拟南芥T2T基因组-文献精读127
A near-complete assembly of an Arabidopsis thaliana genome
拟南芥基因组的近乎完整组装

拟南芥(Arabidopsis thaliana)基因组序列作为广泛应用的模式物种,为植物分子生物学研究提供了巨大的推动力。在基因组序列首次发布后的20多年(Arabidopsis Genome Initiative, 2000)之后,仍然存在一些未解决的间隙区域,这些区域可能由高度重复的序列组成,如端粒、着丝粒、5S rDNA簇和含有45S rDNA的核仁组织区(NOR)。使用相对较短的测序读取来组装这些重复序列非常困难。对广泛使用的TAIR10/Araport11组装(Lamesch等,2012)进行扫描时,发现了165个间隙,涵盖了所有五个着丝粒,并且没有一个染色体可以从头到尾完成。本文展示了一种高质量的组装,包含三个无间隙的染色体和两个只缺少NORs和NOR4末端端粒序列的染色体。通过结合长读取Oxford Nanopore Technologies(ONT)、高保真长读取PacBio和短读取Illumina技术,我们获得了一个新的133,917,231-bp的Col-0基因组组装,命名为Col-PEK,比TAIR10/Araport11组装大14,770,883 bp。此外,我们还填补了最近发布的两个高质量组装Col-CEN和Col-XJTU中大部分剩余的间隙(Naish等,2021;Wang等,2021)。在这个近乎完整的基因组组装中,共注释了27,629个蛋白质编码基因,其中213个是新发现的。这些新基因中的许多位于NORs或着丝粒区域。值得注意的是,我们发现至少有145个新基因是由于之前未被识别的隐藏重复而产生的,包括串联重复,这大大扩展了我们对近期基因重复的理解。在五个完整的着丝粒中,我们观察到178-bp串联卫星DNA重复序列(CEN180)的数量远高于之前的假设。
我们整合了Nanopore ONT、PacBio HiFi和Illumina NovaSeq的读取,用于初步组装、修饰和去污染。随后,我们在TAIR10的框架内将contig定位到染色体水平,然后使用HiFi contig/scaffold填补Chr4上的两个间隙。通过填补所有间隙并定位到TAIR10,我们得到了相同的结果。最后,我们基于仅使用ONT读取的区域修正了结构错误和小型拼接错误,并通过HiFi contig和读取比对检查了NORs中的潜在缺失。最终的Col-PEK组装大小为133,917,231 bp,所有着丝粒已完成(补充方法;补充图1)。
通过基准通用单拷贝同源基因(Supplemental Table 1)、核心真核基因映射方法评估(Supplemental Table 2)、GC-深度分析(Supplemental Figure 2)、Merqury(Rhie等,2020)和Inspector(Chen等,2021)评估(补充方法;补充表3和4)、SNP分析(Supplemental Table 5)以及使用原始Illumina过滤读取、HiFi读取和ONT读取的比对(补充方法;补充图3和4)确认了组装质量的高水平。值得注意的是,Merqury评估表明,Col-PEK的质量明显高于TAIR10和Col-CEN,并且与Col-XJTU的质量相当或略高(补充表3)。所有来自着丝粒区域的测序读取都通过CEN180特异性11-mer序列得到了验证,Merqury对五个着丝粒的评估显示出极高的准确性,Chr2(CEN2)的错误率低至0(补充方法;补充表4)。我们将Col-PEK与TAIR10、Col-XJTU和Col-CEN组装(Naish等,2021;Wang等,2021)进行了比较,发现完美的共线性(图1A–1C;补充图5A和6)。新的组装添加了大约14.8 Mb的新序列,这些序列大多位于着丝粒附近或内部(图1A;补充图5A和7–11)。除了着丝粒之外,我们还在Chr2和Chr4的顶部臂末端分别添加了约499和约183 kb的序列(补充图1和7–11)。序列比对表明,这些新序列包含45S rDNA亚单位(即5.8S、18S和25S rDNA)(补充表6),提示它们是NORs的一部分(Sims等,2021)。尽管长度明显大于TAIR10(>98.55%),两个NOR仍包含一些未完成的间隙(补充方法)。我们进一步应用覆盖度分析来估算重复序列的拷贝数,使用Illumina读取(Long等,2013)。估算的45S rDNA的拷贝数(>310)远大于组装单元的数量(约66)(补充表6),提供了NOR大小的估算值。我们还在Chr2的NOR附近鉴定了2.6 kb的端粒重复序列,而Chr4的NOR仍然缺乏端粒重复序列。总共识别出了九个端粒,大小从2.6 kb到3.6 kb不等(补充表7)。
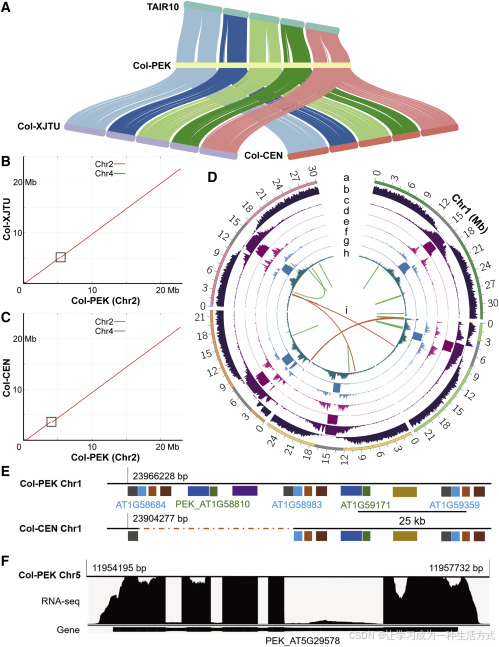
**图1. Col-PEK组装、注释及应用概览**
**(A)** 使用MUMmer比对Col-PEK、Col-XJTU、Col-CEN与TAIR10之间的序列共线性。每个共线区域表示一对一的比对关系。图中从左到右连接的染色体分别为Chr1至Chr5。
**(B 和 C)** Col-PEK与Col-XJTU (B) 或Col-CEN (C) 在Chr2上的共线性比较。两个黑色框表示在Col-XJTU和Col-CEN中存在的间隙。
**(D)** Col-PEK基因组组装的注释,除(h)外,其他内容均按100 kb窗口统计。
- (a) 染色体长度与着丝粒区域(灰色)以及线粒体DNA插入区域(蓝色),染色体Chr1至Chr5按顺时针排列;
- (b) 编码基因数密度;
- (c) 所有重复序列密度;
- (d) CEN180单体密度;
- (e) LTR类转座元件密度;
- (f) DNA类转座元件密度;
- (g) 由GMATA和TRF识别的SSR与串联重复序列的综合密度(补充方法);
- (h) 通过Nanopolish基于ONT数据检测的高频CpG甲基化位点密度(以50 kb窗口);
- (i) 新识别的145个基因与其高度同源基因的共线关系。绿色线表示同一染色体上的基因,红色线表示分布在不同染色体上的基因。
**(E)** Col-PEK在Chr1上识别出Col-CEN中错误组装的区域,包含一个36.0 kb的缺失序列及七个编码基因。图中每个矩形代表一个基因,同一面板中颜色相同表示同源基因。虚线表示Col-CEN中缺失的序列。
**(F)** 一个新预测基因的示例,暂定命名为PEK_AT5G29578,位于新组装的Chr5着丝粒中。该基因获得RNA测序支持,最大比对深度为467×。图底部黑色条带表示预测的基因结构;粗条带为预测外显子,细条带为预测内含子。
与最近发布的高质量组装(Col-CEN与Col-XJTU)相比,Col-PEK组装更完整、长度更长,并填补了多个长度超过40 kb的剩余间隙(图1A–1C;补充图3与6;补充表8与9;补充方法)。例如,Col-XJTU在Chr2上留下的一个108.7 kb间隙已被填补(图1B;补充图3A与12A)。在Col-CEN中,一个232.8 kb的不明间隙现已在Chr2的线粒体DNA插入区被识别并填补。插入后的mtDNA大小(640.5 kb)与之前荧光原位杂交估计值(618 ± 42 kb)以及Col-XJTU报告的值一致(图1C和1D;补充图3B、12B和13)。我们还在Col-CEN的Chr1上识别到一个36.0 kb的间隙,包含七个编码基因(图1E;补充图3C、6B和12B)。这些新序列都得到了ONT和HiFi读取的良好支持(补充图3)。这些分析解释了Col-PEK中Chr2、Chr4和Chr5(NOR除外)序列为何长于Col-XJTU和Col-CEN(补充表8)。另一方面,Col-PEK中的Chr1和Chr3略短于Col-XJTU,可能是由于Col-PEK中缺失了部分序列。为此,我们评估了Chr1中的一个21 kb区域(补充图4A–4E)和Chr3中的一个11 kb区域(补充图4F),并发现ONT通过读取和HiFi读取在Col-PEK断点处有连续覆盖,而在Col-XJTU断点处则没有。值得注意的是,在这些区域,Col-PEK与Col-CEN的序列完全一致(补充图4)。
Col-PEK组装为估算重复序列的分布提供了前所未有的机会。我们识别出26,079个简单序列重复,总长度400,090 bp,识别出46,108个串联重复,总长度15,470,062 bp。随后,使用RepeatMasker(http://www.repeatmasker.org/)预测转座元件,发现约有19,274,191 bp(占基因组的14.40%)归属于转座元件。其中,LTR/Gypsy类逆转录转座元件是最大的类群,占6,885,521 bp(占基因组的5.14%)。重复序列的总占比为26.58%,远高于TAIR10的18.51%(图1D;补充图14;补充表8和10)。
共有27,416个蛋白质编码基因从Araport11转移到了Col-PEK中,总数为27,445个。剩余的基因要么位于TAIR10中错误组装的区域,要么太短(3-39 bp)(补充图15和16;补充表11;补充方法)。例如,AT3G41762在TAIR10中的26 kb错误组装区域中被发现,但也有四个同源拷贝,它们被重新组装到Col-PEK的NOR2和NOR4中(补充图15;补充表11和12)。先前的研究也建议,TAIR10中的这个区域可能存在问题(Pucker等,2021)。值得注意的是,我们识别出145个之前未知的基因,它们与现有基因具有高度相似性(>99% DNA序列相似性)(图1D,内圈;补充表12;补充方法)。在这些隐藏重复的基因中,70个位于两个NORs中,47个位于前述的线粒体DNA插入区域(补充图7–11)。根据TAIR提供的同源基因功能描述,这部分基因推测编码线粒体呼吸途径的蛋白质。至少56个新识别的隐藏重复基因形成了串联重复,其中两个或多个同源基因沿染色体相邻排列(图1D,内圈;补充表12)。以前也曾发现有限的隐藏基因重复现象,例如SEC10(Vukašinović等,2014)(补充图16A),而我们的发现表明这种现象更为常见(补充方法;补充表12)。不同的重复基因可能会相邻排列。例如,Chr5中一个最近更新的区域包含两种基因重复,一种是一个基因重复两次,另一种是一块三基因区域重复一次(补充表12),支持了最近的报告(Pucker等,2021)。为了进一步识别新序列中的基因,我们采用了三种独立的方法,包括基因预测、同源搜索和参考引导的转录组组装,获得了另外68个新编码基因,其中17个基因得到了转录组数据的支持(图1F;补充图7–11;补充表13)。这些新基因大多位于NORs和线粒体DNA插入区,一部分则分布在被着丝粒特异性组蛋白H3样蛋白(CENH3)结合的着丝粒区域(补充图7–11)。
由于其更高的完整性,Col-PEK在识别的非编码RNA(ncRNA)基因数量上超过了Col-CEN和Col-XJTU。总共识别出5,959个ncRNA基因,包括3,910个编码5S rRNA、71个编码18S rRNA、64个编码25S rRNA、66个编码5.8S rRNA、648个编码tRNA,以及1,200个编码其他ncRNA,包括核糖开关和核糖酶(补充表6)。值得注意的是,我们的分析显著增加了5S rRNA的数量(补充表6和8),并揭示了许多5S rRNA集中在Chr3至Chr5的着丝粒附近,并与LTR/Gypsy元素交替排列(补充图7–11)。PacBio HiFi数据有助于填补Chr4上的间隙,并恢复易于丢失的重复序列,如5S rDNA和CEN180阵列,从而确保Col-PEK在注释这些重复元素上的优势(补充图17;补充方法)。
五个完整的着丝粒为细致分析着丝粒组织提供了独特的机会。我们共识别出66,232个着丝粒CEN180重复序列,这一数字超过了Col-CEN和Col-XJTU组装中的数量(图1D;补充图7–11;补充表8)。每个着丝粒中的CEN180阵列体积从2.36 Mb到4.40 Mb不等。CENH3结合在以CEN180重复簇为中心的扩展区域,定义了功能性着丝粒。我们发现CENH3结合区域的长度大致与先前通过物理图谱估算的着丝粒大小一致(Hosouchi等,2002;Kumekawa等,2000, 2001),并且与Col-XJTU一致,但比Col-CEN的CENH3结合区域长约1.82 Mb(补充表14)。在所有染色体中,CENH3在着丝粒核心区域富集,在LTR/Gypsy富集的区域则较少。此外,CENH3与某些CEN180子集表现出优先结合的关系。Nanopore ONT测序为检测DNA甲基化提供了机会,这与亚硫酸盐测序结果高度相关。我们发现NORs和5S rDNA阵列高度甲基化,而着丝粒区域的CpG甲基化水平高于染色体臂,尽管CEN180阵列相对低甲基化。此外,端粒区域则呈现低甲基化状态(图1D;补充图7–11和18)。
总之,结合其他最近报告的高质量组装(Naish等,2021;Wang等,2021),新获得的近完整的Col-PEK组装为拟南芥Col-0提供了一个长期期待的关键资源。Col-PEK的在线信息门户,包括互动式可搜索浏览器以及可下载的基因组组装和注释文件,已上线,网址为:http://col-pek.arashare.cn/。
官网
拟南芥参考基因组_拟南芥数据库-CSDN博客
Ensembl数据库下载参考基因组(常见模式植物)bioinfomatics 工具37_ensembl plant数据库-CSDN博客
http://col-pek.arashare.cn/