英伟达语音识别模型论文速读:Fast Conformer
Fast Conformer:一种具有线性可扩展注意力的高效语音识别模型
一、引言
Conformer 模型因其结合了深度可分离卷积层和自注意力层的优势,在语音处理任务中取得了出色的性能表现。然而,Conformer 模型存在计算和内存消耗大的问题,这主要是由于自注意力层具有二次时间与内存复杂度。为了解决这些问题,本文提出了 Fast Conformer(FC)模型,通过重新设计下采样方案和引入局部注意力与全局上下文令牌相结合的方式,显著提升了模型的效率和可扩展性。
二、Fast Conformer 架构
(一)下采样方案
-
对比现有方法
-
Conformer 的下采样模块使帧率从 10ms 提升到 40ms,序列长度减少 4 倍,降低了后续注意力层的计算与内存成本,但该模块计算成本占比高。
-
EfficientConformer 采用渐进式下采样,在不同层分别进行 2 倍、2 倍、2 倍下采样,使语音特征序列长度减少 8 倍,但存在不同注意力层间计算不平衡的问题。
-
Squeezeformer 结合渐进式下采样与时间 U-Net 结构,在编码器中间增加额外下采样,末尾添加上采样层恢复 4 倍时间分辨率。
-
-
Fast Conformer 的改进
-
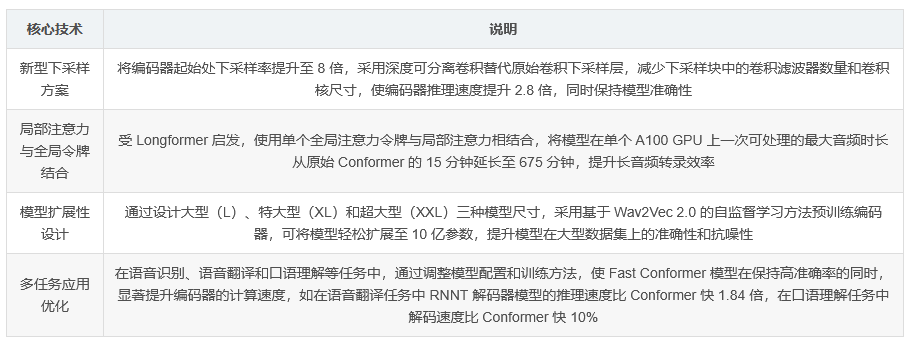
将编码器起始处的下采样率提升至 8 倍,减少后续注意力层计算成本 4 倍。
-
用深度可分离卷积替代原始卷积下采样层,降低计算成本。
-
将下采样块中的卷积滤波器数量从 512 减至 256,卷积核尺寸从 31 降至 9。这些改进使编码器推理速度提升 2.8 倍,同时保持模型准确性。
-
(二)长音频转录
为解决标准多头注意力层在处理长序列时因二次扩展受限的问题,Fast Conformer 采用受 Longformer 启发的局部注意力与全局令牌相结合的方法。使用单个全局注意力令牌,其关注所有其他令牌,其他令牌也关注它,而其他令牌在固定大小窗口内进行注意力计算。通过这种方式,将模型在单个 A100 GPU 上一次可处理的最大音频时长从原始 Conformer 的 15 分钟延长至 675 分钟。
三、实验
(一)语音识别实验
-
数据集与模型配置
-
在 LibriSpeech、多语言 LibriSpeech 英文部分、Mozilla Common Voice 和 Wall Street Journal 等英语 ASR 基准测试上评估 Fast Conformer 模型。
-
使用 Fast Conformer-RNNT 和 Fast Conformer-CTC 模型以及基线 Conformer 模型的大型配置进行实验。对于 LibriSpeech 数据集,采用 SentencePiece 单词单元 tokenizer,CTC 模型使用 128 个令牌,RNNT 模型使用 1024 个令牌。
-
-
实验结果
-
在 LibriSpeech 数据集上,Fast Conformer 的准确率略高于常规 Conformer,其计算效率是原始 Conformer 编码器的 3 倍,且比 EfficientConformer 和 SqueezeFormer 快得多。
-
在包含 25k 小时语音的大数据集上训练时,Fast Conformer 在大多数基准测试中超越了原始 Conformer。
-
(二)语音翻译实验
-
实验设置
-
分析 Fast Conformer 在英语到德语的语音翻译任务中的有效性,训练两种架构模型,它们具有相同的 Conformer 类编码器和不同的自回归解码器,解码器分别为 RNNT 或 6 层 Transformer,使用交叉熵损失训练。
-
编码器初始化权重来自在 25k 小时语音上训练的 ASR RNNT 模型,解码器和联合模块参数随机初始化,词汇表包含 16384 个 YouTokenToMe 字节对编码。
-
-
实验结果
- Fast Conformer 在 RNNT 解码器模型上获得 27.89 的 BLEU 分数,且推理速度比 Conformer 快 1.84 倍。
(三)口语理解实验
-
任务描述
- 研究语音意图分类和插槽填充任务,该任务旨在检测用户意图并提取对应实体插槽的词汇填充。
-
实验结果
- 使用 SLURP 数据集进行实验,Fast Conformer 在该任务上的准确率接近 Conformer,解码速度比 Conformer 快 10%。与 ESPNet-SLU 和 SpeechBrain-SLU 模型相比,预训练的 Fast Conformer 编码器模型在准确率上显著超过这些在近 60K 小时语音上进行自监督预训练的模型。
(四)长音频转录实验
-
模型训练与评估
-
Fast Conformer 在带有有限上下文和全局令牌的情况下,使用与全上下文预训练相同的内部 25k 小时数据集进行额外的 10k 步微调。
-
在 TED-LIUM v3 和 Earnings-21 两个长音频数据集上评估模型性能,使用 Whisper 正规化对转录和预测进行评估。
-
-
实验结果
- Fast Conformer 新的注意力机制模型在两个长形式 ASR 基准测试集上均显著优于带有全上下文注意力的 Conformer 和 Fast Conformer。
四、扩展 Fast Conformer 模型
-
模型尺寸设计
- 设计了三种模型尺寸:大型(L)、特大型(XL)和超大型(XXL)。从 L 到 XL,增加隐藏维度、编码器层数和 RNNT 层数;从 XL 到 XXL,保持其他模型参数不变,仅增加编码器层数。
-
预训练与微调方法
- 扩展模型时,预训练编码器采用基于 Wav2Vec 2.0 的自监督学习方法,有助于稳定训练并启用高学习率。与 Conformer 模型不同,扩展模型时未更改 conformer 块和相对注意力。
-
扩展数据集训练
- 为有效利用大型模型,将数据集大小与模型尺寸成比例地增加,在原有 25k 小时 ASR 数据集基础上,额外加入 40,000 小时的内部数据集(ASR Set ++)进行训练,使 XL 和 XXL 模型的准确性和抗噪性得到提升。
五、结论
Fast Conformer 是一种重新设计的 Conformer 模型,其通过新的下采样方案,在使用更少计算资源的同时,保持与原始 Conformer 相当的词错误率。在语音翻译和口语理解任务上的评估表明,该模型在实现高准确性的同时,显著提升了编码器的计算速度。通过将注意力模块替换为局部注意力,模型能够以单次前向传递高效转录长达 11 小时的音频片段,添加单个全局注意力令牌可进一步提升长音频转录性能。此外,Fast Conformer 架构可轻松扩展至 10 亿参数,这使其在大型数据集上训练时能够进一步提升准确性并增强抗噪性。