【聚类分析】基于copula的风光联合场景生成与缩减
目录
1 主要内容
风光出力场景生成方法
2 部分程序
3 程序结果
4 下载链接
1 主要内容
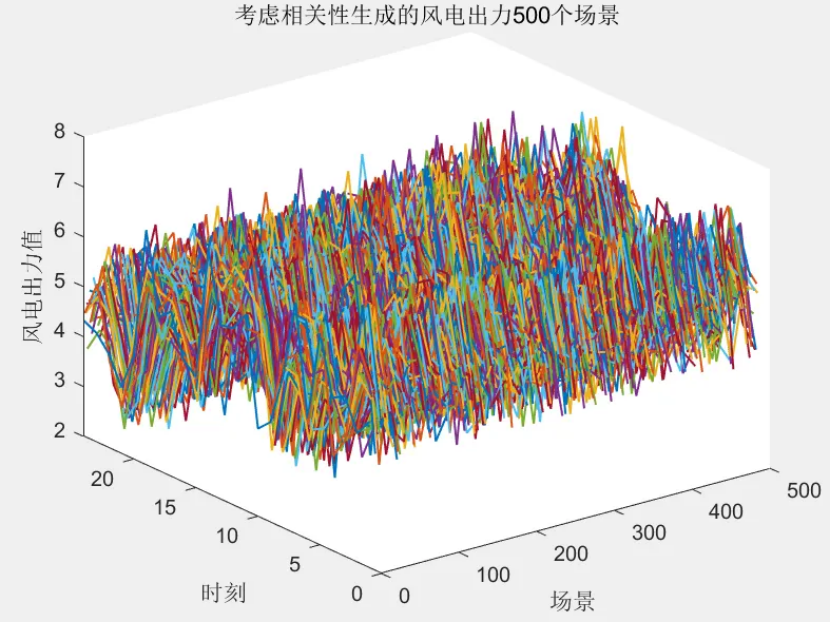
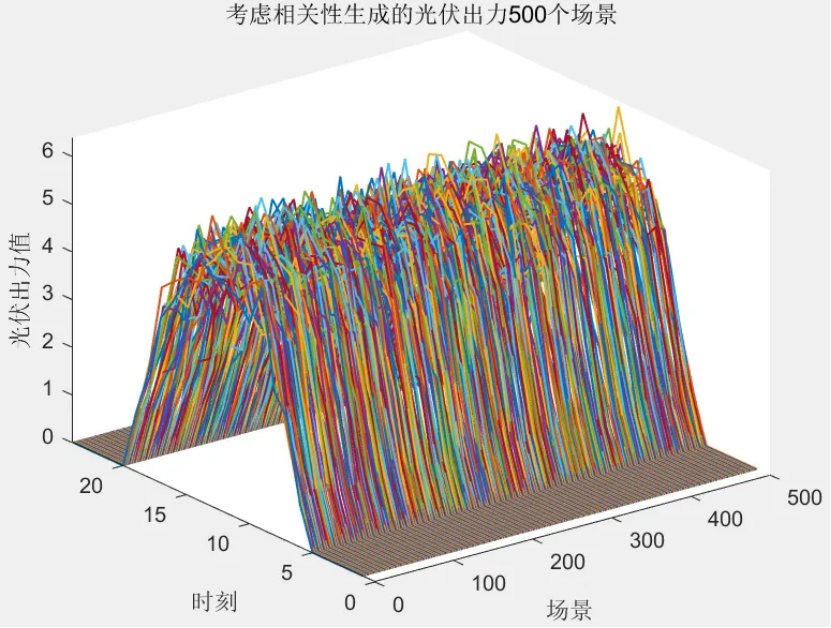
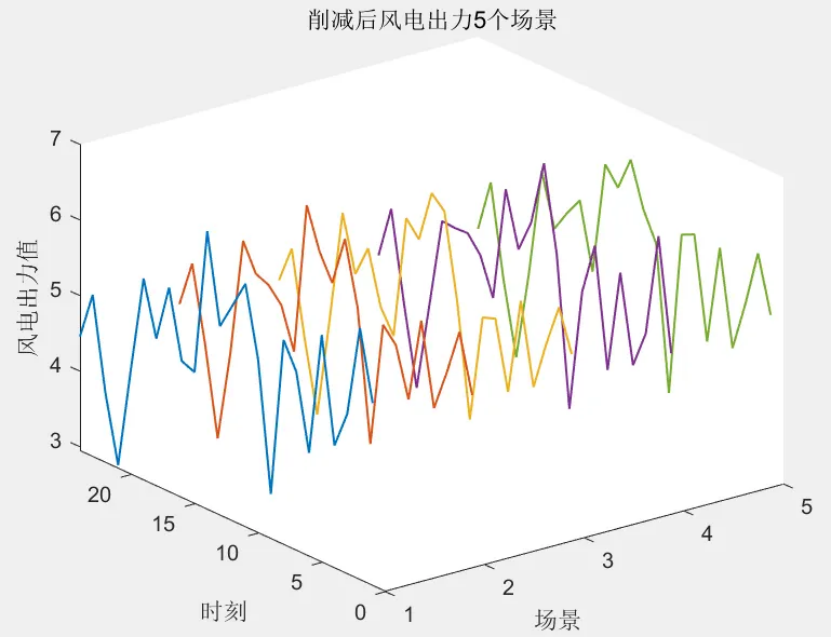
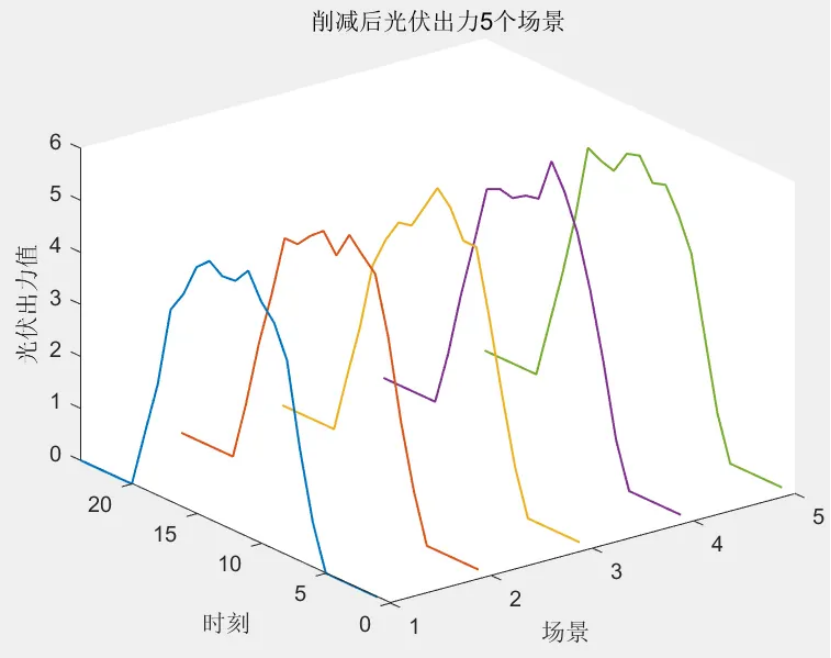
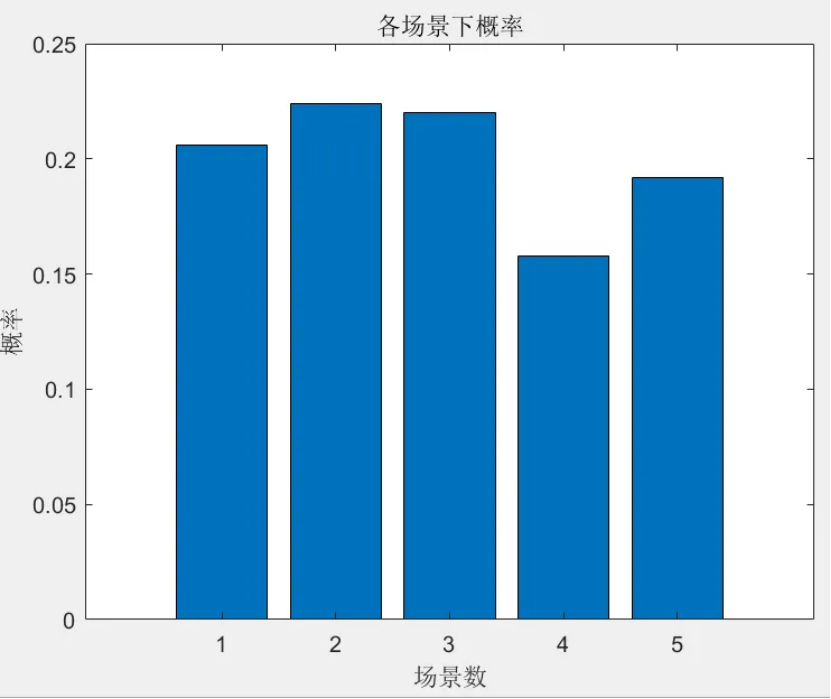
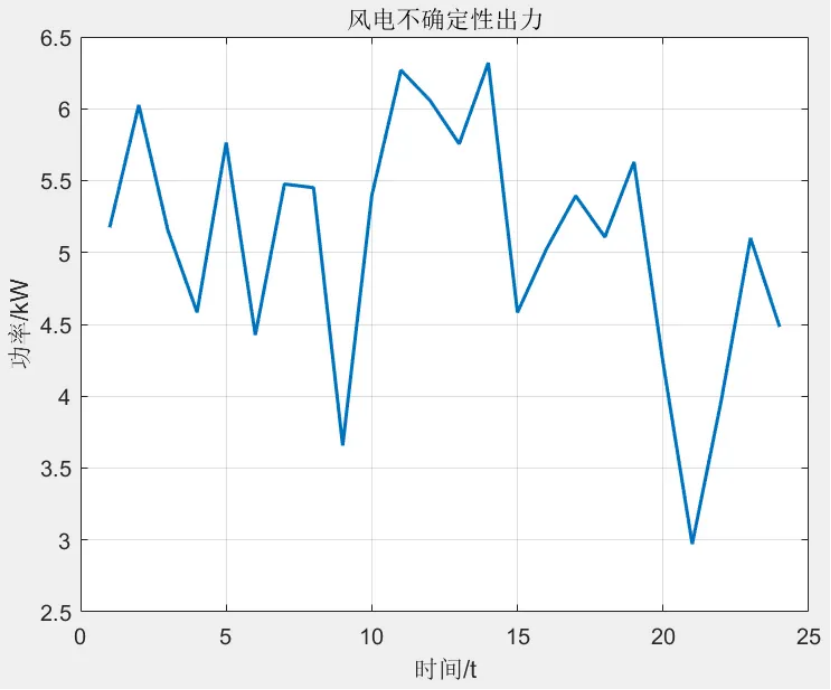
该程序方法复现《融合风光出力场景生成的多能互补微网系统优化配置》风光出力场景生成部分,目前大多数研究的是不计风光出力之间的相关性影响,但是地理位置相近的风电机组和光伏机组具有极大的相关性。因此,采用 Copula 函数作为风电、光伏联合概率分布,生成风、光考虑空间相关性联合出力场景,在此基础上,基于Kmeans算法,分别对风光场景进行聚类,从而实现大规模场景的削减,削减到5个场景,最后得出每个场景的概率与每个对应场景相乘求和得到不确定性出力。

-
风光出力场景生成方法
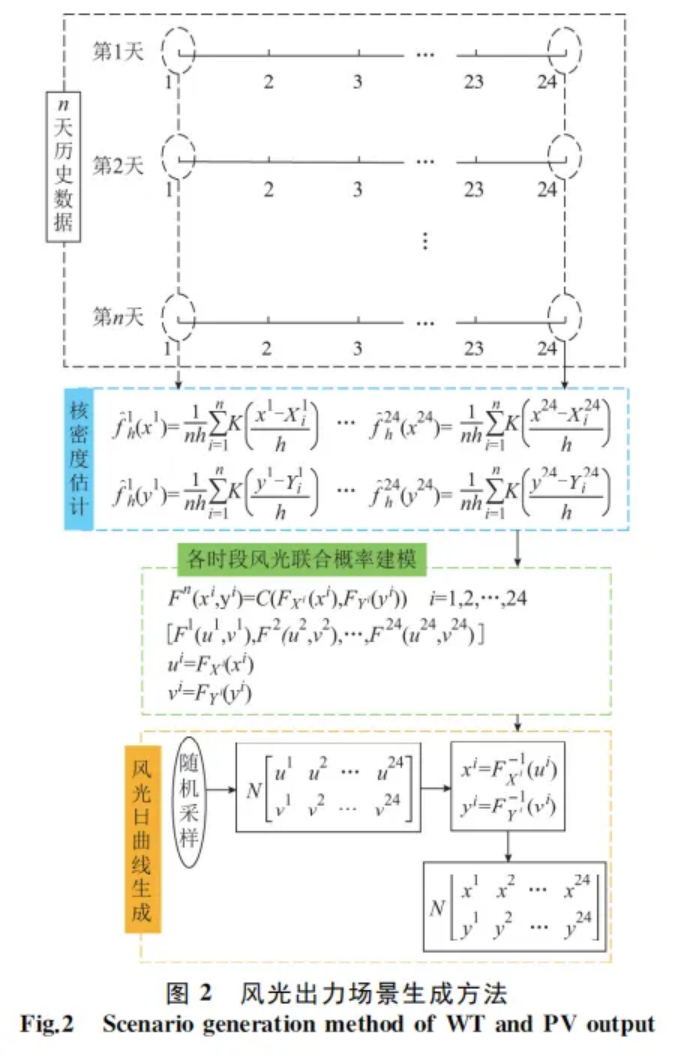
以历史风光出力数据(每小时一个点)为基础(图中x 和y 分别表示单位风机和光伏出力),首先基于核密度估计法选取常用的高斯核函数生成24h内每个时段的风、光出力概率密度函数。然后考虑风光相关性,基于 Copula理论建立每个时段的风光出力联合概率分布函数;对于 Copula函数的选取,由于二元阿基米德 Copula函数中,Gumbel和ClaytonCopula函数只能描述变量间的非负关系,FrankCopula可兼顾变量的非负和负相关关系,而风光常有负相关互补关系,因此本文选取 FrankCopula函数描述风光相关性。最后,对每个时段的联合概率分布函数进行采样,并根据采样结果和风光的联合概率分布函数反变换得到每个时段的采样风机和光伏出力,从而最终生成考虑风光相关性和随机性的典型日曲线。
2 部分程序
% 基于Copula函数的风光功率联合场景生成
% 关键词:Copula;场景生成;风光出力相关性
clear; clc; close all;
%% 导入数据与预处理
solardata = xlsread('数据-光伏.xlsx');
winddata = xlsread('数据-风功率.xlsx');
winddata = winddata(2:end, :);
solardata = solardata(2:end, :);scenarionum = 500; % 初始场景数目,可修改
num_cluster = 5; % 要削减到的场景数目,可修改
ntime = 24; % 24小时% X和Y分别存储风和光的24个时刻历史观测数据
X = []; Y = [];
for t = 1 : ntimeX{t} = winddata(:, t);Y{t} = solardata(:, t);
end%% Copula拟合
% Frank-Copula 函数可以同时考虑变量的非负与负相关的关系
% 故采用 Frank-Copula 函数分别对24个时刻进行拟合for i = 1 : ntimeU = ksdensity(X{i}, 'function', 'cdf'); % 核密度估计V = ksdensity(Y{i}, 'function', 'cdf');alpha = copulafit('frank', [U(:) V(:)]); % 拟合出的参数copulaparams.alpha = alpha;copulaparams.numParams = 1;copModels(i) = copulaparams;
end
%% 绘制二元Frank-Copula的密度函数和分布函数图
[Udata, Vdata] = meshgrid(linspace(0,1,31)); % 为绘图需要,产生新的网格数据
Ccdf_Frank = copulacdf('Frank', [Udata(:), Vdata(:)], copModels(12).alpha);3 程序结果