2. H264编码
1. 视频为什么要编码压缩
- 一张
720x480的图形,用YUV420p的格式来表示,其大小为:720*480*1.5 bype约等于0.5MB
-
- 如果一秒二十五帧,10分钟的数据量:
0.5M*10*60*25=7500MB约等于7G
- 如果一秒二十五帧,10分钟的数据量:
- 视频编码压缩的目的是降低视频数据大小,方便存储和传输

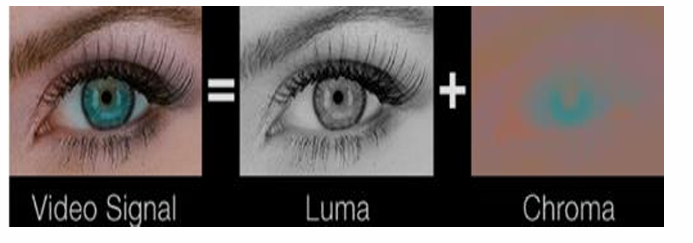
2. 为什么压缩的原始数据一般采用YUV格式
- 视频编码是对一张张图片来进行的。我们知道彩色图像的格式是
RGB的,但RGB三个颜色是有相关性的。 - 采用
YUV格式,利用人对图像的感觉的生理特征,对于亮度信息比较敏感,而对于色度信息不太敏感,所以视频编码是将Y分量和UV分量分开来编码的,并且可以减少UV分量,比如我们之前说的YUV420P。
3. 视频压缩原理——数据冗余
编码的目的是为了压缩,各种视频编码算法都是为了让视频体积变得更小,减少对存储空间和传输带宽的占用。编码的核心是去除冗余信息,通过以下几种冗余来达到压缩视频的目的:
- 空间冗余:图像相邻像素之间有较强的相关性,比如一帧图像划分成多个
16x16的块之后,相邻的块很多时候都有明显的相似性。(比如图片中,全是白色的块,那么一个16x16的白色块同时能代表其他的白色块) - 时间冗余:视频序列的相邻前后帧图像之间内容相似,比如帧率为
25fps的视频中前后两帧相差只有40ms,但前后两张图片的变化很小,相似度很高。(比如图片中,前后两张图片只有毫秒那个地方不同,其它地方全部一模一样) - 视觉冗余:我们的眼睛对某些细节不敏感,对图像中高频信息的敏感度小于低频信息。可以去除图像中的一些高频信息,人眼看起来跟不去除高频信息差别不大(有损压缩,比如连续100个都是白色的,那么把1个变色成灰白色,99个白色+1个灰白肉眼是看不出来差别的)
- 编码冗余(信息熵冗余):一副图像中不同像素出现的概率是不同的。对出现次数比较多的像素,用少的位数来编码。对出现次数比较少的像素,用多的位数来编码,能够减少编码的大小。比如哈夫曼编码。

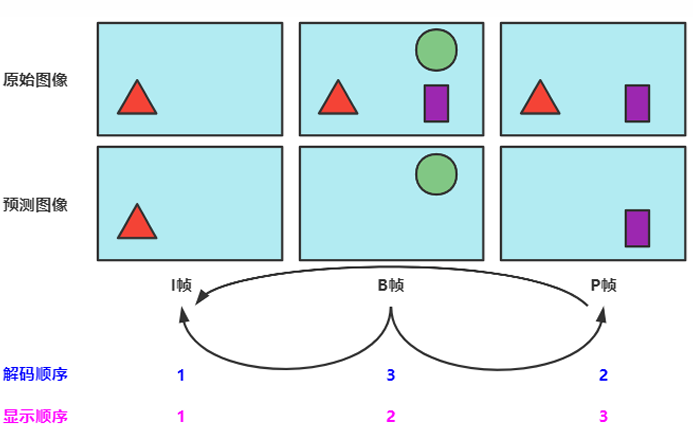
4. 图像帧的类型(I帧、P帧、B帧)
I帧、P帧和B帧是视频压缩领域中的基础概念,用于提升视频压缩效率、视频质量和视频恢复能力。
I帧(关键帧,也称帧内帧)仅由帧内预测的宏块组成。(但也需要PPS、SPS才能编码)P帧代表预测帧,除帧内空域预测以外,它还可以通过时域预测来进行压缩。P帧通过使用已经编码的帧进行运动估计(即上述提到的时间冗余)B帧可以参考在其前后出现的帧,B帧中的B代表双向(故由于B帧需要等到后一帧才能解析,对直播来说延迟太大,故直播一般不会考虑B帧)
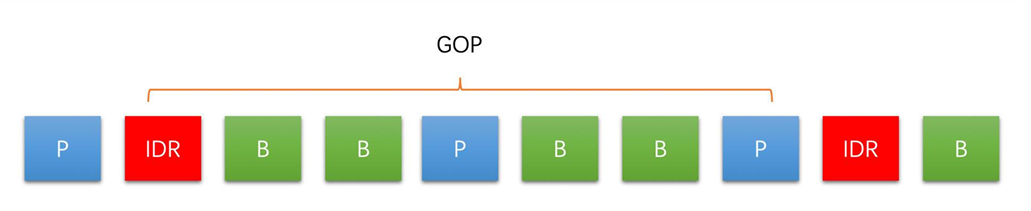
5. GOP 和 GOP 长度
GOP是指一组连续的帧,以一个I帧开头,以另一个I帧的前一帧结束。中间具体有多少帧,就看自己的配置了。比如可以是I、P、B、...、P,只有一个I帧。也可以是I、P、B、...、I、B、P、...、P,有两个I帧。.....,也可以有无穷个I帧。- 一个序列的第一个图像叫做
IDR图像(立即刷新图像),IDR图像都是I帧图像,在视频编码序列中,GOP即(Group of picture图像组),指的是两个IDR之间的距离 GOP长度越大,视频压缩效率越高,但视频质量和视频流恢复能力也越差,反之亦然- 直播中如果一秒二十五帧,一般
GOP设置为25或者50(一般是帧率的倍数) - 如果不是直播率,
B帧一般设置连续两帧,以降低码率
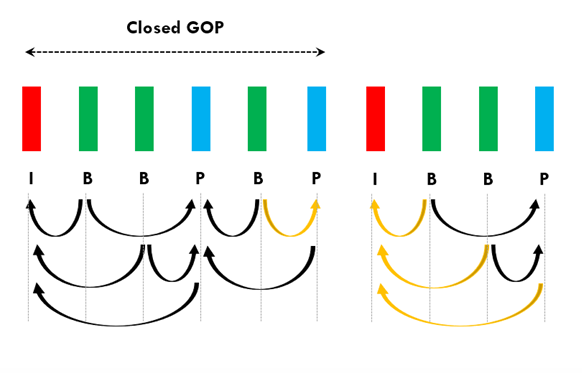
5.1. GOP之Closed GOP 和 Open GOP
Closed GOP和Open GOP常见于视频流中,并影响压缩效率、视频容错能力以及ABR流的切换能力。
- 顾名思义,
Closed GOP对GOP外部的帧是封闭的。一个属于Closed GOP的帧只能参考这个GOP之内的帧 Open GOP则于Closed GOP相反
5.2. GOP间隔
GOP越大,编码的I帧就会越少(因为我可以使用P帧参考自然不可能去使用I帧)。相比而言,P帧、B帧的压缩率更高,因此整个视频的编码效率就会越高。但是GOP太大,也会导致IDR帧距离太大,点播场景时进行视频的seek操作就会不方便。
6. H264编码原理
对于每一帧图像,是划分为一个个块进行编码,也就是我们常说的宏块。
宏块大小一般是16x16(H264、VP8),32x32(H265、VP9),64x64(H265、VP9、AV1),128x128(AV1)
6.1. 宏块扫描
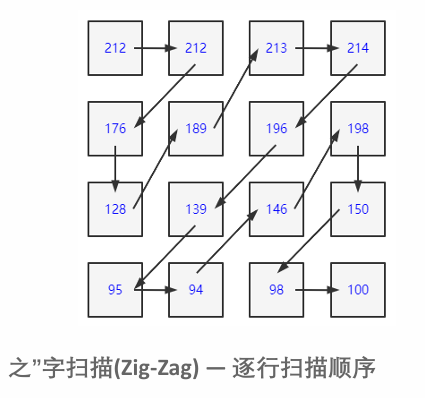
- 对于一个
YUV图像,可以划分成一个个16x16的宏块(以H264为例),Y、U、V的大小分别是16x16、8x8、8x8。我们这里只对Y分量进行分析(U、V同理可得)。假设Y分量这16x16个像素是一个个数字,采用“之”字方式扫描每一个像素值,就可以得到一个“像素串”。 - 压缩的目的是让当前的字符出现连续相同的字符,比如
1,1,1,1,1,1,1,那么我们可以描述为8个1。【可以发现8个1才3个字,比1,1,1,1,1,1,1,1的字符长度短太多了】 - 而且数字越小越容易用更少的
bit做压缩,比如一连串数字很小(比如0,1,2,1,0)的“像素串”,因为0在二进制只占一位,2只占2位即可。要是一连串数字很大(比如255,254,253,222,243)的“像素串”,每一个数字都要花8位来存储,消耗的空间就大了。
(这是16x16当中的4x4)

(这是16x16,其中的红色部分就是上面的4x4,只不过两个数字打错了,不应该是92、99,应该是98,100)
6.2. 帧内预测
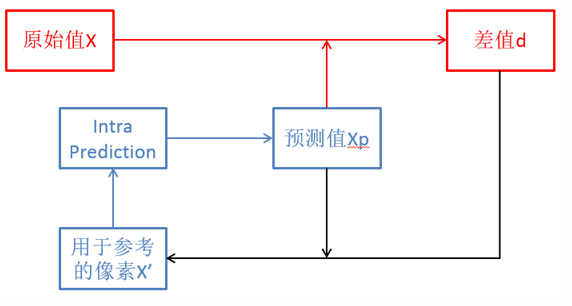
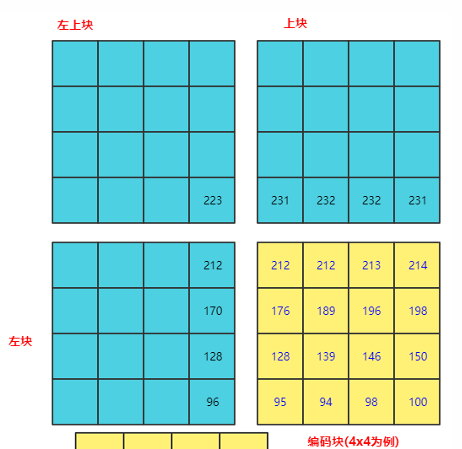
- 帧内预测就是在当前编码图像内部已经编码完成的块中找到将要编码的块相邻的块。一般就是即将编码块的左边块、上边块、左上块、右上块,通过将这些块与编码块相邻的像素经过多种不同的算法得到多个不同的预测块。
- 然后后我们再利用编码块减去每一个预测块得到一个个残差块。最后,我们取这些算法得到的残差块中像素的绝对值加起来最小的块作为预测块(即预测块取的就是残缺块)。而得到这个预测块的算法成为帧内预测模式。
6.3. 残差块
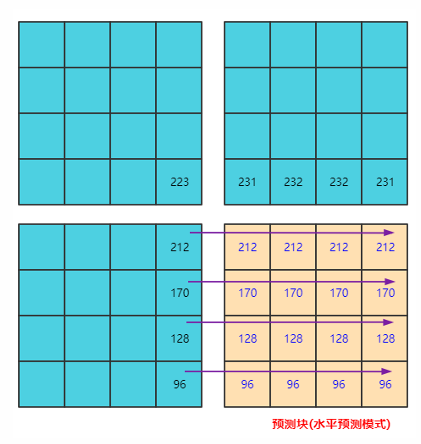
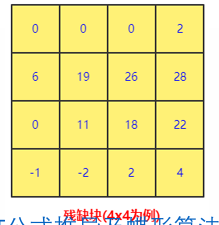
此时我们把原始编码块的像素值减去预测块的像素值得到残缺块,可以看到对应的数值更为接近0。【注意,是第一个图减去第二个图得出的残缺块】
6.4. 帧间预测
- 同理,帧间预测也是一样的。我们在前面已经编码完成的图形中,循环遍历每一个块,将它作为预测块,用当前的编码块与这个块做差值,得到残缺块,取残差块中像素值的绝对值加起来最小的块作为预测块,预测块所在的已经编码的图像成为参考帧。预测块在参考帧中的坐标值(x0,y0)与编码块在编码帧中的坐标值(x1,y1)的差值(x0-x1,y0-y1)成为运动矢量。
- 而在参考帧取寻找预测块的过程称之为运动搜索。事实上编码过程中真正的运动搜索不是一个个块取遍历寻找的,而是有快速的运动搜索算法的。
总结:
- 通过预测得到的残差块的像素值相比的编码块的像素值,去除了大部分空间冗余信息和时间冗余信息,这样得到的像素更小。如果把这个残差块做扫描得到的像素串送去做行程编码,是不是就相比直接拿编码块的像素串做编码更有可能得到更大的压缩率呢?
提示:预测算法并不会丢失数据,此时数据还是可以还原的。
6.5. DCT 变换和量化
- 我们的目标不只是将像素值变小,而是希望能出现连续的0像素
- 这就需要利用我们人眼的视觉敏感性的特点了。我们刚才说了人眼对高频信息不太敏感。因为人眼看到的效果可能差别不大,所以我们可以去除一些高频信息。这个就是我们接下来要讨论的DCT变化和量化。(但这个量化实际上会导致有损,对于生理指标、微表情等这种很细致的算法来说是有影响的)
6.5.1. DCT变换
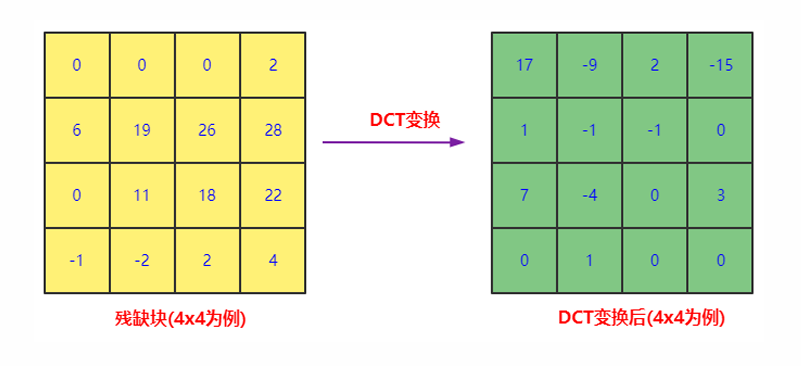
- DCT(离散余弦变换)变换此时也不会丢失数据,也是无损的,可以还原数据。
- 低频信息主要表示的是一张图的总体样貌,一般低频系数的值比较大;编码后尽量保存低频信息,DCT变换后低频信息的数值变小。
- 高频信息主要表示的是图像中人物或者物体轮廓边缘等变换剧烈的地方,高频系数的数量多,但高频系数的值一般比较小。
- 变换之后,低频和高频信息就分离开来了。低频信息在左上角,其余的都是高频信息。(高频指的是高频率出现,同理低频指的是低频率出现)
- 具体的怎么变换的呢?余弦?哈夫曼?反正是数学运算,最后可以复原
6.5.2. 量化步长
- 犹豫人眼对高频信息不太敏感,如果我们可以通过一种手段去除掉大部分高频信息,也就是将大部分高频信息置为0,但又不太影响人的观感,是不是就可以达到我们最初的目标,也就是得到一连串0的像素串?这就涉及到量化操作了。
- 我们让DCT变换块的系数都同时除以一个值,这个值我们称之为量化步长,也就是QStep(QStep是编码器内部的概念),用户一般使用量化参数QP这个值,QP和QStep得到的结果就是量化后的系数。QStep越大,得到量化后的系数就会越小。同时,相同的QStep值,高频系数相比低频系数值更小,量化后更容易变成0(此时就造成了有损,无法复原了)。这样一来,将大部分高频系数变成0。如下图所示:
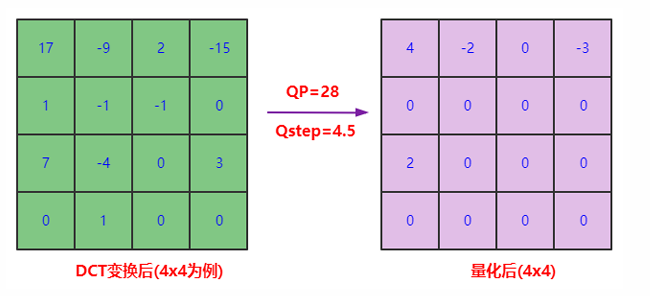
- 解码的时候,需要将QStep乘以量化后的系数得到变换系数,很明显这个变换系数和原始没有量化的系数(DCT变换块)是不一样的,这个就是常说的有损编码。
- 而到底损失多少呢?由QStep来控制,QStep越大,损失就越大。QStep与QP一一对应。从编码器应用角度来看,QP值越大,损失就越大,从而画面的清晰度就会越低。同时,QP值越大,系数被量化成0的概率就越大,这样编码之后码率的大小就会越小,压缩就会越高。
6.5.3. 量化步长表
不要在意QStep和QP的区别,实际上他们就是一个东西,编码器实际上都是处理的QStep,QP只不过是编码器给我们做了一个映射而已,比如数字1代表了0.625。这样我们就不用去记0.625这个数字了,直接输入1就可以了。
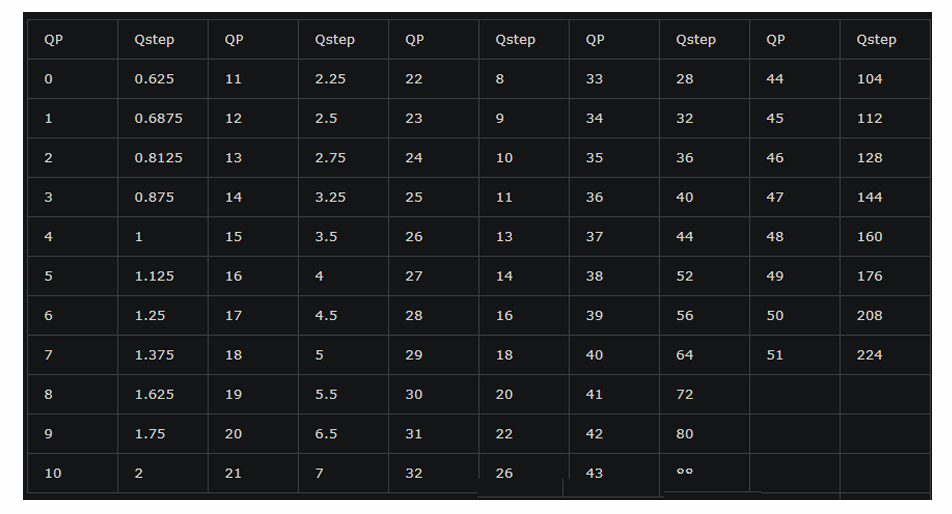
补充一下,QStep有小于1的值,是因为量化后的块中的系数不是一定整数,也可以是小数,即0.4。
0.4 / 1 = 0.4 (四舍五入)=0,则被量化为0
但 0.4 / 0.625 = 0.8 (四舍五入) = 1,则被量化为1。
这就是为什么QStep会有小于1的值。
7. 编码原理总结
- 为了能在最后熵编码的时候压缩率更高,对于送到熵编码(以行程编码为例)的像素串,包含的0越多,越能提高压缩率。为了达到这个目标:
-
- 先通过帧内预测或者帧间预测去除空间冗余和时间冗余,从而得到一个像素值比编码块小很多的残差块。
- 然后再通过DCT变换将低频信息和高频信息分离开来得到变换块(编码冗余),然后在对变换块的系数进行量化(视觉冗余,造成有损)。
- 由于高频系数通常较小,很容易量化为0,同时人眼对高频信息不太敏感,这样就得到了一串含有很多个0,大多数情况下是一串含有连续0的像素串,并且人的观感还不会太明显。
- 这样,最后熵编码就能把图像压缩成比较小的数据,以此达到视频压缩的目的。
- 这就是视频编码的原理。
8. 编码格式
8.1. NALU格式


8.2. SPS与PPS深度解析及实战数据详解
8.2.1. 一、SPS/PPS核心概念解析
1. 序列参数集(SPS)
- 作用:定义整个视频序列的全局参数,相当于视频的"基因编码"
- 关键字段:
-
profile_idc:编码档次标识(Baseline=66, Main=77, High=100)level_idc:编码级别(如3.1对应720p@30fps)pic_width_in_mbs_minus1/pic_height_in_map_units_minus1:通过公式计算实际分辨率frame_mbs_only_flag:帧/场编码模式标识log2_max_frame_num_minus4:帧号计数器位深
2. 图像参数集(PPS)
- 作用:定义单幅图像的编码参数,相当于"个性化配置"
- 关键字段:
-
entropy_coding_mode_flag:熵编码模式选择(0=CAVLC, 1=CABAC)pic_init_qp:初始量化参数(影响码率控制)num_slice_groups_minus1:片组划分方式deblocking_filter_parameters:去块效应滤波参数
8.2.2. 二、实战数据深度解析
示例1:SPS原始数据(十六进制)
00 00 00 01 67 4D 00 28 9E A0 2A 1F 65 04 80 80 80 1F 00 05 68 EB E3 CB 22 C0 2D 00 00 00 01 68 CE 38 80 00 00 00 01 65 B8 00 00 00 01 06逐字段解析:
- NAL头(0x67):
-
- forbidden_zero_bit: 0(合规位)
- nal_ref_idc: 3(高优先级参考帧)
- nal_unit_type: 7(SPS类型标识)
- SPS主体解析:
-
profile_idc=77(Main Profile)level_idc=30(Level 3.0)- 宽高计算:
pic_width_in_mbs_minus1 = 0x2A → 实际宽度=16*(42+1)=688px
pic_height_in_map_units_minus1 = 0x1F → 实际高度=16*(31+1)=512px-
frame_mbs_only_flag=1(纯帧编码模式)log2_max_frame_num_minus4=4→ 最大帧号=2^(4+4)=256
示例2:PPS原始数据(十六进制)
00 00 00 01 68 CE 38 80 00 00 00 01 65 B8 00 00 00 01 06关键字段解析:
- NAL头(0x68):
-
- nal_unit_type=8(PPS类型标识)
- PPS主体解析:
-
entropy_coding_mode_flag=0(使用CAVLC熵编码)pic_init_qp=24(初始量化参数)num_slice_groups_minus1=0(单片组模式)deblocking_filter_parameters:
disable_deblocking_filter_idc=0(启用去块滤波)
slice_alpha_c0_offset=0(滤波强度参数)
slice_beta_offset=08.2.3. 三、数据实战应用场景
1. 码流初始化流程:
码流结构:SPS → PPS → IDR → P帧 → B帧...
解码器初始化步骤:
1. 解析SPS获取分辨率、帧率等全局参数
2. 解析PPS获取量化参数、熵编码模式
3. 根据参数配置解码器上下文
4. 开始正常解码流程2. 参数动态更新机制:
- 当视频分辨率变化时:
-
- 编码器生成新SPS(标识符seq_parameter_set_id递增)
- 插入新PPS(引用新SPS的seq_parameter_set_id)
- 后续帧使用更新后的参数集
8.2.4. 四、深度解析工具推荐
- 码流分析工具:
-
- Elecard StreamEye:可视化显示SPS/PPS参数
- Wireshark H.264解码插件:实时捕获分析
- 参数计算器:
# 分辨率计算示例
def calculate_resolution(sps_data):pic_width = 16 * (sps_data[13] + 1) # 假设pic_width_in_mbs_minus1在固定偏移量pic_height = 16 * (sps_data[14] + 1) * (2 - (sps_data[16] >> 7))return (pic_width, pic_height)8.2.5. 五、常见问题解决方案
Q1:SPS/PPS丢失导致花屏
- 现象:画面出现马赛克或绿色块
- 解决方案:
-
- 在关键帧前重复插入SPS/PPS
- 使用SEI消息携带参数集
Q2:分辨率动态切换失败
- 现象:画面比例异常或黑屏
- 解决方案:
-
- 确保新SPS的seq_parameter_set_id递增
- 在IDR帧前插入更新后的参数集
通过掌握SPS/PPS的深层结构和实战解析技巧,您将具备以下能力:
- 精准定位码流异常根源
- 优化编码参数配置
- 实现视频流的智能适配(如动态分辨率切换)
- 开发高可靠性的视频处理系统
建议结合H.264官方标准文档(ITU-T H.264)进行交叉验证,重点关注第7.3.2节(NAL单元语法)和第7.4节(参数集语义)章节。
8.3. IDR和I帧的区别
8.3.1. 一、IDR帧与I帧的本质区别
- 解码刷新机制
-
- IDR帧:作为GOP(图像组)的起点,IDR帧会强制清空解码器的参考帧列表(DPB),并重新初始化解码状态。这意味着IDR帧之后的帧完全独立于其之前的帧,无法引用任何IDR帧之前的内容。这一特性使得IDR帧成为严格的随机访问点,适合用于视频流的切换或编辑。
- I帧:普通I帧虽不依赖其他帧解码,但不强制清空参考帧列表。其后的P/B帧仍可能引用该I帧之前的帧内容(如其他I帧或P帧),因此普通I帧无法作为独立的随机访问点。
- 参考帧管理
-
- IDR帧:通过清空DPB,确保后续帧仅依赖IDR帧本身及之后的帧,彻底阻断误差传播。
- I帧:DPB可能保留历史参考帧,后续帧可能引用IDR帧之前的帧,误差可能跨帧传播。
- 随机访问能力
-
- IDR帧:因清空参考帧,解码器可从任意IDR帧开始独立解码,支持快速跳转或编辑。
- I帧:普通I帧无法保证独立解码,需依赖其之前的帧状态,随机访问需额外处理。
8.3.2. 二、PPS与SPS的作用及与帧类型的关系
- 参数集定义
-
- SPS(Sequence Parameter Set):描述视频序列的全局参数,如分辨率、帧率、编码档次(Profile)等,作用于整个序列。
- PPS(Picture Parameter Set):定义单帧或一组帧的编码参数,如熵编码模式、量化参数、去块滤波强度等。
- 与帧类型的关联
-
- IDR帧:通常与SPS/PPS绑定传输,因IDR帧标志新序列开始,需重新初始化参数。但SPS/PPS并非IDR帧独有,其他帧类型(如普通I帧)也可引用这些参数集。
- I帧:普通I帧可能复用已有SPS/PPS,无需强制携带新参数集,除非序列参数变更。
8.3.3. 三、总结与误区澄清
- 核心区别:IDR帧通过清空参考帧列表实现解码刷新和严格随机访问,而普通I帧无此机制。
- PPS/SPS的作用:它们是序列/帧级参数容器,与帧类型无直接绑定。IDR帧常携带新参数集,但其他帧也可引用。
- 应用场景:IDR帧适合流媒体关键帧、视频编辑点;普通I帧用于常规压缩,减少数据量。
简言之,IDR帧是I帧的强化版,通过解码刷新和参考帧隔离提供更强鲁棒性,而PPS/SPS的作用独立于帧类型,服务于整个序列或单帧的编码配置。
即一般是 GOP [PPS -> SPS -> IDR -> ...]
而 I 帧前面不一定有 PPS和SPS。
9. 实例代码
9.1. 解析h264文件
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>using namespace std;#define H264_FILE_NAME "D:/data/video/demo/test.h264"
// 大多数创建buf的字节最大值
#define BUF_MAX_SIZE (1024*1024)// 判断数据前三个字节是否是 0x 00 00 01 [NALU的startCode]
static int startCode3(char* buf)
{if (buf[0] == 0 && buf[1] == 0 && buf[2] == 1){return 1;}else{return 0;}
}// 判断数据前四个字节是否是 0x 00 00 00 01 [NALU的startCode]
static int startCode4(char* buf)
{if (buf[0] == 0 && buf[1] == 0 && buf[2] == 0 && buf[3] == 1){return 1;}else{return 0;}
}// 返回一个指针,指向下一个 startCode 开始的第一个字节的位置
static char* findNextStartCode(char* buf, int len)
{// 一个 startCode 至少三个字节,如果 buf 连三个字节都没有,那肯定没有 startCodeif (len < 3){return NULL;}// 这里遍历到 len - 3 [用的 < 符号,实际上是4个字节] 是因为 startCode4 至少需要 4 个字节才行for (int i = 0; i < len - 3; i++){if (startCode3(buf) || startCode4(buf)){return buf;}buf++;}// 如果所有的 startCode4 都不满足,那么还剩下最后一个 startCode3 可以判断if (startCode3(buf)){return buf;}return NULL;
}// 从文件中读取一帧NALU数据,数据内容写入 frame,大小写入 frameSize
void getH264Frame(FILE *fp, char* frame, int& frameSize)
{// 从文件中读取一大段数据int rSize = fread(frame, 1, BUF_MAX_SIZE, fp);// 如果读取出来不是以 NALU的 startCode开头,代表这个H264文件的内容有问题if (!startCode3(frame) && !startCode4(frame)){printf("读取视频文件 %s 结束, 找不到startCode, frameSize=%d \n", H264_FILE_NAME, rSize);frameSize = -1;return;}// 找到下一个 startCode 的位置char* nextStartCode = findNextStartCode(frame + 3, rSize - 3);// 如果没找到,那么代表这个H264文件的内容有问题[当然,有可能是文件读取完毕了,没有下一个了]if (!nextStartCode){printf("读取视频文件 %s 结束, 找不到下一个startCode, frameSize=%d \n", H264_FILE_NAME, rSize);frameSize = -1;return;}else{// 下一个 startCode 的位置 减去 这一个 startCode 的位置 就能得出这个 NALU 的总长度了frameSize = nextStartCode - frame;/** 由于刚刚读取数据多了,所以需要将文件的游标移动回去,本次只读取一个 NALU 大小的数据就够了* [frameSize - rSize 是负数,所以文件游标会向左移动]*/fseek(fp, frameSize - rSize, SEEK_CUR);}// 获取 startCode 的长度int startCode = 0;if (startCode3(frame)){startCode = 3;}else{startCode = 4;}// 去掉 startCode 的长度,只保留NALU的数据部分frameSize -= startCode;// 向右偏移,去掉 startCode 的长度的数据,只保留NALU的数据部分memmove(frame, frame + startCode, BUF_MAX_SIZE - startCode);
}// 解析NALU数据
void parseH264Frame(char* frame, int frameSize)
{// 第一个字节是 NALU Headeruint8_t naluHeader = frame[0];// 0x1F:0001 1111 即后五位,即Typeuint8_t naluType = naluHeader & 0x1F;// 记录帧数static int i = 0;i++;// 判断类型if (naluType == 7){printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "SPS", frameSize);}else if (naluType == 8){printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "PPS", frameSize);}else if (naluType == 5){printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "IDR", frameSize);}else if (naluType == 1){printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "I、B、P", frameSize);}else if (naluType == 6){printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "private data", frameSize);}else{printf("no:%d,\ttype:%s,\tbyteSize:%d\n", i, "unknown", frameSize);}
}int main()
{int frameSize = 0;char* frame = (char*)malloc(BUF_MAX_SIZE);// 本地读取数据FILE* fp = fopen(H264_FILE_NAME, "rb");if (!fp){printf("打开视频文件 %s 失败\n", H264_FILE_NAME);return -1;}// 开始循环读取视频数据while (true){// 从文件中读取一个NALU的数据getH264Frame(fp, frame, frameSize);if (frameSize < 0){printf("读取视频文件 %s 结束, frameSize=%d \n", H264_FILE_NAME, frameSize);break;}// 解析帧内容parseH264Frame(frame, frameSize);}// 释放内存free(frame);system("pause");return 0;
}