MySQL性能调优探秘:我的实战笔记 (上篇:从EXPLAIN到SQL重写)
哈喽,各位技术伙伴们!👋 最近我一头扎进了 MySQL 性能调优的奇妙世界,感觉就像打开了新世界的大门!从一脸懵懂到现在能看懂 EXPLAIN 的“天书”,还能对 SQL “指点江山”,这个过程充满了“啊哈!”时刻。今天就想和大家分享一下我到目前为止的学习心得和实战笔记,希望能给同样在学习或者工作中需要和 MySQL 打交道的你带来一些启发。我们不谈空泛理论,只聊干货和实践!💪
一、你的第一把瑞士军刀:EXPLAIN 命令 🔍
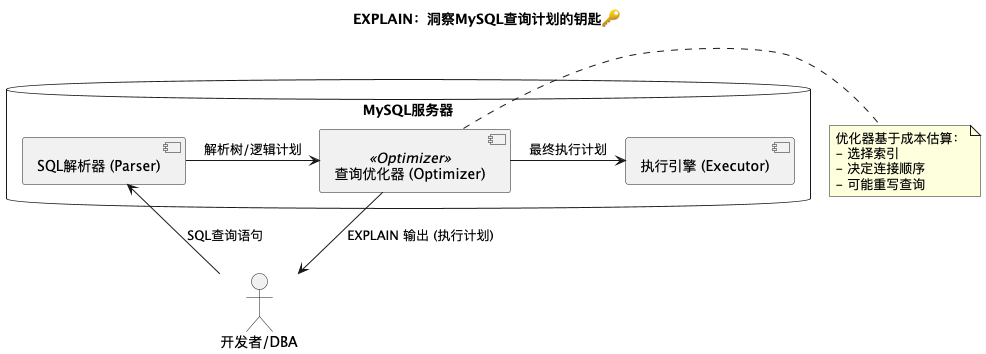
想象一下,你要去一个陌生城市,地图就是你的向导。在 MySQL 的世界里,EXPLAIN 命令就是你洞察 SQL 查询执行计划的“活地图”!
当我们向 MySQL 提交一条查询语句时,它并不会立刻闷头去硬盘里翻箱倒柜。相反,它会先经过解析器 (Parser) 解析语法,然后交给查询优化器 (Query Optimizer)。优化器会像个足智多谋的军师,分析各种可能的执行路径(比如是用这个索引还是那个索引?表连接的顺序怎样最优?),最后选择一个它认为成本最低的执行计划 (Execution Plan),再交给执行引擎 (Executor) 去真正干活。
EXPLAIN 命令就能让我们一窥优化器最终选定的这份“作战地图”。通过它,我们可以知道:
- 查询访问了哪些表?
- MySQL 选择了哪个索引(或者没用索引导致全表扫描😭)?
- 预估扫描了多少行数据?
- 连接表的方式是怎样的?
- 有没有用到临时表或者文件排序等耗性能的操作?
这是我们诊断慢查询、理解性能瓶颈的第一步,也是最重要的一步!
二、索引的魔法:不止是“目录”那么简单 📚✨
说到性能优化,90% 的情况都和索引有关。我们不仅要创建索引,更要理解它的“脾气”,让它真正为我们所用。
1. 索引不是万能的,选择性很重要! 高选择性的列(比如用户ID、订单号)创建索引效果拔群。但如果给“性别”这样的列(只有几种固定值)创建索引,优化器可能宁愿全表扫描。
2. 复合索引与“最左前缀”黄金法则! 当查询条件涉及多个列时,复合索引 (INDEX(colA, colB, colC)) 能大显神通。但记住最左前缀原则:查询必须从索引的最左列开始,并且不能跳过中间的列,才能充分利用复合索引。

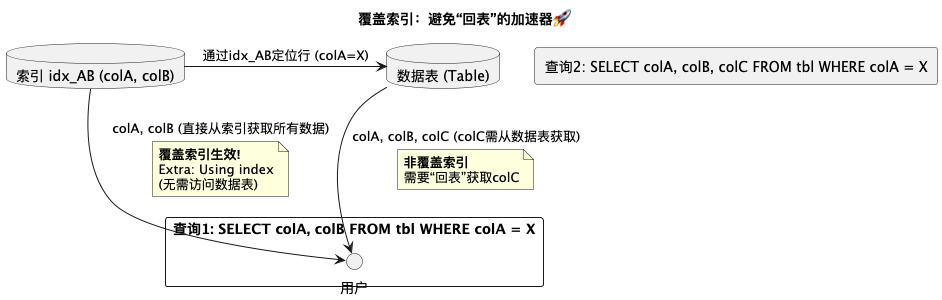
3. 覆盖索引:让查询“飞”起来! 如果一个索引包含了查询所需的所有列(SELECT 和 WHERE 里用到的),MySQL 就可以只读取索引而无需访问数据表本身(避免了“回表”),这就是覆盖索引。EXPLAIN 的 Extra 列显示 Using index 就是它的标志。不过,我们在实践中也发现,即使设计了覆盖索引,优化器也可能因为前缀索引或其他成本考量而不显示 Using index,但查询依然高效!这提醒我们优化器的世界很深奥。
三、SQL优雅转身:重写技巧让查询更“Smarter” ✍️
除了索引,SQL 语句本身的写法也至关重要。有些看似不经意的写法,可能就是性能杀手。
1. 告别 SELECT *: 只选择你真正需要的列,减少I/O、网络开销,还能为覆盖索引创造机会。
2. 让 WHERE 条件“Sargable” (参数可优化): 这是重中之重!避免在索引列上使用函数或运算,否则索引会“哭晕在厕所”(失效)。 * 反例:WHERE YEAR(order_date) = 2024 (索引失效) * 正解:WHERE order_date >= '2024-01-01' AND order_date < '2025-01-01'(索引可用!) 我们在实践中发现,即使写对了Sargable条件,如果查询范围覆盖的数据量特别大(比如超过表数据的20-30%),优化器也可能“自作主张”选择全表扫描,因为它认为那样总成本更低!通过 FORCE INDEX 可以一探究竟,但生产环境慎用。
3. 子查询 vs. JOIN: 以前常说用 JOIN 替换子查询,但现代 MySQL 优化器对 IN 和 EXISTS 子查询(尤其前者)优化得相当好,甚至能转成高效的半连接(FirstMatch 策略)。JOIN + SELECT DISTINCT 反而可能因为临时表开销更大。关键还是:EXPLAIN大法好,具体问题具体分析!
4. UNION vs. UNION ALL: 如果不介意重复行,或者确定不会有重复,果断用 UNION ALL,因为它省去了去重步骤,更快!
四、实践出真知:我的实验小结 🛠️
这次学习最大的感受就是,理论结合实践太重要了!我们搭建了包含百万级数据的测试库,亲手创建索引,用 EXPLAIN 分析执行计划,尝试重写SQL,看到 type: ALL 变成 ref 或 range,rows从几十万降到几十几百,那种成就感无与伦比!也遇到了优化器“不按套路出牌”的情况,逼着我们更深入地思考其背后的成本估算逻辑。
总结与展望 💡
到目前为止,我们主要聚焦在查询分析和SQL层面的优化。通过EXPLAIN、理解索引机制、重写SQL,已经能解决很多常见的性能问题了。
但MySQL调优之路还很长!接下来,我们还会探索:
- MySQL服务器配置参数调优
- 不同存储引擎的特性与优化
- 更高级的诊断工具和技巧
- ...等等
如果你也对MySQL性能调优感兴趣,或者有什么独门秘籍,欢迎在评论区交流!也请期待我的下一篇学习笔记哦!😉