【学习笔记】机器学习(Machine Learning) | 第五章(3)| 分类与逻辑回归
机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- 机器学习(Machine Learning)
- 简要声明
- 三、代价函数
- 平方误差代价函数
- 逻辑回归的损失函数
- 损失函数的性质
- 逻辑回归的代价函数
- 代价函数的凸性
- 简化的损失函数
- 简化的代价函数
一、逻辑回归的基本原理
二、决策边界
三、代价函数
平方误差代价函数
在逻辑回归中,如果我们直接使用线性回归的平方误差代价函数:
J ( w → , b ) = 1 m ∑ i = 1 m 1 2 ( f w → , b ( x → ( i ) ) − y ( i ) ) 2 J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} \frac{1}{2} (f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) - y^{(i)})^2 J(w,b)=m1i=1∑m21(fw,b(x(i))−y(i))2
其中, f w → , b ( x → ) = w → ⋅ x → + b f_{\overrightarrow{w}, b}(\overrightarrow{x}) = \overrightarrow{w} \cdot \overrightarrow{x} + b fw,b(x)=w⋅x+b 是线性回归模型的输出。
然而,对于逻辑回归,这种代价函数可能会导致非凸问题,使得梯度下降算法难以收敛到全局最小值。
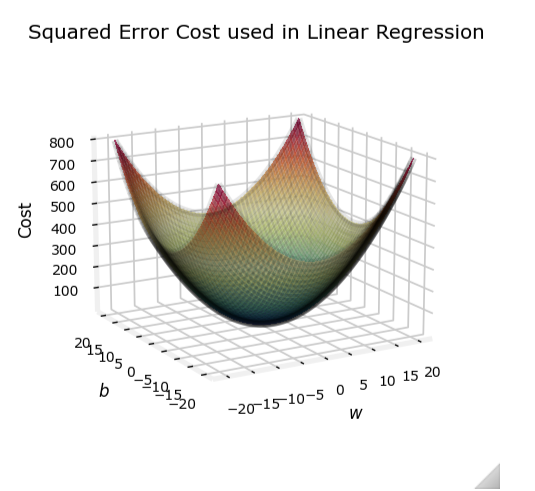
线性回归
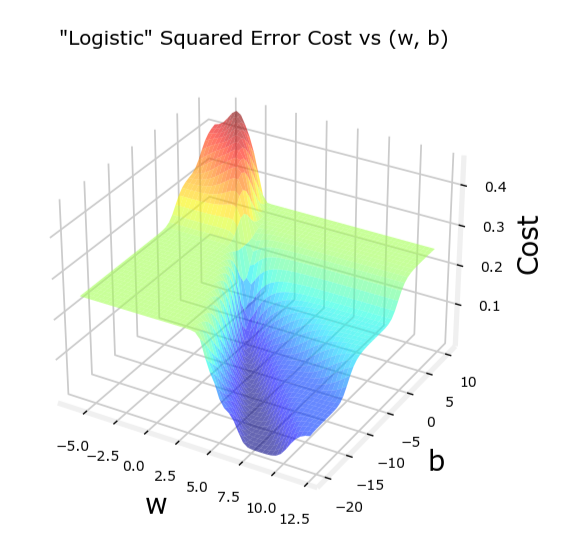
并不像线性回归的“汤碗”那么光滑
逻辑回归的损失函数
为了解决这个问题,逻辑回归采用了不同的损失函数。对于单个训练样本 ( x → ( i ) , y ( i ) ) (\overrightarrow{x}^{(i)}, y^{(i)}) (x(i),y(i)),逻辑回归的损失函数定义为:
L ( f w → , b ( x → ( i ) ) , y ( i ) ) = { − l o g ( f w → , b ( x → ( i ) ) ) if y ( i ) = 1 − l o g ( 1 − f w → , b ( x → ( i ) ) ) if y ( i ) = 0 L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) = \begin{cases} -log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 1 \\ -log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 0 \end{cases} L(fw,b(x(i)),y(i))={−log(fw,b(x(i)))−log(1−fw,b(x(i)))if y(i)=1if y(i)=0
其中, f w → , b ( x → ) = 1 1 + e − ( w → ⋅ x → + b ) f_{\overrightarrow{w}, b}(\overrightarrow{x}) = \frac{1}{1 + e^{-(\overrightarrow{w} \cdot \overrightarrow{x} + b)}} fw,b(x)=1+e−(w⋅x+b)1 是逻辑回归模型的输出。
损失函数的性质
-
当 y ( i ) = 1 y^{(i)} = 1 y(i)=1 时:
- 如果 f w → , b ( x → ( i ) ) → 1 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 1 fw,b(x(i))→1,损失 → 0 \to 0 →0
- 如果 f w → , b ( x → ( i ) ) → 0 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 0 fw,b(x(i))→0,损失 → ∞ \to \infty →∞
-
当 y ( i ) = 0 y^{(i)} = 0 y(i)=0 时:
- 如果 f w → , b ( x → ( i ) ) → 0 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 0 fw,b(x(i))→0,损失 → 0 \to 0 →0
- 如果 f w → , b ( x → ( i ) ) → 1 f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}) \to 1 fw,b(x(i))→1,损失 → ∞ \to \infty →∞
这种损失函数的设计使得模型在预测错误时付出更大的代价,从而激励模型尽可能准确地预测。
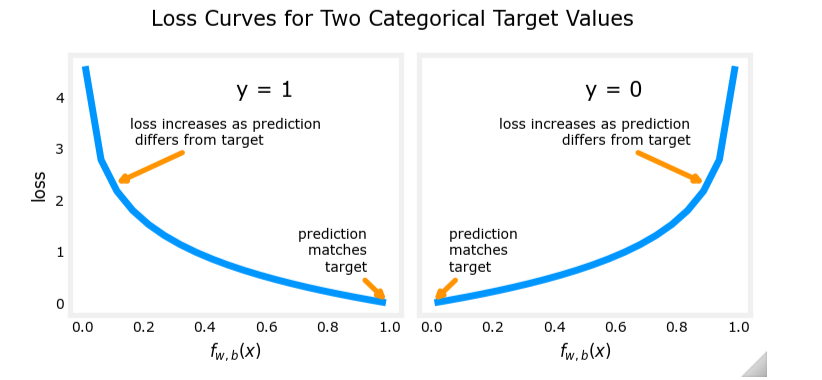
逻辑回归的代价函数
逻辑回归的代价函数是所有训练样本损失的平均值:
J ( w → , b ) = 1 m ∑ i = 1 m L ( f w → , b ( x → ( i ) ) , y ( i ) ) J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) J(w,b)=m1i=1∑mL(fw,b(x(i)),y(i))
展开后为:
J ( w → , b ) = 1 m ∑ i = 1 m { − l o g ( f w → , b ( x → ( i ) ) ) if y ( i ) = 1 − l o g ( 1 − f w → , b ( x → ( i ) ) ) if y ( i ) = 0 J(\overrightarrow{w}, b) = \frac{1}{m} \sum_{i=1}^{m} \begin{cases} -log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 1 \\ -log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) & \text{if } y^{(i)} = 0 \end{cases} J(w,b)=m1i=1∑m{−log(fw,b(x(i)))−log(1−fw,b(x(i)))if y(i)=1if y(i)=0
代价函数的凸性
逻辑回归的代价函数是凸的,这意味着它只有一个全局最小值,梯度下降算法可以保证收敛到这个全局最小值。
相比之下,平方误差代价函数在逻辑回归中可能会导致非凸问题,使得梯度下降算法陷入局部最小值。
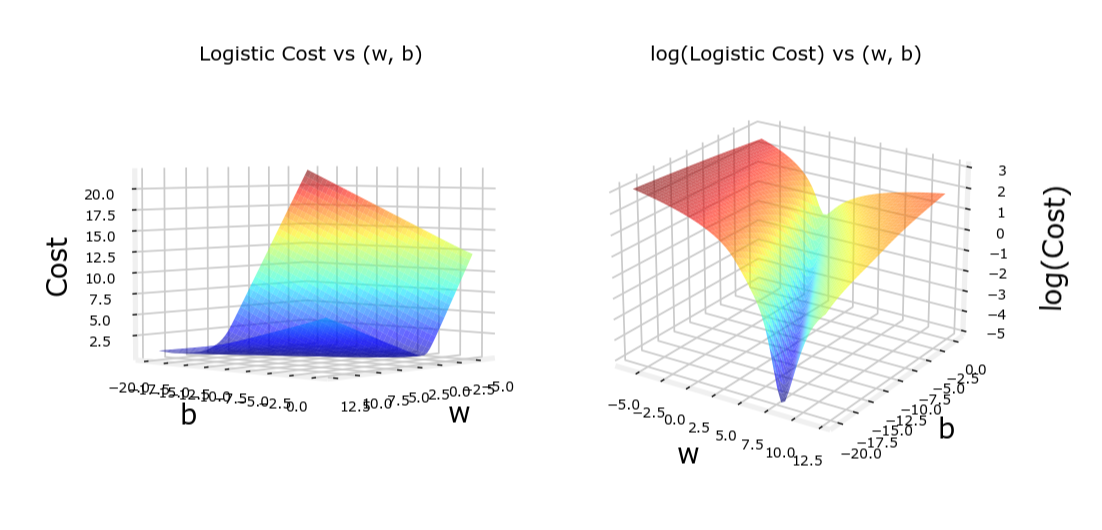
简化的损失函数
逻辑回归的损失函数可以简化为一个统一的表达式:
L ( f w → , b ( x → ( i ) ) , y ( i ) ) = − y ( i ) log ( f w → , b ( x → ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − f w → , b ( x → ( i ) ) ) L(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)}), y^{(i)}) = - y^{(i)} \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) - (1 - y^{(i)}) \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) L(fw,b(x(i)),y(i))=−y(i)log(fw,b(x(i)))−(1−y(i))log(1−fw,b(x(i)))
这个表达式结合了两种情况:
- 当 y ( i ) = 1 y^{(i)} = 1 y(i)=1 时,损失函数为 − log ( f w → , b ( x → ( i ) ) ) - \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) −log(fw,b(x(i)))
- 当 y ( i ) = 0 y^{(i)} = 0 y(i)=0 时,损失函数为 − log ( 1 − f w → , b ( x → ( i ) ) ) - \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) −log(1−fw,b(x(i)))
简化的代价函数
逻辑回归的代价函数也可以相应地简化为:
J ( w → , b ) = − 1 m ∑ i = 1 m [ y ( i ) log ( f w → , b ( x → ( i ) ) ) + ( 1 − y ( i ) ) log ( 1 − f w → , b ( x → ( i ) ) ) ] J(\overrightarrow{w}, b) = - \frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log(f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) + (1 - y^{(i)}) \log(1 - f_{\overrightarrow{w}, b}(\overrightarrow{x}^{(i)})) \right] J(w,b)=−m1i=1∑m[y(i)log(fw,b(x(i)))+(1−y(i))log(1−fw,b(x(i)))]
这个代价函数实际上是对数似然函数的负数,因此最小化这个代价函数等价于最大化似然函数。这种方法被称为 最大似然估计(Maximum Likelihood Estimation)。
逻辑回归采用了不同于线性回归的损失函数,以适应分类问题的特点。其代价函数是凸的,保证了梯度下降算法可以收敛到全局最小值。通过最小化这个代价函数,我们可以找到最优的模型参数,使模型在训练数据上的表现最佳。
continue…