【C++】哈希表
目录
前言:
一:什么是哈希?
二:哈希冲突
三:平衡因子
四:开放寻址法
1.定义状态
2.定义哈希表节点
3.定义哈希表
4.定义默认构造
5.定义Insert方法
6.定义Find方法
7.定义Erase方法
8.实现扩容
五:提供仿函数能够处理string
六:哈希桶(链地址法)
1.定义节点
2.定义哈希表和默认构造
3.定义Insert方法
4.定义Find方法
5.定义Erase方法
6.定义析构方法
7.实现扩容
总结:
前言:
我们已经知道了map和set底层是使用红黑树进行封装的,它的增删查的效率可以达到O(log n),这已经很快了。但是其实还有更快的,就是哈希表!
哈希表的效率都可以达到O(1),最坏情况也是O(n),这里一般分为两种哈希表的实现,一种是开放寻址法,一种是链地址法(有很多方法,但是我们只说最常见的两种方法)。
接下来我们一一介绍。
一:什么是哈希?
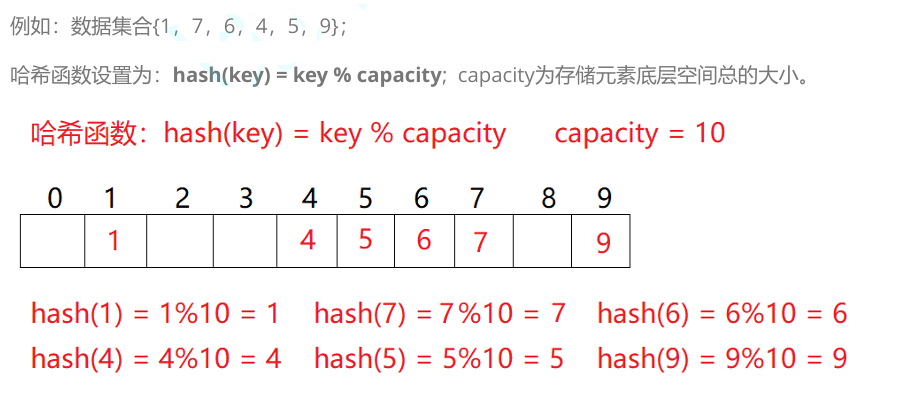
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素 时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即 O(log N),搜索的效率取决于搜索过程中元素的比较次数。 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立 一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
举个栗子你就懂了:
二:哈希冲突
对于两个数据元素的关键字k_i和 k_j(i != j),有k_i != k_j,但有:Hash(k_i) == Hash(k_j),即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突 或 哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。 发生哈希冲突该如何处理呢?
解决哈希冲突两种常见的方法是:闭散列(开放寻址法)和开散列(链地址法)。
三:平衡因子
当数据已经占据到一定的空间时,我们就要对其扩容。这里就需要一个条件,这个条件就是负载因子。对于也就是 存放数据个数 / 总容量 = 负载因子 。具体可以看我们实现哈希表的具体方法。
四:开放寻址法
比如我们在刚才的数据中再插入一个元素44,此时要映射到下标为4的位置上去,但是此时已经有数据了,我们要找下一个为空的地方存放:

1.定义状态
这里我们写代码的话应该怎么办?对,增加标记。
两个标记是不是就可以了?存在,不存在。但是我们还会进行删除,下次插入的元素当然也可以在删除的位置。
所以这里定义三个标记状态(在myHash.h头文件中,因为本篇要实现两个哈希表,所以这里用到命名空间,这里是open_address):
enum States
{EMPTY, //空EXIST, //存在DELETE //删除
};2.定义哈希表节点
这里和树一样,都需要定义节点(这里依旧是键值对存储,不存在重复值):
template<class K, class V>
struct HashNode
{HashNode() = default;HashNode(const pair<K, V>& kv) //调用其默认构造: _kv(kv), _s(EMPTY) //状态默认是空{}pair<K, V> _kv;States _s;
};3.定义哈希表
这里的哈希表我们不要像之前一样傻傻的去声明什么T* capacity,我们已经学习过了vector,所以直接把它定义为哈希表的成员变量即可。这里当然还要用一个值来记录当前数组中已经存放的节点个数。
template<class K, class V>
class HashTable
{
public:using Node = HashNode<K, V>;private:vector<Node> _table; //用vector存放好操作size_t _n; //记录哈希表中存放数据的个数
};4.定义默认构造
仔细想想,我们要先让vector开空间,也就是resize,改变其size,所以我们先写一个构造函数出来。
HashTable()
{_table.resize(10); //这里就先开10个空间
}5.定义Insert方法
这里我们先不考虑扩容,只考虑插入。就是先取模,之后开是否为空,为空或删除就插入。
bool Insert(const pair<K, V>& kv)
{//这里无需创建新节点 不需要开空间size_t hashi = kv.first % _table.size();while (_table[hashi]._s == EXIST){++hashi;hashi %= _table.size(); //因为可能会越界}//遇到空或DELETE_table[hashi]._kv = kv;_table[hashi]._s = EXIST;++_n;return true;
}6.定义Find方法
比对值并且存在即可,我们返回对应节点的指针,注意最多查找size次,所以我们需要再次多增加一个条件:
Node* Find(const K& key)
{size_t hashi = key % _table.size();//我们要限制次数 因为可能死循环size_t limit = 0;while (limit < _table.size() && _table[hashi]._s != EMPTY){//此时键相等且存在 就找到了if (_table[hashi]._kv.first == key &&_table[hashi]._s == EXIST){return &_table[hashi];}++hashi;hashi %= _table.size();++limit; //最多找10次}return nullptr;//没找到
}tips:所以Insert函数中可以复用Find,存在就不插入。
7.定义Erase方法
这个方法也很简单,我们先查找,如果该值存在,将其对应的标记修改为DELETE即可。
bool Erase(const K& key)
{//先查找Node* ret = Find(key);if (ret) //存在{ret->_s = DELETE;return true;}return false;
}8.实现扩容
什么时候扩容呢?这里就需要用到负载因子了,我们定义当 _n / _table.size() > 7 时扩容。
可能很多人会想,我们直接调用_table的reserve函数不就好了?如下图:
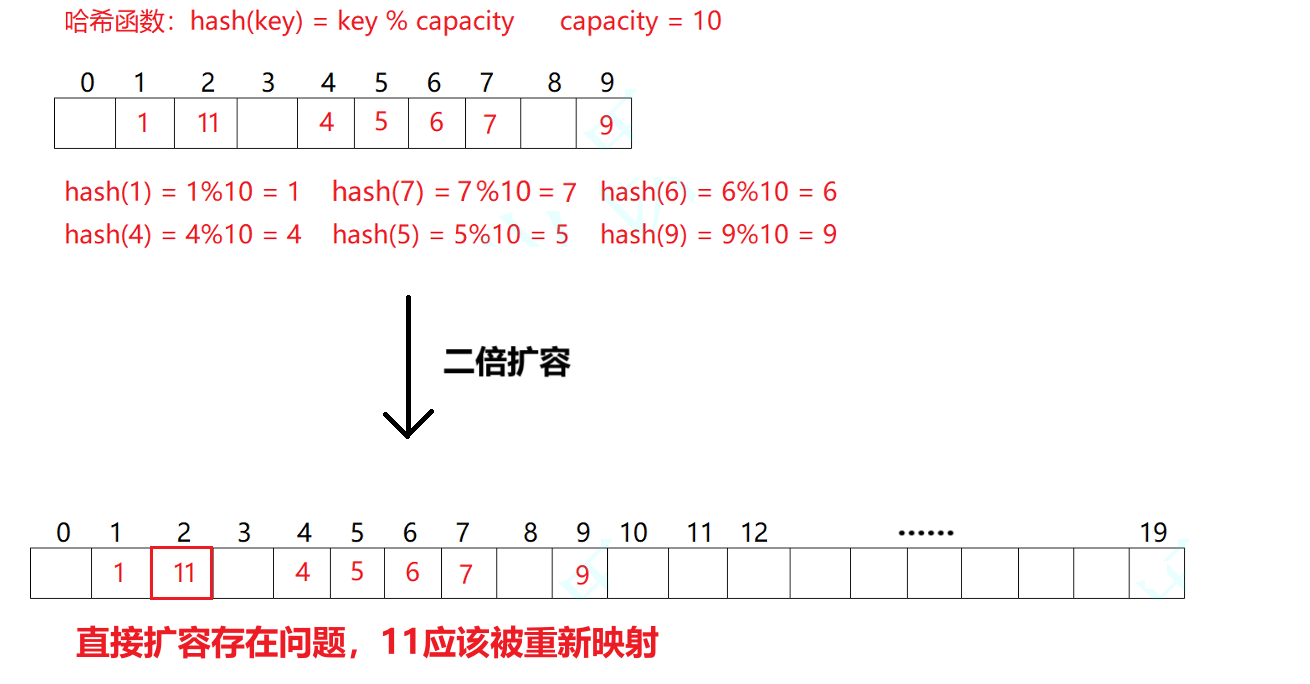
所以不能直接扩容,我们需要将所有值再次重新映射一遍,所以在Insert方法中添加一下代码:
//扩容
if (_n * 10 / _table.size() > 7)
{//这里创建一个新的哈希表HashTable newHT;newHT._table.resize(_table.size() * 2); //二倍扩容//遍历旧表for (size_t i = 0; i < _table.size(); ++i){if (_table[i]._s == EXIST){newHT.Insert(_table[i]._kv);}}_table.swap(newHT._table); //最后交换即可
}OK了,就这么简单,我们已经实现了开放寻址法的哈希表。
五:提供仿函数能够处理string
刚才我们已经能处理很多类型的数据,但是string该怎么办呢?它是怎么取模的?所以这里我们要进行处理,对哈希表多增加一个模板参数,使其能够处理string类型,也就是仿函数。
所以我们先写一个仿函数,之后提供特化版本,特化就是针对不同类型而尽心特殊处理。
template<class T>
struct HashFunc
{size_t operator()(const T& data){//直接进行强转即可return (size_t)data;}
};这里处理string类型的特化版本我们要特殊处理,不能直接加上每个字符对应的ASCII码值,因为这样处理会存在如:"abc"和"bca"处理的值相同的情况。所以这里可以以下方式处理(大佬研究的,几乎可以保证都不一样,这里我们只要记住就行):
//特化版本
template<>
struct HashFunc<string>
{size_t operator()(const string& s){size_t len = 0;for (auto e : s){len *= 31;len += e;}return len;}
};所以我们在HashTable中多加一个模板参数,并提供缺省值就是刚才写的HashFunc。之后再多加一个成员变量,就是实例化一个仿函数对象,需要计算hashi的时候就转换为size_t即可。
//提供缺省值
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
public:using Node = HashNode<K, V>;//实例化仿函数对象Hash hs;//...bool Insert(const pair<K, V>& kv){//...//这里无需创建新节点 不需要开空间//size_t hashi = kv.first % _table.size();size_t hashi = hs(kv.first) % _table.size();//...}Node* Find(const K& key){//size_t hashi = key % _table.size();size_t hashi = hs(key) % _table.size();//...return nullptr;//没找到}//...
};这时我们就可以正确处理string类型了。
六:哈希桶(链地址法)
我们已经实现了开放寻址法。接下来介绍第二种方法,链地址法。也就是数组每个值都存放的是指针, 类似一个链表。
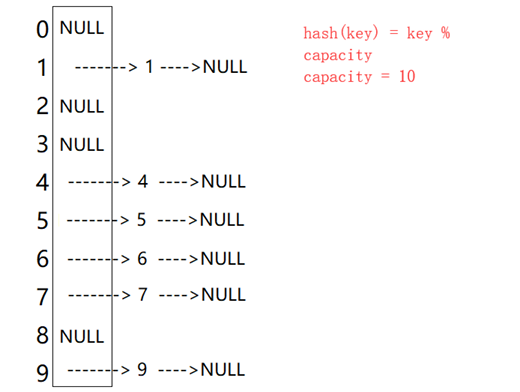
当有冲突节点插入相同索引时,我们使用头插:
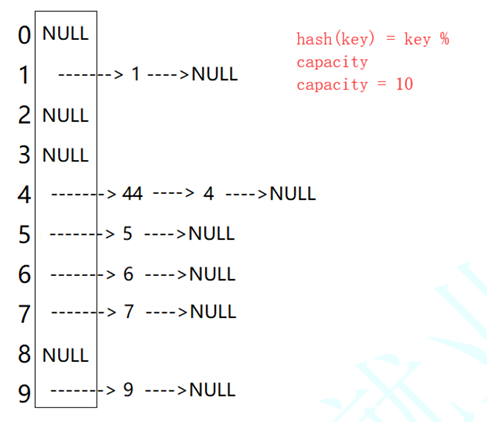
不同于开放寻执法的是,我们已经可以不再定义状态了,还是先定义节点(命名在hast_bucket命名空间中)。
1.定义节点
这里我们只需要数据和一个指针即可:
template<class K, class V>
struct HashNode
{HashNode() = default;HashNode(const pair<K, V>& kv): _kv(kv), _next(nullptr){}pair<K, V> _kv;HashNode* _next;
};2.定义哈希表和默认构造
没什么好说的,这里和之前的哈希表类似,很简单,看代码:
template<class K, class V>
class HashTable
{
public:using Node = HashNode<K, V>;HashTable(){_table.resize(10, nullptr); //开10个空间并赋值nullptr}private:vector<Node*> _table;size_t _n;
};你可能会问,为什么不用list呢?这是为了后面的封装等操作更简单。
3.定义Insert方法
这里使用头插法,同样先不处理扩容。
bool Insert(const pair<K, V>& kv)
{//需要开辟空间Node* newNode = new Node(kv);size_t hashi = kv.first % _table.size();//头插newNode->_next = _table[hashi];_table[hashi] = newNode;++_n;return true;
}4.定义Find方法
找到对应索引,之后逐个遍历即可,这里我们同样返回指针:
Node* Find(const K& key)
{size_t hashi = key % _table.size();Node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;
}5.定义Erase方法
找到并释放,但是要注意要让前一个节点的_next指向删除节点的下一个节点。且要注意头删的情况:
bool Erase(const K& key)
{size_t hashi = key % _table.size();Node* cur = _table[hashi];Node* parent = nullptr; //记录父节点while (cur){if (cur->_kv.first == key){//要考虑parent是否为空if (parent){parent->_next = cur->_next;}else{_table[hashi] = cur->_next;}delete cur;return true; //删除完毕}parent = cur;cur = cur->_next;}return false;
}6.定义析构方法
因为我们这里new了,所以就要用delete释放空间,所以就要写析构函数。
//析构
~HashTable()
{for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];Node* nextP = nullptr;while (cur){nextP = cur->_next;delete cur;cur = nextP;}//记得置空_table[i] = nullptr;}
}7.实现扩容
当我们数据个数达到_table.size()时,就扩容。
依旧是二倍扩容,但是我们不再使用之前的方法扩容,因为会释放和新建节点,效率低下。
我们只需要改变节点指针指向即可,这里我们给出完整的Insert代码:
bool Insert(const pair<K, V>& kv)
{//先复用FindNode* ret = Find(kv.first);if (ret){//存在 无需插入return false;}//扩容if (_n == _table.size()){HashTable newHT;newHT._table.resize(_table.size() * 2, nullptr);for (size_t i = 0; i < _table.size(); ++i){Node* cur = _table[i];while (cur){Node* nextP = cur->_next;//不复用Insertsize_t hashi = cur->_kv.first % newHT._table.size();//直接头插即可cur->_next = newHT._table[hashi];newHT._table[hashi] = cur;cur = nextP;}//记得置空_table[i] = nullptr;}//交换_table.swap(newHT._table);}//需要开辟空间Node* newNode = new Node(kv);size_t hashi = kv.first % _table.size();//头插newNode->_next = _table[hashi];_table[hashi] = newNode;++_n;return true;
}最后我们当然要能够处理string类,所以我们可以将之前的仿函数作为全局函数,之后给HashTable多加一个模板参数。这里不再赘述。
总结:
本章内容相对红黑树部分比较简单,当然需要用红黑树的基础才会更好的学习。下一篇我将带领大家讲本篇的哈希桶封装为unordered_set和unordered_map,也就类似于我们之前将红黑树封装为set和map一样,很复杂。
大家继续追剧,别掉队!