哈夫曼树和哈夫曼编码
哈夫曼编码一般用来对字符串进行编码格式的表示。其中要克服的最大问题,莫过于就是一串由0或者1组成的编码,你无法区分哪些01组成的编码部分是属于哪些字符的,因此哈夫曼编码的出现解决了这个问题。
在介绍哈夫曼编码之前,先介绍以下哈夫曼树:
哈夫曼树(Huffman Tree),又称最优二叉树,是一种带权路径长度最短的二叉树,由美国数学家大卫·哈夫曼(David A. Huffman)在1952年提出。以下从基本概念、构建过程和应用场景等方面进行介绍:
-
基本概念
-
路径和路径长度:在一棵树中,从一个结点到另一个结点所经过的分支序列称为路径,路径上的分支数目称为路径长度。
-
结点的权和带权路径长度:若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为从根结点到该结点的路径长度与该结点权值的乘积。
-
树的带权路径长度:树中所有叶子结点的带权路径长度之和,记为WPL。哈夫曼树就是WPL最小的二叉树。
-
-
构建过程
-
假设有n个权值,将这些权值看成是有n棵树的森林(每棵树仅有一个结点)。
-
从森林中选出根结点权值最小的两棵树作为左右子树构造一棵新的二叉树,新二叉树的根结点权值为其左右子树根结点权值之和。
-
从森林中删除这两棵树,同时将新得到的二叉树加入森林中。
-
重复上述步骤,直到森林中只剩下一棵树为止,这棵树就是哈夫曼树。
-
-
特点
-
哈夫曼树是一棵二叉树,且所有的非叶子结点都有两个子树,不存在度为1的结点。
-
权值越大的叶子结点越靠近根结点,而权值越小的叶子结点越远离根结点。
-
-
应用场景
-
数据压缩:哈夫曼编码是一种常用的无损数据压缩算法。通过对数据中不同字符出现的频率进行统计,构造哈夫曼树,为每个字符分配一个唯一的二进制编码,频率高的字符编码短,频率低的字符编码长,从而实现数据的压缩。
-
信息检索:在一些需要快速检索的数据结构中,可以利用哈夫曼树的思想来优化查找过程,提高查找效率。
-
霍夫曼编码:在通信领域,用于构造一种编码方式,使得通信中传输的数据量最小,提高信道的利用率。
-
通过应用场景我们可以发现哈夫曼树就是主要实现单个字符唯一编码的功能。
我们来用举例的方法来讲解哈夫曼树:
一句话:
i like bananas
-
-
在句子“i like bananas”中,统计每个字母的出现次数如下:
-
a:3
-
b:1
-
i:2
-
k:1
-
l:1
-
n:2
-
s:1
-
空格:2
-
e:1
-
-
然后开始搭建哈夫曼树:
-
初始节点(叶子节点):
-
节点
a,权重(出现次数)为 3 -
节点
b,权重为 1 -
节点
i,权重为 2 -
节点
k,权重为 1 -
节点
l,权重为 1 -
节点
n,权重为 2 -
节点
s,权重为 1 -
节点
e,权重为 1
-
-
第一次合并:
-
取出权重最小的
b(权重 1)和k(权重 1),创建新节点N1,权重为 1 + 1 = 2 。 -
N1的左子节点为b,右子节点为k。 -
此时节点情况:
-
节点
a,权重 3 -
节点
i,权重 2 -
节点
l,权重 1 -
节点
n,权重 2 -
节点
s,权重 1 -
节点
e,权重 1 -
节点
N1,权重 2
-
-
-
第二次合并:
-
取出权重最小的
l(权重 1)和s(权重 1),创建新节点N2,权重为 1 + 1 = 2 。 -
N2的左子节点为l,右子节点为s。 -
此时节点情况:
-
节点
a,权重 3 -
节点
i,权重 2 -
节点
n,权重 2 -
节点
e,权重 1 -
节点
N1,权重 2 -
节点
N2,权重 2
-
-
-
第三次合并:
-
取出权重最小的
e(权重 1)和N1(权重 2),创建新节点N3,权重为 1 + 2 = 3 。 -
N3的左子节点为e,右子节点为N1。 -
此时节点情况:
-
节点
a,权重 3 -
节点
i,权重 2 -
节点
n,权重 2 -
节点
N2,权重 2 -
节点
N3,权重 3
-
-
-
第四次合并:
-
取出权重最小的
i(权重 2)和N2(权重 2),创建新节点N4,权重为 2 + 2 = 4 。 -
N4的左子节点为i,右子节点为N2。 -
此时节点情况:
-
节点
a,权重 3 -
节点
n,权重 2 -
节点
N3,权重 3 -
节点
N4,权重 4
-
-
-
第五次合并:
-
取出权重最小的
a(权重 3)和N3(权重 3),创建新节点N5,权重为 3 + 3 = 6 。 -
N5的左子节点为a,右子节点为N3。 -
此时节点情况:
-
节点
n,权重 2 -
节点
N4,权重 4 -
节点
N5,权重 6
-
-
-
第六次合并:
-
取出权重最小的
n(权重 2)和N4(权重 4),创建新节点N6,权重为 2 + 4 = 6 。 -
N6的左子节点为n,右子节点为N4。 -
此时节点情况:
-
节点
N5,权重 6 -
节点
N6,权重 6
-
-
-
第七次合并:
-
取出
N5(权重 6)和N6(权重 6),创建新节点Root(根节点),权重为 6 + 6 = 12 。 -
Root的左子节点为N5,右子节点为N6。
-
通过上述步骤我们得到了哈夫曼树:
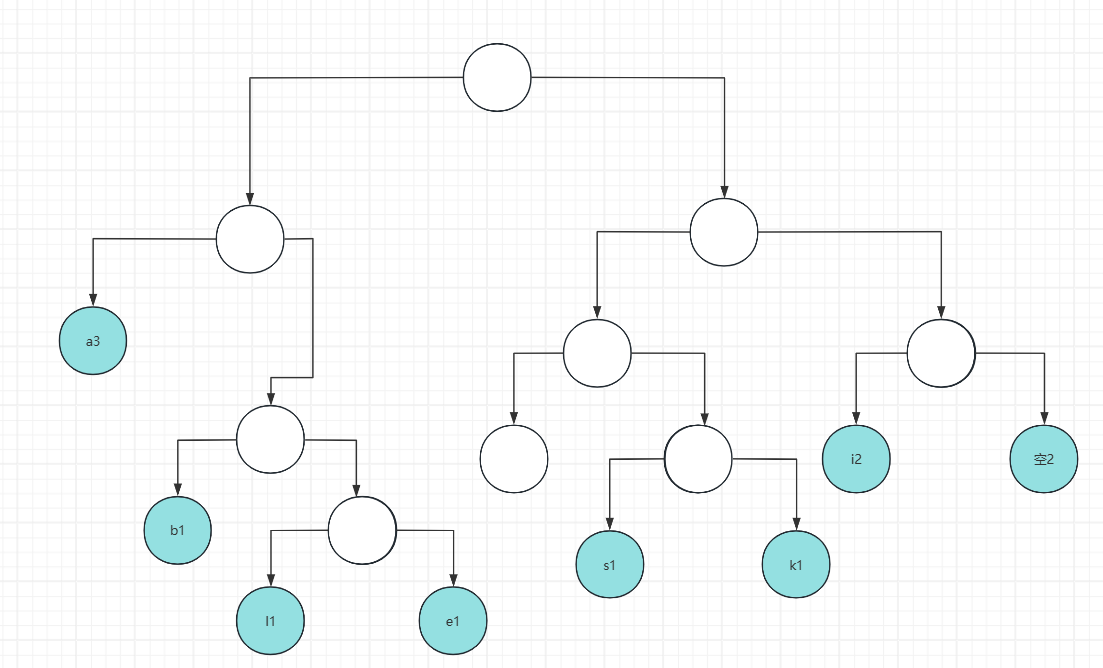
然后我们将向左移动的路径设置为0,向右的为1
我们的哈夫曼树就变为:
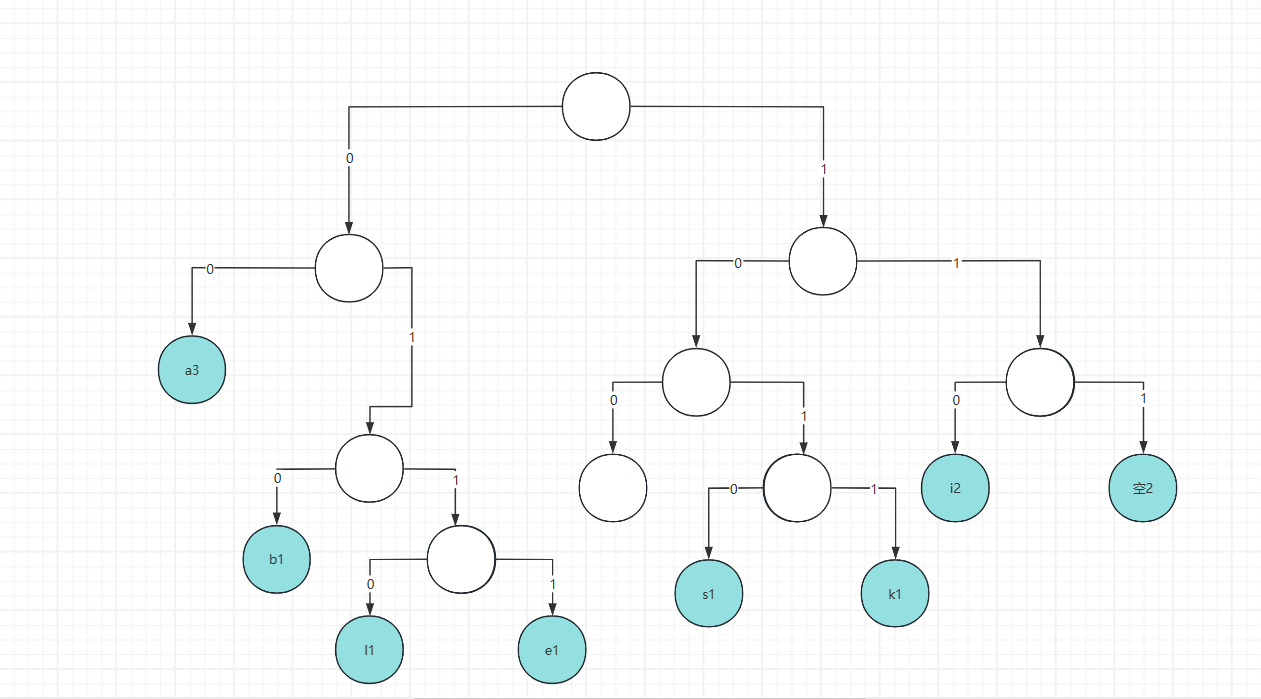
有了哈夫曼树,我们的哈夫曼编码也就得到了,每个字符的编码就为从根路径到指定字符的叶子节点:
-
a:出现次数为 3,编码是 00
-
n:出现次数为 2,编码是 100
-
i:出现次数为 2,编码是 110
-
空:出现次数为 2,编码是 111
-
l:出现次数为 1,编码是 0110
-
k:出现次数为 1,编码是 1011
-
e:出现次数为 1,编码是 0111
-
b:出现次数为 1,编码是 010
-
s:出现次数为 1,编码是 1010