机器人强化学习入门学习笔记(二)
基于上一篇的《机器人强化学习入门学习笔记》,在基于 MuJoCo 的仿真强化学习训练中,除了 PPO(Proximal Policy Optimization)之外,还有多个主流强化学习算法可用于训练机器人直行或其他复杂动作。
🧠 一、常见强化学习算法对比(可用于 MuJoCo)
| 算法 | 类型 | 特点 | 适合场景 |
|---|---|---|---|
| PPO(Proximal Policy Optimization) | On-policy | 稳定、易调参,训练效率适中 | MuJoCo官方推荐、机器人控制首选 |
| SAC(Soft Actor-Critic) | Off-policy | 探索强、样本效率高 | 多关节复杂任务、稀疏奖励 |
| TD3(Twin Delayed DDPG) | Off-policy | 避免过估计,适合连续控制 | 动作精细控制、稳定性好 |
| DDPG(Deep Deterministic Policy Gradient) | Off-policy | 最早的连续动作算法之一 | 适合学习基础 |
| TRPO(Trust Region Policy Optimization) | On-policy | 稳定但实现复杂 | PPO的前身,现已较少使用 |
✅ 推荐顺序(MuJoCo 中的实用性):PPO > SAC > TD3 > DDPG > TRPO
📌 二、原理讲解(简洁易懂)
(1)PPO算法
PPO 是由 OpenAI 提出的,是一种 策略梯度(Policy Gradient)方法的改进版本,它的目标是:
在不让策略变动太大的前提下,最大化策略更新的期望回报。
🧩 核心思想:限制策略更新幅度
策略梯度方法要优化目标函数:
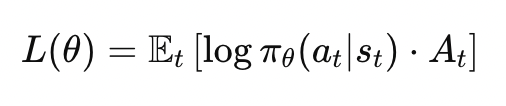
但如果每次更新步长太大,会让策略发散(学崩),所以 PPO 引入了