【TF-BERT】基于张量的融合BERT多模态情感分析
不足:1. 传统跨模态transformer只能处理2种模态,所以现有方法需要分阶段融合3模态,引发信息丢失。2. 直接拼接多模态特征到BERT中,缺乏动态互补机制,无法有效整合非文本模态信息
改进方法:1. 基于张量的跨模态transformer模块,允许同时处理3个模态的交互,打破了2模态限制。2. 将TCF模块插入BERT的Transformer层,逐步融合多模态信息,即在Bert微调时动态补充非文本模态信息,避免简单拼接导致的语义干扰
abstract
(背景与问题)由于单模态情感识别在复杂的现实应用中的局限性,多模态情感分析(MSA)得到了极大的关注。传统方法通常集中于使用Transformer进行融合。然而,这些传统的方法往往达不到,因为Transformer只能同时处理两种模态,导致信息交换不足和情感数据的潜在丢失。(方法提出)针对传统跨模态Transformer模型一次只能处理两种模态的局限性,提出了一种基于张量的融合BERT模型(TF-BERT)。TF-BERT的核心是基于张量的跨模态融合(TCF)模块,该模块无缝集成到预训练的BERT语言模型中。通过将TCF模块嵌入到BERT的Transformer的多个层中,我们逐步实现了不同模态之间的动态互补。此外,我们设计了基于张量的跨模态Transformer(TCT)模块,该模块引入了一种基于张量的Transformer机制,能够同时处理三种不同的模态。这允许目标模态和其他两个源模态之间进行全面的信息交换,从而加强目标模态的表示。TCT克服了现有Crossmodal Transformer结构只能处理两个模态之间关系的局限性。(实验结果)此外,为了验证TF-BERT的有效性,我们在CMU-MOSI和CMU-MOSEI数据集上进行了广泛的实验。TF-BERT不仅在大多数指标上取得了最佳结果,而且还通过消融研究证明了其两个模块的有效性。研究结果表明,TFBERT有效地解决了以前的模型的局限性,逐步整合,并同时捕捉复杂的情感互动在所有形式。
intro
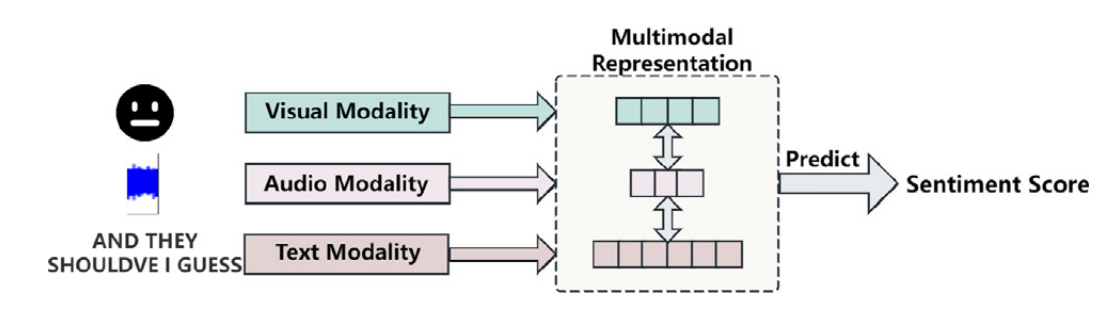
(研究背景,强调单一模态的不足,引出多模态情感分析的必要性)随着AI技术的进步和应用场景的拓展,单一模态的情感分析已不足以满足情感识别复杂多样的需求(Das & Singh,2023; Gandhi et al.,2023年)的报告。例如,仅仅依靠文本分析可能无法准确地捕捉说话者的情绪,因为语调和面部表情也起着至关重要的作用。这种情况催生了多模态情感分析(MSA)的出现,其目的是通过整合多个数据源,实现更准确、更全面的情感识别,如图1所示。例如,在智能客户服务系统中,结合文本、语音和面部表情可以更准确地评估用户的情绪。如果系统检测到用户语气中的不满意,它可以迅速调整其响应策略以提供更快或更详细的帮助。
(现有方法的缺陷)Zadeh等人(2017)的早期工作引入了一种基于张量的融合方法,计算3重笛卡尔空间以捕获模态之间的关系。近年来,随着深度学习的快速发展,研究者们不断创新融合策略,以更好地平衡不同模态之间的情感信息。Wang等人(2019)使用门控机制将音频和视频(非文本)模态转换为与文本模态相关的偏见,然后将其与文本融合。Mai等人(2021年)设计了声学和视觉LSTM来增强文本表征。Tsai等人(2019)将Transformer(Vaswani,2017)引入MSA领域,设计了用于融合不同模态的跨模态变压器。此后,交叉模态变换器得到了广泛的应用,Zhang等人(2022)利用它们来模拟人类感知系统,Huang等人(2023)利用它们来围绕文本进行融合。然而,尽管它们是有效的,但是这些跨模态变换器有一个局限性:它们的自注意结构一次只能接受两个模态作为输入,一个作为查询,另一个作为关键字和值,考虑到每次迭代只有两个模态之间的交互(Lv等人,2021年)的报告。由于多模态任务通常涉及两个以上的模态,所以当处理多模态时,这种结构限制要求交互被分阶段或分步骤地建模。这种限制可能导致信息丢失或不完整的交互,无法充分利用所有模态之间的潜在关系,从而影响情绪预测(Sun、Chen和Lin,2022)。此外,虽然Rahman等人(2020)、Zhao、Chen、Chen等人(2022)使用了预训练的来自变换器的双向编码器表示(BERT)模型(Devlin等人,2018),他们的方法只是将非文本模态与文本模态一起集成到BERT的Transformer层中,导致整个模型中多模态情感信息的集成不足。
(解决方案)针对传统的多模态Transformer无法同时处理多模态信息以及BERT中单层嵌入导致的多模态信息融合不足的问题,提出了一种基于张量的融合BERT(TFBERT)。该模型的核心组件是基于张量的跨模态融合(TCF)模块,该模块可以集成到预先训练的BERT语言模型的Transformer架构中。这允许用非文本模态表示来逐渐补充文本模态表示。具体地说,我们的框架能够在保持BERT核心结构的同时进行微调,从某个点开始将TCF嵌入每个Transformer层。TCF模块中的基于张量的跨模态Transformer(TCT)允许BERT在学习文本表示的同时嵌入非文本情感信息,逐步增强文本模态表示以充分整合多模态情感信息。TCT引入了一种基于张量的方法,在跨模态Transformer融合之前,在目标模态和两个其他源模态之间建立交互。TCT允许所有模态同时交换相关信息,补充和增强目标模态的情感信息。
最后,在CMU-MOSI和CMU-MOSEI两个数据集上测试了TF-BERT模型的性能,并通过情感预测任务对TF-BERT模型的性能进行了评估.仿真实验结果表明,TF-BERT算法优于已有的多度量方法.此外,消融研究进一步确认了TF-BERT中相应模块的有效性。
(1)提出了TF-BERT并设计了TCT模块,克服了传统的跨模态变换器一次只能处理两种模态的局限性。TCT模块使跨模态Transformer能够同时处理多个模态,促进目标模态与其他模态之间的全面信息交换。这种增强显著地改善了目标模态的情感特征表示。
(2)我们设计了TCF模块,它可以集成到预训练的BERT语言模型的Transformer架构中。通过在每个Transformer层中嵌入TCF模块,逐步实现了文本模态和非文本模态的互补,增强了多模态情感信息的融合和表达能力。
(3)实验结果表明:所提出的图像修复算法性能优于多种现有算法.
本文的其余部分组织如下:第二节回顾了有关单峰和MSA的工作。第3节详细描述了我们提出的方法,包括TF-BERT模型的总体架构以及TCF和TCT模块的设计。第4节讨论了在两个不同数据集上进行的实验细节。第五部分给出了实验结果沿着进行了深入的分析。最后,第六章对全文进行了总结和展望。
related works
multimodal sentiment analysis
结构框架:从单模态到多模态,按技术迭代的步伐递进
- 单模态情感分析:
- 肯定成就:引用近期文献(Darwich et al., 2020; Hamed et al., 2023)说明单模态方法的应用价值。
- 批判局限性:指出其无法捕捉情感复杂性(Geetha et al., 2024),引出多模态融合的必要性。
- 多模态融合早期方法:
- 经典模型:Zadeh等(2017)的张量融合网络(计算复杂度高)。
- 改进方向:Sun等(2022)的CubeMLP(降低复杂度)、Miao等(2024)的低秩张量融合(增强信息捕获)。
- 深度学习时代:
- RNN/LSTM局限:序列处理瓶颈(Hou et al., 2024)与长程依赖问题。
- Transformer崛起:并行处理优势(Xiao et al., 2023)及在MSA中的应用(MULT、MISA、Self-MM等)。
- 现有Transformer方法的不足:
- 两模态交互限制:Tsai等(2019)、Wang等(2023)仅支持双模态交互,导致信息不完整。
- BERT融合不足:现有工作(Rahman et al., 2020; Zhao et al., 2022)仅单层嵌入非文本模态,未能充分整合多模态信息。
- 本文解决方案:
- 提出TCT模块:同时处理三模态交互,克服两模态限制。
- TCF模块嵌入BERT:逐层渐进融合,增强多模态表征。
单模态情感分析侧重于从单一模态(如文本、音频或视频)中提取情感信息。这些年来,该领域已经取得了实质性的进步,并且已经在各种实际情况下得到了广泛的应用(Darwich等人,2020年; Hamed等人,2023年; Sukawai和Omar,2020年; Wang等人,2022年)的报告。然而,尽管取得了这些成就,但依赖单一模态往往无法捕捉到人类情感的全部复杂性和多维性(Geetha等人,2024年)的报告。单模态方法在表现情感丰富性和多样性方面的局限性(Hazmoune和Bougamouza,2024; Lian等人,2023年)促使研究人员探索多模态融合。这导致了MSA的出现,与单峰方法相比,MSA提供了具有改进的准确性、鲁棒性和泛化性的增强的情感识别。在MSA中,来自不同模态(如文本、音频和视频)的数据被集成到一个模型中,以更全面地捕获情感特征。随着深度学习技术的发展,MSA已经成为一个重要的研究热点。
最初,Zadeh等人(2017年)提出了张量融合网络,该网络需要计算三重笛卡尔积,导致计算复杂度较高。Sun,Wang,et al.(2022)介绍了CubeMLP,它通过在三个MLP单元中使用仿射变换来降低张量融合网络的计算复杂度。Miao等人(2024)通过将低秩张量融合与Mish激活函数相结合来捕获模态之间的相互作用,从而增强了MSA模型的信息捕获能力。随着深度学习的发展,研究人员开始探索在神经网络中整合多模态信息的更有效方法。传统的深度学习方法依赖于RNN和LSTM网络来处理来自不同模态的信息。Mai等人(2021)开发了声学和视觉LSTM,以建立声学和视觉增强的模态相互作用。Huddar等人(2021)提出使用基于注意力的双向LSTM从话语中提取关键的上下文信息。然而,由于LSTM的序列性质,这些模型难以并行处理序列数据,增加了计算复杂性(Hou、Saad和Omar,2024)。此外,长序列输入可能会导致信息丢失,从而限制模型探索长期依赖关系的能力。
为了解决这些问题,近年来Transformer模型已逐渐引入MSA领域(Sun等人,2023; Wang等人,2024年; Zong等人,2023年)的报告。Transformer建立在多头注意力机制的基础上,以其强大的并行处理和全局聚合能力而闻名(Xiao等人,2023),有效地解决了序列内的长期依赖性(Xiao等人,2024年)的报告。Hazarika等人(2020年)提出了MISA模型,该模型在使用Transformer融合特定模态和共享特征之前对其进行分解。为了保留特定模态的信息,Yu等人(2021年)引入了Self-MM,而Hwang和Kim(2023年)提出了SUGRM,两者都使用自我监督来生成用于单模态情感预测任务的多模态标签,然后通过Transformer进行级联和融合。为了更好地捕捉多模态数据之间的错位,Tsai等人(2019)率先提出了MULT,修改了Transformer结构,以捕捉两种不同模态之间的情感信息和长期依赖性。Wang等人(2023)进一步提出了文本增强Transformer融合网络,修改了跨模态Transformer结构,以通过将文本信息集成到非文本模态中进行增强来充分利用文本信息。Huang et al.(2023)介绍了TeFNA,该方法使用跨模态注意力逐渐对齐和融合非文本和文本表征。为了进一步增强每种模态的表示,Hou,Omar,et al.(2024)提出了TCHFN,在跨模态Transformer中使用目标模态作为键和值,使用源模态作为查询。Hu等人(2024)提出了一种基于转换器的多模态增强网络,该网络通过融合共享信息周围的模态、结合自适应对比学习和多任务学习来增强性能,从而改善MSA。
尽管这些基于transformer的跨模态方法的性能有了显著的改进,但它们的能力受到限制,一次只能处理两个相应的模态。这种约束阻碍了模型同时捕获多个模态之间复杂交互的能力,导致信息集成不足,处理复杂性增加,以及潜在的信息不一致,最终影响全局情感表示的准确性。为了克服这些限制,Lv等人(2021)引入了渐进式模态强化模型,该模型包含一个消息模块来存储多模态信息,增强了每种模态,同时允许在所有模态之间进行同时交互。然而,模态交互的消息模块的引入可能导致信息冗余。Sun,Chen和Lin(2022)调整了Transformer框架,以便在每个融合过程中同时捕获所有模态的互补信息。然而,这种方法导致相对较高的空间复杂度。Huang等人(2024)提出了一种模态绑定学习框架,该框架将细粒度卷积模块集成到Transformer架构中,以促进三种模态之间的有效交互。尽管其有效性,融合过程仍然相对复杂。为了应对这些挑战,我们设计了TCT,以同时建立所有模式之间的互动。在通过TCT增强每种模式之后,它构成了TCF的基础。此外,由于预训练的语言模型BERT在多个下游任务中表现出出色的性能,并具有强大的迁移学习能力,因此可以对其进行微调以适应MSA任务,从而显着提高模型性能,同时节省训练资源,并能够构建更简单,更高效的融合网络。Kim和Park(2023)提出了All-Modalities-in-One BERT模型,该模型通过两个多模态预训练任务使BERT适应MSA。Rahman等人(2020)提出了MAG-BERT,它通过多模态适应门将非文本模态集成到文本模态中。Zhao,Chen,Liu和Tang(2022)介绍了共享私有记忆网络,它在通过BERT学习文本表示的同时,结合了非文本模态的共享和私有特征。Zhao,Chen,Chen,et al.(2022)还提出了HMAI-BERT,它将记忆网络集成到BERT的主干中,以对齐和融合非文本模态。Wang等人(2022)介绍了CENet,它以自我监督的方式生成非文本词典,并采用转换策略来减少文本和非文本表示之间的分布差异,然后与BERT融合。然而,这些模型仅将非文本模态嵌入到BERT内的单个Transformer层中以与文本模态融合,从而导致整个模型中的多模态信息的集成不足。为了解决这个问题,我们提出了TF-BERT,其目的是将TCF从BERT中的特定层嵌入到每个Transformer层中,逐步增强和融合所有模态表示。
method
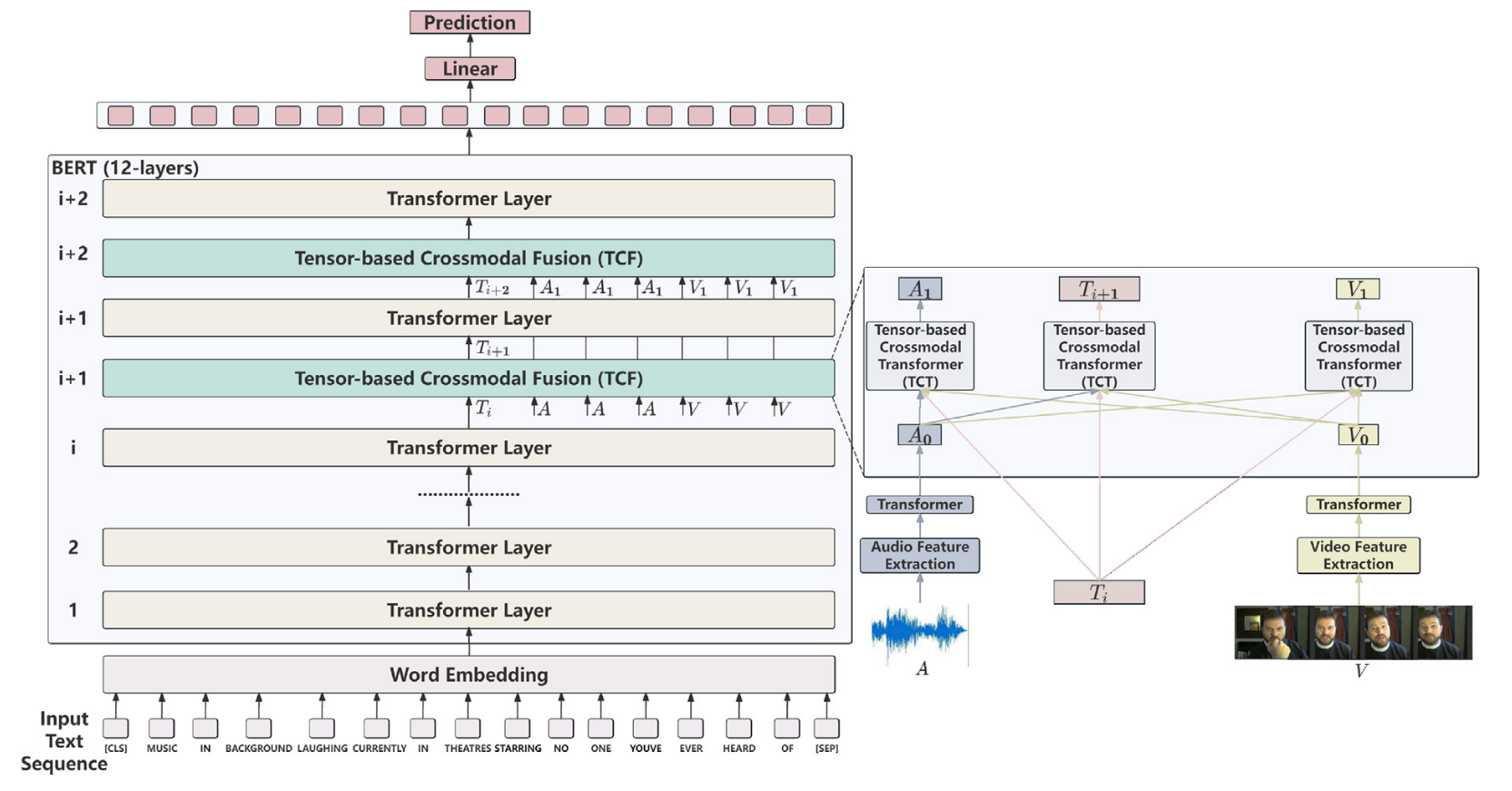
在本节中,我们将详细解释TF-BERT的整体架构及其关键组件,如图2所示。具体来说,第3.1节介绍了任务定义。第3.2节简要概述了整个模型。第3.3节介绍BERT模型。第3.4节描述了TCF模块,第3.5节讨论了TCT模块。
task definition
overall architecture
TF-BERT的结构如图2所示。
-
文本模态处理:
- 文本模态数据通过词嵌入转换为向量形式,输入BERT的Transformer层。
- 这些层捕获文本中不同位置之间的复杂上下文依赖关系。
- 经过前 i 个Transformer层处理后,文本表示在语义上更加丰富。
-
TCF模块嵌入:
- 从第 (i+1) 个Transformer层开始,TCF模块被嵌入BERT中。
- 该模块通过多模态交互增强各模态的表示:
- 第 (i+1) 个Transformer层处理增强后的文本表示。
- 非文本模态(如音频、视觉)的表示经第 (i+1) 个TCF模块增强后,与处理后的文本表示一同输入第 (i+2) 个TCF模块,进行进一步强化。
- 第 (i+2) 个Transformer层将多模态情感信息充分整合到文本表示中。
-
基于张量的跨模态交互:
- TCF模块内使用基于张量的方法,从两个源模态(如音频、视觉)中捕获情感信息。
- 跨模态Transformer利用这些信息增强目标模态(如文本),实现目标模态与两个源模态之间的情感信息交换。
-
输出与预测:
- TF-BERT最终输出的文本表示富含多模态情感信息。
- 通过线性层(Linear)进行情感预测。
基于BERT的多层嵌入
在TF-BERT模型中,BERT起着核心作用。BERT最初由Google开发,是一种专门为自然语言处理任务设计的深度学习模型,需要进行微调以适应多模态任务。BERT包括12个Transformer层,并使用双向训练方法,这意味着它在处理文本时会考虑前后上下文,从而捕获更丰富的语义关系。
BERT首先通过两个主要任务在大规模无监督文本数据上进行预训练:Masked Language Modeling和Next Sentence Prediction。在这个预训练阶段,BERT学习语言表征,包括与情感相关的信息。它非常适合集成到多模态任务中,可以进行微调以有效地融合多模态情感信息。
BERT首先通过两个主要任务进行大规模预训练:掩码语言建模(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。在此预训练阶段,BERT学习语言表示(包括情感相关信息),因此非常适合集成到多模态任务中,通过微调实现多模态情感信息的有效融合。


基于张量的交叉模态Transformer
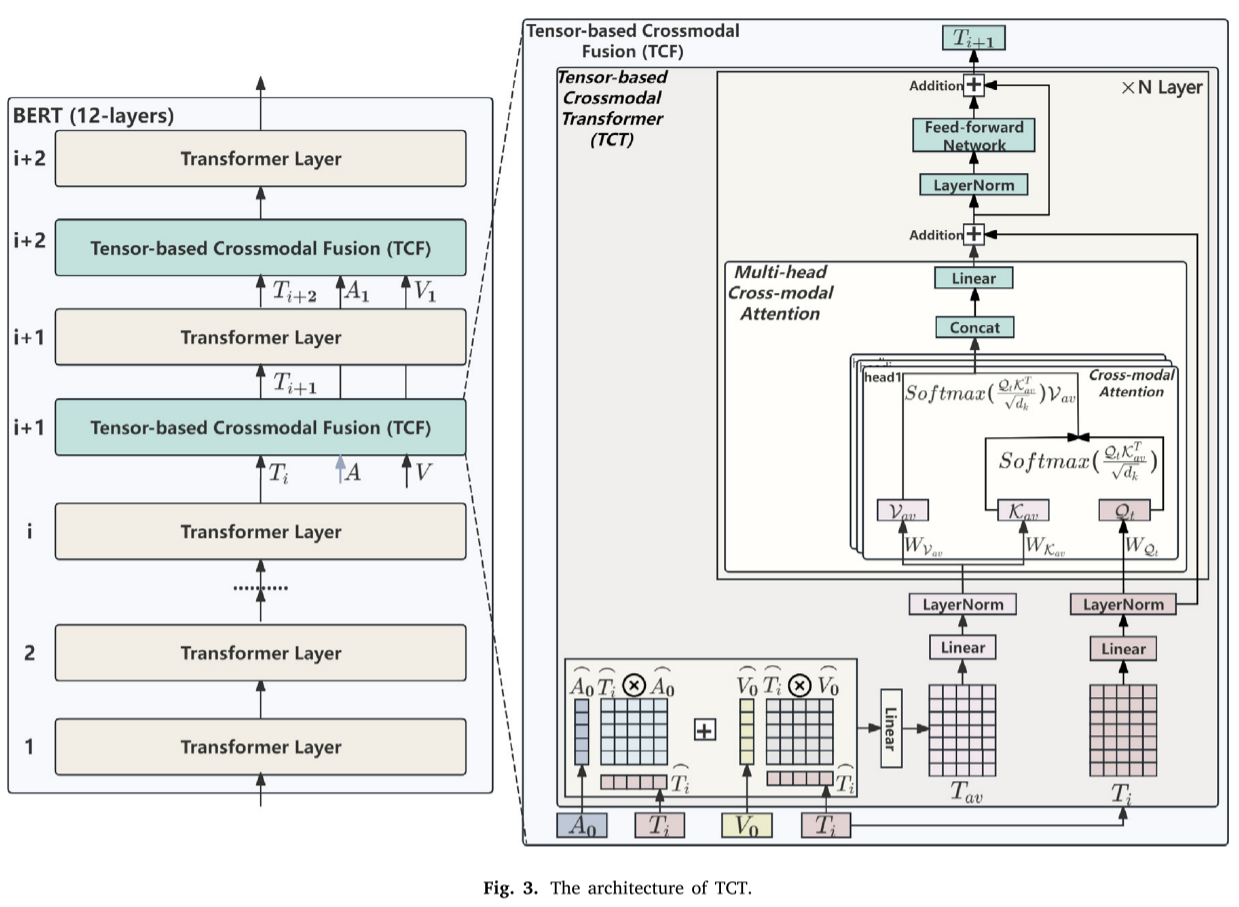
为了在跨模态Transformer中同时考虑来自所有模态的情感信息,我们设计了TCT模块,如图3所示。以文本模态的第(i+1)层TCT模块为例,具体步骤如下:


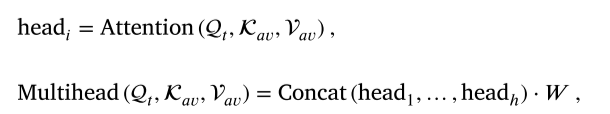
其中,k表示多头交叉模态注意机制中的头的数量,k表示多头交叉模态注意机制的最终线性变换中使用的权重系数。
最后,经过多头跨模态注意机制处理的表征经过LayerNorm层和前馈层,增强文本表征的稳定性,最终得到的结果是LayerNorm+1。
