Kaggle——House Prices(房屋价格预测)简单实现
题目:
- 从Kaggle的“House Prices - Advanced Regression Techniques”数据集
- 使用Pandas读取数据,并查看数据的基本信息。
- 选择一些你认为对房屋价格有重要影响的特征,并进行数据预处理(如缺失值处理、异常值处理等)。
- 使用matplotlib绘制特征与目标变量(房屋价格)之间的散点图或箱线图,观察它们之间的关系。
- 将数据分为训练集和测试集。
- 使用numpy或scikit-learn搭建一个线性回归模型,并在训练集上进行训练。
- 在测试集上评估模型的性能,并计算均方误差(MSE)或均方根误差(RMSE)。
- 尝试使用不同的特征组合或进行特征选择,观察模型性能的变化。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error# 设置中文显示
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = Falsedef load_data(file_path):"""加载数据并查看基本信息"""df = pd.read_csv(file_path, encoding="utf-8")print("数据基本信息:",df.columns)return dfdef preprocess_data(df, features, target):"""数据预处理:去除重复特征、处理缺失值和异常值"""features = list(set(features)) # 去除重复特征X = df[features]Y = df[target]# 合并特征和目标变量combined = pd.concat([X, Y], axis=1)# 删除包含缺失值的行combined = combined.dropna()# 异常值处理(使用 IQR 方法)def remove_outliers(df):Q1 = df.quantile(0.25)Q3 = df.quantile(0.75)IQR = Q3 - Q1df = df[~((df < (Q1 - 1.5 * IQR)) | (df > (Q3 + 1.5 * IQR))).any(axis=1)]return dfcombined = remove_outliers(combined)# 重新分离特征和目标变量X = combined[features]Y = combined[target]return X, Ydef plot_features(X, Y):"""绘制特征与目标变量的散点图"""for feature in X.columns:plt.scatter(X[feature], Y)plt.title(f"{feature}-房价")plt.xlabel(feature)plt.ylabel("房价")plt.show()def train_model(X, Y):"""划分训练集和测试集,训练模型并评估性能"""x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=22)# 数据标准化transfer = StandardScaler()x_train = transfer.fit_transform(x_train)x_test = transfer.transform(x_test)# 训练模型estimator = Ridge(alpha=1)estimator.fit(x_train, y_train)# 预测y_predict = estimator.predict(x_test)# 评估模型ret = estimator.score(x_test, y_test)mse = mean_squared_error(y_test, y_predict)rmse = np.sqrt(mse)print("预测值:", y_predict)print("准确率:", ret)print("均方误差(MSE):", mse)print("均方根误差(RMSE):", rmse)return estimatorif __name__ == "__main__":file_path = "./data/train.csv"df = load_data(file_path)x = ['GrLivArea', 'OverallQual', 'TotalBsmtSF', 'GarageCars']y = ['SalePrice']X, Y = preprocess_data(df, x, y)plot_features(X, Y)model = train_model(X, Y)
结果展示:
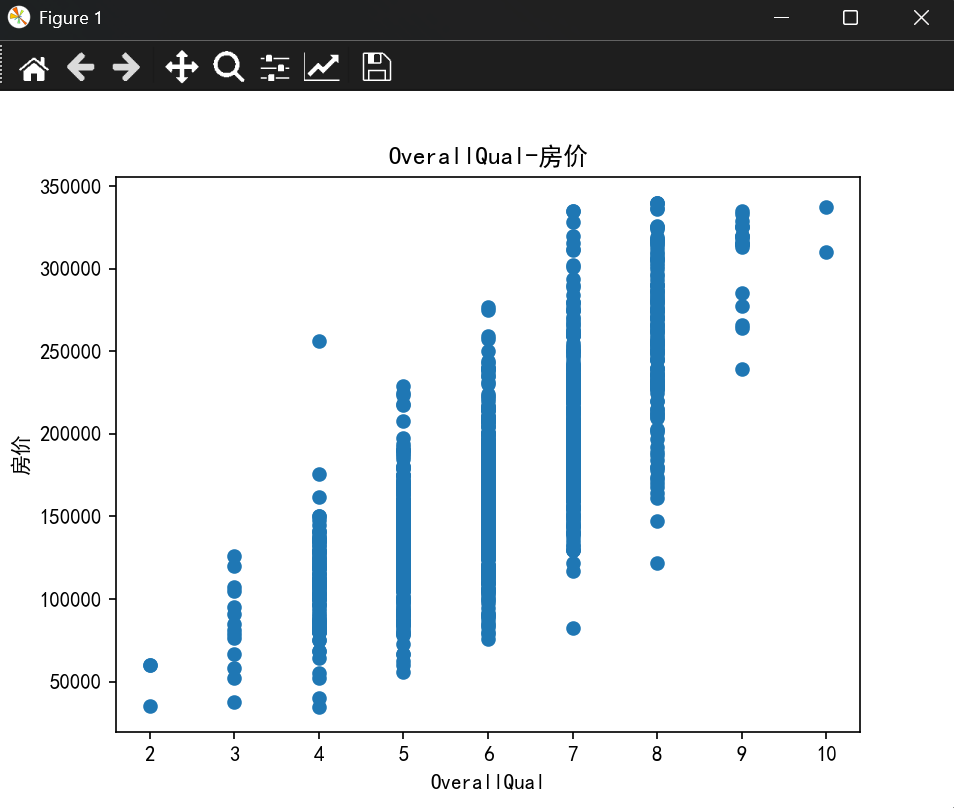
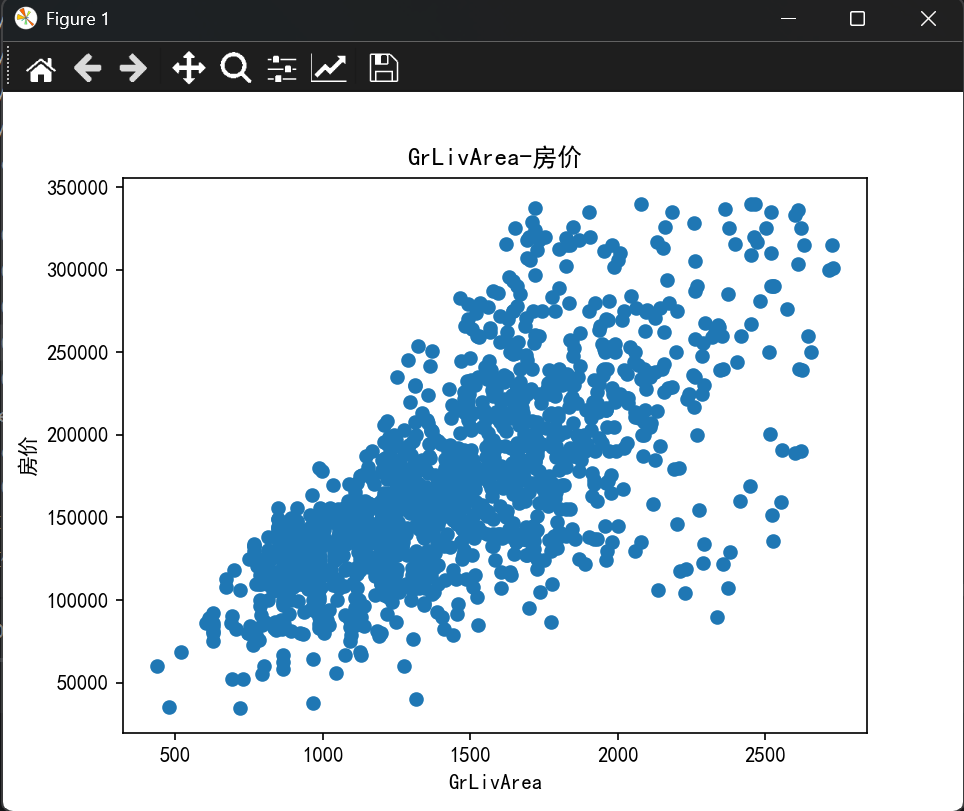
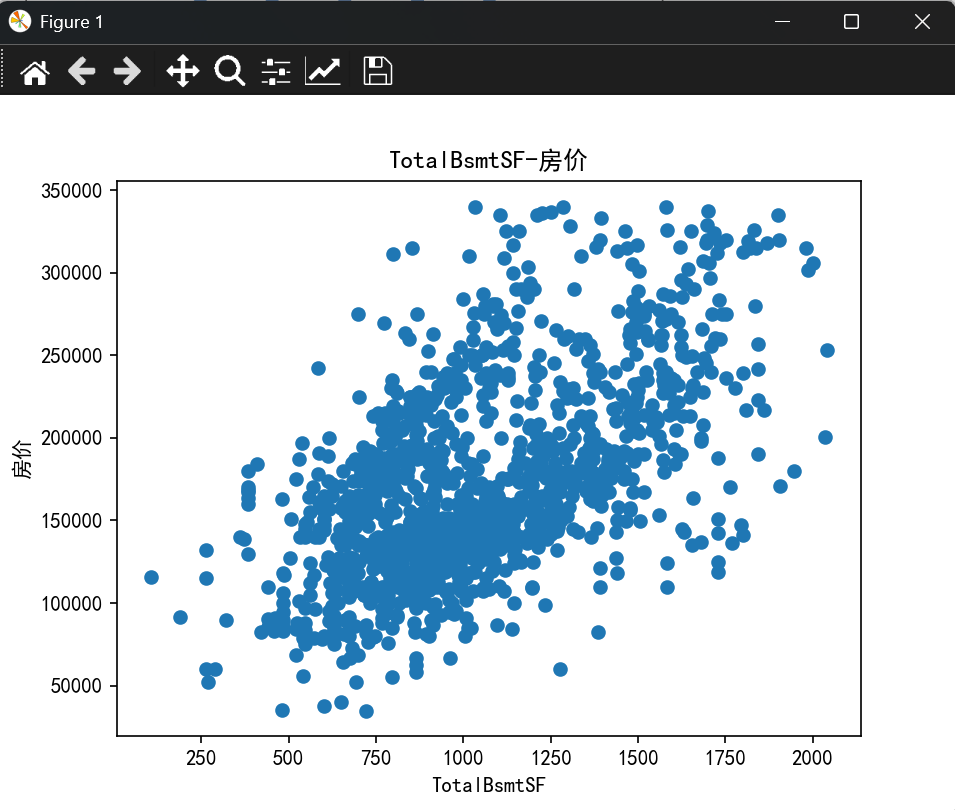
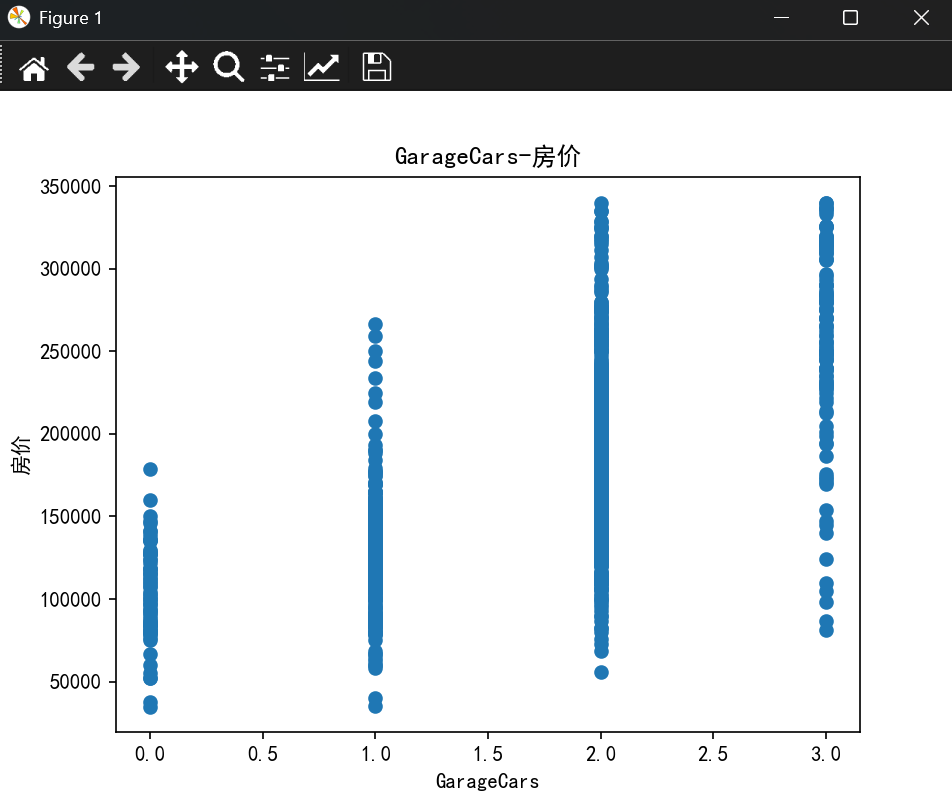
准确率: 0.8232886900015453
均方误差(MSE): 591601359.6413734
均方根误差(RMSE): 24322.856732739543