【LLM】deepseek R1之GRPO训练笔记(持续更新)
note
- 相关框架对比:
- 需微调模型且资源有限 → Unsloth;
- 本地隐私优先的小规模推理 → Ollama;
- 复杂逻辑或多模态任务 → SGLang;
- 高并发生产环境 → vLLM
- 微调SFT和GRPO是确实能学到新知识的
- 四种格式(
messages、sharegpt、alpaca、query-response)在AutoPreprocessor处理下都会转换成ms-swift标准格式中的messages字段,即都可以直接使用--dataset <dataset-path>接入,即可直接使用json数据
文章目录
- note
- 一、Swift框架
- 数据集定义
- 奖励函数
- GRPO公式
- 训练参数
- 二、unsloth框架
- 1. Unsloth框架介绍
- 2. 使用
- 3. 训练参数
- 三、open r1项目
- 数据生成
- 模型训练
- 模型评估
- 四、GRPO经验总结
- 关于DeepseekR1的17个观点
- Reference
一、Swift框架
数据集定义
Coundown Game任务:给定几个数字,进行加减乘除后得到目标数值。
数据量:5w条
[INFO:swift] train_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 49500
})
[INFO:swift] val_dataset: Dataset({features: ['nums', 'messages', 'target'],num_rows: 500
})
通过 template, 使用 numbers 和 target 完成任务定义,并给到 query 字段供模型采样使用。同时,我们需要保留 nums 和 target 两个字段,用于后续的奖励函数计算。
class CoundownTaskPreprocessor(ResponsePreprocessor):def preprocess(self, row: Dict[str, Any]) -> Dict[str, Any]:numbers = row['nums']target = row.pop('response', None)query = f"""Using the numbers {numbers}, create an equation that equals {target}.You can use basic arithmetic operations (+, -, *, /) and each number can only be used once.Show your work in <think> </think> tags. And return the final equation and answer in <answer> </answer> tags,for example <answer> (1 + 2) / 3 * 4 = 4 </answer>."""row.update({'target': target, 'query': query})return super().preprocess(row)register_dataset(DatasetMeta(ms_dataset_id='zouxuhong/Countdown-Tasks-3to4',subsets=['default'],preprocess_func=CoundownTaskPreprocessor(),tags=['math']))
奖励函数
- 格式奖励函数:Deepseek-R1 中提到的格式奖励函数,已经在swift中内置,通过 --reward_funcs format 可以直接使用
- 准确性奖励函数:使用 external_plugin 的方式定义准确性奖励函数,将代码放在
swift/examples/train/grpo/plugin/plugin.py中。- 奖励函数的输入包括 completions、target 和 nums 三个字段,分别表示模型生成的文本、目标答案和可用的数字。
- 每个都是list,支持多个 completion 同时计算。注意这里除了 completions 之外的参数都是数据集中定义的字段透传而来,如果有任务上的变动,可以分别对数据集和奖励函数做对应的改变即可。
class CountdownORM(ORM):def __call__(self, completions, target, nums, **kwargs) -> List[float]:"""Evaluates completions based on Mathematical correctness of the answerArgs:completions (list[str]): Generated outputstarget (list[str]): Expected answersnums (list[str]): Available numbersReturns:list[float]: Reward scores"""rewards = []for completion, gt, numbers in zip(completions, target, nums):try:# Check if the format is correctmatch = re.search(r"<answer>(.*?)<\/answer>", completion)if match is None:rewards.append(0.0)continue# Extract the "answer" part from the completionequation = match.group(1).strip()if '=' in equation:equation = equation.split('=')[0]# Extract all numbers from the equationused_numbers = [int(n) for n in re.findall(r'\d+', equation)]# Check if all numbers are used exactly onceif sorted(used_numbers) != sorted(numbers):rewards.append(0.0)continue# Define a regex pattern that only allows numbers, operators, parentheses, and whitespaceallowed_pattern = r'^[\d+\-*/().\s]+$'if not re.match(allowed_pattern, equation):rewards.append(0.0)continue# Evaluate the equation with restricted globals and localsresult = eval(equation, {"__builti'ns__": None}, {})# Check if the equation is correct and matches the ground truthif abs(float(result) - float(gt)) < 1e-5:rewards.append(1.0)else:rewards.append(0.0)except Exception as e:# If evaluation fails, reward is 0rewards.append(0.0)return rewards
orms['external_countdown'] = CountdownORM
GRPO公式
J G R P O ( θ ) = E [ q ∼ P ( Q ) , { o i } i = 1 G ∼ π θ o l d ( O ∣ q ) ] 1 G ∑ i = 1 G 1 ∣ o i ∣ ∑ t = 1 ∣ o i ∣ { min [ π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) A ^ i , t , clip ( π θ ( o i , t ∣ q , o i , < t ) π θ o l d ( o i , t ∣ q , o i , < t ) , 1 − ε , 1 + ε ) A ^ i , t ] − β D K L [ π θ ∣ ∣ π r e f ] } \begin{aligned} \mathcal{J}_{G R P O}(\theta) & =\mathbb{E}\left[q \sim P(Q),\left\{o_i\right\}_{i=1}^G \sim \pi_{\theta_{o l d}}(O \mid q)\right] \\ & \frac{1}{G} \sum_{i=1}^G \frac{1}{\left|o_i\right|} \sum_{t=1}^{\left|o_i\right|}\left\{\min \left[\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)} \hat{A}_{i, t}, \operatorname{clip}\left(\frac{\pi_\theta\left(o_{i, t} \mid q, o_{i,<t}\right)}{\pi_{\theta_{o l d}}\left(o_{i, t} \mid q, o_{i,<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) \hat{A}_{i, t}\right]-\beta \mathbb{D}_{K L}\left[\pi_\theta| | \pi_{r e f}\right]\right\} \end{aligned} JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ε,1+ε)A^i,t]−βDKL[πθ∣∣πref]}
训练参数
选取 Qwen2.5-3B-Instruct 作为基础模型进行训练,选取 Instruct 而不是基模的主要原因是可以更快地获取 format reward。我们在三卡 GPU 上进行实验,因此vllm的推理部署在最后一张卡上,而进程数设置为2,在剩下两张卡上进行梯度更新。
由于任务较为简单,我们设置 max_completion_length 和 vllm_max_model_len 为1024,如果有更复杂的任务,可以适当加大模型输出长度。注意,这两个参数越大,模型训练需要的显存越多,训练速度越慢,单个step的训练时间与max_completion_length呈现线性关系。
在我们的实验中,总batch_size为 n u m _ p r o c e s s e s × p e r _ d e v i c e _ t r a i n _ b a t c h _ s i z e × g r a d i e n t _ a c c u m u l a t i o n _ s t e p s = 2 × 8 × 8 = 128 num\_processes \times per\_device\_train\_batch\_size \times gradient\_accumulation\_steps = 2 \times 8 \times 8 = 128 num_processes×per_device_train_batch_size×gradient_accumulation_steps=2×8×8=128 而参数设置有一个限制,即: n u m _ p r o c e s s e s × p e r _ d e v i c e _ t r a i n _ b a t c h _ s i z e num\_processes \times per\_device\_train\_batch\_size num_processes×per_device_train_batch_size 必须整除 n u m _ g e n e r a t i o n s num\_generations num_generations,其中, n u m _ g e n e r a t i o n s num\_generations num_generations就是GRPO公式中的 G G G,故我们设置为8。
注意:
- 这里单卡batch_size设置也与显存息息相关,请根据显存上限设置一个合适的值。
- 总的steps数量 : n u m _ s t e p s = e p o c h s × l e n ( d a t a s e t s ) × n u m _ g e n e r a t i o n s ÷ b a t c h _ s i z e num\_steps = epochs \times len(datasets) \times num\_generations \div batch\_size num_steps=epochs×len(datasets)×num_generations÷batch_size,需要根据这个来合理规划训练的学习率和warmup设置。
- 设置是学习率和 beta,学习率比较好理解,而beta则是是以上公式的 β \beta β,即KL散度的梯度的权重。这两个参数设置的越大,模型收敛原则上更快,但训练往往会不稳定。经过实验,我们分别设置为
5e-7和0.001。在实际训练中,请根据是否出现不稳定的震荡情况适当调整这两个参数。 - 对于KL散度,社区有很多的讨论,可以参考为什么GRPO坚持用KL散度。
- 具体的参数介绍:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%8F%82%E6%95%B0.html
CUDA_VISIBLE_DEVICES=0,1,2 \
WANDB_API_KEY=your_wandb_key \
NPROC_PER_NODE=2 \
swift rlhf \--rlhf_type grpo \--model Qwen/Qwen2.5-3B-Instruct \--external_plugins examples/train/grpo/plugin/plugin.py \--reward_funcs external_countdown format \--use_vllm true \--vllm_device auto \--vllm_gpu_memory_utilization 0.6 \--train_type full \--torch_dtype bfloat16 \--dataset 'zouxuhong/Countdown-Tasks-3to4#50000' \--max_length 2048 \--max_completion_length 1024 \--num_train_epochs 1 \--per_device_train_batch_size 8 \--per_device_eval_batch_size 8 \--learning_rate 5e-7 \--gradient_accumulation_steps 8 \--eval_steps 500 \--save_steps 100 \--save_total_limit 20 \--logging_steps 1 \--output_dir output/GRPO_COUNTDOWN \--warmup_ratio 0.01 \--dataloader_num_workers 4 \--num_generations 8 \--temperature 1.0 \--system 'You are a helpful assistant. You first thinks about the reasoning process in the mind and then provides the user with the answer.' \--deepspeed zero3 \--log_completions true \--vllm_max_model_len 1024 \--report_to wandb \--beta 0.001 \--num_iterations 1
二、unsloth框架
链接:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl/tutorial-train-your-own-reasoning-model-with-grpo
1. Unsloth框架介绍
- 开源项目Unsloth AI实现重大突破,通过优化GRPO训练方法,将内存使用减少80%,让7GB显存GPU就能本地运行DeepSeek-R1级别的推理模型;
- Unsloth实现了与vLLM的深度整合,可将模型吞吐量提升20倍,同时仅需一半VRAM,使单张48GB GPU就能微调Llama 3.3 70B;
- 该项目在GitHub获2万多星,其核心团队仅由两兄弟组成,成功大幅降低了AI推理模型的部署门槛。本地也能体验「Aha」 时刻:现在可以在本地设备上复现DeepSeek-R1的推理!只需7GB VRAM,你就能体验到「Aha」时刻。Unsloth把GRPO训练需要的内存减少了80%。15GB VRAM就可以把Llama-3.1(8B)和Phi-4(14B)转变为推理模型。
2. 使用
unsloth是推理、微调一体式框架,unsloth将Llama 3.3、Mistral、Phi-4、Qwen 2.5和Gemma的微调速度提高2倍,同时节省80%的内存。官网地址:GitHub - unslothai/unsloth: Finetune Llama 3, Mistral & Gemma LLMs 2-5x faster with 80% less memoryhttps://github.com/unslothai/unsloth
使用如下命令快速安装:
pip install unslothpip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
3. 训练参数
SFTTTrainer 进行监督微调(Supervised Fine-Tuning, SFT),适用于 transformers 和 Unsloth 生态中的模型微调:1. 相关库
-
SFTTrainer(来自 trl 库):
- trl(Transformer Reinforcement Learning)是 Hugging Face 旗下的 trl 库,提供监督微调(SFT)和强化学习(RLHF)相关的功能。
- SFTTrainer 主要用于有监督微调(Supervised Fine-Tuning),适用于 LoRA 等低秩适配微调方式。
-
TrainingArguments(来自 transformers 库):
- 这个类用于定义训练超参数,比如批量大小、学习率、优化器、训练步数等。
-
is_bfloat16_supported(来自 unsloth):- 这个函数检查当前 GPU 是否支持 bfloat16(BF16),如果支持,则返回 True,否则返回 False
- bfloat16 是一种更高效的数值格式,在新款 NVIDIA A100/H100 等GPU上表现更优。
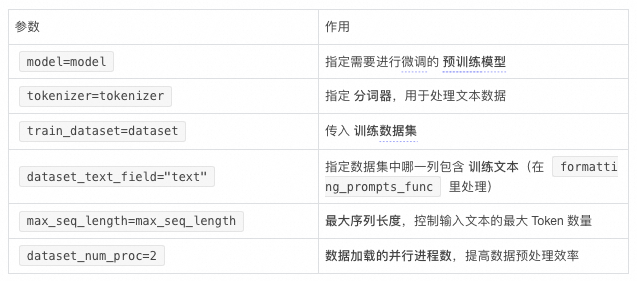
SFTTrainer 部分
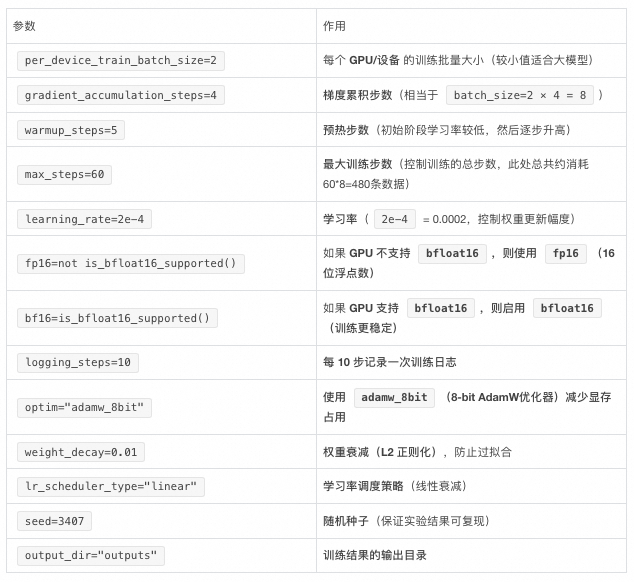
TrainingArguments 部分
参考:从零开始的DeepSeek微调训练实战(SFT)阿里云开发社区
三、open r1项目
一个parquet文件:/root/paddlejob/workspace/env_run/gtest/rl_train/data/OpenR1-Math-220k/open-r1/OpenR1-Math-220k/all/train-00001-of-00020.parquet
SFT训练:
# Train via command line
accelerate launch --config_file=recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py \--model_name_or_path Qwen/Qwen2.5-1.5B-Instruct \--dataset_name open-r1/OpenR1-Math-220k \--learning_rate 1.0e-5 \--num_train_epochs 1 \--packing \--max_seq_length 16384 \--per_device_train_batch_size 16 \--gradient_checkpointing \--bf16 \--output_dir data/Qwen2.5-1.5B-Open-R1-Distill# Train via YAML config
accelerate launch --config_file recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py \--config recipes/Qwen2.5-1.5B-Instruct/sft/config_demo.yaml
GRPO训练:
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/zero2.yaml \--num_processes=7 src/open_r1/grpo.py \--config recipes/DeepSeek-R1-Distill-Qwen-1.5B/grpo/config_demo.yaml
数据生成
数据生成:为了构建 OpenR1-220k,我们使用 DeepSeek R1 大语言模型生成 NuminaMath 1.5 中 40 万个问题的解决方案。我们遵循模型卡的推荐参数,并在用户提示词前添加以下指令:“请逐步推理,并将最终答案放在 \boxed{} 中。”
from datasets import load_dataset
from distilabel.models import vLLM
from distilabel.pipeline import Pipeline
from distilabel.steps.tasks import TextGenerationprompt_template = """\
You will be given a problem. Please reason step by step, and put your final answer within \boxed{}:
{{ instruction }}"""dataset = load_dataset("AI-MO/NuminaMath-TIR", split="train").select(range(10))model_id = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B" # Exchange with another smol distilled r1with Pipeline(name="distill-qwen-7b-r1",description="A pipeline to generate data from a distilled r1 model",
) as pipeline:llm = vLLM(model=model_id,tokenizer=model_id,extra_kwargs={"tensor_parallel_size": 1,"max_model_len": 8192,},generation_kwargs={"temperature": 0.6,"max_new_tokens": 8192,},)prompt_column = "problem"text_generation = TextGeneration(llm=llm, template=prompt_template,num_generations=4,input_mappings={"instruction": prompt_column} if prompt_column is not None else {})if __name__ == "__main__":distiset = pipeline.run(dataset=dataset)distiset.push_to_hub(repo_id="username/numina-deepseek-r1-qwen-7b")
提示词:
You are a mathematical answer validator. You will be provided with a mathematical problem and you need to compare the answer in the reference solution, and the final answer in a model's solution to determine if they are equivalent, even if formatted differently.PROBLEM:{problem}REFERENCE SOLUTION:{answer}MODEL'S SOLUTION:{generation}Focus ONLY on comparing the final mathematical answer provided by the model while ignoring differences in:- Formatting (e.g., \\boxed{{}} vs plain text)
- Multiple choice formatting (e.g., "A" vs full solution)
- Order of coordinate pairs or solutions
- Equivalent mathematical expressions or notation variations
- If the model's answer is nonsense, return "Verdict: AMBIGUOUS"Start with a brief explanation of your comparison (2-3 sentences). Then output your final answer in one of the following formats:- "Verdict: EQUIVALENT"
- "Verdict: DIFFERENT"
- "Verdict: AMBIGUOUS"
模型训练
模型评估
在几个经典benchmark上评估:
MODEL=deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
MODEL_ARGS="pretrained=$MODEL,dtype=bfloat16,max_model_length=32768,gpu_memory_utilization=0.8,generation_parameters={max_new_tokens:32768,temperature:0.6,top_p:0.95}"
OUTPUT_DIR=data/evals/$MODEL# AIME 2024
TASK=aime24
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# MATH-500
TASK=math_500
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# GPQA Diamond
TASK=gpqa:diamond
lighteval vllm $MODEL_ARGS "custom|$TASK|0|0" \--custom-tasks src/open_r1/evaluate.py \--use-chat-template \--output-dir $OUTPUT_DIR# LiveCodeBench
lighteval vllm $MODEL_ARGS "extended|lcb:codegeneration|0|0" \--use-chat-template \--output-dir $OUTPUT_DIR
四、GRPO经验总结
关于DeepseekR1的17个观点
DeepseekR1总结,在 DeepSeek-R1 发布 100 天后,我们学到了什么?,100 Days After DeepSeek-R1: A Survey on Replication Studies and More Directions for Reasoning Language Models,https://arxiv.org/pdf/2505.00551,DeepSeek-R1模型发布后的100天内,学术界对其复制研究的进展和未来发展方向。
17个观点:
1、高质量、经过验证的思维链(Chain-of-Thought, CoT)数据对于监督微调(Supervised Fine-Tuning, SFT)是有效的。
2、为 SFT 挑选更难的问题(例如,基于较弱模型的低通过率筛选)能显著提升模型性能。
3、开放数据集中混杂有基准测试样本,需要仔细进行数据去污染(decontamination)以保证公平评估。
4、倾向于包含更长 CoT(通常意味着问题更复杂)的数据集,在 SFT 后往往能带来更好的推理性能。
5、SFT 能有效地赋予模型推理结构,为后续的强化学习(Reinforcement Learning, RL)奠定必要基础。
6、相较于基础模型,已经过指令微调的模型在 SFT 阶段能更有效地学习推理模式。
7、强化学习(RL)数据集受益于严格的验证过程(例如使用数学求解器、代码执行)以及筛选掉模型可能出错的“不确定性”样本。
8、使用简单的、可验证的、基于结果的奖励(例如,判断对错)是有效的,并且能降低奖励操纵(reward hacking)的风险。
9、在推理模型的强化学习(RL for Verification/Reasoning)中,明确的格式或长度奖励的必要性和益处尚存争议,有时模型可以隐式地学习这些方面。
10、PPO 和 GRPO 是最常用的 RL 算法,但它们的变体(如 DAPO、Dr. GRPO、VC-PPO、VAPO)被设计用于解决偏差(如长度偏差、难度偏差)和训练不稳定性问题。
11、KL 损失虽然常用于提升训练稳定性,但在推理模型的 RL 训练中有时会被省略,或者发现它会限制模型的探索能力和最终的性能提升。
12、在 RL 训练过程中,逐步增加训练样本的难度或模型允许的最大响应长度,有助于提升性能和稳定性。
13、将训练重点放在更难的样本上,或者剔除模型已经“学会解决”的简单样本,这类策略可以提升 RL 的训练效率。
14、集成了价值函数的方法(如 VC-PPO、VAPO)在处理长 CoT 问题时,其表现可能优于无价值函数的方法(如 GRPO)。
15、RL 训练能够提升模型的域外泛化能力,其效果可能超越单独使用 SFT,甚至能泛化到看似不相关的任务上(例如,通过数学/代码训练提升写诗能力)。
16、推理模型带来了新的安全挑战,例如奖励操纵(reward hacking)、过度思考(overthinking)以及特定的越狱(jailbreaking)漏洞。
17、对于较小规模的模型(例如 <32B 参数),相比于使用蒸馏得到的检查点(distilled checkpoints),单纯依靠 RL 来复现最佳性能通常更具挑战性。
Reference
[1] Open R1 项目 第二周总结与展望
[2] 摸着Logic-RL,复现7B - R1 zero
[3] https://huggingface.co/blog/open-r1/update-2
[4] 用极小模型复现R1思维链的失败感悟
[5] https://github.com/Unakar/Logic-RL
[6] 【LLM-RL】强化对齐之GRPO算法和微调实践
[7] 官方文档:https://docs.unsloth.ai/get-started/fine-tuning-guide
[8] https://huggingface.co/datasets/yahma/alpaca-cleaned/viewer
[9] 官方文档跑GRPO:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl/tutorial-train-your-own-reasoning-model-with-grpo
[10] R1复现小记:在业务场景的两类NLP任务上有显著效果 NLP工作站
[11] 批判性视角看待 R1 训练(基础模型和强化学习)中的坑
[12] MLNLP社区发布《动画中学强化学习笔记》项目!
[13] 【LLM】R1复现项目(SimpleRL、OpenR1、LogitRL、TinyZero)持续更新
[14] 项目地址:https://github.com/MLNLP-World/Reinforcement-Learning-Comic-Notes
[15] 笔记:https://github.com/MLNLP-World/Reinforcement-Learning-Comic-Notes/tree/main/note
[16] unsloth官方微调指南:https://docs.unsloth.ai/get-started/fine-tuning-guide
[17] unsloth官方GRPO指南:https://docs.unsloth.ai/basics/reasoning-grpo-and-rl
[18] 基于unsloth框架完成7B规模模型SFT微调训练(10GB显存占用) bookname,某乎
[19] 使用Unsloth训练自己的R1模型.中科院计算所
[20] GRPO中的KL Loss实现细节问题
[21] 个性训练(2)-借助GRPO提升多轮对话能力
[22] 个性训练-借助GRPO塑造一个有个性且智商在线的大模型
[23] 为什么大家都在吹deepseek的GRPO?某乎
[24] Datasets Guide 数据集指南
[25] 基于qwen2.5进行GRPO训练:https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(3B)-GRPO.ipynb
[26] DeepSeek同款GRPO训练大提速!魔搭开源全流程方案,支持多模态训练、训练加速和评测全链路
[27] 聊聊DeepSeek-R1-Distilled-QWen32B基于GRPO算法下的训练记录——基于ms-swift训推框架
[28] 多模态GRPO完整实验流程- swift 小健
[29] swift官方文档GRPO训练过程:https://swift.readthedocs.io/zh-cn/latest/BestPractices/GRPO%E5%AE%8C%E6%95%B4%E6%B5%81%E7%A8%8B.html
[30] [Wandb] api key怎么查看
[31] 多模态GRPO完整实验流程.swift官方文档
[32] AI大模型ms-swift框架实战指南(十):自定义数据集微调实践大全
[33] 大模型团队搞GRPO强化学习,一些小Tips2