自注意力(Self-Attention)和位置编码
自注意力
-
给定序列 x 1 , … , x n \mathbf{x}_1, \ldots, \mathbf{x}_n x1,…,xn, ∀ x i ∈ R d \forall \mathbf{x}_i \in \mathbb{R}^d ∀xi∈Rd
-
自注意力池化层将 x i \mathbf{x}_i xi 当做key, value, query来对序列抽取特征得到 y 1 , … , y n \mathbf{y}_1, \ldots, \mathbf{y}_n y1,…,yn, 这里
y i = f ( x i , ( x 1 , x 1 ) , … , ( x n , x n ) ) ∈ R d \mathbf{y}_i = f(\mathbf{x}_i, (\mathbf{x}_1, \mathbf{x}_1), \ldots, (\mathbf{x}_n, \mathbf{x}_n)) \in \mathbb{R}^d yi=f(xi,(x1,x1),…,(xn,xn))∈Rd
与 CNN、RNN 的比较
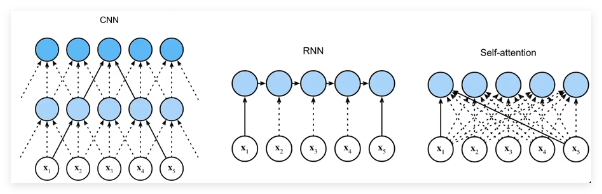
| CNN | RNN | 自注意力 | |
|---|---|---|---|
| 计算复杂度 | O( k n d 2 knd^2 knd2) | O( n d 2 nd^2 nd2) | O( n 2 d n^2d n2d) |
| 并行度 | O( n n n) | O( 1 1 1) | O( n n n) |
| 最长路径 | O( n / k n/k n/k) | O( n n n) | O( 1 1 1) |
位置编码
- 跟CNN/RNN不同,自注意力并没有记录位置信息
- 位置编码将位置信息注入到输入里
- 假设长度为 n n n 的序列是 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d,那么使用位置编码矩阵 P ∈ R n × d \mathbf{P} \in \mathbb{R}^{n \times d} P∈Rn×d 来输出 X + P \mathbf{X} + \mathbf{P} X+P 作为自编码输入
- P \mathbf{P} P 的元素如下计算:
p i , 2 j = sin ( i 1000 0 2 j / d ) , p i , 2 j + 1 = cos ( i 1000 0 2 j / d ) p_{i,2j} = \sin\left(\frac{i}{10000^{2j/d}}\right), \quad p_{i,2j+1} = \cos\left(\frac{i}{10000^{2j/d}}\right) pi,2j=sin(100002j/di),pi,2j+1=cos(100002j/di)
位置编码矩阵
- P ∈ R n × d \mathbf{P} \in \mathbb{R}^{n \times d} P∈Rn×d: p i , 2 j = sin ( i 1000 0 2 j / d ) , p i , 2 j + 1 = cos ( i 1000 0 2 j / d ) p_{i,2j} = \sin\left(\frac{i}{10000^{2j/d}}\right), \quad p_{i,2j+1} = \cos\left(\frac{i}{10000^{2j/d}}\right) pi,2j=sin(100002j/di),pi,2j+1=cos(100002j/di)
相对位置信息
-
位于 i + δ i+\delta i+δ 处的位置编码可以线性投影位置 i i i 处的位置编码来表示
-
记 ω j = 1 / 1000 0 2 j / d \omega_j = 1/10000^{2j/d} ωj=1/100002j/d,那么

总结
- 自注意力池化层将 x i \mathbf{x}_i xi 当做key, value, query来对序列抽取特征
- 完全并行、最长序列为1、但对长序列计算复杂度高
- 位置编码在输入中加入位置信息,使得自注意力能够记忆位置信息
代码实现
首先导入必要的环境
import math
import torch
from torch import nn
from d2l import torch as d2l
自注意力
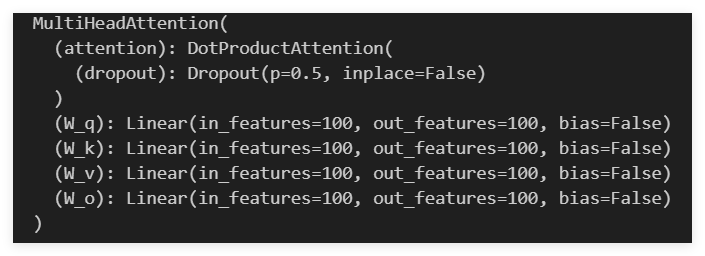
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,num_hiddens, num_heads, 0.5)
attention.eval()
位置编码
#@save
class PositionalEncoding(nn.Module):"""位置编码"""def __init__(self, num_hiddens, dropout, max_len=1000):"""初始化位置编码类参数:num_hiddens: int编码的隐藏维度大小(即每个位置的编码维度)dropout: floatDropout的概率,用于防止过拟合max_len: int, 默认值为1000最大序列长度,用于生成足够长的位置编码矩阵"""super(PositionalEncoding, self).__init__()# 定义Dropout层,用于在前向传播中随机丢弃部分神经元self.dropout = nn.Dropout(dropout)# 创建一个形状为 (1, max_len, num_hiddens) 的位置编码矩阵 P# 其中 1 表示批量维度,max_len 表示序列长度,num_hiddens 表示编码维度self.P = torch.zeros((1, max_len, num_hiddens))# 生成位置索引的张量,形状为 (max_len, 1)# 每个位置索引除以 10000 的幂次,幂次由编码维度决定X = torch.arange(max_len, dtype=torch.float32).reshape(-1, 1) / torch.pow(10000, torch.arange(0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)# 对编码维度的偶数索引位置应用正弦函数self.P[:, :, 0::2] = torch.sin(X)# 对编码维度的奇数索引位置应用余弦函数self.P[:, :, 1::2] = torch.cos(X)def forward(self, X):"""前向传播函数,将位置编码添加到输入张量 X 上参数:X: torch.Tensor输入张量,形状为 (batch_size, seq_len, num_hiddens)返回:torch.Tensor添加了位置编码的张量,形状与输入张量相同"""# 将位置编码矩阵 P 的前 seq_len 个位置与输入张量 X 相加# 并将 P 移动到与 X 相同的设备(如 GPU 或 CPU)X = X + self.P[:, :X.shape[1], :].to(X.device)# 应用 Dropout 并返回结果return self.dropout(X)
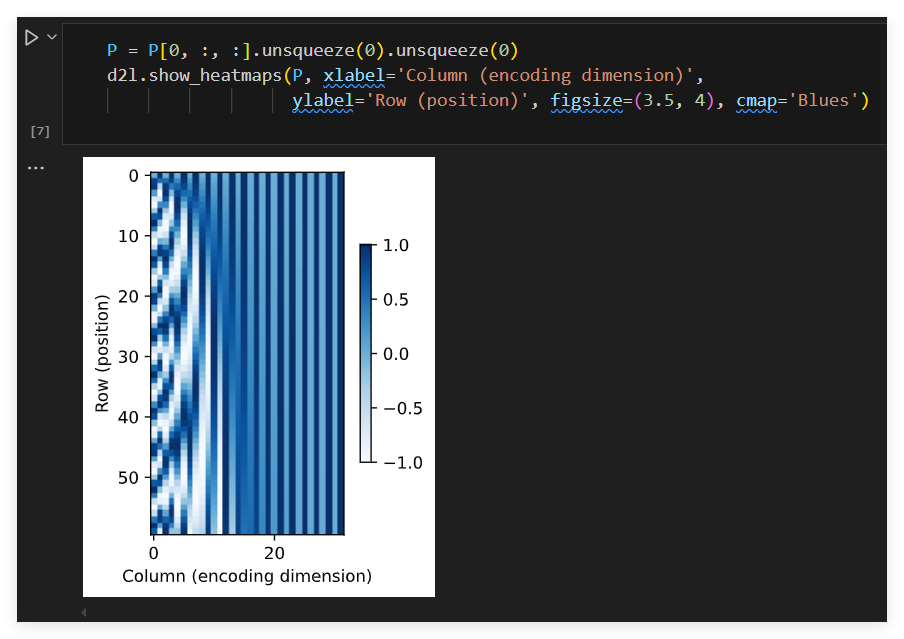
行代表标记在序列中的位置,列代表位置编码的不同维度
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
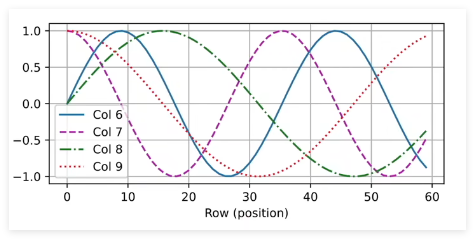
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
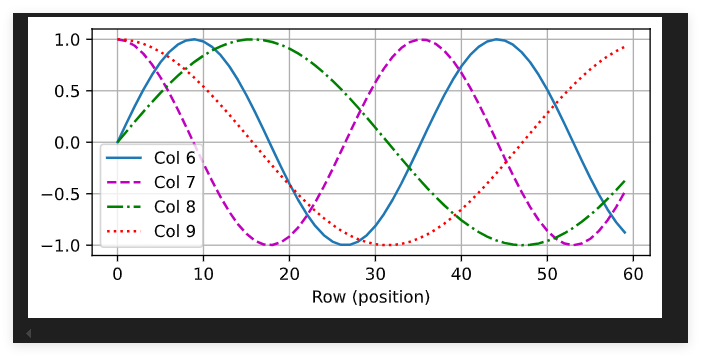
在编码维度上降低频率