2025.4.28-20025.5.4学习周报
目录
- 摘要
- 1 文献阅读
- 1.1 模型架构
- 1.2 实验分析
- 总结
摘要
在本周阅读的文献中,作者提出了一种创新的PM2.5浓度预测方法。该方法将交通拥堵指数作为新型输入特征,结合多尺度数据输入,显著提升了城市空气质量预测的精度。通过特征选择、时间对齐和空间关联规则,实现了交通拥堵指数与其他数据的匹配和融合,构建了多源异构数据集,从而充分考虑到了交通拥堵对城市颗粒物污染和空间异质性的影响。论文采用的CNN-LSTM-ATT混合模型,整合了卷积神经网络的局部特征提取、LSTM的时间序列建模以及注意力机制的关键信息聚焦能力,有效的捕捉了污染热点和时空动态。相较于传统方法,该模型在处理高污染场景(如交通高峰期)时展现出更高的敏感性和鲁棒性,为城市环境管理和公共健康改善提供了新思路。
1 文献阅读
本周阅读了一篇名为 的论文。
论文地址:https://www.sciencedirect.com/science/article/pii/S1001074224004844
论文提出了一种创新的PM2.5浓度预测方法,其核心在于引入交通拥堵指数(TCI) 作为输入特征,并结合多尺度输入模式以提升预测精度。
1.1 模型架构
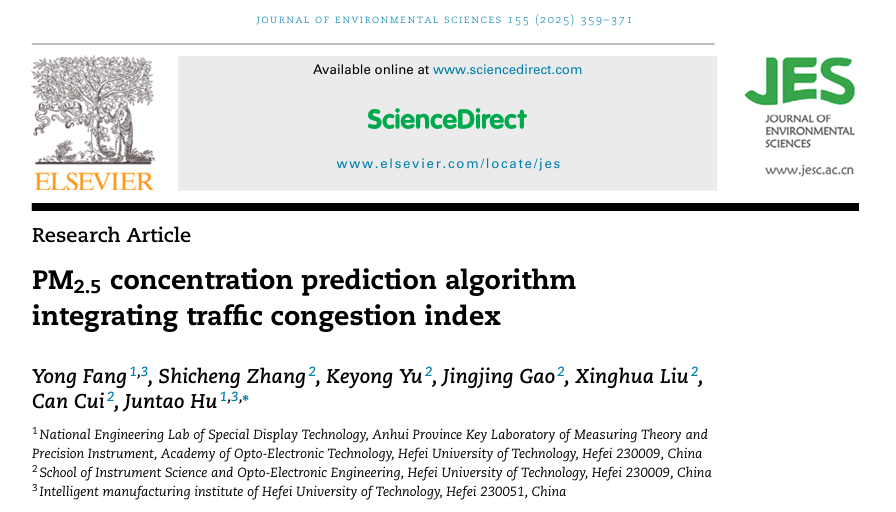
论文使用到的模型总体结构如下图所示:
其主要可以分为两个部分,第一部分是通过CNN+LSTM结构提取输入数据的时序特征,第二部分是通过GCN提取研究区域中所有空间站的空间相关特征。在获得这两部分的特征信息后将其进行拼接后再经注意力机制处理后得到最终的预测结果。
(1) 时序特征提取
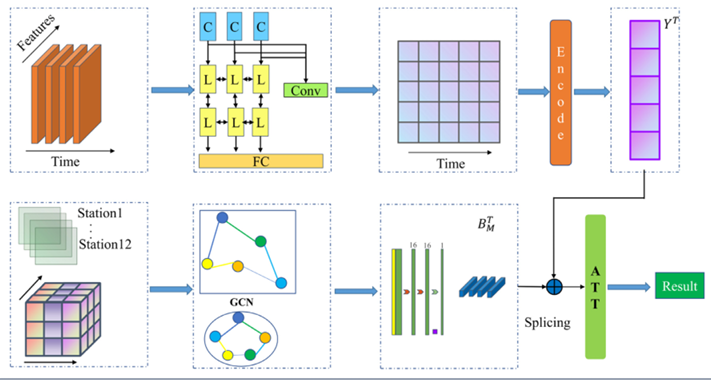
该部分的数据输入包括空气质量、气象数据以及交通拥堵指数,首先模型通过多层堆叠的卷积层,通过卷积核对多维输入数据进行卷积操作,生成特征图提取局部模式和特征。然后通过多个并行的LSTM接收CNN提取的特征序列,学习时间序列中的长期和短期依赖关系。LSTM通过其的门控机制在序列长程依赖关系的捕获上有显著优势,其结构如下所示:
此后再通过一个全连接层整合各个LSTM分支的特征,得到特征图,由于该模型的输入是多尺度的,所以还需要通过一个encoder将高维数据转换为低维的,但是关于encoder的结构论文中并无详细介绍。
(2)监测站空间相关性
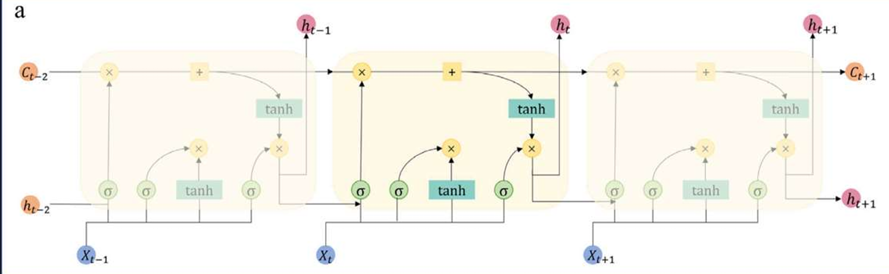
论文中通过GCN实现实验区域中各个监测站的空间相关性的信息提取,以捕捉目标站和训练站之间的空间相关性和可变性。其结构如下所示:
将每个监测站视为图结构中的一个节点。将每个节点的初始特征表示构建为一个特征向量,该特征向量集成了各种信息,包括流量敏感数据、气象数据和车站的交通拥堵指数。GCN通过聚合相邻节点的特征信息来更新当前节点的数据内容。通过不断迭代,将全部特征整合成特征矩阵,并从已知标签的特征中提取属性。
该部分的代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.data import Data
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdistnum_stations = 7
num_features = 1
time_steps = 100
sequence_length = 10
num_test = 20stations_coords = np.array([])# PM2.5数据
data = [data list]
data = np.maximum(data, 0)# 构建邻接矩阵
dist_matrix = cdist(stations_coords, stations_coords, metric='euclidean')
threshold = 0.1
adj_matrix = (dist_matrix < threshold).astype(float)
adj_matrix = adj_matrix - np.eye(num_stations)
edge_index = torch.tensor(np.where(adj_matrix > 0), dtype=torch.long)# 准备时间序列数据
X, y = [], []
for t in range(time_steps - sequence_length):X.append(data[t:t+sequence_length])y.append(data[t+sequence_length])
X = np.array(X) # (样本数, 序列长度, 站数, 特征数)
y = np.array(y) # (样本数, 站数, 特征数)train_X = X[:-num_test]
train_y = y[:-num_test]
test_X = X[-num_test:]
test_y = y[-num_test:]train_X = torch.tensor(train_X, dtype=torch.float)
train_y = torch.tensor(train_y, dtype=torch.float)
test_X = torch.tensor(test_X, dtype=torch.float)
test_y = torch.tensor(test_y, dtype=torch.float)# 定义GCN模型
class GCN(nn.Module):def __init__(self, in_channels, hidden_channels, out_channels, lstm_hidden):super(GCNLSTM, self).__init__()self.gcn1 = GCNConv(in_channels, hidden_channels)self.gcn2 = GCNConv(hidden_channels, hidden_channels)self.lstm = nn.LSTM(hidden_channels, lstm_hidden, batch_first=True)self.fc = nn.Linear(lstm_hidden, out_channels)def forward(self, data, sequence):outputs = []for t in range(sequence.shape[1]): # 遍历序列x = sequence[:, t, :, :] # (batch, stations, features)data.x = x.squeeze(-1)x = F.relu(self.gcn1(data.x, data.edge_index))x = F.relu(self.gcn2(x, data.edge_index))outputs.append(x)x = torch.stack(outputs, dim=1) # (batch, seq_len, stations, hidden)x, _ = self.lstm(x) # (batch, seq_len, lstm_hidden)x = x[:, -1, :] # 取最后一个时间步x = self.fc(x)return x# 创建图数据
graph_data = Data(edge_index=edge_index)# 训练模型
model = GCNLSTM(in_channels=num_features, hidden_channels=16, out_channels=num_features, lstm_hidden=32)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = nn.MSELoss()model.train()
for epoch in range(100):total_loss = 0for i in range(len(train_X)):optimizer.zero_grad()sequence = train_X[i:i+1] # (1, seq_len, stations, features)target = train_y[i] # (stations, features)output = model(graph_data, sequence)loss = criterion(output, target.squeeze(-1))loss.backward()optimizer.step()total_loss += loss.item()if epoch % 20 == 0:print(f'Epoch {epoch}, Loss: {total_loss / len(train_X):.4f}')# 测试模型
model.eval()
predictions = []
with torch.no_grad():for i in range(len(test_X)):sequence = test_X[i:i+1]output = model(graph_data, sequence)predictions.append(output.numpy())
predictions = np.array(predictions) # (num_test, stations, features)# 可视化预测结果
plt.figure(figsize=(15, 10))
for i in range(num_stations):plt.subplot(num_stations, 1, i+1)plt.plot(test_y[:, i, 0], label='True PM2.5', color='blue')plt.plot(predictions[:, i, 0], label='Predicted PM2.5', color='red', linestyle='--')plt.title(f'Station {i+1} PM2.5 Prediction (Guilin)')plt.xlabel('Time Step')plt.ylabel('PM2.5 (μg/m³)')plt.legend()
plt.tight_layout()
plt.savefig('pm25_predictions_guilin.png')
plt.close()# 可视化邻接矩阵
plt.figure(figsize=(8, 6))
plt.imshow(adj_matrix, cmap='Blues', interpolation='nearest')
plt.colorbar(label='Edge Weight')
plt.title('Adjacency Matrix of Guilin Monitoring Stations')
plt.xlabel('Station ID')
plt.ylabel('Station ID')
plt.xticks(np.arange(num_stations), [f'Station {i+1}' for i in range(num_stations)])
plt.yticks(np.arange(num_stations), [f'Station {i+1}' for i in range(num_stations)])
plt.savefig('adj_matrix_guilin.png')
plt.close()print("Plots saved as 'pm25_predictions_guilin.png' and 'adj_matrix_guilin.png'")
print("Graph structure and predictions generated successfully.")
最终获得所有站点的空间相关矩阵,如下图所示:
再获得输入数据的时序特征和检测站点间的空间相关性后,将这两部分拼接后再经注意力机制计算隐藏状态的权重,突出重要时间步。论文中使用的注意力机制结构如下图所示:
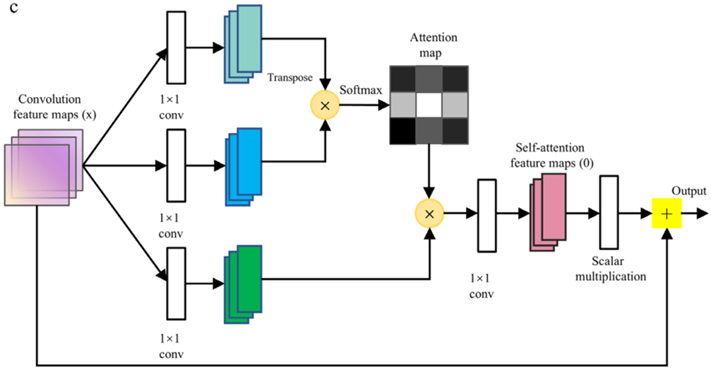
首先通过三个一维卷积分别获得Q、K、V矩阵,再进行注意力计算得到自注意力特征。将计算所得的注意力特征图进行矩阵乘法进行特征的校验,最后根据输入特征调整融合特征的维度得到最后的输出。
1.2 实验分析
(1)数据集
研究区域位于上海,实验所用数据包括2018年1月1日至2019年10月28日间上海7个监测站的每小时污染物浓度,包括包括颗粒物、一氧化碳、二氧化氮、臭氧和二氧化硫,其中以颗粒物研究为主,其他为辅;上海气象局提供的气象数据以及上海交通出行网和高德交通大数据平台提供的交通拥堵指数。原始数据共有165274条。
(2)数据预处理
实验按时间顺序划分,将数据的85%划分为训练,15%划分为测试集,预处理包括数据缺失值和异常值的处理,并通过线性插值法来保证数据的完整性:

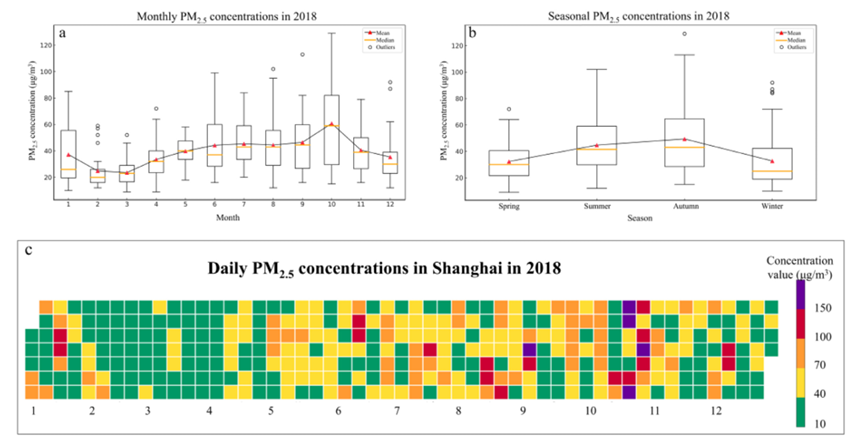
处理后的数据中PM2.5的分布情况如下图所示:
同时,因为有交通拥塞指数的输入,实验前需要分析交通拥塞指数与污染物浓度之间的相关性,在这里作者使用的是Pearson相关系数:

此后再经归一化后得到正式用于处理的数据,归一化是将数据按比例缩放到特定范围(如0,1或−1,1)的过程,目的是消除不同特征间的量纲差异,使数据具有可比性,通过归一化可以减少模型对某些特征数值范围的敏感性,避免过拟合,从而提高了模型的泛化能力。以层归一化为例,其计算过程如下:

(3)评估标准与基线
1.RMSE:
R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 {RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
2.MAE:
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
3.R2:
R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
实验所对比的基线模型有:ARMA、ANN、LSTM、CNN-LSTM、GCN-LSTM。
(4)实验结果
1)消融实验
论文的核心创新点是交通拥塞指数的添加,所以消融实验是为了确认该部分的数据对实验的影响,实验结果如下所示:
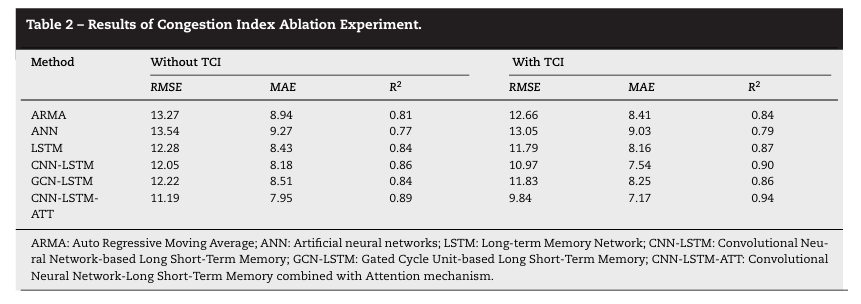
由结果可知,具有交通拥堵指数特征参数的预测模型在RMSE、MAE和R2都优于基准模型,证明了交通拥塞指数作为输入特征的必要性。
2)多尺度输入模式实验
这部分实验是为了探索不同粒度的TCI数据(道路粒度和行政区粒度)对PM2.5预测性能的影响,并验证将两种粒度结合是否能进一步提升预测精度,实验结果如下:
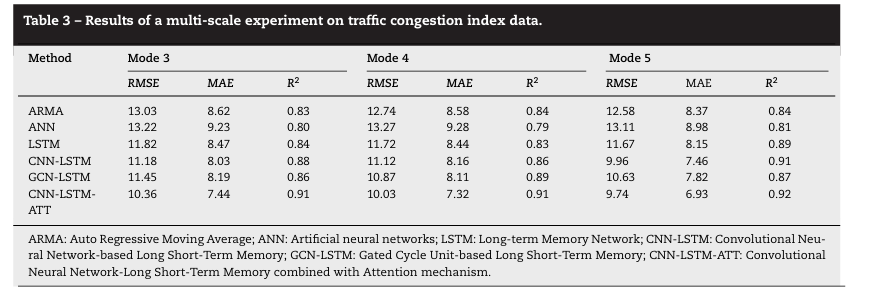
该部分实验验证了复合TCI输入的优越性,证明道路和行政区粒度的TCI能够协同作用,在加入道路颗粒度的交通拥堵指数后,各基准模型的预测性能总体上有所提高,优于使用单一气象和空气质量数据的基准模型。这一结果有力地证实了多尺度交通拥堵指数对PM2.5预测的协同作用。
3)早晚高峰预测实验
这部分实验的目的是评估模型在交通高峰期的PM2.5预测性能,特别是在引入TCI后是否能有效捕捉高峰期交通排放导致的污染热点,实验结果如下:
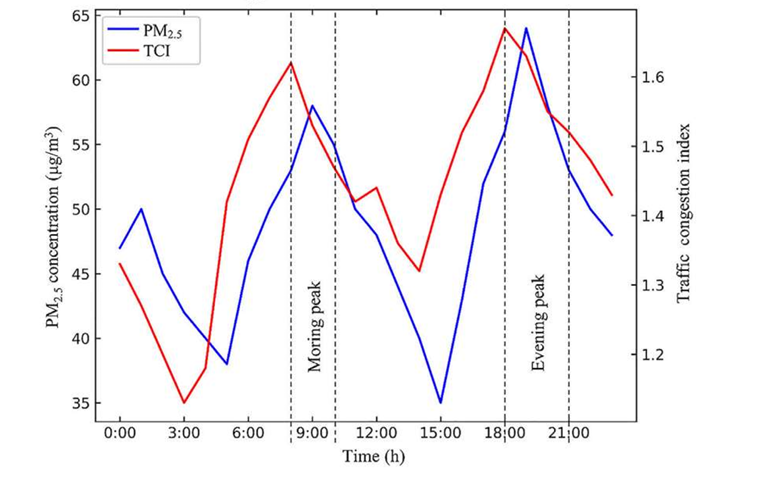
实验结果表明,含TCI的模型在高峰期表现优异,这表明TCI显著提升了模型对高峰期污染的预测能力,特别是在早晨高峰,模型能够精确识别污染热点。实验结果表明,含TCI的模型在高污染场景下具有优异的鲁棒性。
总结
本周阅读的论文中的算法结合了交通拥堵指数的多尺度特征。将交通拥堵指数视为模型的新输入特征,充分考虑了交通拥堵对城市颗粒物污染和空间异质性的影响。但其中也不乏存在一些可以改进的地方。结合之前阅读的文献中的方法,在基于GCN的监测站相关性邻接矩阵的建模中可以采取动态图邻接矩阵;在数据预处理过程中,本次阅读的论文中的数据预处理比较简单,例如:线性插值可能忽略时间序列的非线性特性。可以通过采用更好的预处理方法从而进一步提高模型的性能。