AIDC智算中心建设:计算力核心技术解析
目录
一、智算中心发展概览
二、计算力核心技术解析

一、智算中心发展概览
智算中心是人工智能发展的关键基础设施,基于人工智能计算架构,提供人工智能应用所需算力服务、数据服务和算法服务的算力基础设施,融合高性能计算设备、高速网络以及先进的软件系统,为人工智能训练和推理提供高效、稳定的计算环境。智算中心的主要功能包括:
-
提供强大的计算能力:智算中心采用专门的AI算力硬件,如GPU、NPU、TPU等,以支持高校的AI计算任务。
-
高效的数据处理:智算中心融合了高性能计算设备和高速网络,能够处理大规模的数据集和复杂的计算任务。
-
支持多种AI应用:智算中心适用于计算机视觉、自然语言处理、机器学习等领域,处理图像识别、语音识别、文本分析、模型训练推理等任务。
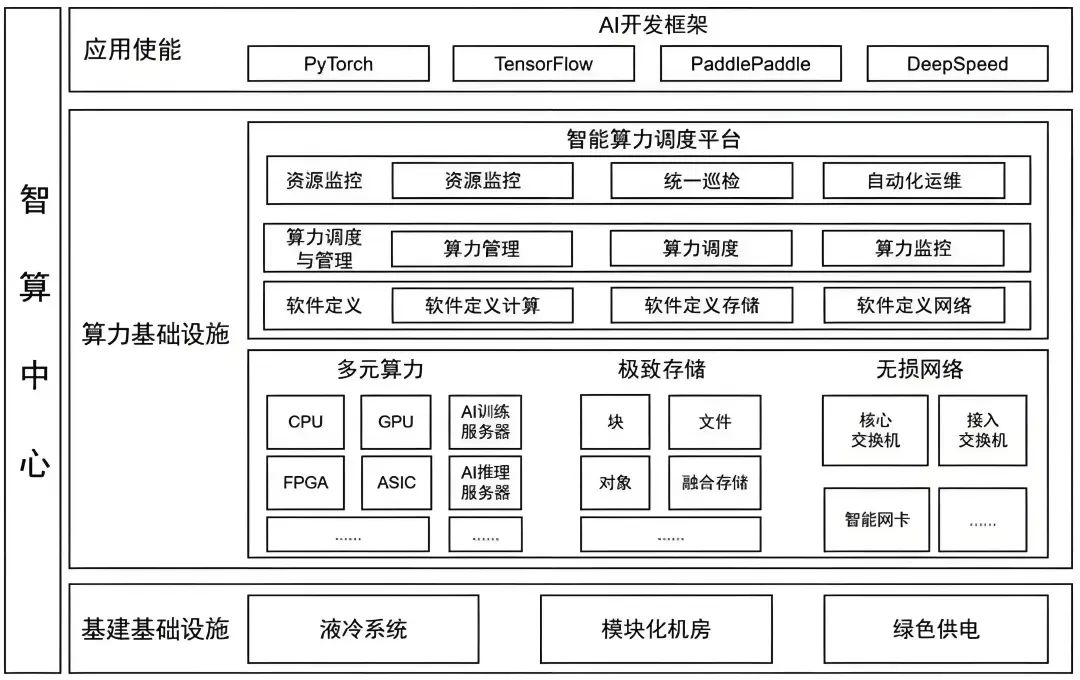
智算中心AIDC内涵
狭义上讲,智算中心是通用算力中心的升级,在传统数据中心的基础上融合GPU、TPU、FPGA等专用芯片支撑大量数据处理和复杂模型训练。AIDC把不同的计算任务实时智能调度分配给不同的服务器集群以提升计算效率。简单讲智算中心就是“机房+网络+GPU 服务器+算力调度平台”的融合基础设施,是传统数据中心的增值性延伸。
广义地说,智算中心是提供人工智能应用所需算力服务、数据服务和算法服务的新型算力基础设施,包含基础层、平台层和应用层。其中,基础部分是支撑智算中心建设与应用的先进人工智能理论和计算架构,平台部分围绕智算中心算力生产、聚合、调度、释放的作业逻辑展开;应用层提供算力生产供应、数据开放共享、智能生态建设和产业创新聚集。是融合算力+数据+算法的新型基础设施,是AI技术一体化的载体,是传统云的智能化升级。
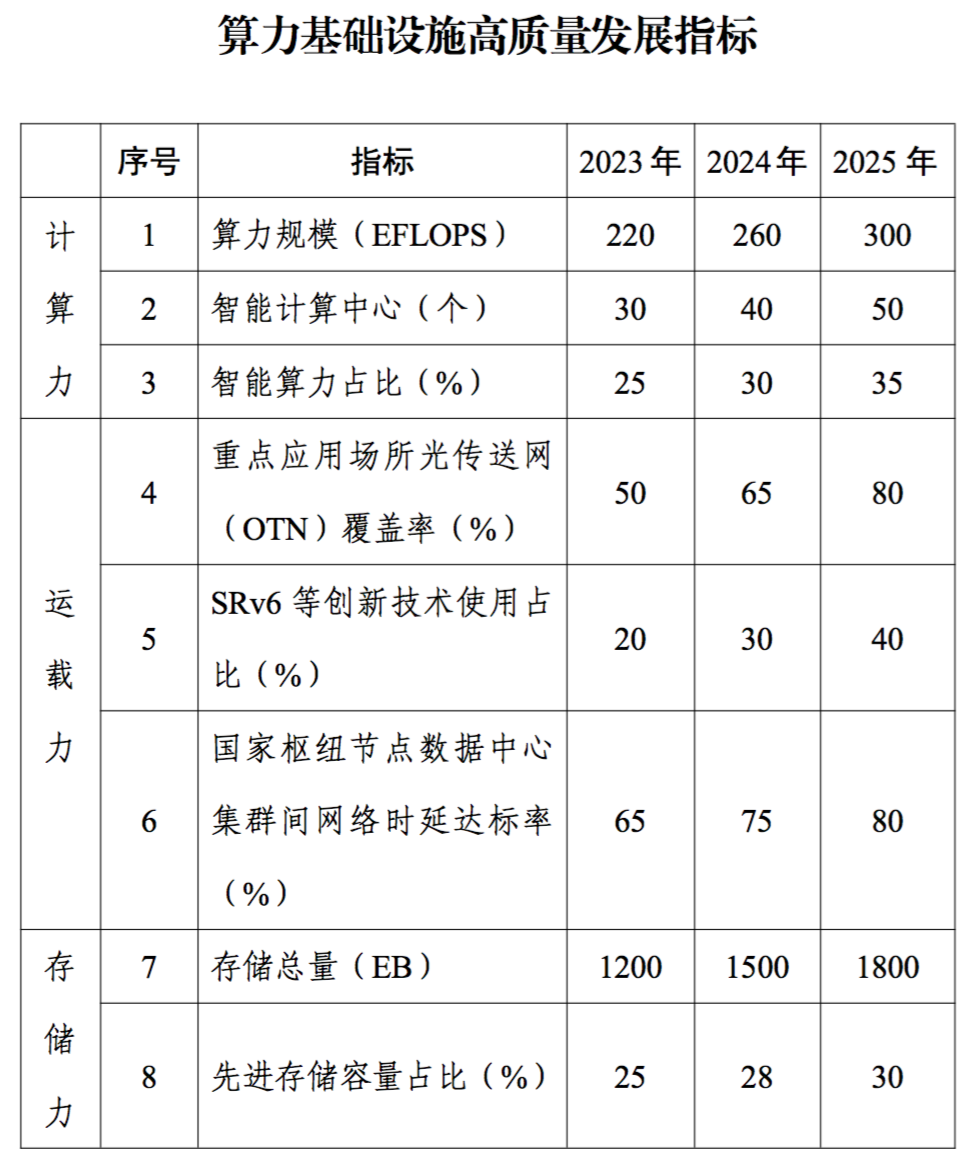
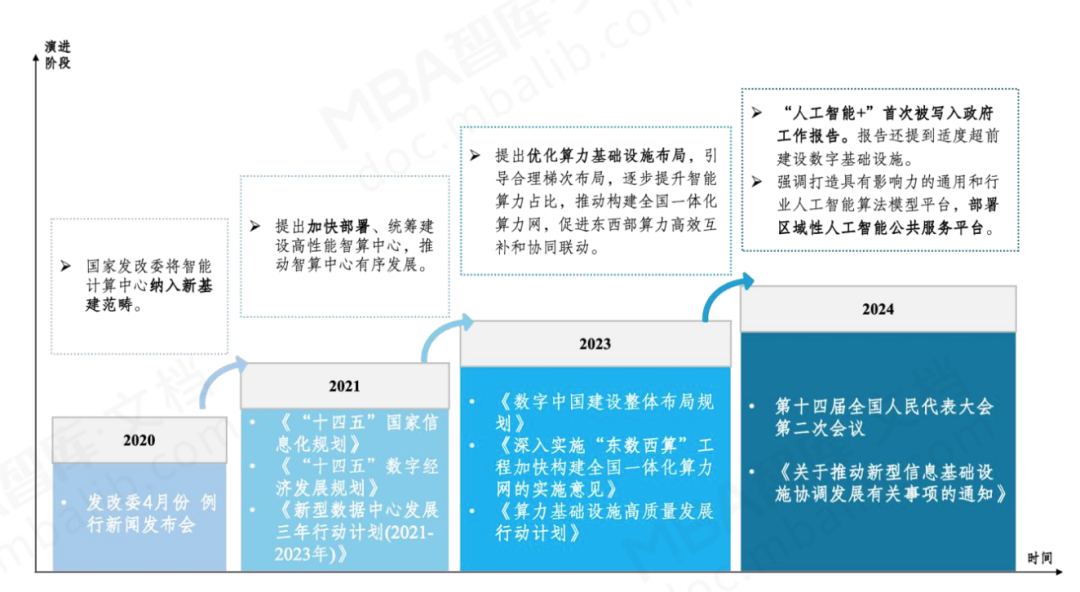
人工智能作为引领未来的战略性技术,逐步成为衡量国家国际竞争力的重要领域,高性能算力是人工智能发展的重要组成部分。从全球范围看,各国纷纷制定人工智能相关的战略和政策,推动高性能算力发展。如美国成立智算中心基础设施特别工作组、欧盟出台《欧盟高性能计算共同计划》、日本发布《人工智能战略2022》等。我国也于2023年出台《算力基础设施高质量发展行动计划》,进一步凝聚产业共识、强化政策引导,全面推动我国算力基础设施高质量发展。报告要求,到2025年要实现如下主要目标:

算力常用计量单位是每秒执行的浮点运算次数(FLOPS,Floating-point operations per second),数值越大计算能力越强。
KFLOPS(kiloFLOPS)=10^3 FLOPS
MFLOPS(megaFLOPS)=10^6 FLOPS
GFLOPS(gigaFLOPS)=10^9 FLOPS
TFLOPS(teraFLOPS)=10^12 FLOPS
PFLOPS(petaFLOPS)=10^15 FLOPS
EFLOPS(exaFLOPS)=10^18 FLOPS
存储容量常用计量单位是艾字节(EB,1EB=2^60bytes)
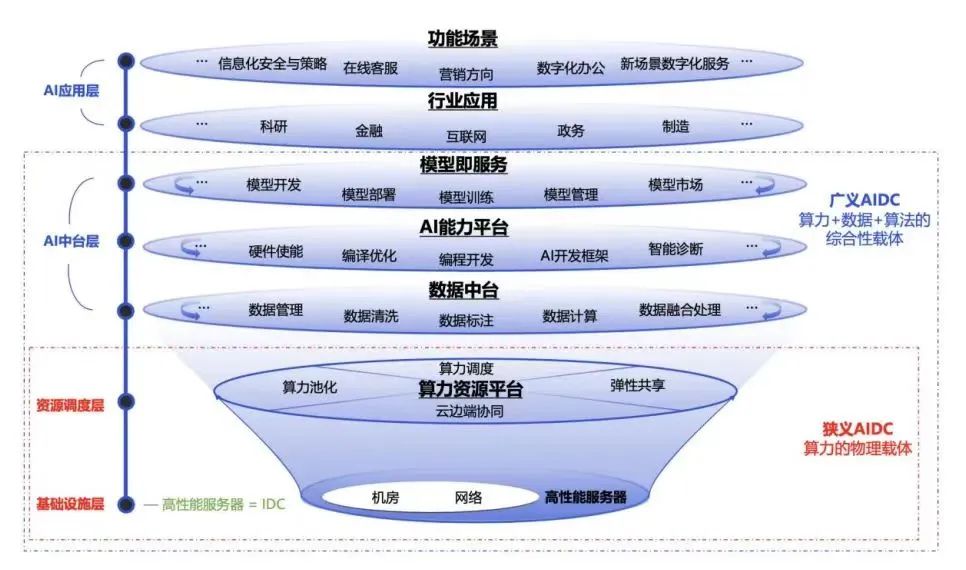
智算中心产业及市场规模
智算中心产业链涵盖从AI芯片/服务器等设计制造、基础设施建设,到智算服务提供,以及生成式大模型研发及基于大模型的行业应用。
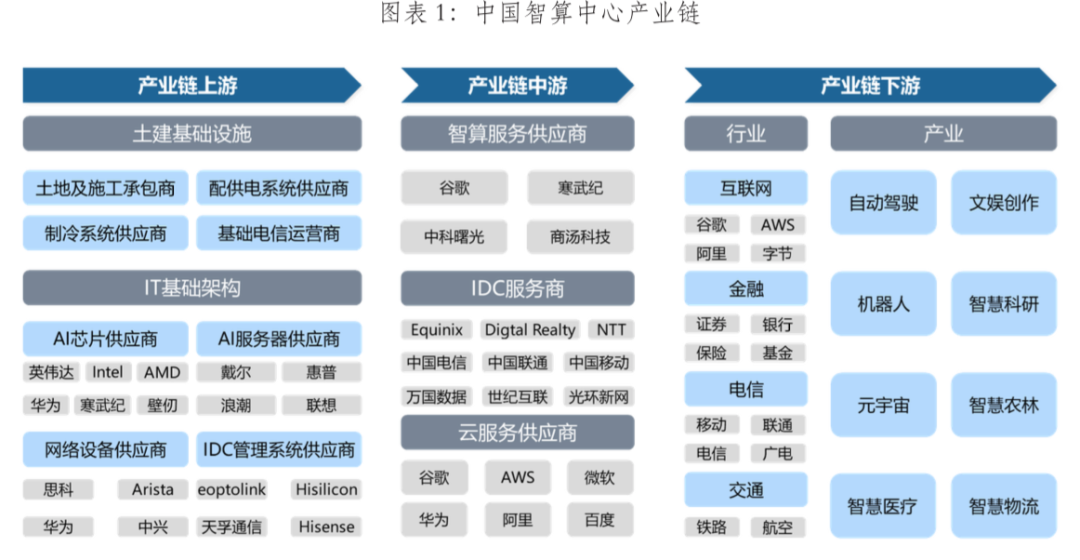
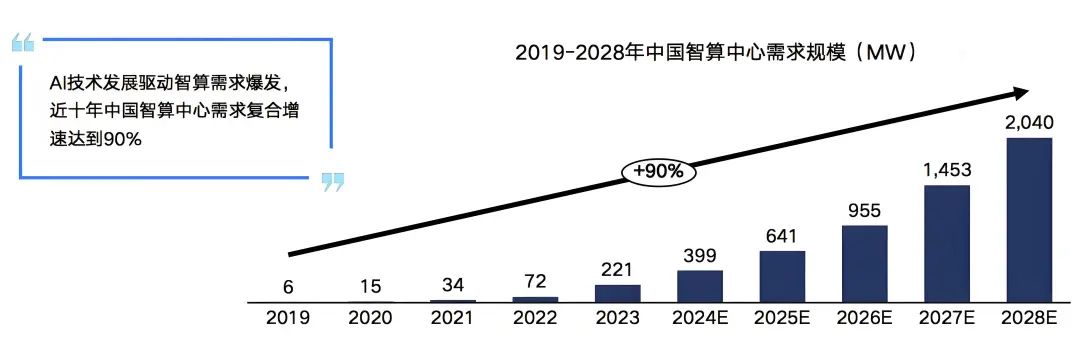
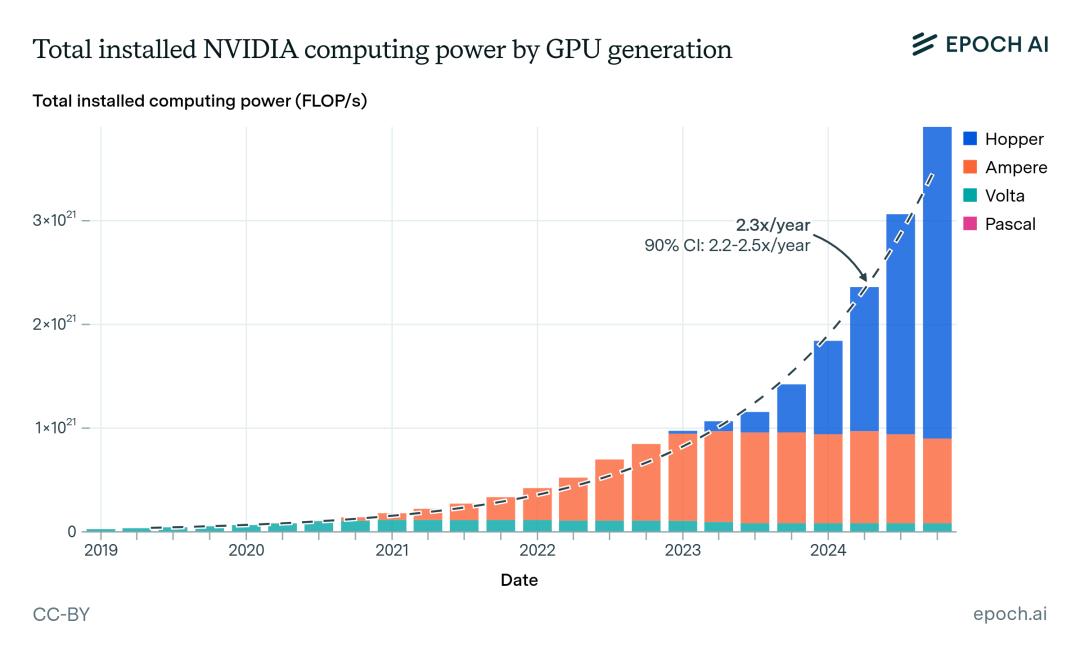
在需求的推动下我国智算中心市场投资规模高速增长。2022年生成式人工智能大模型推向市场,在过国内引起AIGC发展热潮,大模型训练对智能算力的需求迅速攀升。2023年起国内头部互联网企业及科技公司加速AIGC布局,政府也牵头建设公共智能算力中心,赋能社会数字化转型需求,全国智算中心投资火热,智算中心市场规模大幅增长,尤其是今年1月份DeekSeep的火爆出圈,更是进一步加速了这一进程。
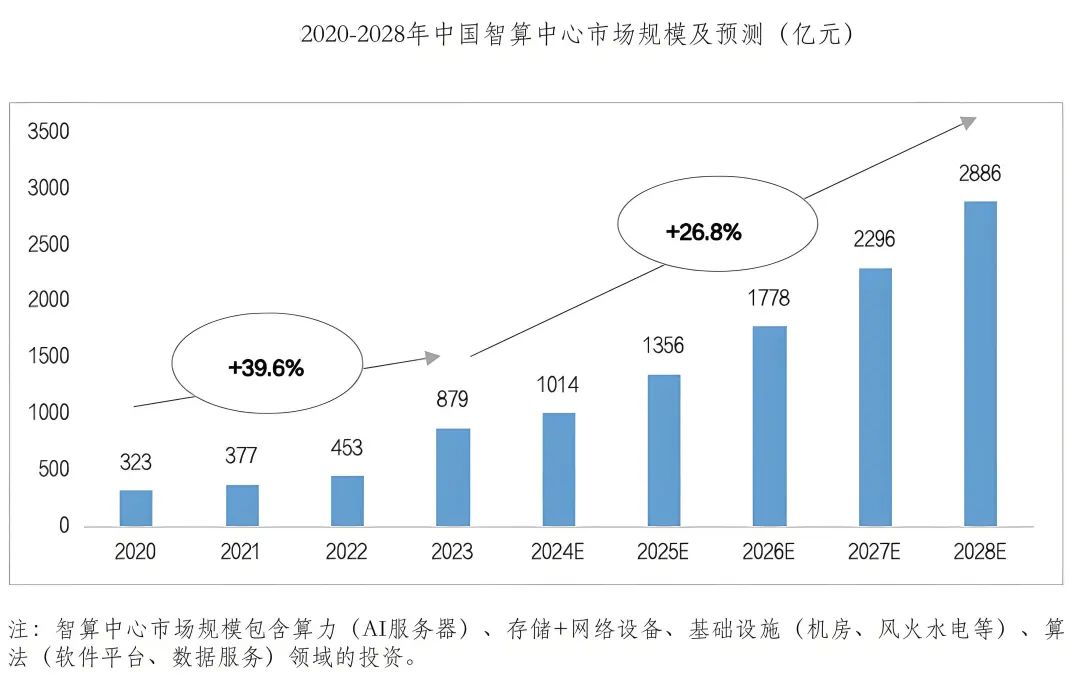
虽然近期有消息称,智算中心建设暂时按下了减速键,但是未来,AI大模型应用场景,不断丰富,商用进程逐步加快,智算中心市场增长动力逐渐由训练切换至推理,市场进入平稳增长期,预计2028年我国智算中心市场投资规模有望达到2886亿元。
二、计算力核心技术解析
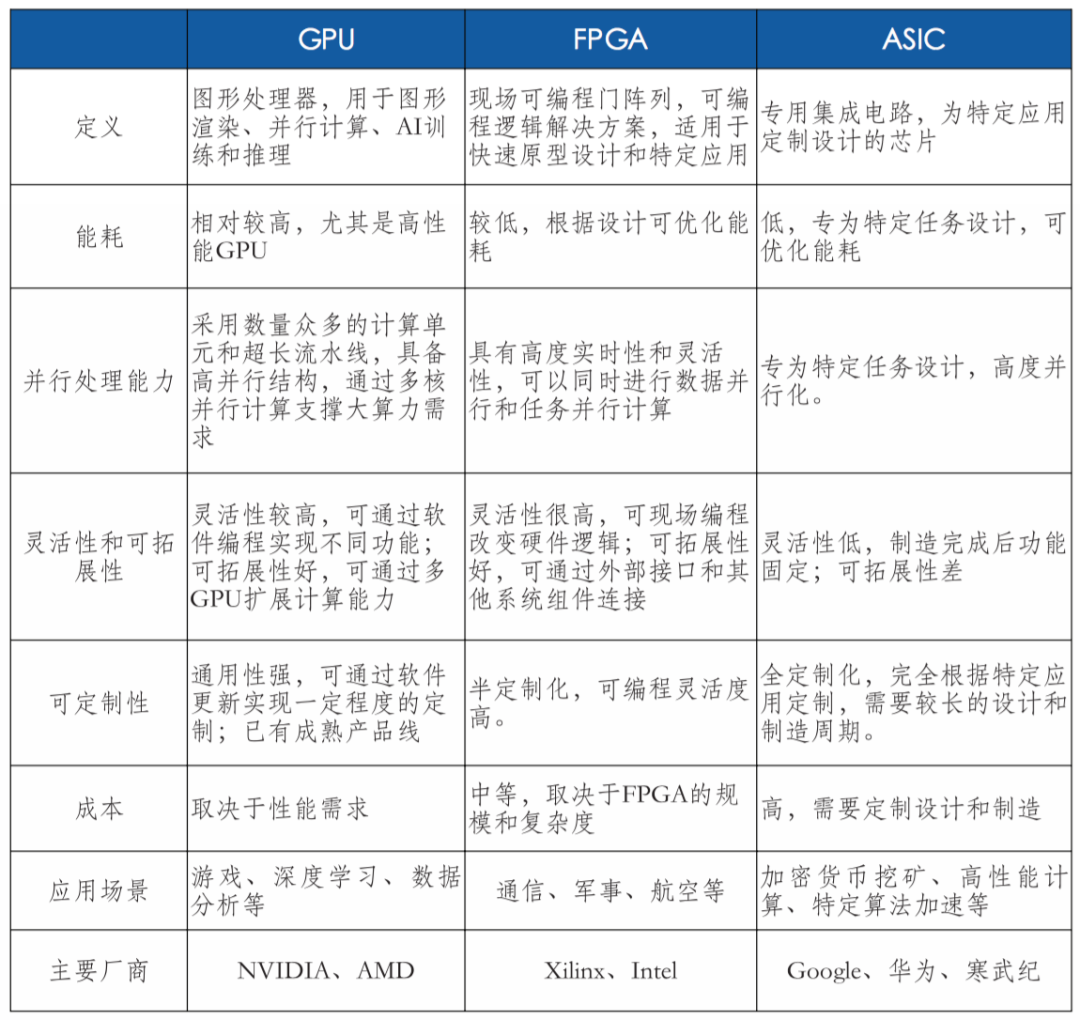
AI芯片
智算中心常见应用场景为训练和推理,根据其对算力精度的需求的差异分为FP32、TF32、FP16、BF16、INT8、FP8、FP6、FP4等。智能算力的核心是CPU、GPU、FPGA、ASIC等各类计算芯片。AI芯片内核数量多,擅长并行计算,满足AI算法所需要的大量并行处理能力,并显著提升计算效率和灵活性。智算服务器是智算中心的主要算力硬件一般采用CPU+GPU、CPU+FPGA、CPU+ASIC等异构形式,以充分发挥不同算力芯片在性能、成本和能耗上的优势。
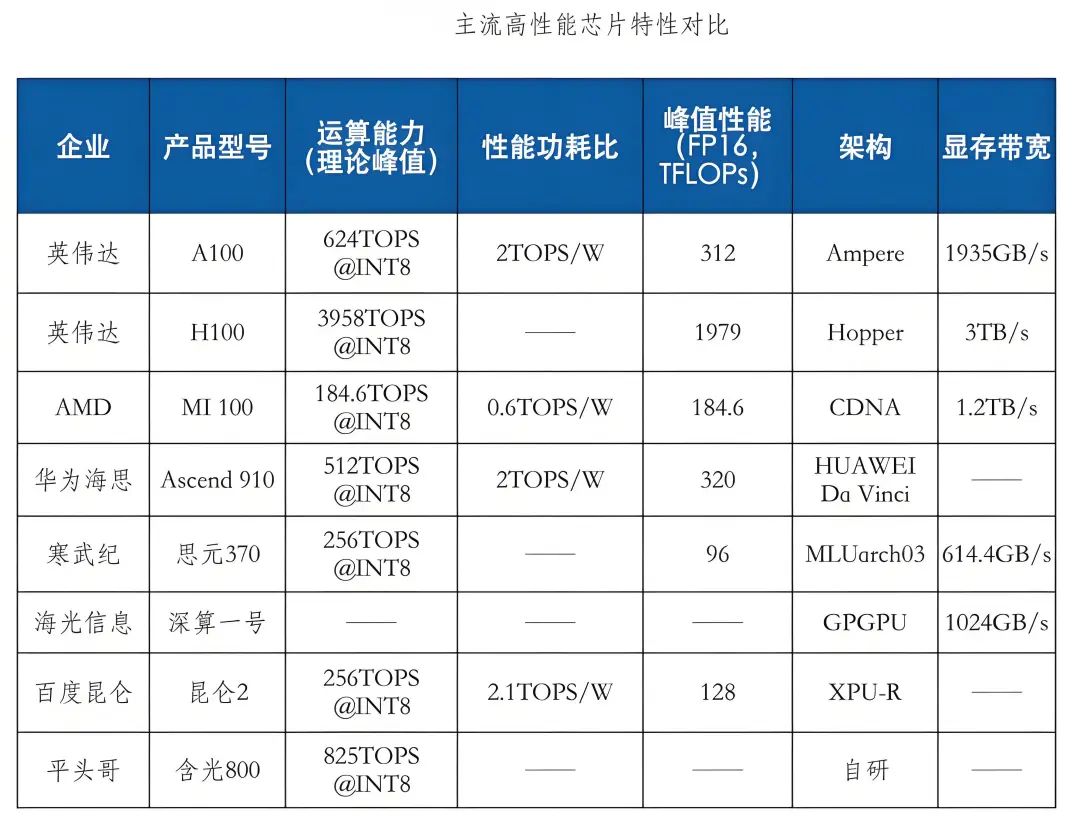
高性能芯片技术快速迭代创新,为人工智能发展提供保障,进而带动智算中心发展,Nvidia作为全球GPU算力芯片市场领导者,代表性产品H100、A100、V100技术指标处于领先水平,最新的Blackwell架构B200 GPU采用先进的4纳米工艺,实现了基于FP4高达40PFLOPS的运算能力,相较前代提升5倍。其他科技巨头如AMD、英特尔、微软、亚马逊和谷歌也在AI芯片领域展开竞争。同时,我国AI芯片国产化进程正在加速发展,华为、寒武纪、海光信息、景嘉微以及阿里、百度等企业不仅在自研AI芯片技术上取得重要进展,还通过产品集成、行业解决方案及生态伙伴合作等方式推进国产AI芯片商业化应用,为智能算力发展提供坚实基础。
Nvidia H100 GPU
本节基于Nvidia的公开资料GPU H100报告为例,解析GPU的相关技术实现。
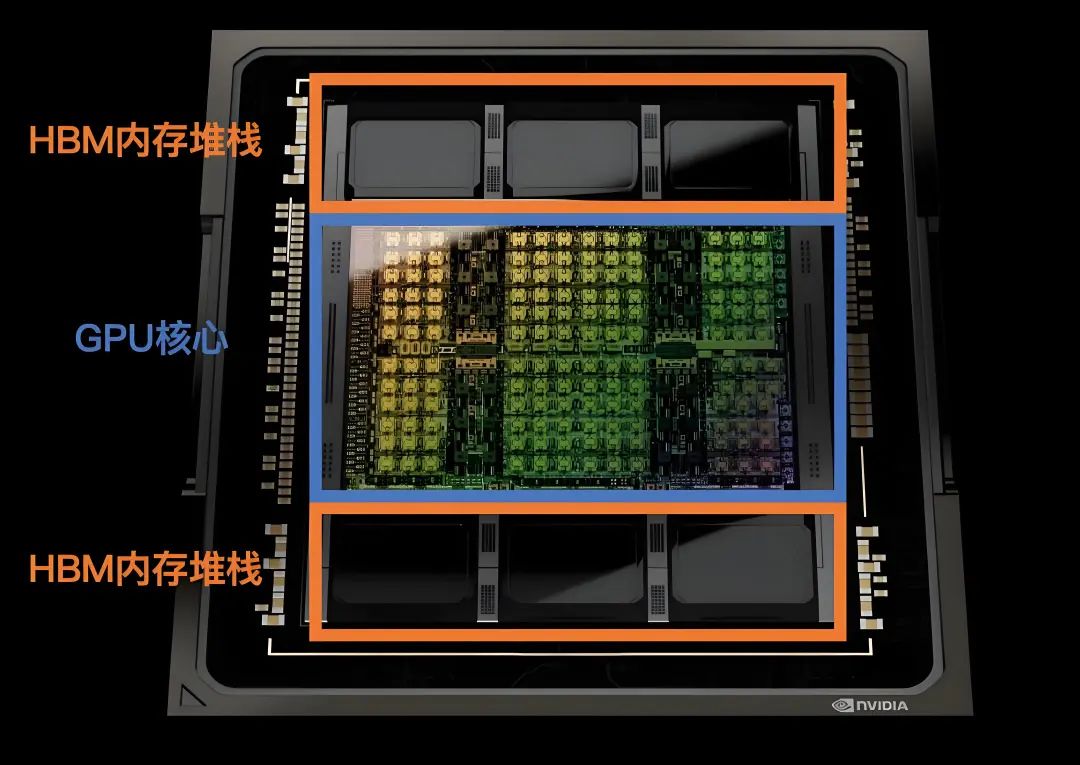
GPU在本质上是一个PCI-E插卡/扣卡,由PCB(Printed Circult Board,印刷电路板)、GPU芯片、GPU内存(即“显存”)及其他附属电路构成。
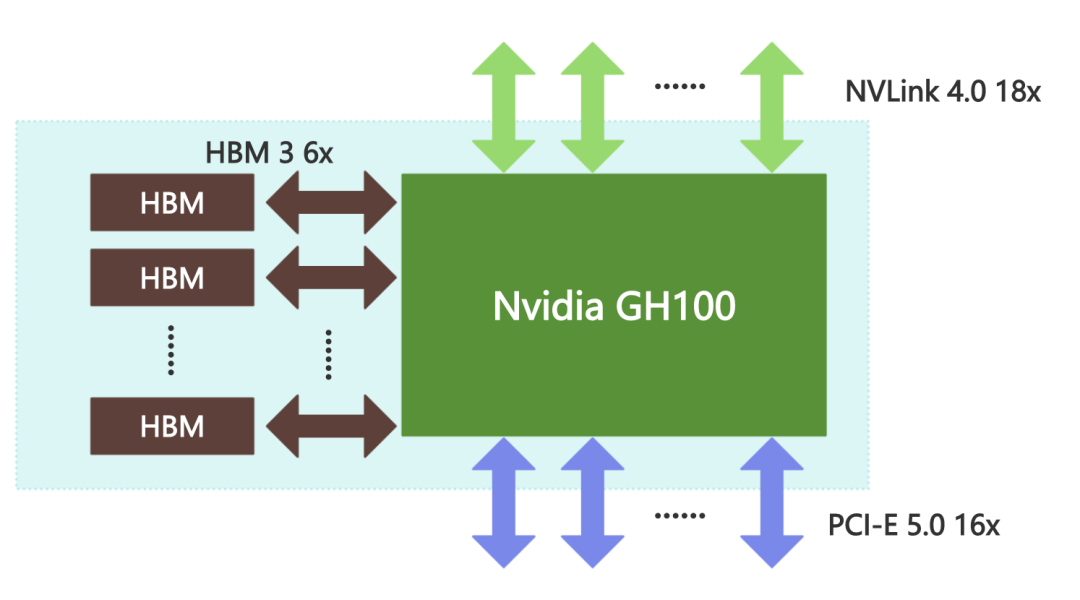
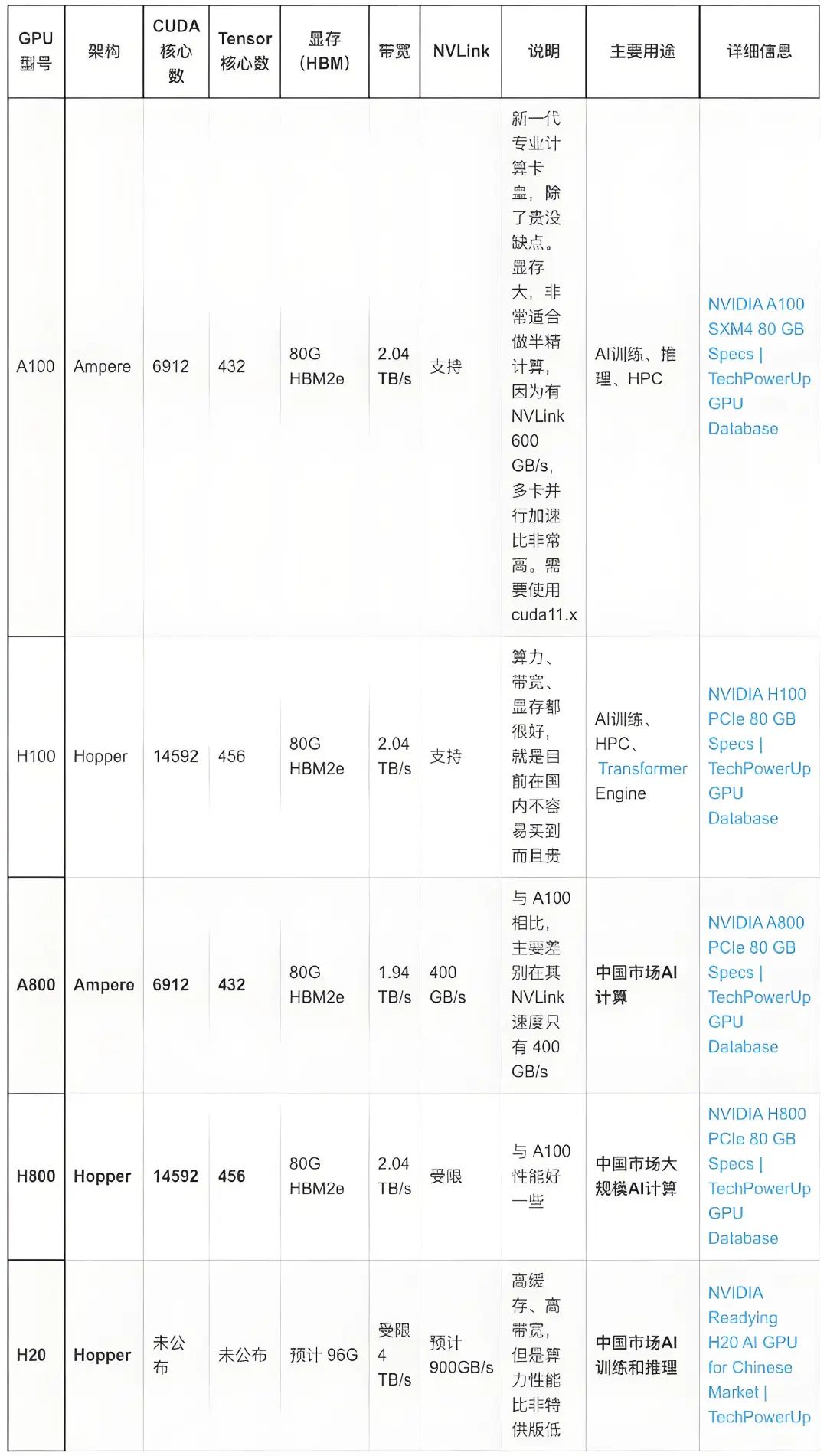
Nvidia H100 GPU的核心芯片是Nvidia GH100,对外的接口有16个PCI-E 5.0通道、18个NVLink 4.0通道和6个HBM 3/HBM 2e通道。
-
在Nvidia H100 GPU卡上,Nvidia GH100 的16个PCI-E 5.0通道用于连接到CPU,实现CPU将程序指令发送到GPU,并为GPU提供访问计算机主存储器的通道,总共可以提供约63GBps的理论传输带宽。
-
与Nvidia GH100 配套的显存是HBM(High Bandwidth Memory,高带宽内存)。HBM是由三星、AMD和SK Hynix等芯片厂商在2013年提出的一种在DDR内存的基础上进一步提升内存性能的内存接口标准,仍然采用DDR内存的时序标准。与DDR内存不同,HBM充分利用了内存芯片封装内部的立体空间,在内存芯片中将多层存储电路堆叠起来,以实现在较小的平面面积上获得极高的内存容量和带宽。Nvidia GH100 芯片支持6个HBM Stack,每个HBM Stack都可以提供800GBps的传输带宽,总内存带宽可达到4.8TBps。
-
Nvidia GH100 还提供了18个NVLink 4.0通道,共提供900GBps的理论传输带宽,可以直接连接到其他GPU,或通过NVLink Switch连接多个GPU,实现GPU之间的互访,让一个GPU可以在CPU无感知的情况下访问另一个GPU的内存,而无需绕行PCI-E总线。
在Nvidia H100 GPU卡上,PCI-E 5.0通道和NVLink通道是连接到GPU卡外部的,而HBM通道在PCB内部连接到PCB上的HBM芯片,不延伸到卡外部。另外,Nvidia提供了不带NVLink的精简版本Nvidia H100 GPU卡,这样Nvidia GH100芯片上的NVLink接口也就闲置了,在其他规格上也有一定的精简。同时,Nvidia考虑到其他因素,为特定的国家和地区提供了进一步精简规格的GPU,比如Nvidia H800等。
SM 流式多处理器
下图是Nvidia GH100芯片的内部架构图,在Nvidia GH100芯片中,除了NVLink接口、PCI-E接口和HBM接口,真正的核心部件就是SM(Streaming Multiprocessor,流式多处理器)。
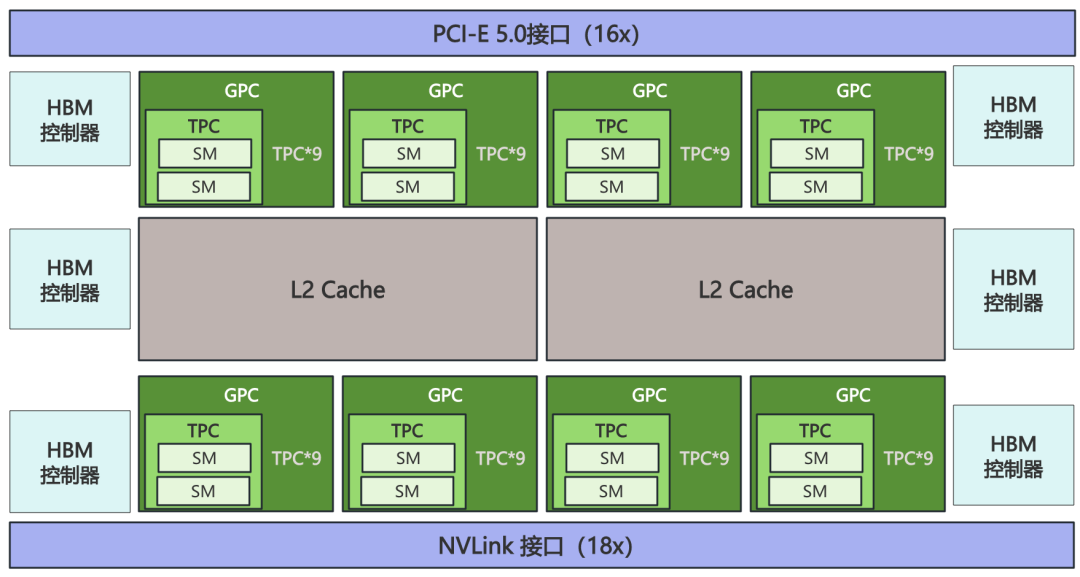
整个Nvidia GH100 芯片有8个GPC(CPU Processing Cluster,GPU处理集群),每4个GPC都共有30MB的L2 Cache(二级缓存),每个GPC都有9个TPC(Texture Processing Cluster,纹理处理集群),在每个TPC内都有2个SM。也就是说,整颗Nvidia GH100 芯片集成了144个SM。
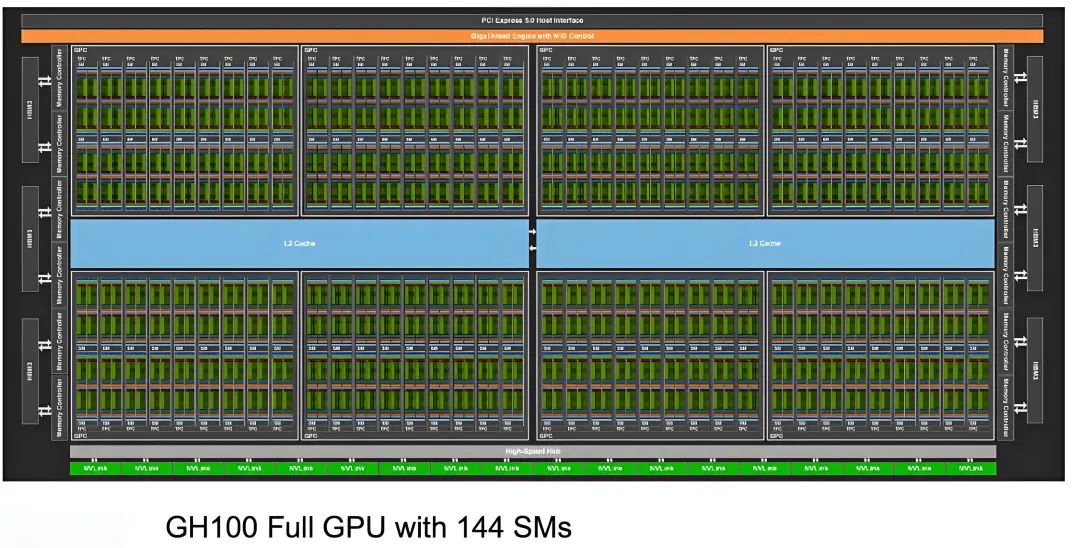
SM内部结构如下图所示。在每个SM内部都有256KB的L1 Data Cache(一级数据缓存),被所有计算单元共享,同时,在SM内部还有4个纹处理单元Tex。SM的计算核心部件是Tensor Core和CUDA Core(下图中一个INT32单元、2个FP32单元和1个FP64计算单元组成)。除此之外,还有L0 Instruction Cache(一级指令缓存)等部件。
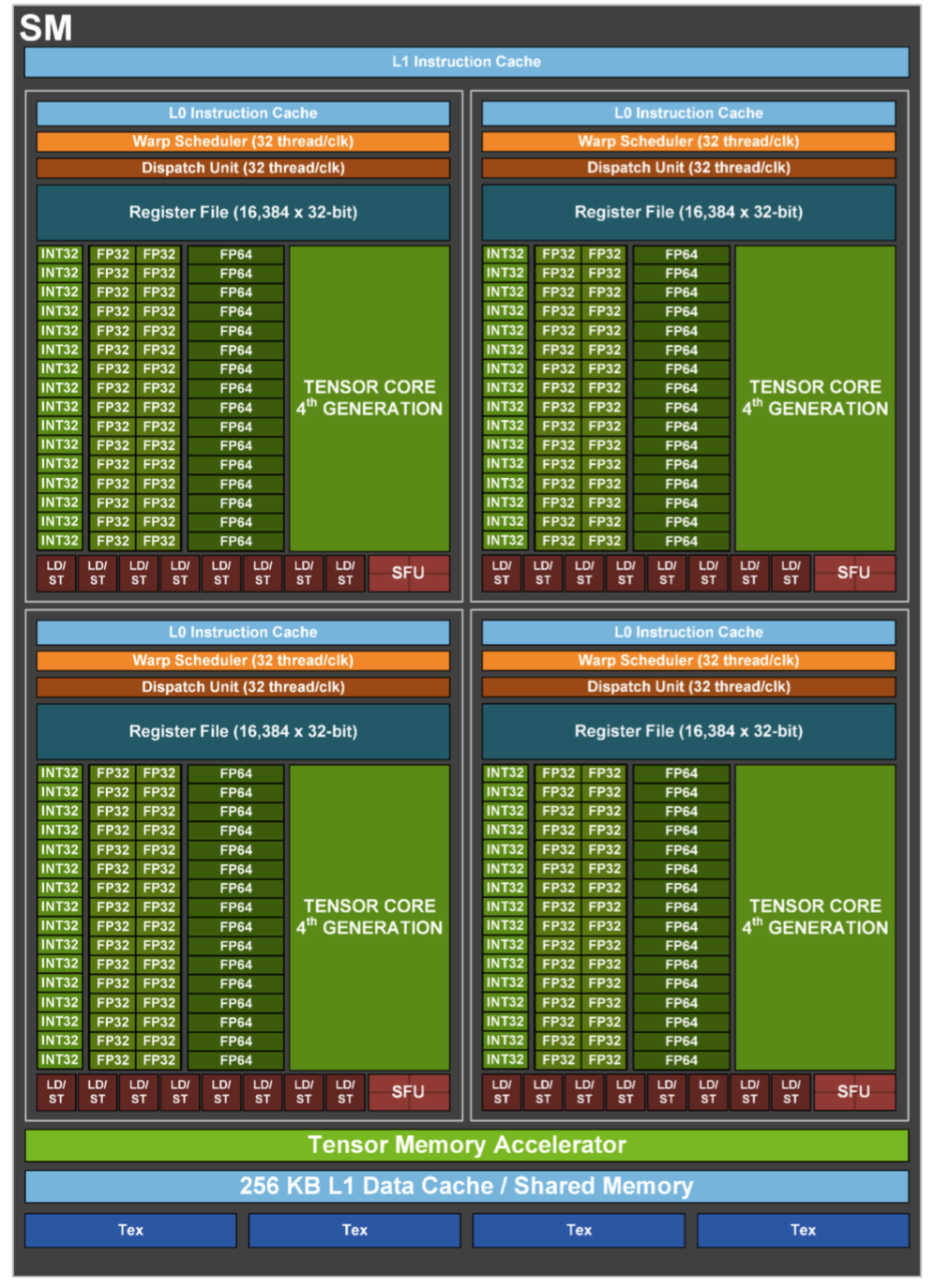
在Hopper架构中,每个SM都有4个象限,每个象限都包含1个Tensor Core和32个CUDA Core,总计4个Tensor Core和128个CUDA Core。整颗芯片可用的CUDA Core数量为144 X 128 = 18432个,可用的Tensor Core 数量为144 X 4 = 576个。
内存加速器
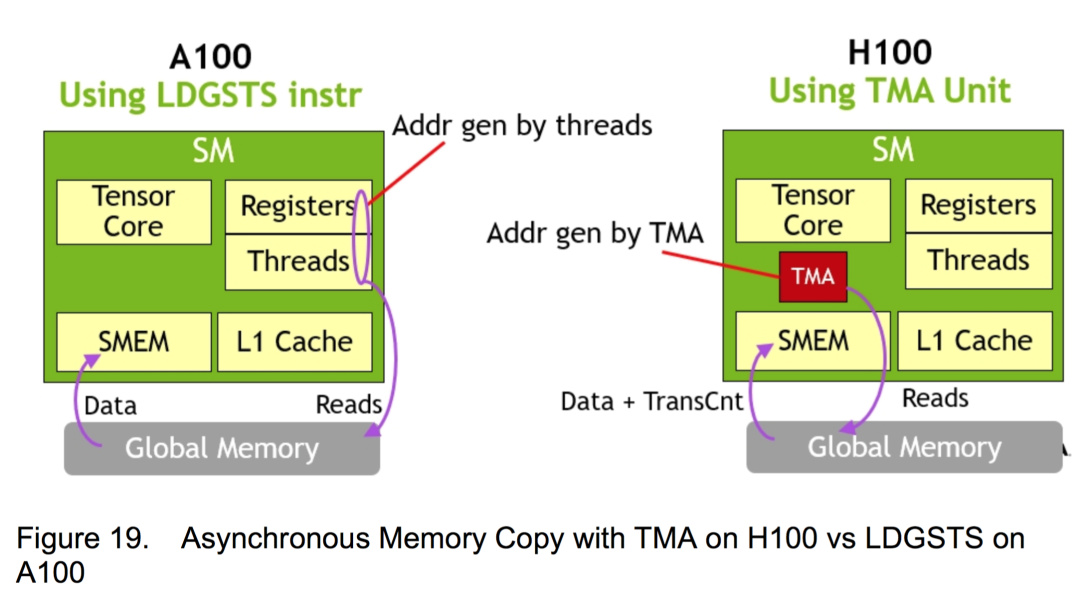
为了提升Tensor Core的内存存取速度,Nvidia在Hopper架构中引入了TMA(Tensor Memory Accelerator,张量存储加速器),以提高Tensor Core读写内存的交换效率。TMA可以让Tensor Core使用张量维度和块坐标指定数据传输,而不是简单地按数据地址直接寻址,这在矩阵分割等场景中能进一步提升寻址效率。例如,在Nvidia A100上,线程本身需要生成矩阵的子矩阵中各行数据所在的地址,并执行所有数据复制操作。但在基于Hopper架构的Nvidia H100中,TMA可以自动生成矩阵中各行的地址序列,接管数据复制任务,将线程解放出来做真正有价值的计算任务。TMA加速的工作原理如下图。
数据局部性考量
在GPU这种超大规模的并行计算机中,对数据局部性的考量变得尤为重要,对于GPU而言,就是要将数据尽量放在靠近计算单元的位置,这样能够让计算单元尽可能发挥缓存的低延迟和高带宽优势。如果想充分利用时间局部性和空间局部性提升计算机的性能,就首先要充分理解计算单元和缓存。
-
在Hopper架构下,访问速度最快的是SM中每个象限的1KB Register File。
-
访问速度次之的是每个象限的1块L0指令缓存,被32个CUDA Core和1个Tensor Core共用。
-
访问速度更慢一些的,是每个SM中的256KB L1 Data Cache,由所有CUDA Core和Tensor Core共用。
-
比L1 Data Cache更慢的是在整颗芯片中集成的60MB的L2 Cache,由2个BANK 组成,最慢的是Nvidia GH100 芯片外部的HBM3显存。
在划分工作负载时,也需要充分考虑这几个阈值,在避免发生缓存冲突的同时,将系统性能发挥到最大。
异步计算
除了基于缓存的优化外,并行计算在异步计算方面也进行了优化。异步计算就是尽量杜绝任务的互锁或序列化操作,充分利用所有计算单元,避免计算单元等待和阻塞。Hopper架构提供了SM之间共享内存的交换网络,每个线程块都可以将自身的内存共享出来,是的其他线程块的CUDA Core和Tensor Core能够直接通过load/store/atomic等操作访问。
Hopper架构还继承和改进了Amper架构的一个重要特性:MIG(Multi-Intance CPU),支持GPU的硬件虚拟化。在MIG的加持下,可以将GPU划分为多个彼此隔离的GPU实例给不同的用户使用,每个GPU实例都拥有自己独立的SM和显存,如下图所示。
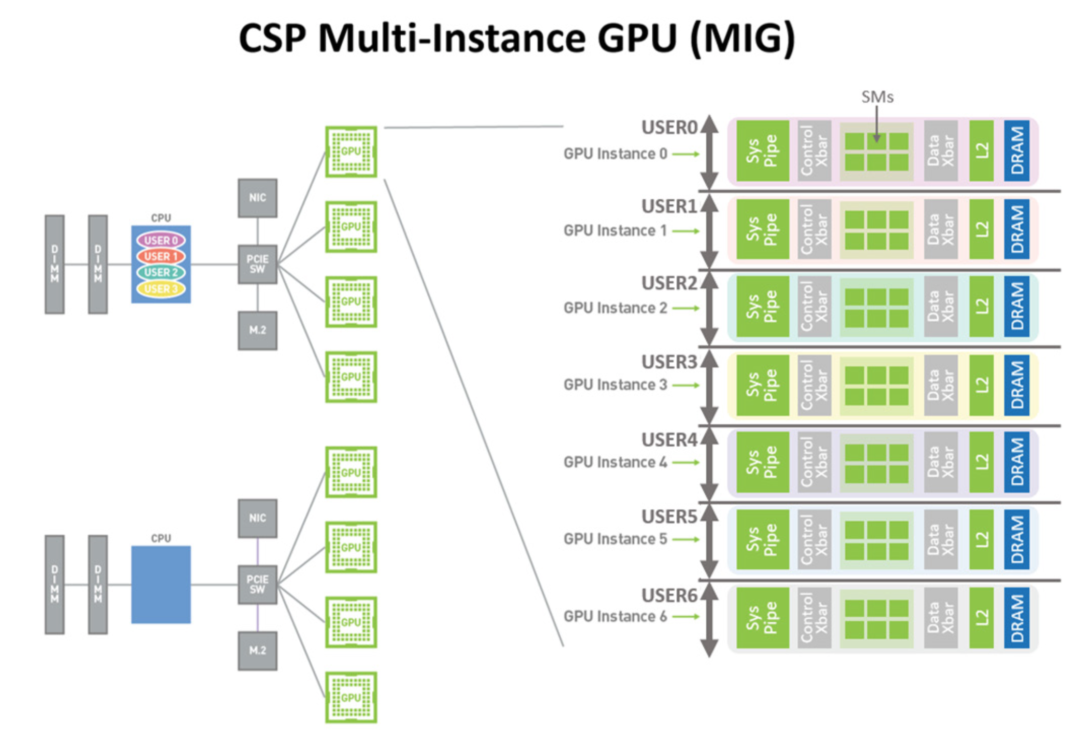
在Hopper架构中对MIG进行了安全方面的增强,能够支持可信计算,还增加了对MIG虚拟化实例监控能力,从而更适应多租户的云服务场景。
IO框架
分布式计算机系统,I/O设计往往也是影响系统性能的重要因素。典型的分布式I/O设计有虚拟化系统中常用的VirtIO,高性能计算中常用的HPFS,以及大数据平台依托的HDFS。在常规的分布式训练模式中,会涉及以下问题:
-
CPU对其他节点上的GPU下发GPU指令
-
GPU和GPU之间的交互,比如交换彼此计算出的权重、取值等。
-
GPU与本地存储设备的交互,比如读取模型和样本。
-
GPU与远端存储设备的交互,比如读取其他节点上的模型和样本。
对于这些问题,Nvidia给出的解决方案是让GPU使用尽量短的路径实现直通,也就是GPU Direct。对此Nvidia提供了对应的I/O设计框架:Magnum IO,如下所示。
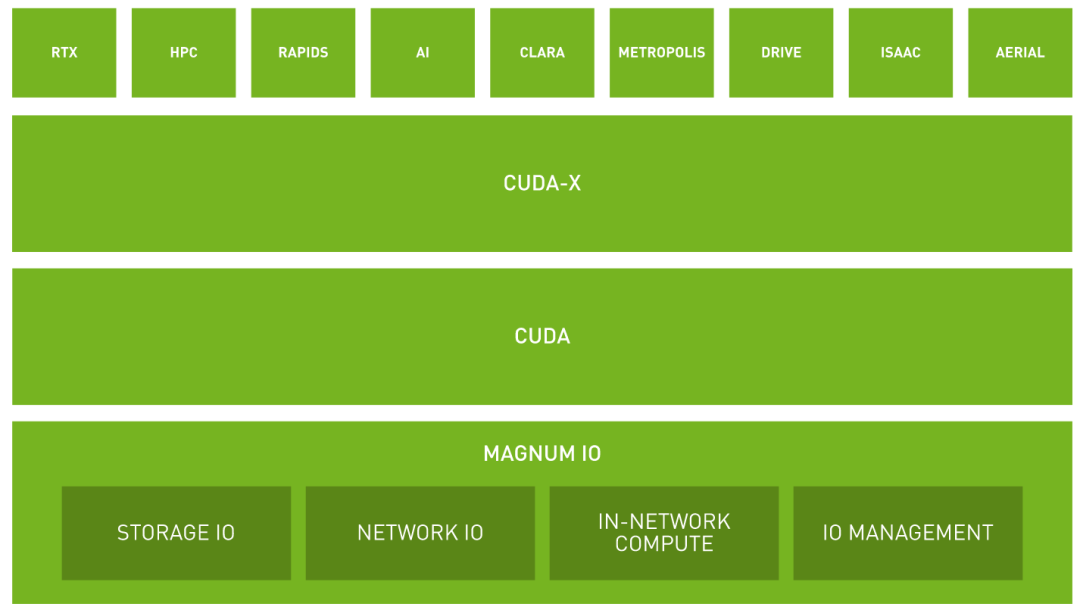
Magnum IO四大核心组件:Storage IO、Network IO、In-Network Compute和IO Management。这几大组件都是GPU Direct的一部分,或者是支撑GPU Direct运行的保障体系。GPU Direct是Nvidia开发的一种技术,可实现GPU与其他设备(例如主机内存、其他GPU、网络接口卡NIC或存储设备)之间的直接通信和数据传输,而不涉及CPU。
往期推荐
一文解读DeepSeek在保险业的应用-CSDN博客
一文解读DeepSeek在银行业的应用_deepseek在银行的应用-CSDN博客
一文解读DeepSeek大模型在政府工作中具体的场景应用_大模型会议纪要场景-CSDN博客
一文解读DeepSeek大模型在政务服务领域的应用-CSDN博客
一文解读DeepSeek在工业制造领域的应用-CSDN博客
一文解读DeepSeek的安全风险、挑战与应对策略_deepseek的发展带来的风险与挑战-CSDN博客