的高质量片段(对应λ=80%的监督式数据量),超参数直接沿用Gandhi等人(2023)的配置(详见附录C表13),未进行额外调优。
5 Results and Discussion
我们首先报告Waheed等人(2024)的基线模型结果,并在SADA测试集和验证集上评估所有模型。主要实验结果见表1,不同评估场景的平均表现见表2,SADA数据集中五种主要方言的详细结果见表9。所有报告结果均基于去除变音符号的规范化文本计算,未规范化文本的结果见附录3.3。
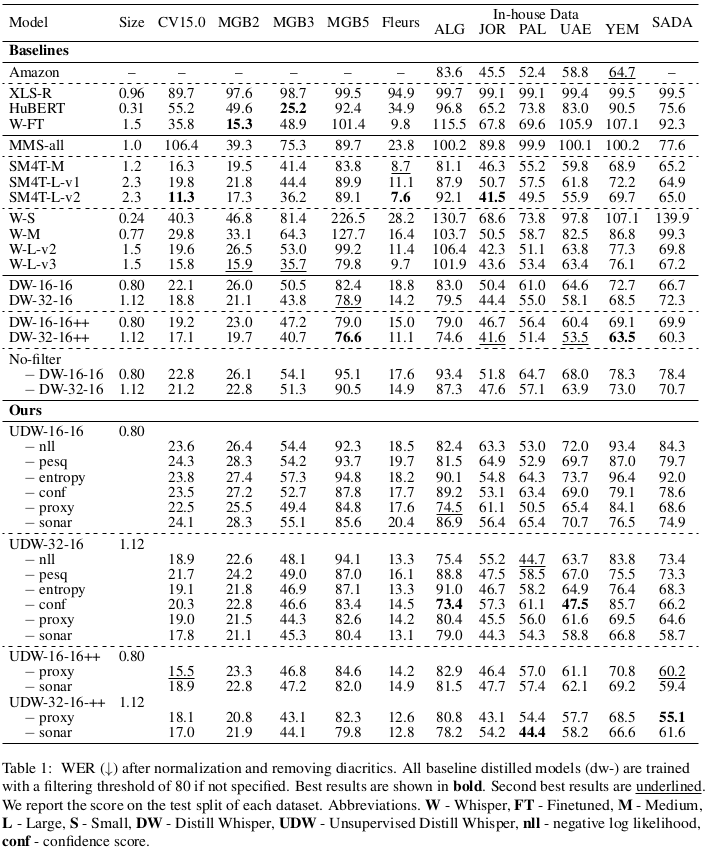
研究发现,虽然SeamlessM4T和Whisper的大规模变体在Common Voice、Fleurs等标准测试集上表现良好(如SeamlessM4T-large-v2在Fleurs上的WER为7.6%),但在方言语音识别任务中表现显著下降(SADA测试集WER达65.0%)。这揭示了零样本模型在陌生复杂场景下的评估不足与泛化局限。相比之下,我们最佳蒸馏模型DW-32-16++全面超越教师模型(Whisper-large-v2)、最优Whisper版本(large-v3)及最佳基线(SeamlessM4T-large-v2)。
在蒸馏模型方面,两种最佳过滤方法(sonar-sim和proxy-ref)达到或超越监督式基准。具体而言:采用80%过滤阈值、基于10万样本训练的DW-32-16模型,在基准测试集、SADA测试集和五种新方言上的WER分别为35.3%、66.6%和61.1%;而相同配置下UDW-32-16-sonar模型对应结果为35.5%、58.7%和60.6%,平均成绩较监督式设置提升近3%(51.6 vs 54.3),较无过滤设置提升超7%。小规模学生模型UDW-16-16配合proxy-ref方法时表现更优,在10万样本训练下与监督式结果相当(58.5% vs 57.6%),较未过滤设置提升超6%。
当训练数据从10万扩展至50万样本时,采用proxy-ref和sonar-sim过滤的UDW-32-16++模型与监督式DW-32-16++性能相当(WER 51.4% vs 50.0%)。值得注意的是,小模型UDW-16-16++表现反超监督式过滤模型(53.9% vs 56.2%),验证了数据过滤方法的有效性。
在未知方言泛化测试中,UDW-32-16++在SADA五大主要方言类别上平均WER为58.06%,优于DW-32-16++的59.42%。这证实了我们方法的三重优势:(1)实现Whisper大模型的有效压缩;(2)保持或提升性能;(3)完全摆脱对标注数据的依赖。
针对伪标签质量的定量分析显示:对于WER>80的劣质样本,sonar-sim和proxy-ref的AUC分别达到0.77和0.82,显著优于置信度指标(AUC=0.68)。这表明基于SONAR嵌入和代理参考的度量方法在无监督场景下能有效提升伪标签质量。