# 从零构建一个简单的卷积神经网络:手写数字识别
从零构建一个简单的卷积神经网络:手写数字识别
在深度学习的世界里,卷积神经网络(CNN)是处理图像数据的强大工具。今天,我们将通过一个简单的例子,从零开始构建一个CNN模型,用于手写数字识别。这个过程不仅展示了CNN的基本结构,还涉及了数据准备、模型训练和测试的完整流程。希望通过这篇文章,你能对CNN有一个更直观的理解。
数据准备
在机器学习中,数据是基础。我们首先需要准备用于训练和测试的数据。在这个例子中,我们模拟了一个手写数字数据集。每个样本包含一个20x20像素的图像和一个对应的标签(0-9)。为了简化,我们直接生成了随机数据,但在实际应用中,你可能会从文件中读取数据。
data = np.random.rand(5000, 401) # 5000个样本,每个样本401个特征(20x20像素+1个标签)
X = data[:, :-1].reshape(-1, 1, 20, 20) # 输入数据,20x20像素
y = data[:, -1].astype(int) # 目标标签
接下来,我们将数据分为训练集和测试集,并将它们转换为PyTorch张量。这是深度学习中常见的步骤,因为PyTorch框架需要张量作为输入。
train_X, test_X = X[:train_size], X[train_size:]
train_y, test_y = y[:train_size], y[train_size:]
train_X = torch.tensor(train_X, dtype=torch.float32)
test_X = torch.tensor(test_X, dtype=torch.float32)
train_y = torch.tensor(train_y, dtype=torch.long)
test_y = torch.tensor(test_y, dtype=torch.long)
最后,我们使用TensorDataset和DataLoader来创建数据加载器,这使得数据的加载和批处理变得更加方便。
模型定义
CNN的核心在于卷积层和池化层。在我们的模型中,我们定义了两个卷积层和两个池化层,以及两个全连接层。这个结构是CNN的典型设计,适用于处理图像数据。
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.pool = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(64 * 5 * 5, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))x = x.view(-1, 64 * 5 * 5)x = torch.relu(self.fc1(x))x = self.fc2(x)return x
在forward方法中,我们定义了数据通过网络的路径。首先,数据通过两个卷积层和池化层,然后被展平并传递到两个全连接层。最终,模型输出每个类别的概率。
模型训练
模型训练是深度学习中最关键的步骤之一。我们使用交叉熵损失函数和Adam优化器来训练模型。在每个epoch中,我们遍历训练数据,计算损失,然后更新模型的权重。
for epoch in range(num_epochs):model.train()running_loss = 0.0for inputs, labels in train_loader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()running_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {running_loss/len(train_loader)}")
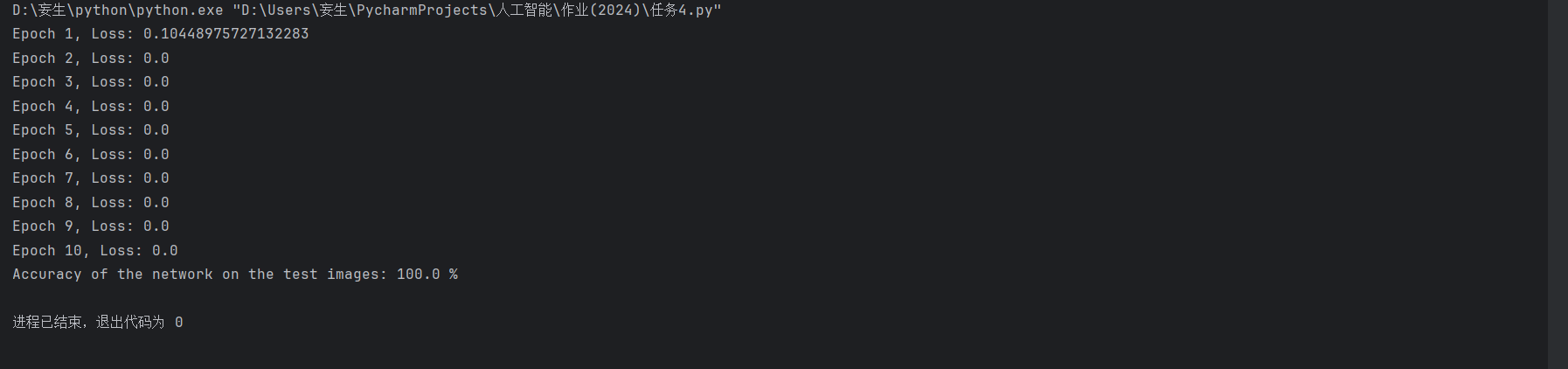
在训练过程中,我们打印每个epoch的平均损失,以便观察模型的训练进度。
模型测试
训练完成后,我们需要测试模型的性能。我们使用测试集来评估模型的准确率。在测试过程中,我们不进行梯度计算,因为这一步只是评估模型的性能。
model.eval()
correct = 0
total = 0
with torch.no_grad():for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the test images: {100 * correct / total} %')
最终,我们计算并打印模型在测试集上的准确率。
总结
通过这个简单的例子,我们展示了如何从零开始构建一个CNN模型,包括数据准备、模型定义、训练和测试的完整过程。虽然我们使用的是随机生成的数据,但这个过程同样适用于真实世界的数据集。希望这篇文章能帮助你更好地理解CNN的工作原理和实现方法。在未来的文章中,我们将探索更多深度学习的应用和技巧。