网络开发基础(游戏)之 心跳机制
简介
心跳机制:是指客户端定时(比如每隔着10秒)向服务端发送PING消息,服务端收到后回应PONG消息。服务端会记录客户端最后一次发送PING消息的时间,如果很久没有收到下一次客户端发来的消息,服务端就就判定客户端断开连接,服务端会关闭连接,释放系统资源。
心跳机制是网络通信中保持连接活跃性的重要技术,主要用于检测连接是否仍然有效,防止因长时间无通信而被防火墙或路由器断开连接。
protobuf定制协议参考
// Heartbeat.proto
syntax = "proto3";package NetworkProtocol;// 心跳请求消息(客户端→服务端)
message HeartbeatRequest {int64 timestamp = 1; // 时间戳(毫秒)uint32 sequence = 2; // 序列号string client_id = 3; // 客户端IDdouble cpu_usage = 4; // 可选:客户端CPU使用率double memory_usage = 5; // 可选:客户端内存使用率
}// 心跳响应消息(服务端→客户端)
message HeartbeatResponse {int64 timestamp = 1; // 时间戳(毫秒)uint32 sequence = 2; // 与请求相同的序列号bool healthy = 3; // 服务健康状态string message = 4; // 可选:附加消息
}客户端流程
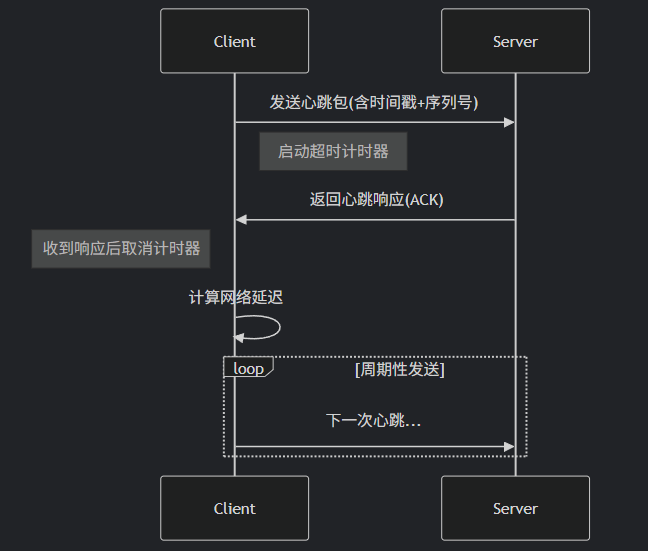
服务端流程
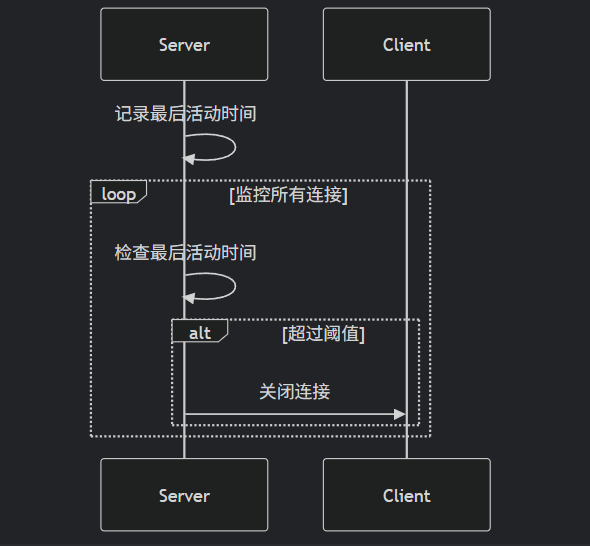
分类
单向心跳
仅仅客户端发送给服务端心跳请求,服务端仅做回复
-
典型场景:
-
传统C/S架构(如HTTP服务)
-
服务端无需主动检测客户端状态的场景
-
客户端需要保活但服务端无状态要求
-
-
优点:
-
实现简单,减少网络开销
-
服务端压力小
-
-
缺点:
-
服务端无法主动感知客户端异常(如客户端进程崩溃但TCP连接未断开)
-
无法检测双向网络链路质量
-
双向心跳
客户端和服务端都向对方心跳请求,并回复对方的请求。
-
典型场景:
-
对等网络(P2P)
-
实时通信系统(如WebSocket、游戏服务器)
-
需要双向健康检测的关键系统
-
-
优点:
-
双向健康检测:双方都能感知对方状态
-
链路质量监控:可测量双向网络延迟
-
容错性更强:避免单侧假死问题
-
-
缺点:
-
实现复杂度稍高
-
增加少量网络开销
-
优缺点
优点
| 连接状态检测 | 及时性:能够快速发现断开的连接(相比等待TCP超时) 可靠性:比依赖TCP底层机制更可靠,特别是在NAT环境下 |
| 连接保持 | 防止超时断开:避免因长时间无数据传输被防火墙/NAT设备断开 维持会话:保持长时间会话的有效性(如即时通讯、在线游戏) |
| 灵活性 | 可定制性:可以自定义心跳间隔、超时时间和处理逻辑 应用层控制:比TCP Keep-Alive提供更多的控制权 |
| 资源管理 | 及时释放资源:能快速检测死连接并释放相关资源 |
缺点
| 额外开销 | 带宽消耗:定期发送心跳包会增加网络流量 CPU/内存消耗:需要额外线程/任务来处理心跳逻辑 |
| 实现复杂性 | 同步问题:需要处理多线程同步问题(如最后接收时间的更新) 异常处理:需要完善处理各种网络异常情况 |
| 可能的误判 | 网络延迟:在高延迟网络中可能导致误判连接断开 短暂波动:网络短暂不稳定可能导致不必要的重连 |
| 配置挑战 | 参数调优:需要根据实际网络环境调整心跳间隔和超时时间 太短:增加不必要的网络负担 太长:无法及时检测断开 |
注意事项
合理设置心跳间隔
太短会增加网络负担,太长可能导致连接断开不能及时发现,通常建议30秒到5分钟之间。
双向心跳
不仅客户端发送心跳,服务器也应定期发送心跳,双向检测确保连接的双向有效性。
心跳超时处理
设置合理的超时时间(通常是心跳间隔的2-3倍),超时后应断开连接并尝试重连。
心跳包设计
尽量小(1-2字节足够),可以包含时间戳或序列号用于检测延迟。
异常处理
心跳失败应触发重连机制,记录心跳异常日志用于分析网络问题。
自适应心跳
可以根据网络状况动态调整心跳间隔,网络差时缩短间隔,良好时可适当延长。
资源释放
确保在断开连接时停止所有心跳计时器,避免内存泄漏。
心跳机制是网络通信中保持连接可靠性的重要手段,合理实现可以大大提高应用程序的稳定性。
课外阅读
心跳风暴
心跳风暴是指网络通信中由于心跳机制设计不当,导致短时间内大量心跳消息集中爆发,引发系统性能下降甚至瘫痪的现象。以下是全面分析:
一、核心特征
-
突发性流量激增:短时间内出现远超正常水平的心跳报文
-
资源耗尽表现:
-
CPU占用率飙升
-
网络带宽被占满
-
连接数暴涨
-
-
连锁反应:
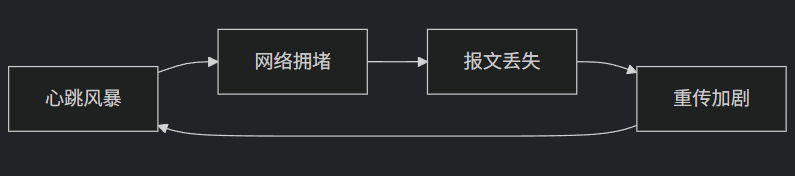
二、典型成因
1. 同步化发送
-
问题场景:所有客户端在同一时刻(比如每5秒)发送心跳
-
雪崩效应:服务端每5秒遭遇一次流量洪峰
2. 异常触发机制
-
错误恢复策略:连接断开后所有客户端同时重连
-
案例:某交易所系统在网络恢复后,8万台设备在1秒内同时重连
三、灾难性后果
| 影响层面 | 具体表现 |
|---|---|
| 网络设备 | 交换机端口拥塞,ARP表溢出 |
| 服务器 | TCP连接数突破极限,OOM killer触发 |
| 应用程序 | 业务请求超时,成功率暴跌 |
| 监控系统 | 告警风暴淹没真实问题 |
| 运维响应 | 难以定位根本原因 |
四、解决方案
1. 时间随机化,加入随机扰动
2. 指数退避策略
3. 分级心跳机制
| 层级 | 检测目标 | 间隔 | 协议 |
|---|---|---|---|
| L1 | 物理连接 | 5s | TCP Keepalive |
| L2 | 应用层连接 | 30s | 自定义协议 |
| L3 | 业务健康度 | 300s | 聚合报告 |
4. 服务端防护
五、经典案例复盘
某云计算平台故障
-
现象:
-
00:00整点10万VM同时上报心跳
-
控制平面API服务雪崩
-
故障持续53分钟
-
-
根本原因:
-
NTP时间同步导致所有VM系统时钟对齐
-
固定间隔心跳未设置随机延迟
-
-
修复方案:
-
客户端心跳增加±15%随机抖动
-
服务端实现令牌桶限流
-
建立分级心跳体系
-