架构思维:构建高并发读服务_热点数据查询的架构设计与性能调优
文章目录
- 一、引言
- 二、热点查询定义与场景
- 三、主从复制——垂直扩容
- 四、应用内前置缓存
- 4.1 容量上限与淘汰策略
- 4.2 延迟刷新:定期 vs. 实时
- 4.3 逃逸流量控制
- 4.4 热点发现:被动 vs. 主动
- 五、降级与限流兜底
- 六、前端/接入层其他应对
- 七、模拟压测Code
- 八、总结

一、引言
在前面的几篇博客中,
架构思维:使用懒加载架构实现高性能读服务
架构思维:利用全量缓存架构构建毫秒级的读服务
架构思维:异构数据的同步一致性方案
我们依赖全量缓存与 Binlog 同步,实现了零毛刺、百毫秒级延迟的读服务,且分布式部署后轻松承载百万 QPS。但这里的“百万”是指 百万不同用户 的并发请求。
百万请求属于不同用户的架构图
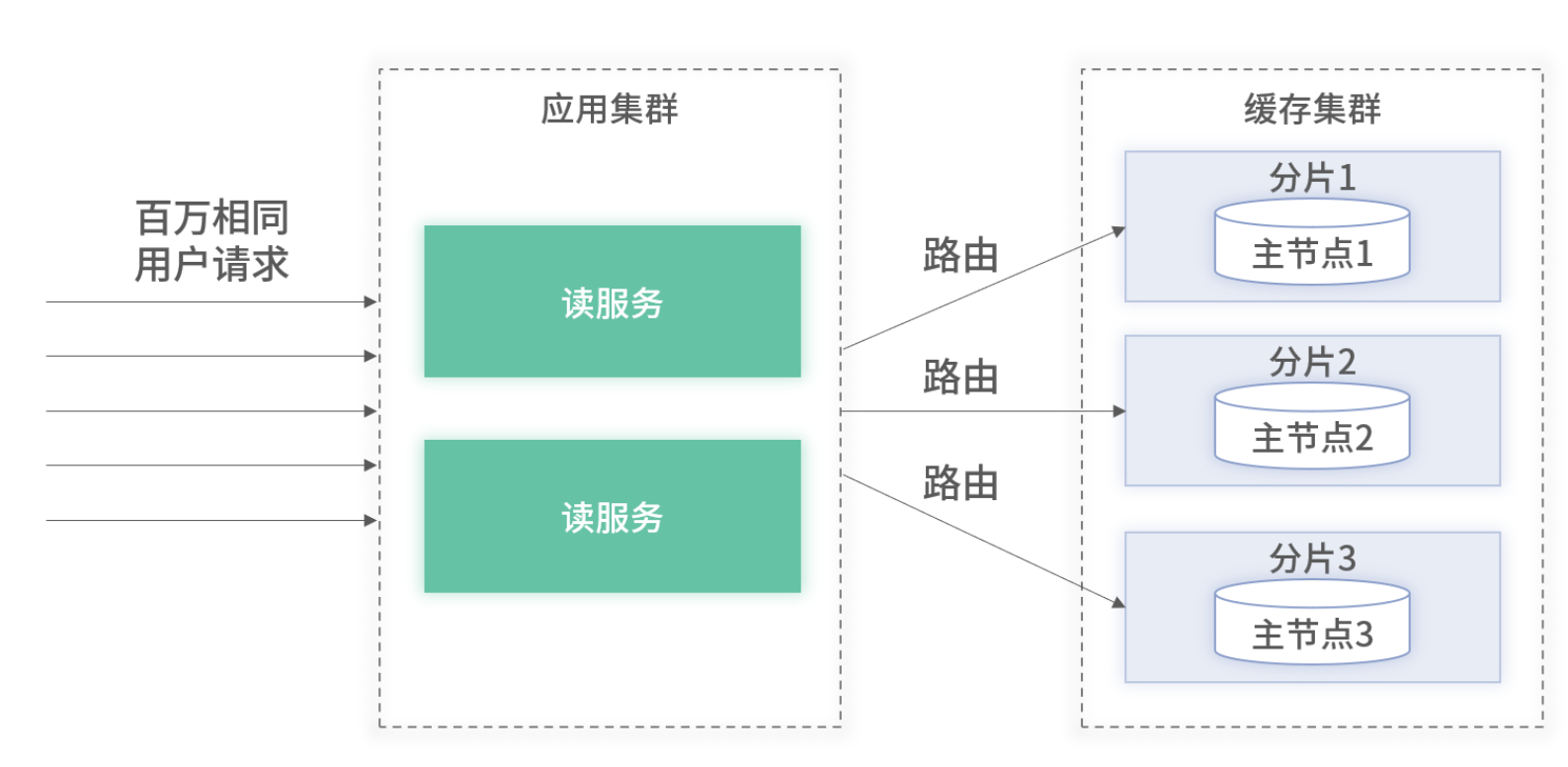
假设一个节点最大能够支撑 10W QPS,我们只需要在集群中部署 10 台节点即可支持百万流量。
当这百万请求都集中到同一用户时(即同一键热点查询),传统集群方案将不堪重负——单节点路由所有流量,硬件和程序性能都无法无限扩容。
当百万 QPS 都属于同一用户时,即使缓存是集群化的,同一个用户的请求都会被路由至集群中的某一个节点
百万请求属于相同用户的架构图
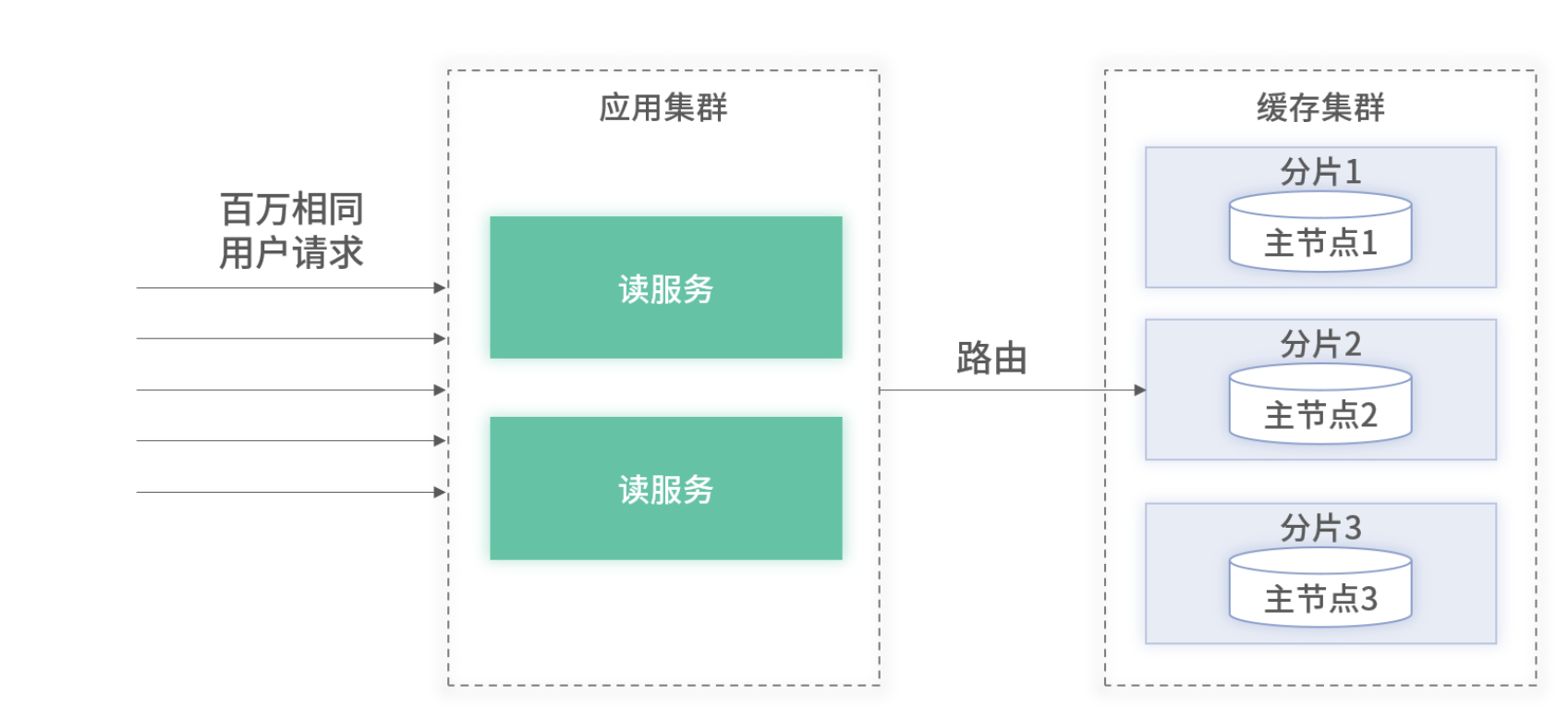
即使此节点的机器配置非常好,当前能够支持住百万 QPS。但随着流量上涨,它也无法满足未来的流量诉求。原因有 2 点:
-
单台机器无法无限升级;
-
缓存程序本身也是有性能上限的。
这里我们讲将聚焦**单用户百万并发(热点查询)**场景,剖析架构瓶颈并给出多层次应对策略。
二、热点查询定义与场景
热点查询:对同一数据项发生极高频率的重复读取。
典型场景:
- 社交媒体热点内容(某条微博、热搜话题)。
- 电商秒杀商品详情持续刷新。
- 网站排行榜页/直播间房间信息。
这些场景下,同一个 Key 的请求会被路由到同一缓存分片或服务实例,导致“集中过载”。
三、主从复制——垂直扩容
主从复制应对热点的架构图
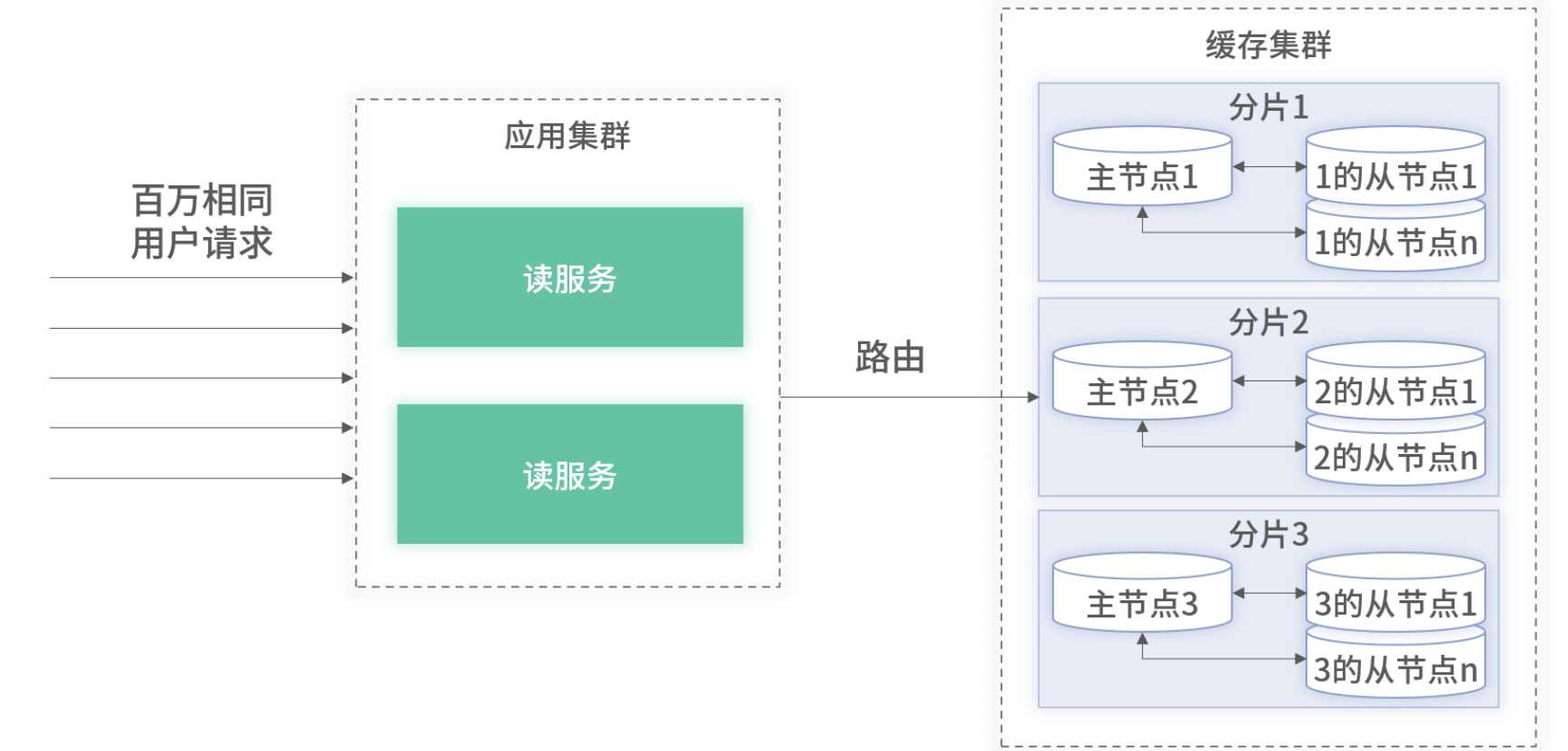
思路:利用缓存的主从复制机制,开启 随机读 策略,让同一 Key 的并发请求分散到主+多个从节点。
在查询时,将应用内的缓存客户端开启主从随机读。此时,包含一个从的分片的并发能力,可以提升至原来的一倍。随着从节点的增加,单分片的并发性能会不断翻倍。这对于所有请求只会命中某一个固定单分片的热点查询能够很好地应对。
但此方案存在一个较大的问题,就是浪费资源。
主从复制除了有应对热点的功能,另外一个主要作用是为了高可用。当集群中的某一个主节点发生故障后,集群高可用模块会自动对该节点进行故障迁移,从该节点所属分片里选举一个从节点为主节点。为了高可用模块在故障转移时的逻辑能够简单清晰并做到统一,会将集群的从节点数量设置为相同数量。
相同从节点数量也带来了较大的资源浪费。为了应对热点查询,需要不断扩容从分片。但热点查询只会命中其中一个分片,这就导致所有其他分片的从节点全部浪费了。为了节约资源,可以对高可用模块进行改造,不强制所有分片的从节点必须相同,但这个代价也是非常高昂的。另外,热点查询很多时候是随时出现的,并不能提前预测,所以提前扩容某一个分片意义并不大。
- 优点:实现简单,只需客户端配置;
- 扩展:每加一个从节点,分片吞吐线性提升;
- 缺点:资源浪费——为热点单一分片预留大量从节点,而其他分片则闲置;
- 改造:可自定义高可用中间件配置,按需增减分片,从而降低浪费。
总的来说,主从复制能够解决一定流量的热点查询且实施起来较简单。但不具备扩展性,在应对更大流量的热点时会有些吃力。
四、应用内前置缓存
热点查询特点:请求次数多、数据项少。可在业务应用进程内维护一份本地缓存,彻底分散热流量。
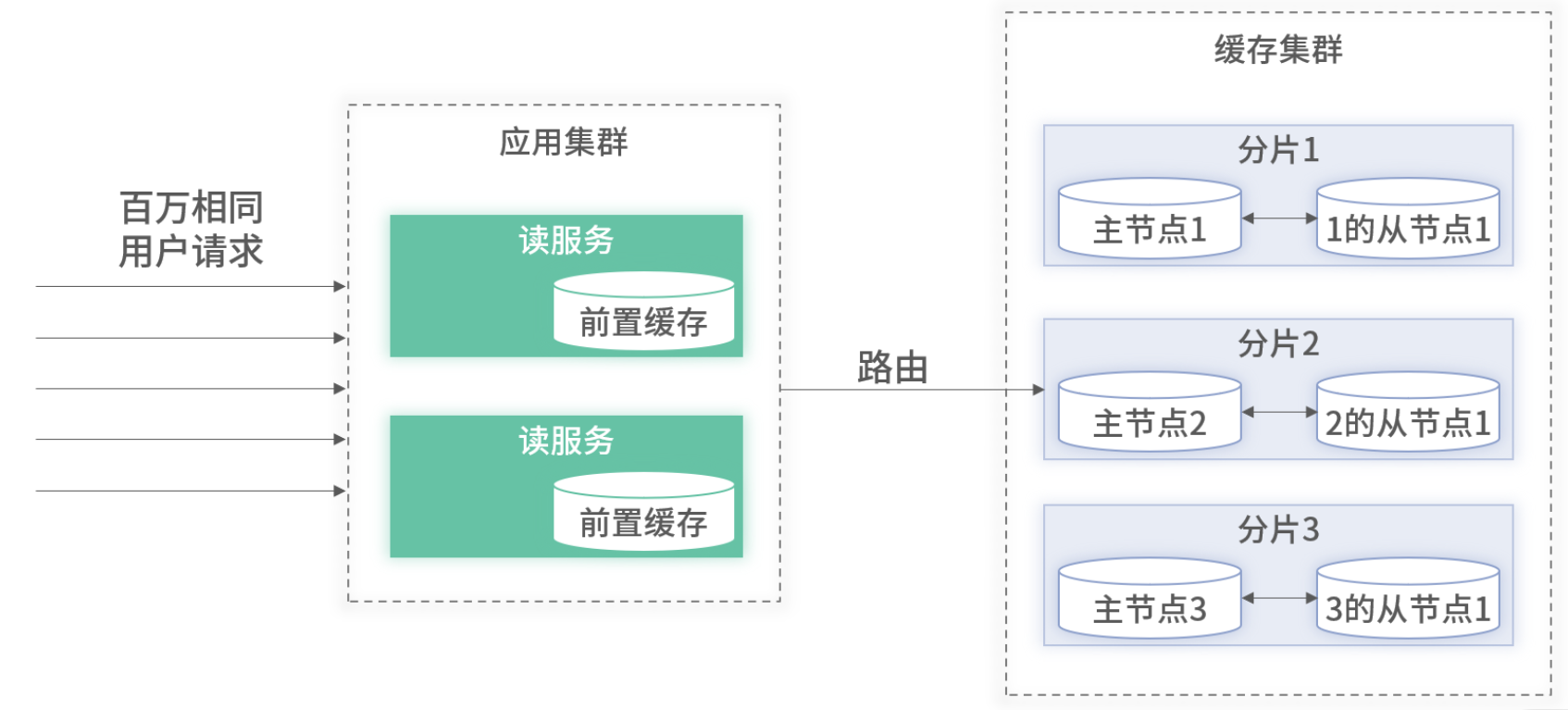
4.1 容量上限与淘汰策略
- 设置缓存上限,采用 LRU 淘汰最少访问条目;
- 配合 TTL,过期未访问的数据自动释放。
4.2 延迟刷新:定期 vs. 实时
- 定期刷新:设置过期时间后,按周期批量更新,简单高效;
- 实时刷新:借助异构判断层+MQ,主动推送变更,仅针对热点更新,需额外组件支持。
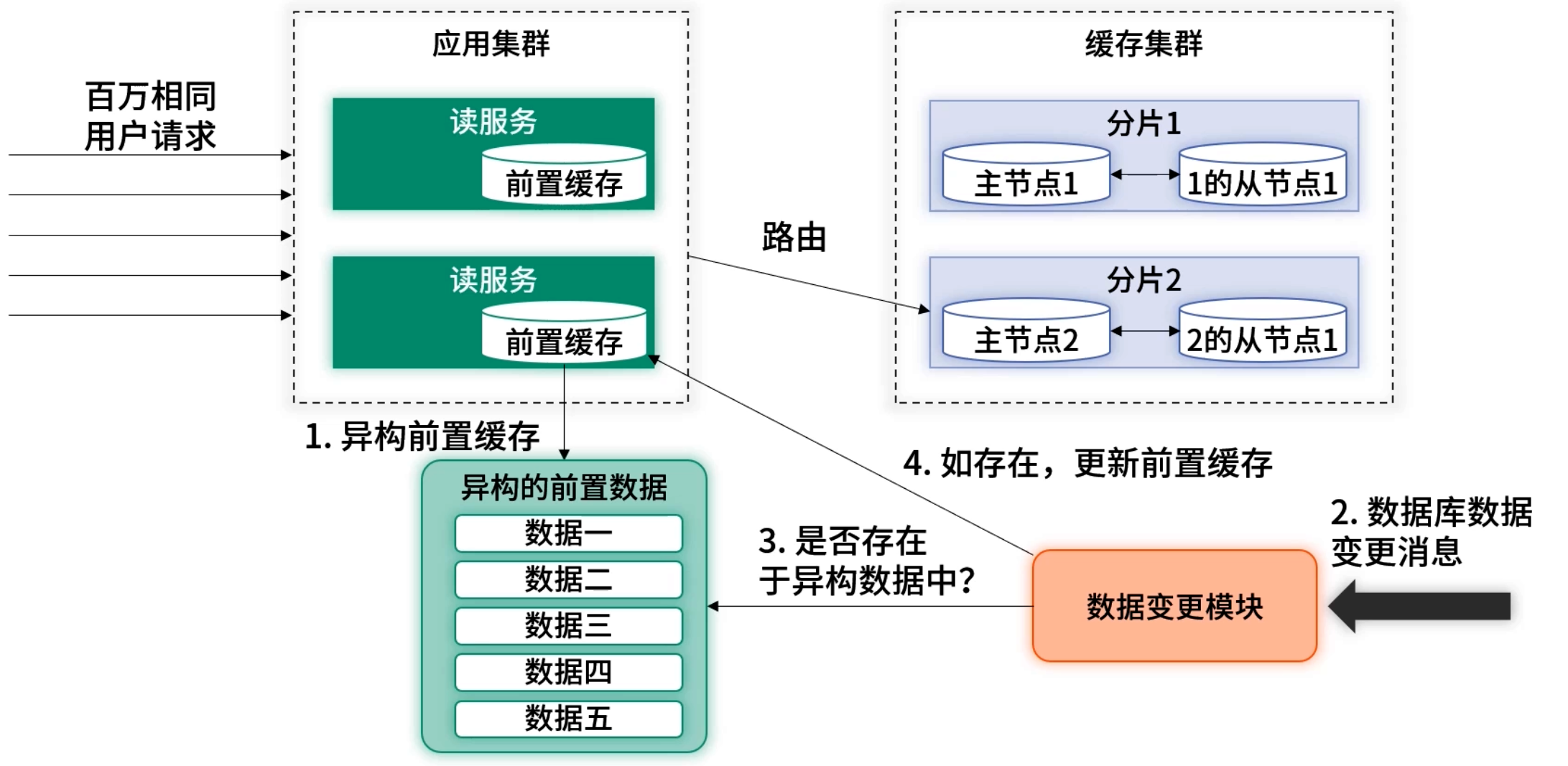
4.3 逃逸流量控制
再者要把控好瞬间的逃逸流量
应用初始化时,前置缓存是空的。假设在初始化时,瞬间出现热点查询,所有的热点请求都会逃逸到后端缓存里。可能这个瞬间热点就会把后端缓存打挂。
其次,如果前置缓存采用定期过期,在过期时若将数据清理掉,那么所有的请求都会逃逸至后端加载最新的缓存,也有可能把后端缓存打挂。这两种情况对应的流程图如下图所示:
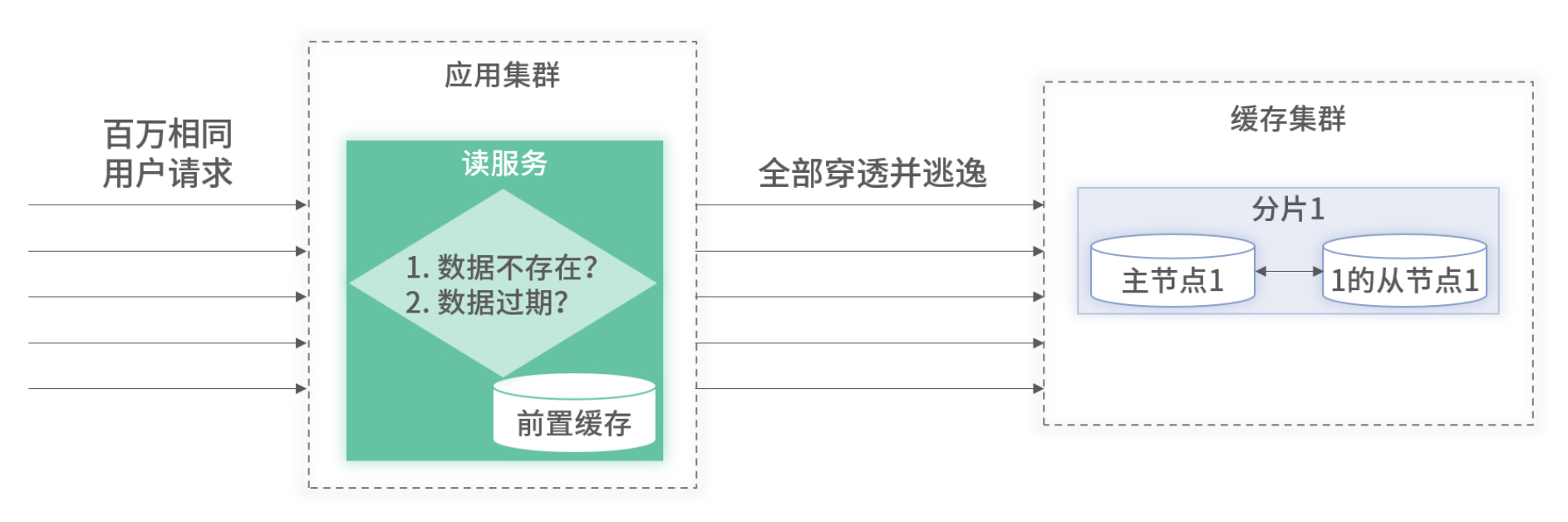
对于这两种情况,可以对逃逸流量进行前置等待或使用历史数据的方案。不管是初始化还是数据过期,在从后端加载数据时,只允许一个请求逃逸。这样最大的逃逸流量为部署的应用总数,量级可控。架构如下图 所示

- 初始化或过期瞬间,只允许 1 个 请求穿透后端加载并更新本地缓存;
- 其他并发请求 等待(带超时)或 返回历史脏数据,防止短时洪峰打挂后端。
4.4 热点发现:被动 vs. 主动
除了需要应对热点缓存,另外一个重点就是如何发现热点缓存。对于发现热点有两个方式,一种是被动发现,另外一种是主动发现。
- 被动:凭借本地缓存容量和 LRU 策略,自然淘汰非热点,热点常驻;
被动发现是借助前置缓存有容量上限实现的。在被动发现的方案里,读服务接受到的所有请求都会默认从前置缓存中获取数据,如不存在,则从缓存服务器进行加载。因为前置缓存的容量淘汰策略是 LRU,如果数据是热点,它的访问次数一定非常高,因此它一定会在前置缓存中。借助前置缓存的容量上限和淘汰策略,即实现了热点发现。
但此方式也存在一个问题——所有的请求都优先从前置缓存获取数据,并在未查询到时加载服务端数据到本地的前置缓存里,此方式也会把非热点数据存储至前置缓存里,导致非热点数据产生非必要的延迟性。
- 主动:在缓存层或接入层统计访问频次,超过阈值后 推送 到本地缓存,避免误入冷数据。
主动发现则需要借助一些外部计数工具来实现热点的发现。外部计数工具的思路大体比较类似,都是在一个集中的位置对于请求进行计数,并根据配置的阈值判断某请求是否会命中数据。对于判定为热点的数据,主动的推送至应用内的前置缓存即可。下图为在缓存服务器进行计数的架构方案:
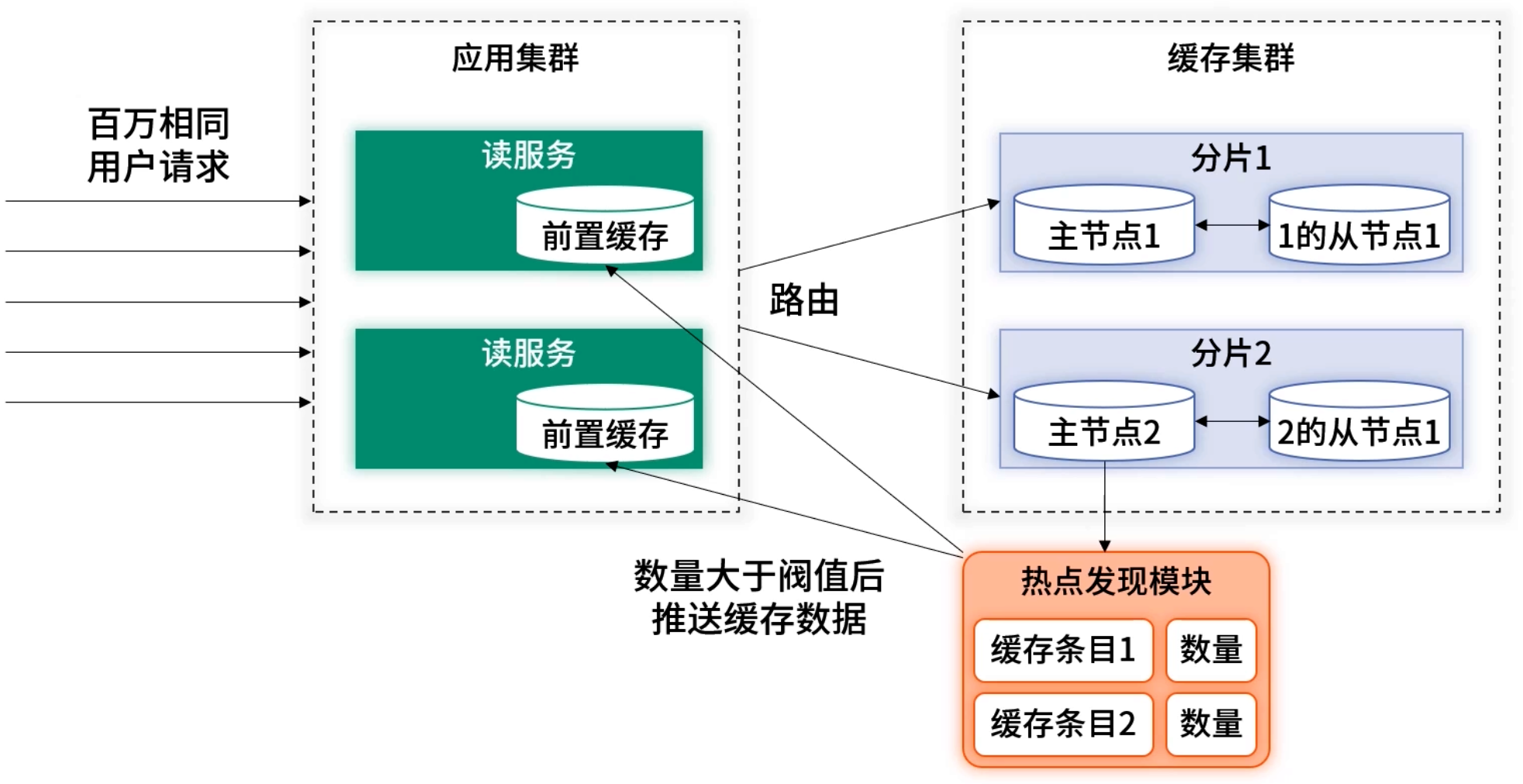
采用主动发现的架构后,读服务接受到请求后仍然会默认的从前置缓存获取数据,如获取到即直接返回。如未获取到,会穿透去查询后端缓存的数据并直接返回。但穿透获取到的数据并不会写入本地前置缓存。数据是否为热点且是否要写入前置缓存,均由计数工具来决定。此方案很好地解决了因误判断带来的延迟问题。
五、降级与限流兜底
在采用了前置缓存并解决了上述四大类问题之后,当再次遇到百万级并发时,基本没什么疑难问题了。但这里还存在一个前置条件,即当热点查询发生时,你所部署的容器数量所能支撑的 QPS 要大于热点查询的 QPS。
但实际情况并非如此,所部署的机器能够支持的 QPS 未必都能够大于当次的热点查询。对于可能出现的超预期流量,可以使用前置限流的策略进行应对。在系统上线前,对于开启了前置缓存的应用进行压测,得到单机最大的 QPS。根据压测值设置单机的限流阈值,阈值可以设置为压测值的一半或者更低。设置为压测阈值的一半或更低,是因为压测时应用 CPU 基本已达到 100%,为了保证线上应用能够正常运转,是不能让 CPU 达到 100% 的
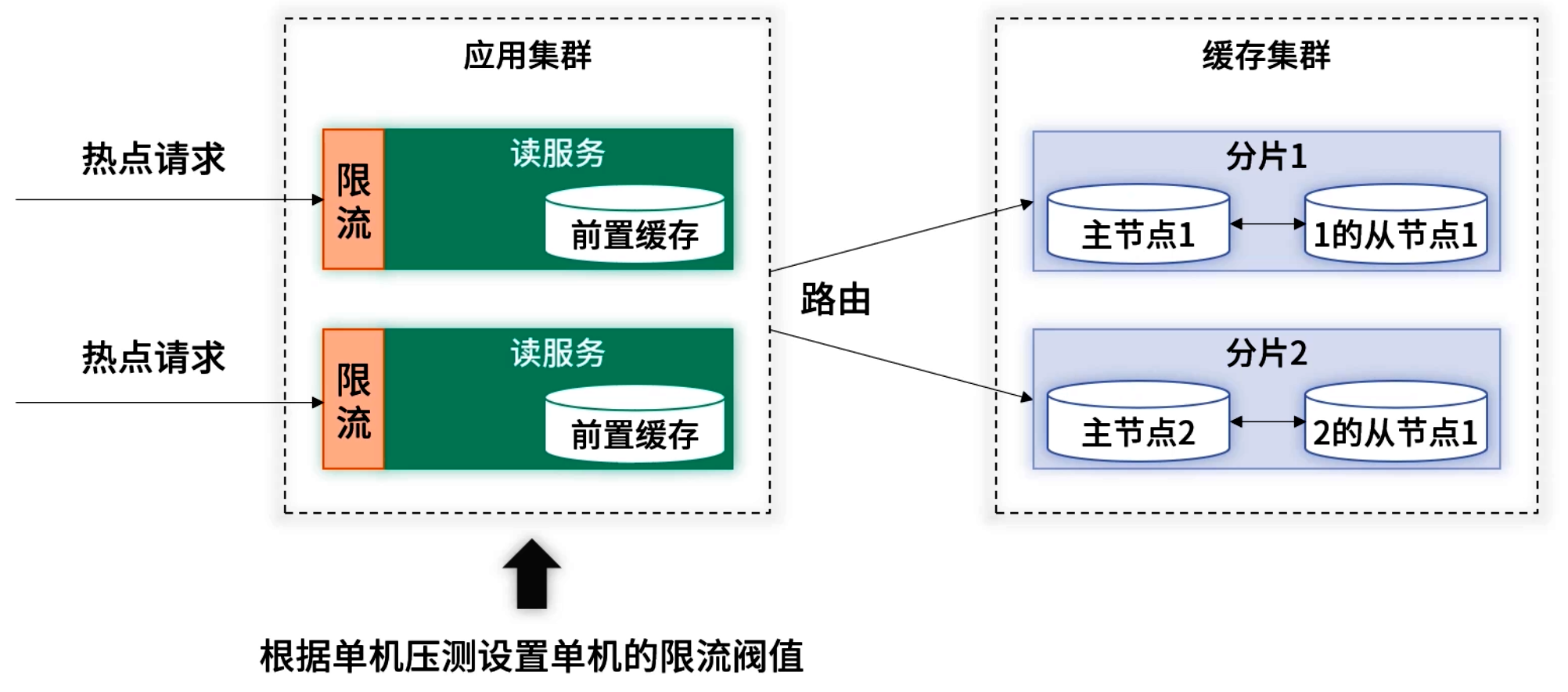
即便前置缓存和后端扩展俱全,也难保偶发超预期洪峰不至于打满资源。
- 前置限流:根据单机压测 QPS 设定阈值(如 50% 负载),超过即返回降级策略或失败;
- 降级内容:可返回缓存的历史值、静态页面或友好提示。
六、前端/接入层其他应对
在网络边界亦可做热点缓解:
- Nginx/接入层缓存:对热点 Key 做短时缓存;
- CDN/边缘缓存:将热点内容推至离用户更近节点;
- 浏览器缓存:HTTP Cache-Control 头设置合理 TTL。
七、模拟压测Code
import com.github.benmanes.caffeine.cache.LoadingCache;
import com.github.benmanes.caffeine.cache.Caffeine;import java.util.concurrent.TimeUnit;/*** FrontCacheBenchmark.java* 示例:基于 Java + Caffeine 实现前置缓存的性能对比*/
public class FrontCacheBenchmark {// 模拟后端数据源加载private static String loadFromBackend(String key) {try {// 模拟网络/数据库延迟TimeUnit.MILLISECONDS.sleep(10);} catch (InterruptedException e) {Thread.currentThread().interrupt();}return "Value-for-" + key;}public static void main(String[] args) {final int WARM_UP = 1_000;final int TEST_OPS = 100_000;final String HOT_KEY = "hot-item";// 1. 构建 Caffeine LoadingCache,自动加载逻辑LoadingCache<String, String> cache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(5, TimeUnit.MINUTES).build(FrontCacheBenchmark::loadFromBackend);// 2. 预热缓存for (int i = 0; i < WARM_UP; i++) {cache.get(HOT_KEY);}// 3. 测试缓存命中性能long startHits = System.nanoTime();for (int i = 0; i < TEST_OPS; i++) {cache.get(HOT_KEY);}long endHits = System.nanoTime();// 4. 测试直接后端加载性能long startMisses = System.nanoTime();for (int i = 0; i < TEST_OPS; i++) {loadFromBackend(HOT_KEY);}long endMisses = System.nanoTime();double avgHitLatencyMs = (endHits - startHits) / 1e6 / TEST_OPS;double avgMissLatencyMs = (endMisses - startMisses) / 1e6 / TEST_OPS;double throughputWithCache = TEST_OPS / ((endHits - startHits) / 1e9);double throughputWithout = TEST_OPS / ((endMisses - startMisses) / 1e9);System.out.println("=== Performance Comparison ===");System.out.printf("Operation | Avg Latency (ms) | Throughput (ops/sec)%n");System.out.printf("----------------+------------------+--------------------%n");System.out.printf("Cache Hit | %8.6f | %10.0f%n", avgHitLatencyMs, throughputWithCache);System.out.printf("Backend Direct | %8.6f | %10.0f%n", avgMissLatencyMs, throughputWithout);}
}八、总结
- 单一用户百万 QPS 需额外考虑热点路由压力;
- 主从复制 简单易行但资源浪费;
- 应用内前置缓存 从四大维度(容量、刷新、逃逸、发现)精细打磨;
- 限流降级 是最后的安全阀;
- 前端与接入层也可层层加固。
