【Python】存储机制和容器四大件列表、元组、字典、集合
文章目录
- 1 Python中的引用机制
- 2 列表List
- 2.1 列表的底层实现
- 2.2 列表的基本使用
- 2.3 列表的深拷贝和浅拷贝
- 2.4 列表推导式
- 3 元组Tuple
- 3.1 元组和列表的区别
- 3.2 元组的内存机制
- 3.3 元组和字符串
- 4 字典Dict
- 4.1 字典的常用操作
- 4.2 字典的常见错误
- 5 集合set
- 5.1 集合的常用操作
1 Python中的引用机制
Python中变量是对象的引用,也就是说创建一个变量不会直接存储值,而是存储一个地址指向内存中的对象。
m = 5
n = m
m = 30
print(n) #输出:5
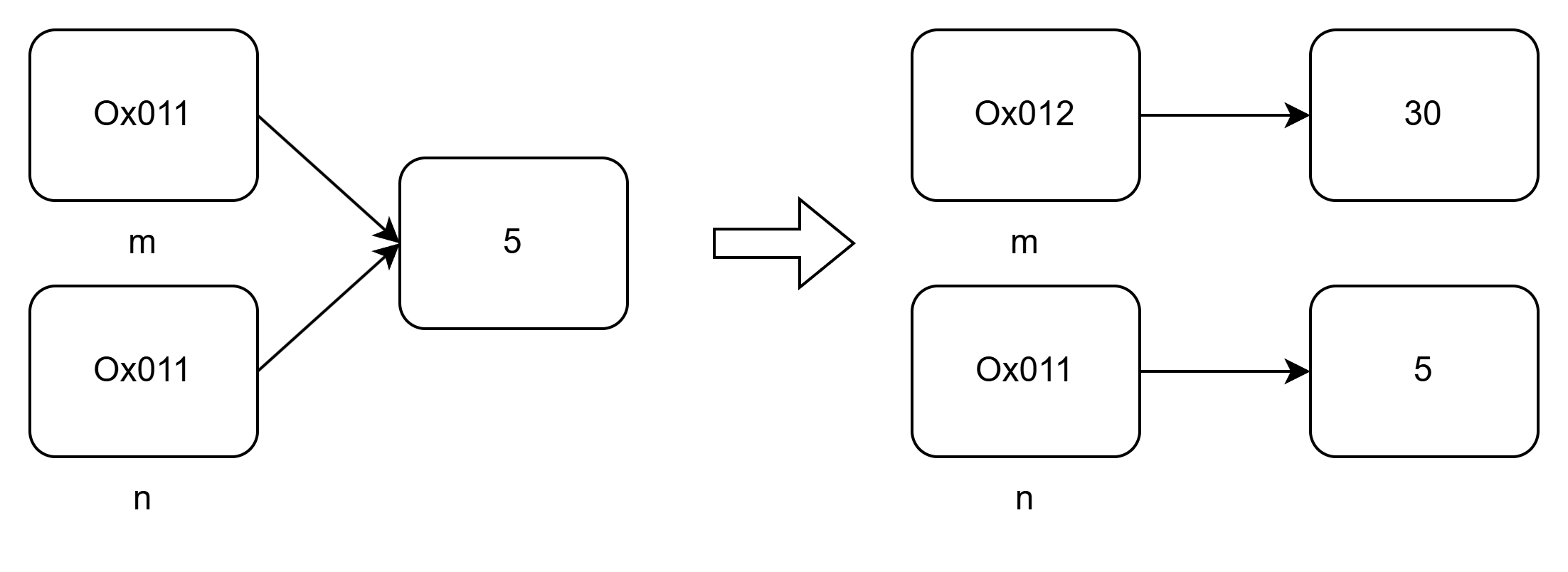
对于对象而言,如果有多个变量存的地址指向这个对象,那么这个对象就会有一个引用计数,当引用计数为0时,对象销毁。
import sys
a = [] # 对象创建,引用计数=1
b = a # 引用计数+1 → 2
print(sys.getrefcount(a)) # 查看引用计数输出3
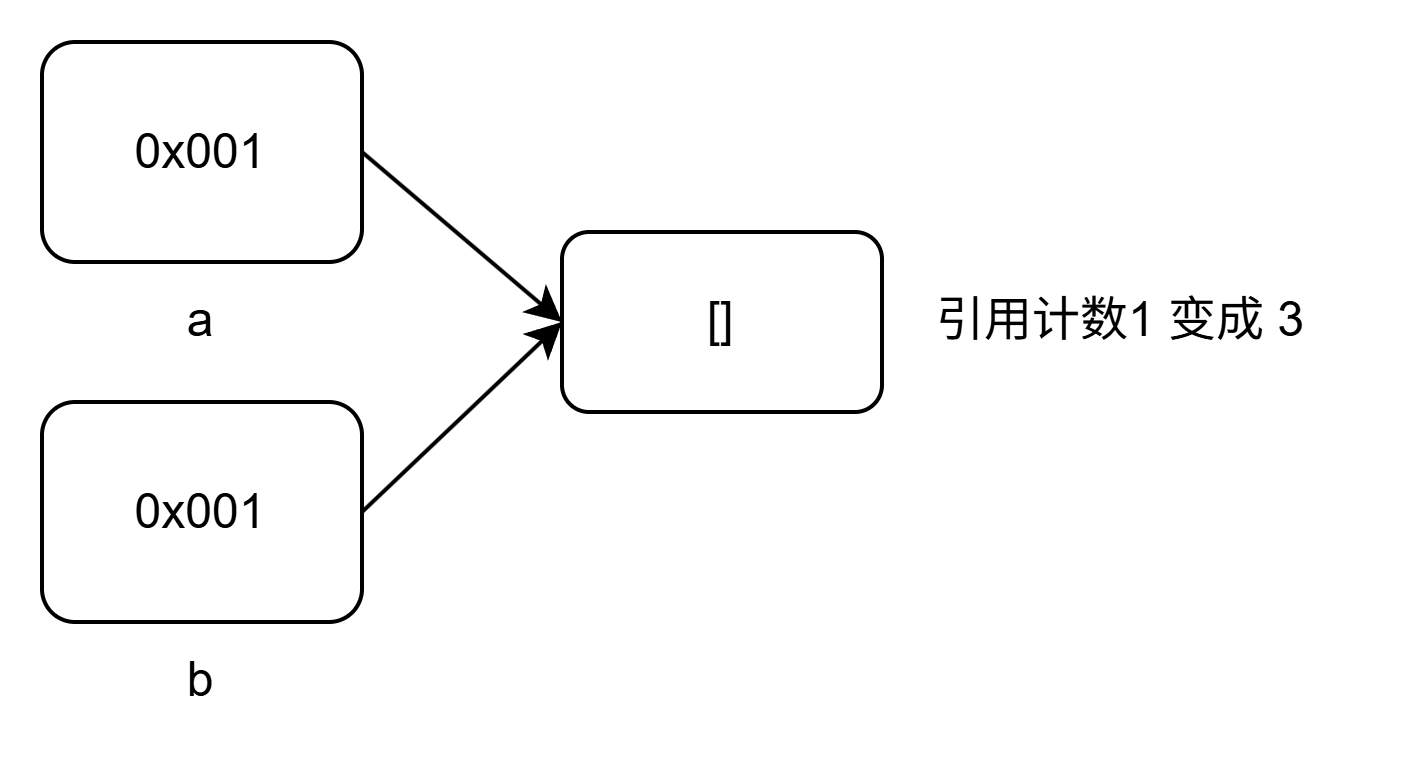
上面引用计数为什么不是2?
因为Python 解释器会内部缓存一些简单对象比如上面的空列表[],为了复用内存地址以提升性能。
在之后创建列表、元组、字典、集合这些对象时,其实都是变量存放一个地址指向对象。
2 列表List
2.1 列表的底层实现
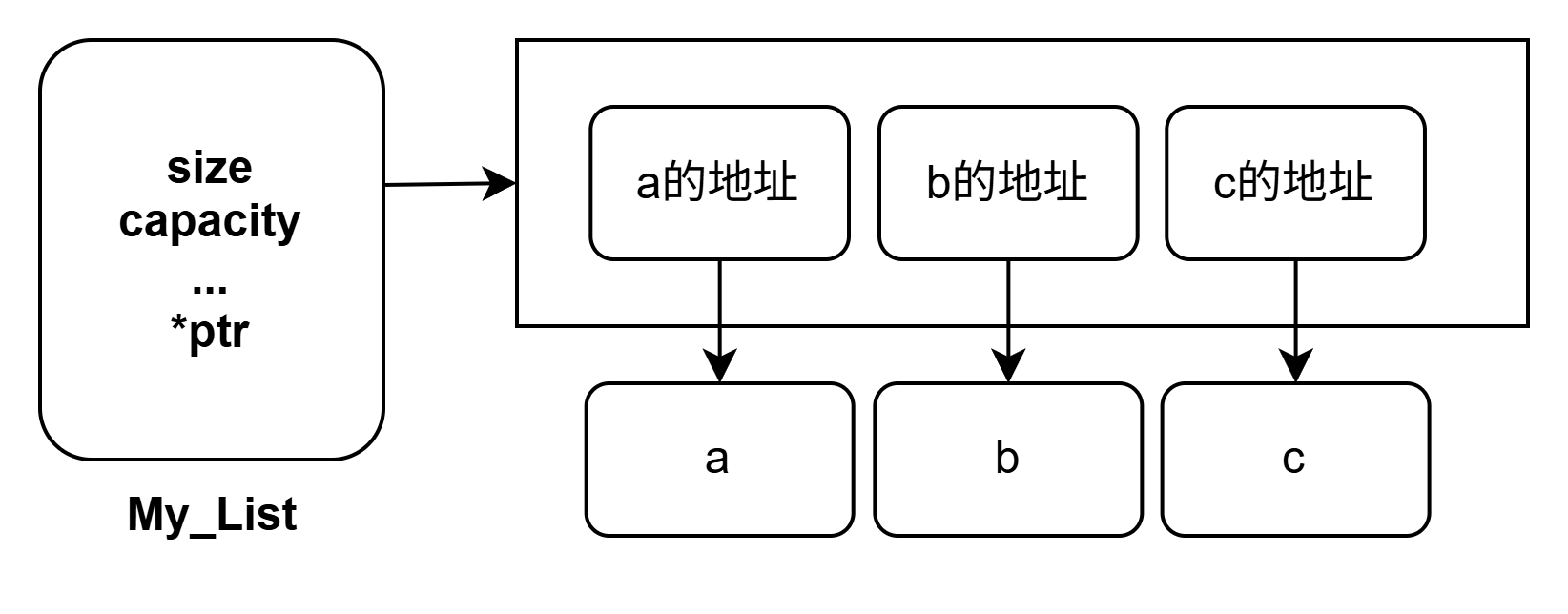
- 列表底层就是一个动态数组,其有着有效数据长度、空间容量、元素类型等组成。
- 列表内有着连续的内存块,其中存储着每个元素的内存地址引用(并非实际数据),可以通过索引快速定位。
- 列表中数据存储的内存地址是连续的,但是其实际数据会分散在内存的不同位置。
列表作为一个动态数组,在容量不足时会进行扩容,扩容系数在1.125-1.5之间,为的是避免频繁扩容。扩容时,系统会申请一块新的空间,将列表原有的数据(里面存放着指向实际数据的地址)拷贝过去,再改变list中ptr的指向(但list的地址不会改变)后释放原有内存。(整个过程是一个浅拷贝)
2.2 列表的基本使用
列表在使用上和数组类似,不同的是它可以存储多种类型的数据,先让我们快速看一下如何使用列表
#列表是可变类型,可添加各种可变(列表、字典)和不可变的类型(字符串、元组)
##########################################
#append添加
list1 = ["样例1"]
list1.append("样例2")
list1.append('a')
list1.append(1)
list1.append(["样例3","样例4"])
print(list1) # 输出:['样例1', '样例2', 'a', 1, ['样例3', '样例4']]##########################################
#insert按位置插入
list1.insert(len(list1), "样例5")#[]下标访问
list1[2] = 'b'
print(list1) # 输出:['样例1', '样例2', 'b', 1, ['样例3', '样例4'], '样例5']##########################################
#切片
list2 = list1[0:5:2] #[start:end:gap] start位置到end前一个位置每次隔了gap个
list3 = list1[:2] #start不写默认从头开始,end不写默认到尾部,gap不写默认为1
print(list2) # 输出:['样例1', 'b', ['样例3', '样例4']]print(list3) # 输出:['样例1', '样例2']##########################################
#删除元素
list1.remove("b") #没有会报错
#遍历
for e in list1:print(e,end=' ')
print()
for i in range(len(list1)):print(list1[i],end=' ')
print()
#二者都输出:样例1 样例2 1 ['样例3', '样例4'] 样例5##########################################
# +和*
list4 = list2 + list3
list5 = list3 * 2
print(list4) #['样例1', 'b', ['样例3', '样例4'], '样例1', '样例2']
print(list5) #['样例1', '样例2', '样例1', '样例2']
2.3 列表的深拷贝和浅拷贝
拷贝的时候,需要确保原始数据是否需要保护,以免出现数据意外修改。
进行深拷贝的时候,需要使用copy.deepcopy(),而浅拷贝则在切片的时候触发。
import copy
#深拷贝复制所有层的数据各不干扰
list1 = ["a",["b", "c"]]
list2 = copy.deepcopy(list1)
list2[0] = "d"
list2[1][1] = "e"
print(list1) # ['a', ['b', 'c']]#浅拷贝 只拷贝第一层的地址数据且共享深层的数据,就是说第一层其地址指向的数据不会拷贝。
list_1 = ["a",["b","c"]]
list_2 = list_1[:] # 切片触发浅拷贝
list_2[0] = "d" # 修改第一层 list_1不受影响
list_2[1][1] = "e" # 修改深层 list_1受到影响
print(list_1) # ['a', ['b', 'e']]
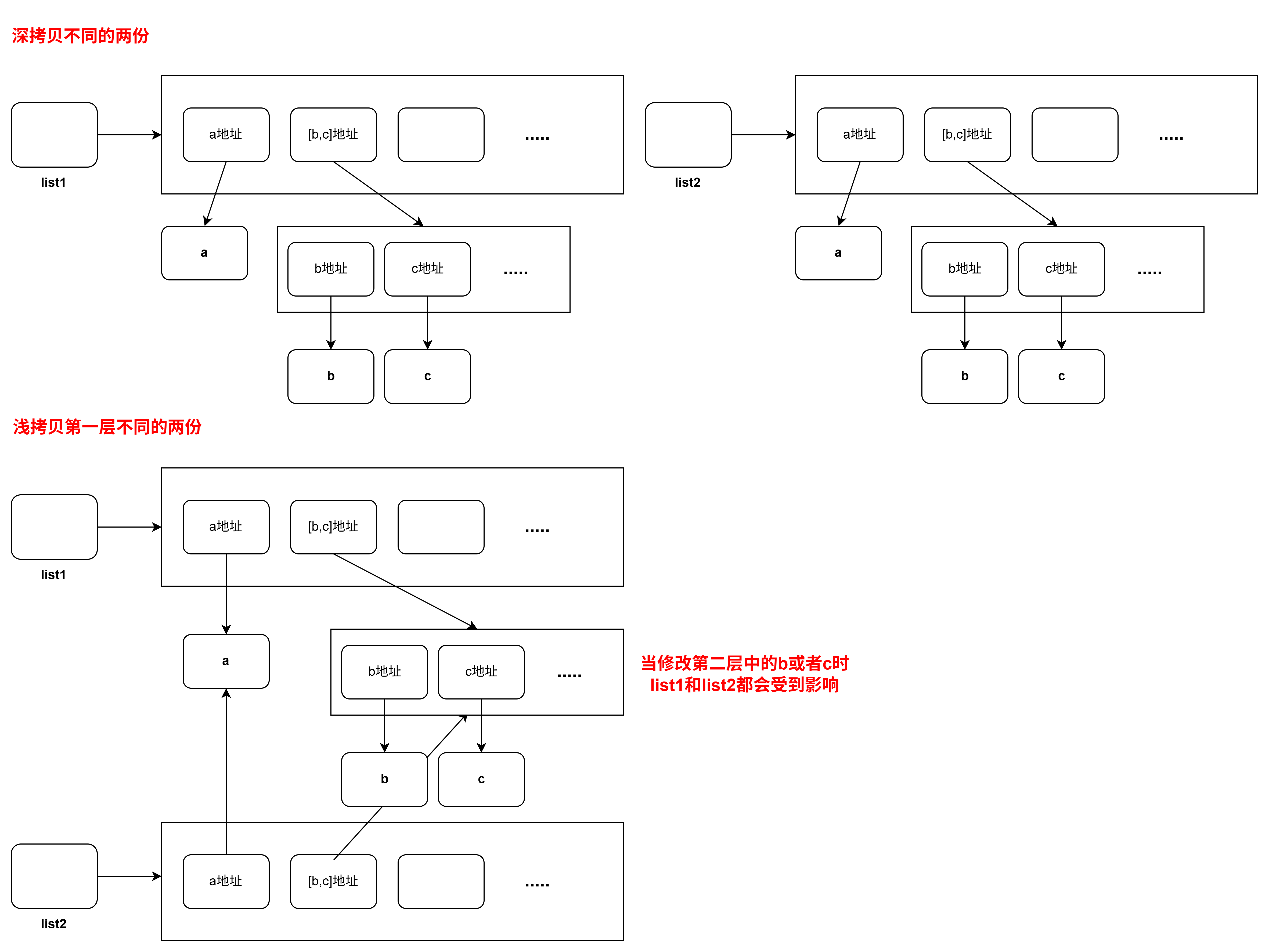
很明显:
深拷贝优点是不会影响原有数据,缺点是占用空间多。
浅拷贝优点是节约空间,但会影响原有数据。
2.4 列表推导式
列表推导式能有效的简化代码,将可迭代的对象转换成新列表。
用法:
新列表 = [表达式 for 变量in 可迭代对象]
新列表 = [表达式 for 变量in 可迭代对象 if 条件]
列表推导式的嵌套循环和条件判断遵从 从外到内、从左到右
下面看懂一些列表推导式就行了。
# 列表推导式
matrix = [[i*j for j in range(3)] for i in range(4)]
print(matrix)
# 输出:[[0, 0, 0], [0, 1, 2], [0, 2, 4], [0, 3, 6]]####################
#右边带条件的
nums = [x for x in range(20) if x%2==0 if x>10] #又要整除2又要大于10#列表推导式的嵌套循环和条件判断遵从 从外到内、从左到右
pairs = [(x, y) for x in range(3) if x!=1 for y in range(3) if x+y>1]
# 输出:[(0, 2), (2, 0), (2, 1), (2, 2)]#和函数一起
def process(num):return num ** 2 + 1
result = [process(x) for x in range(5)] # [1, 2, 5, 10, 17]#lambda表达式 左边(lambda num: num**3)作为一个临时函数,右边(num)代表接受的参数
squares = [(lambda num: num**3)(num) for x in range(4)] # [0, 1, 8, 27]# 矩阵转置
matrix = [[1, 2], [3, 4], [5, 6]]
transposed = [[row[i] for row in matrix] for i in range(2)]
# 输出:[[1, 3, 5], [2, 4, 6]]# 平铺嵌套列表
nested_list = [[1,2], [3,4,5]]
flat = [num for sublist in nested_list for num in sublist] # [1,2,3,4,5]#all()代表所有满足
primes = [x for x in range(2, 30) if all(x % y !=0 for y in range(2, int(x**0.5)+1))]
# 输出:[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]colors = ['红', '蓝']
sizes = ['S', 'L']
cartesian = [(c, s) for c in colors for s in sizes]
# 输出:[('红', 'S'), ('红', 'L'), ('蓝', 'S'), ('蓝', 'L')]
3 元组Tuple
Python中元组是一种不可变的序列,其特点是不可变性以及内存高效性。不可变性就是元组一旦创建,里面的元素就不能修改(当然元组里面的可变对象比如列表,可以修改,但本身元组中存的地址是不会变的),内存高效性体现在,元组在创建时就确定好了开辟内存空间的大小,而不是像列表有预留的空间。
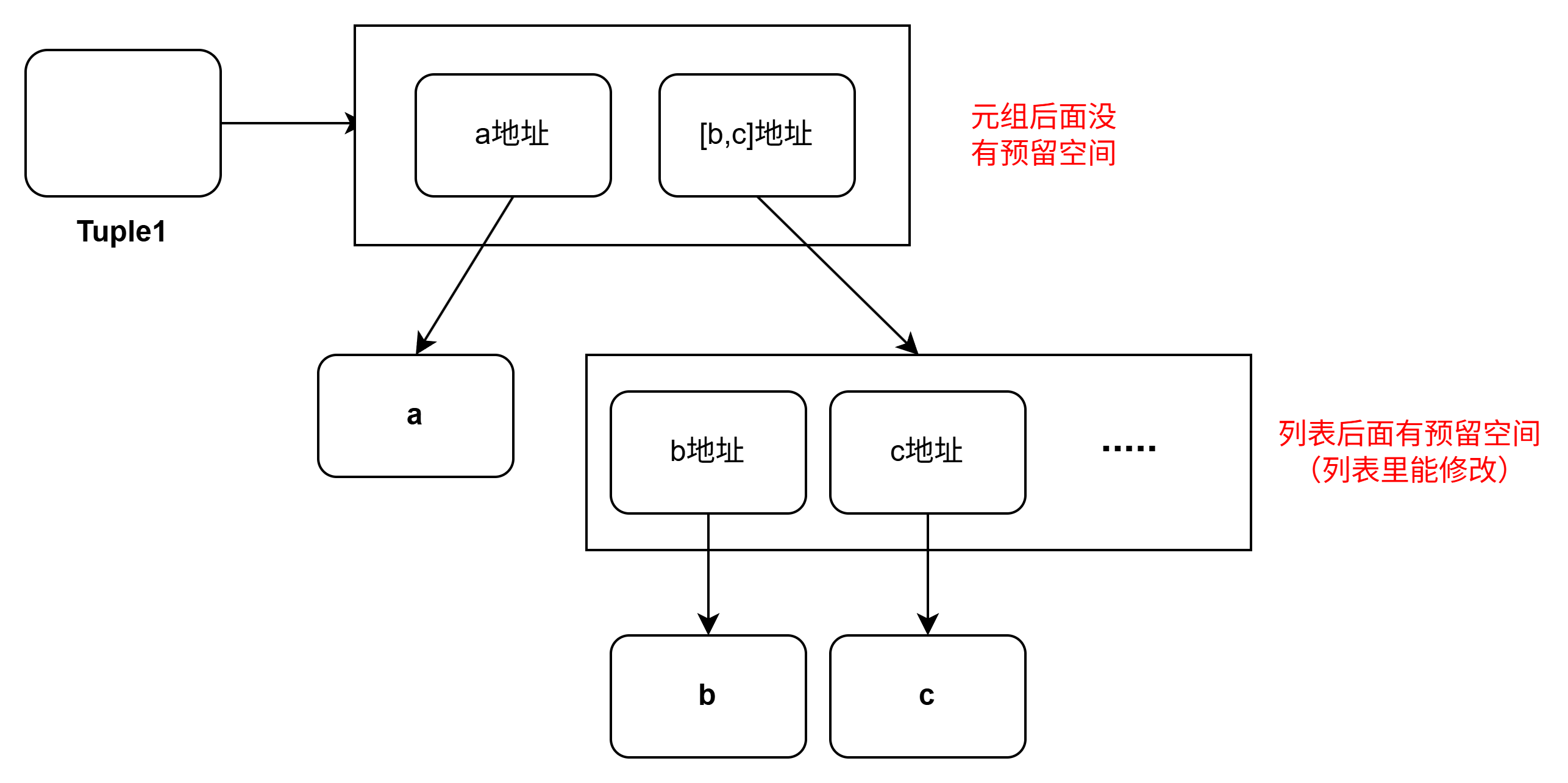
3.1 元组和列表的区别
- 列表是可变序列,也就是支持增删改操作,而元组一旦创建就无法修改元素。
- 元组在创建时就确定了所有元素,其内存空间就会一次性给它分配完成。这个内存空间不可扩展或收缩是固定的,而列表的空间则是动态的,会预留额外空间。
- 元组使用()进行表示,而列表则是 [ ] 。
下面看元组具体的一些使用
# 创建元组 单元素元组需要加','
a = (1,)
b = (1,2)
c = 1,2
d = tuple([1,2,3,3,5,7])# 一些常用的内置函数
print(len(d)) # 打印d长度
print(d.count(3)) # 打印d中3出现的个数
print(d.index(3)) # 打印d中首次出现3的下标# 元组无增删 但可以用索引和切片
a = (1,2,[3,4])
# a[0] = 6 #报错
# a[2] = [5,6] #报错
a[2][0] = 5 #可以修改
print(a) # 输出:(1, 2,[5, 4])# 元组的切片也是浅拷贝
b = a[:]
print(b) # 输出:(1, 2,[5, 4])
b[2][0] = 7
print(a) # 输出:(1, 2,[7, 4])import copy
c = copy.deepcopy(a)
print(c) # 输出:(1, 2,[7, 4])
c[2][0] = 8
print(a) # 输出:(1, 2,[7, 4])
3.2 元组的内存机制
元组作为不可变数据也会发生“变化”,在添加了元素后,会创建新的元组。而列表作为可变数据则不会“改变”
# 新的元组有着不同的地址
tuple01 = ("西瓜", "苹果")
print(id(tuple01)) #3031491680896
tuple01 += ("草莓", "芒果")
print(id(tuple01)) #3031491260432# 列表修改为相同的地址
tuple02 = ["西瓜", "苹果"]
print(id(tuple02)) #2027854913728
tuple02 += ["草莓", "芒果"]
print(id(tuple02)) #2027854913728
内存复用机制
由于元组的不可变性,Python 解释器会缓存简单元组(如空元组 () 或小整数元组),复用内存地址以提升性能。
tuple02 = ()
tuple03 = ()
tuple04 = ()
print(id(tuple02))
print(id(tuple03))
print(id(tuple04)) #都是140717271565760tuple05 = (1,2,3,4)
tuple06 = (1,2,3,4)
tuple07 = (1,2,3,4)
print(id(tuple05))
print(id(tuple06))
print(id(tuple07)) #都是1961087315984
3.3 元组和字符串
- 元组和字符串均属于不可变序列,修改就会报错。
- 两个都可以通过下标进行访问以及进行切片操作。
- 由于两个都有不可变性,它们都有内存复用机制,使得在一些场景下使用的性能提高。
s = "hello"
t = (1, 2, 3)
s[0] = "H" # 报错
t[0] = 4 # 报错 s = "Python"
print(s[1:4]) # "yth"(正向切片)
print(s[-3:]) # "hon"(反向切片)
下面看字符串的一些操作方式
(1)字符串的分割和合并
data = "apple,banana,orange"
fruits = data.split(",") # ['apple', 'banana', 'orange']words = ["Python", "is", "awesome"]
sentence = " ".join(words) # "Python is awesome"(2)strip 去除首尾指定元素
默认时,去除前后空白,包括\t和\n
s = " hello world\t\n"
print(s.strip()) # 输出:"hello world"
也可以指定元素
s = "###hello#world###"
print(s.strip('#')) # 输出:"hello#world"
s2 = "abc123cba"
print(s2.strip('abc')) # 输出:"123"(首尾的a、b、c均被移除)
(对应对于lstrip()和rstrip()也可以指定方向,其他用法都是一样的)
(3)查找和替换
s = "hello world"
print(s.find("wo")) # 输出 6text = "I like Java"
new_text = text.replace("Java", "Python") # "I like Python"
(4)格式化输出
f-string方式
name = "Alice"
print(f"Hello, {name.upper()}!") # 输出:Hello, ALICE!
format方式
print("{} is {} years old".format("Bob", 25))
%方式
print("Price: $%.2f" % 99.99) # 输出:Price: $99.99
4 字典Dict
字典作为一种可变的无序键值对集合,其以键值对{key,value}的方式存储数据。
- 字典中的键(key)必须不可变类型,比如元组、字符串、数字,并且唯一。若重复则后定义的会覆盖前面的。值(value)可以是任意类型。
- 字典是可变的,支持动态增删改键值对。
- 字典的查询效率很高是O(1),因为其底层是采用哈希表。因为引用键值对的地址不是连续的因此不可索引访问。
4.1 字典的常用操作
字典的创建
# 1. 直接定义键值对
person = {"name": "Tom", "age": 22, "city": "Shanghai"} # 2. 使用 dict 构造函数
config = dict(host="localhost", port=3306)# 3. 通过 zip 组合键值
# zip作用是将多个可迭代对象的元素按索引位置一一配对,生成由元组组成的迭代器
keys = ["name", "age"]
values = ["Alice", 25]
user = dict(zip(keys, values)) # {'name': 'Alice', 'age': 25}# 4. 字典推导式快速生成
squares = {x: x**2 for x in range(5)} # 生成 {0:0, 1:1, 2:4...}
键值访问和遍历
# 1. 直接访问(KeyError 风险)
print(person["name"]) # 输出 "Tom"# 2. 安全访问 get 方法 若没有就输出unknown
print(person.get("gender", "unknown")) # 输出 "unknown"# 3. 遍历键值对
for key, value in person.items(): print(f"{key}: {value}") # 4. 单独获取键/值列表
keys = person.keys() # ["name", "age", "city"]
values = person.values() # ["Tom", 22, "Shanghai"]
键值修改
# 1. 添加/修改键值
person["gender"] = "male" # 新增字段
person["age"] = 23 # 修改已有字段# 2. 批量更新 update
person.update({"age":24, "job":"Engineer"})# 3. 智能设置 setdefault
# 当键不存在时设置默认值,存在则返回当前值
count = person.setdefault("login_count", 0)
删除操作
# 1. 删除指定键
del person["city"] # 直接删除
age = person.pop("age") # 删除并返回值# 2. 清空字典
person.clear() # 变为空字典 {}
4.2 字典的常见错误
(1)遍历时修改字典
因为第一个迭代器遍历的时候会跟踪字典状态,在循环中删除键值对就会导致无法正常跟踪后续元素。第二个则是生成一个静态列表与原字典解耦,可以根据列表进行正常迭代。
# 错误方式:
for key in person:del person[key] # RuntimeError
# 正确方式:
for key in list(person.keys()): del person[key]
(2)可变对象作为键
键必须是不可变类型的。
# 错误示例:
d = {[1,2]: "value"} # TypeError
# 正确方式:
d = {tuple([1,2]): "value"}
(3)误用浅拷贝
d1 = {"a": [1,2]}
d2 = d1.copy()
d2["a"].append(3) # d1 的值也会被修改!
# 正确深拷贝:
import copy
d2 = copy.deepcopy(d1)
5 集合set
Python中集合set和字典dict底层都是由哈希表实现,因此集合中的元素也没有固定顺序,无法通过索引访问。set底层和dict类似都是键值对,只不过set的键和值都一样,因此这个值需要满足键的特征,因此其存储的元素具有唯一性以及只能存储不可变类型(如整数、字符串、元组),不可存放列表、字典等可变对象。
5.1 集合的常用操作
集合的创建
集合和字典一样,都用{}。
s1 = {1, 2, 3} # 直接定义
s2 = set([1, 2, 2, 3]) # 通过列表去重创建 → {1, 2, 3}
empty_set = set() # 空集合必须要用set()({}是空字典)集合的增删改查
s = {1, 2}
s.add(3) # 添加单个元素 → {1, 2, 3}
s.update([4, 5]) # 批量添加 → {1, 2, 3, 4, 5}s = {1, 2, 3, 4}
s.remove(3) # 删除指定元素(不存在则报错)
s.discard(5) # 安全删除(元素不存在不报错)
s.pop() # 随机删除并返回一个元素(如1)s = {2, 4, 6}
print(2 in s) # True(成员检查)
print(len(s)) # 输出元素数量 → 3
集合的运算
& 取交集、| 取并集、-取差集(在A不在B的)、^对称差集(仅属于A或B的)
a = {1, 2, 3}
b = {2, 3, 4}
print(a & b) # 输出 {2, 3}
print(a | b) # 输出 {1, 2, 3, 4}
print(a - b) # 输出 {1}
print(a ^ b) # 输出 {1, 4}
子集判断issubset,父集判断issuperset
x = {1, 2}
print(x.issubset(a)) # True(x是a的子集)
print(a.issuperset(x)) # True(a是x的父集)
本节需要重点了解各个容器的底层实现,其次是基本使用操作,方便后续内容的使用。