小土堆pytorch--transform
torchvision中的transform
- torchvision中的transform
- 1. transforms的使用
- 1.1 transforms的结构及用法理论
- 1.2 相应代码
- 1.3 对上述代码的解释
- 2. 常见的transforms
- 2.1 python 的call函数
- 2.2 ToTensor的使用
- 2.3 Normalize的使用
- 2.4 Resize的使用
- 2.5 Compose的使用
- 2.6 RandomCrop的使用
- 3.一些技巧
torchvision中的transform
1. transforms的使用
1.1 transforms的结构及用法理论
transforms中有很多工具,我们可以利用其中的工具把图片转换成想要的结果
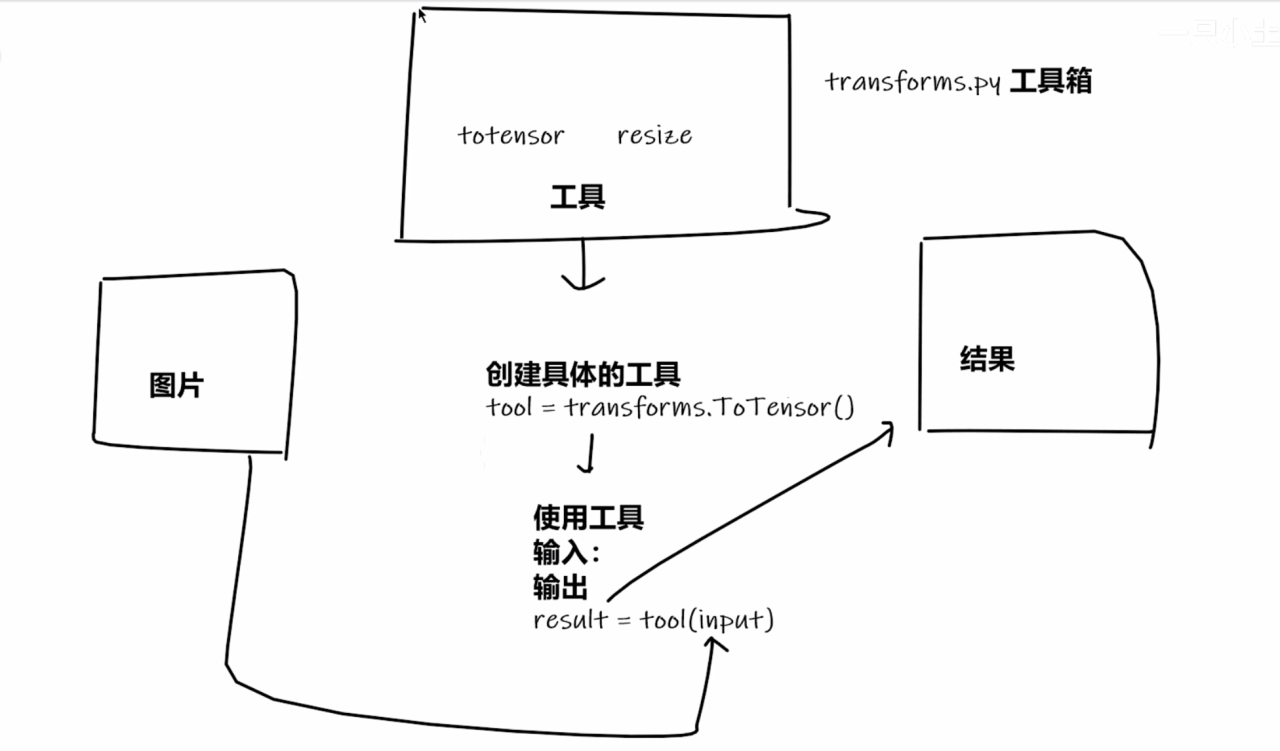
这张图展示了 transforms 在图像处理中的结构及用法:
- 整体流程:以图片作为输入,经过
transforms.py工具箱中的工具处理后,得到处理结果。 - 关键组件
transforms.py工具箱:是一个包含各种图像处理工具的集合,这里提到了totensor和resize两种工具。totensor:通常用于将图片数据转换为张量(Tensor)格式 ,这在深度学习中是常见操作,方便后续的模型处理。resize:用于改变图片的尺寸,可将图片调整为指定的大小,满足不同模型输入尺寸的要求等。
- 流程说明:原始图片进入
transforms.py工具箱,利用其中的totensor、resize等工具进行处理,处理完毕后输出得到结果,供后续使用,比如输入到深度学习模型中进行训练或预测等。
1.2 相应代码
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
# python 的用法 -》 tensor数据类型
# 通过 transforms.Totensor 去看两个问题img_path = 'dataset/train/bees/36900412_92b81831ad.jpg'
img = Image.open(img_path)
print(img)writer = SummaryWriter("logs")
# 1.transforms该如何使用(python)tensor_trans = transforms.ToTensor()
print(tensor_trans)
tensor_img = tensor_trans(img)print(tensor_img)# 2.为什么我们需要Tensor数据类型
writer.add_image("Tensor_img", tensor_img)writer.close()
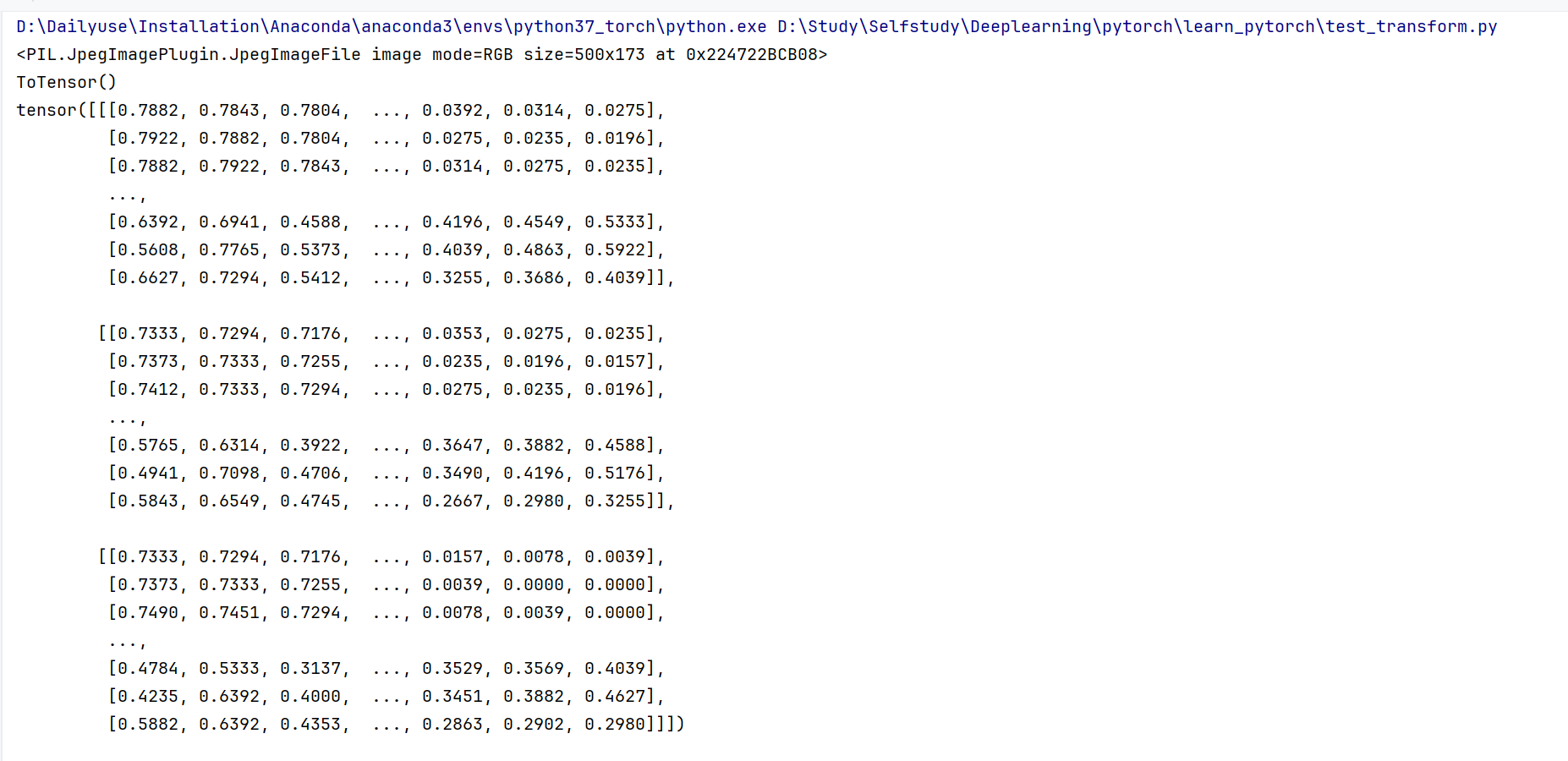
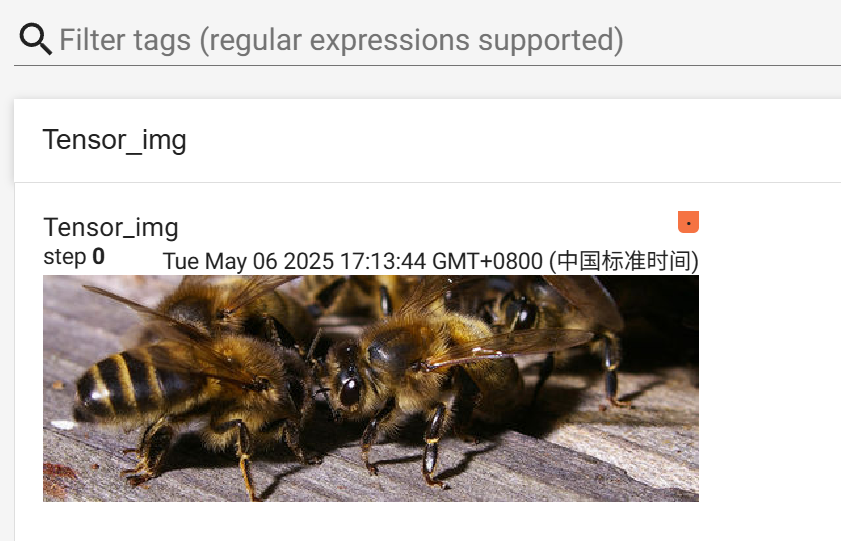
上述代码主要演示了如何使用 torchvision.transforms 中的 ToTensor 类将 PIL 图像转换为 Tensor 数据类型,并使用 torch.utils.tensorboard 将转换后的图像可视化。
运行结果:
1.3 对上述代码的解释
- 导入必要的库
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
SummaryWriter:用于将数据写入TensorBoard日志文件,方便后续可视化。transforms:torchvision库中的模块,提供了各种图像变换工具。Image:PIL库中的类,用于打开和处理图像。
- 打开图像文件
img_path = 'dataset/train/bees/36900412_92b81831ad.jpg'
img = Image.open(img_path)
print(img)
img_path:指定图像文件的路径。Image.open(img_path):使用PIL的Image类打开指定路径的图像文件,并将其存储在img变量中。print(img):打印图像的基本信息,例如图像的模式(如RGB)和尺寸。
- 创建
SummaryWriter对象
writer = SummaryWriter("logs")
SummaryWriter("logs"):创建一个SummaryWriter对象,将日志文件保存到logs目录下。
- 使用
ToTensor进行图像转换
tensor_trans = transforms.ToTensor()
print(tensor_trans)
tensor_img = tensor_trans(img)
print(tensor_img)
transforms.ToTensor():创建一个ToTensor实例,用于将PIL图像或numpy.ndarray转换为Tensor数据类型。print(tensor_trans):打印ToTensor实例的信息。tensor_trans(img):调用ToTensor实例的__call__方法,将img转换为Tensor数据类型,并将结果存储在tensor_img中。print(tensor_img):打印转换后的Tensor图像的信息。
tips:
1.

当我们不知道一个方法中需要什么参数是,我们可以按快捷键CTRL+p进行查看
2.
当我们不确定函数的用法时候我们可以通过CTRL+左键去看对应函数的官方文档
-
解释为什么需要
Tensor数据类型
在深度学习中,模型通常只能处理Tensor数据类型。因此,需要将图像数据转换为Tensor类型,以便能够输入到模型中进行训练或推理。ToTensor类将PIL图像转换为Tensor时,还会将像素值从[0, 255]归一化到[0, 1]范围内,这有助于模型的训练和收敛。 -
将
Tensor图像写入TensorBoard
writer.add_image("Tensor_img", tensor_img)
writer.add_image("Tensor_img", tensor_img):将tensor_img写入TensorBoard日志文件,并指定图像的标签为"Tensor_img"。
- 关闭
SummaryWriter
writer.close()
writer.close():关闭SummaryWriter对象,确保所有数据都被写入日志文件。
综上所述,这段代码展示了如何使用 torchvision.transforms 中的 ToTensor 类将 PIL 图像转换为 Tensor 数据类型,并使用 TensorBoard 可视化转换后的图像。
2. 常见的transforms
2.1 python 的call函数
class Person:def __call__(self, name):print("__call__"+"Hello "+name)def hello(self, name):print("hello"+ name)person = Person()
person("zhangsan")
person.hello("lisi")

也就是如果我们有内置的call函数的话,我们只需要使用:对象+参数 就可以直接调用对应函数,而不用使用“." 的方法
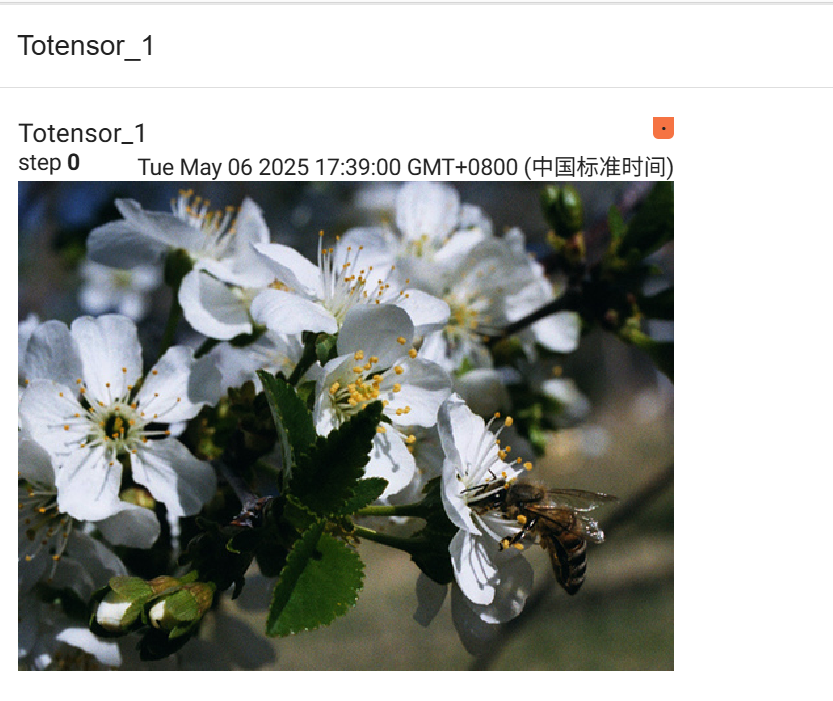
2.2 ToTensor的使用
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)# ToTensor
trans_totensor = transforms.ToTensor();
img_tensor = trans_totensor(img)
writer.add_image("Totensor_1",img_tensor)writer.close()
现在我们把PIL类型的img使用transforms中的totensor方法把他变成tensor数据类型的img(即img_tensor), 然后就可以直接装入tensorboard中
运行结果

2.3 Normalize的使用
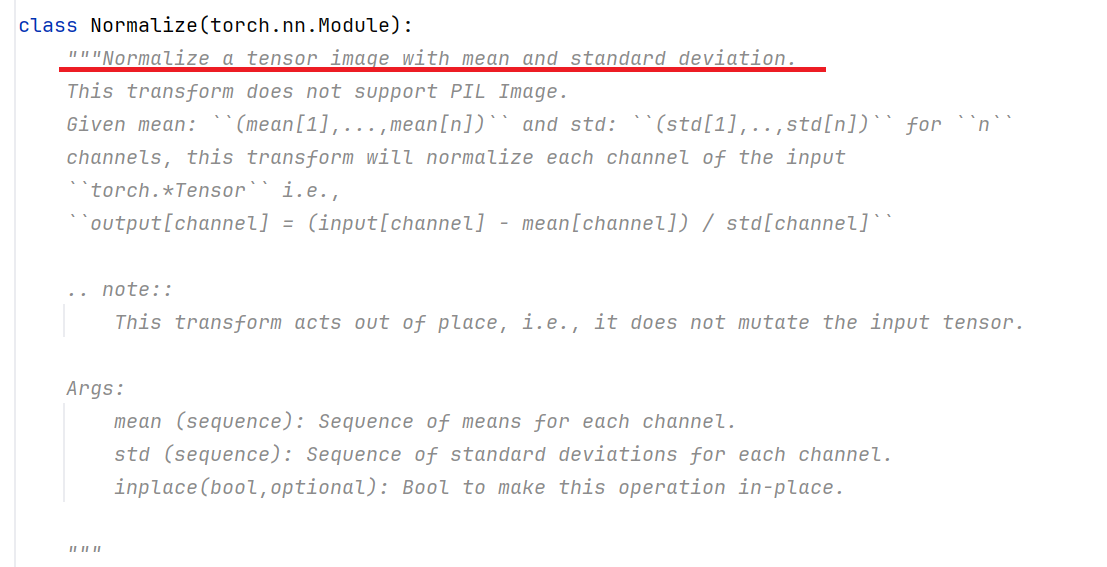
即用均值和标准差归一化tensor数据类型的图片
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)# ToTensor
trans_totensor = transforms.ToTensor();
img_tensor = trans_totensor(img)
writer.add_image("Totensor_1",img_tensor)# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)writer.close()

归一化:-0.7098 = (0.1451-0.5)/0.5
即输入值减去均值除以标准差
经过归一化之后发现这张图片和上一张图片的颜色上有了一些区别
2.4 Resize的使用
Resize 是 torchvision.transforms 模块里的一个类,其用途是调整图像的大小

trans_resize = transforms.Resize((512, 512))
transforms.Resize 是一个类,用于创建一个调整图像大小的变换对象。
其参数可以是一个整数或者一个元组:
若为整数,Resize 会把图像的短边调整为该整数指定的长度,同时保持图像的宽高比。
若为元组 (h, w),则会把图像调整为指定的高度 h 和宽度 w。
在上述代码中,(512, 512) 表示将图像调整为高度和宽度均为 512 像素的大小。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)# ToTensor
trans_totensor = transforms.ToTensor();
img_tensor = trans_totensor(img)
writer.add_image("Totensor_1",img_tensor)# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)writer.close()
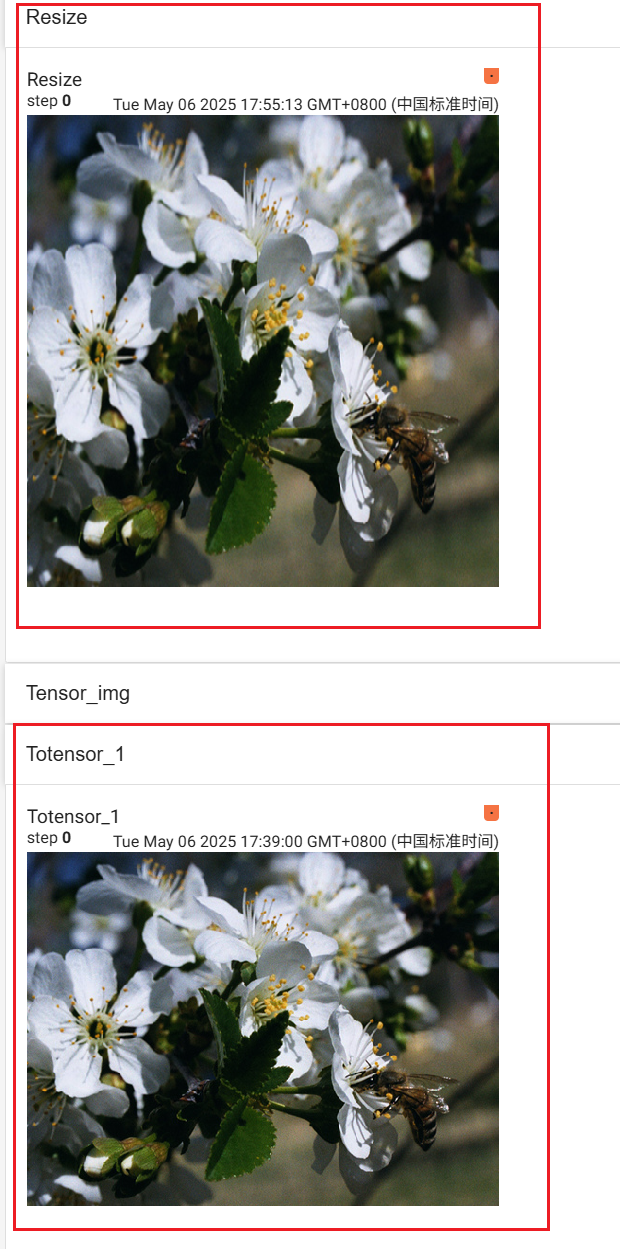
经过resize之后发现图片的尺寸发生了改变
2.5 Compose的使用
transforms.Compose 作用是将多个图像变换操作组合成一个操作序列
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)# ToTensor
trans_totensor = transforms.ToTensor();
img_tensor = trans_totensor(img)
writer.add_image("Totensor_1",img_tensor)# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)writer.close()
当需要对图像依次进行多个变换时,如先调整大小再转为张量,若不使用 Compose ,每次都要分别调用变换函数,代码冗余。使用 Compose 可将多个变换整合,只需一次调用组合操作就能按顺序执行所有变换。如代码中 trans_compose = transforms.Compose([trans_resize_2, trans_totensor]) ,把 Resize(调整图像大小)和 ToTensor(转换为张量)操作组合,后续 img_resize_2 = trans_compose(img) 调用一次,就相当于依次执行了这两个操作。
运行结果

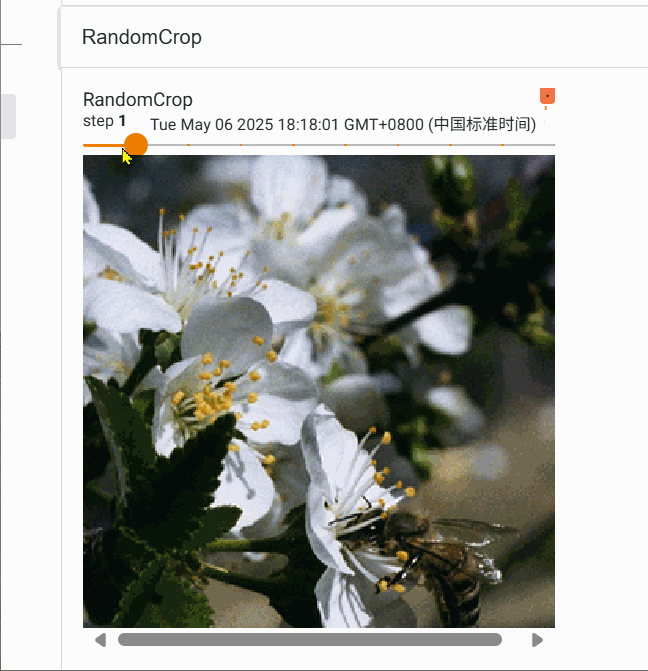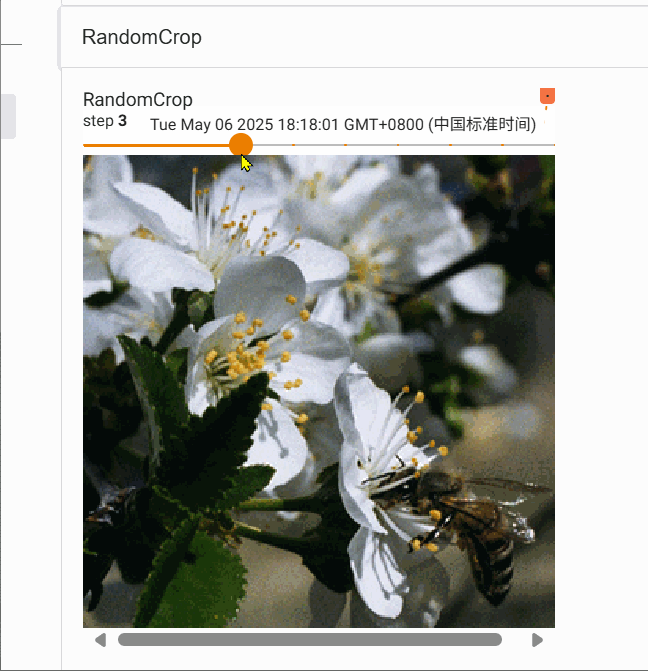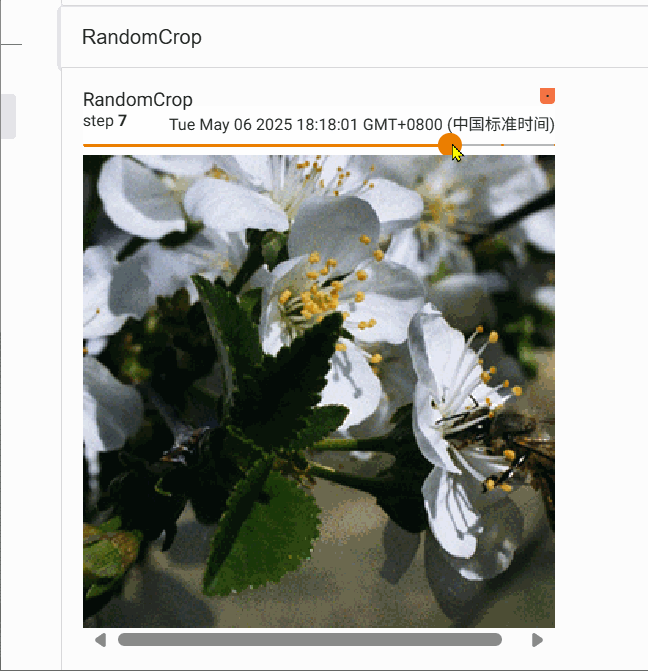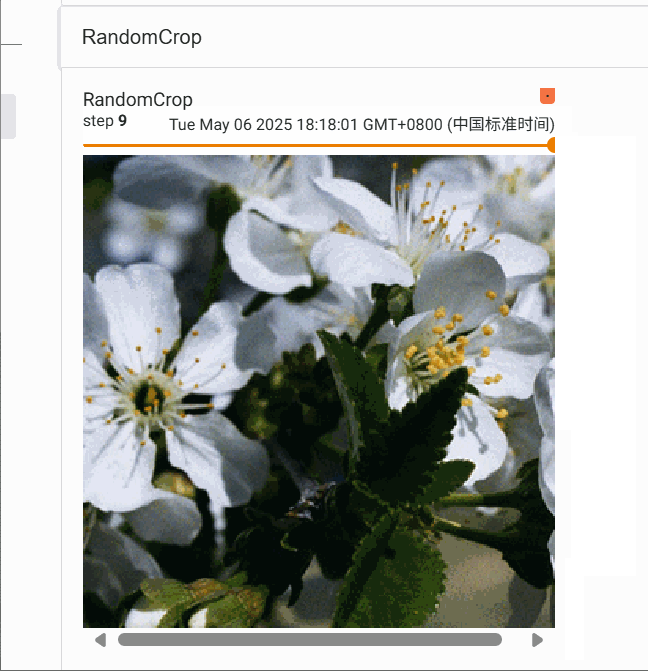
2.6 RandomCrop的使用
transforms.RandomCrop 是 torchvision 库中用于图像数据增强的一个类,主要作用是对输入图像进行随机裁剪,增加数据多样性,提升模型泛化能力。

trans_random = transforms.RandomCrop(300)
transforms.RandomCrop 类的构造函数形式为 transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode=‘constant’) :
size:必填参数 ,用于指定裁剪后图像的尺寸。可以是一个整数,若为整数,则表示裁剪出的正方形图像边长;也可以是 (h, w) 形式的元组,分别代表裁剪后图像的高度 h 和宽度 w 。代码中 300 表示裁剪出边长为 300 像素的正方形图像。
padding:可选参数,用于指定在图像四周填充的像素数。若为整数,图像上下左右均匀填充该整数个像素;若为序列(如二元组或四元组),有不同的填充规则 。例如 padding = 4 ,图像四周都填充 4 个像素;若为 (2, 4) ,表示左右填充 2 个像素,上下填充 4 个像素;若为 (1, 2, 3, 4) ,则依次对应左、上、右、下填充的像素数。
pad_if_needed:可选参数,布尔值。若设为 True ,当图像尺寸小于裁剪尺寸时,会对图像进行填充,使其满足裁剪要求;默认 False ,若图像尺寸小于裁剪尺寸会报错 。
fill:可选参数,用于指定填充的值。当 padding_mode 为 ‘constant’ 时有效。若为整数,各通道填充该值;若为长度为 3 的元组,对应 RGB 通道填充的值 。
padding_mode:可选参数,指定填充模式,有 ‘constant’(常量填充) 、‘edge’(按图像边缘像素值填充)等 4 种模式。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformswriter = SummaryWriter("logs")
img = Image.open("dataset/train/bees/92663402_37f379e57a.jpg")
print(img)# ToTensor
trans_totensor = transforms.ToTensor();
img_tensor = trans_totensor(img)
writer.add_image("Totensor_1",img_tensor)# Normalize
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm)# Resize
print(img.size)
trans_resize = transforms.Resize((512,512))img_resize = trans_resize(img)
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize", img_resize, 0)# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)# RandomCrop
trans_random = transforms.RandomCrop(300)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image("RandomCrop", img_crop,i)writer.close()
我们对图片随机裁剪10次,得到的结果
3.一些技巧
