Spring AI 实战:第一章、Spring AI入门之DeepSeek调用
引言:当Spring遇上AI,会擦出怎样的火花?
作为一名Java开发者,是否曾经眼红Python阵营那些花里胡哨的AI应用?是否在对接各种大模型API时,被五花八门的接口规范搞得头大?好消息是,Spring家族的新成员——Spring AI,正在用Java开发者最熟悉的方式,为我们打开AI应用开发的新世界大门。
一、Spring AI初探 - 你的AI管家
1.1 为什么需要Spring AI?
场景假设
- 你的老板说:"我们要做个智能客服,先用OpenAI,下个月换Claude,年底可能用Gemini..."
- 产品经理要求:"这个AI回答要能直接转成我们的领域对象"
- 运维大哥抱怨:"AI调用太慢了,能不能给个监控看板?"
解决方案
将Spring AI框架集成到应用当中,它是一个专注于AI工程的应用框架;旨在将Spring生态的设计原则(如可移植性、模块化)引入AI领域,简化企业数据或者API服务与大模型的集成,将大模型的调用通过普通Java对象来封装,降低开发复杂度,从而高效构建企业智能应用
// 不管底层是哪个AI服务,调用方式都一样
String joke = aiClient.generate("讲个程序员笑话");1.2 核心能力
| 分类 | 功能描述 |
| 多模型支持 | 支持主流AI模型提供商(如OpenAI、Anthropic、Google、Microsoft等),覆盖多种模型类型:
|
| 统一API接口 |
|
| 结构化输出映射 |
|
| 向量数据库集成 |
|
| 工具与实时交互 |
|
| 企业级支持 |
|
| 开发者友好设计 |
|
| 快速集成 |
|
二、实战DeepSeek - 从手动到自动
2.1 手动执行请求
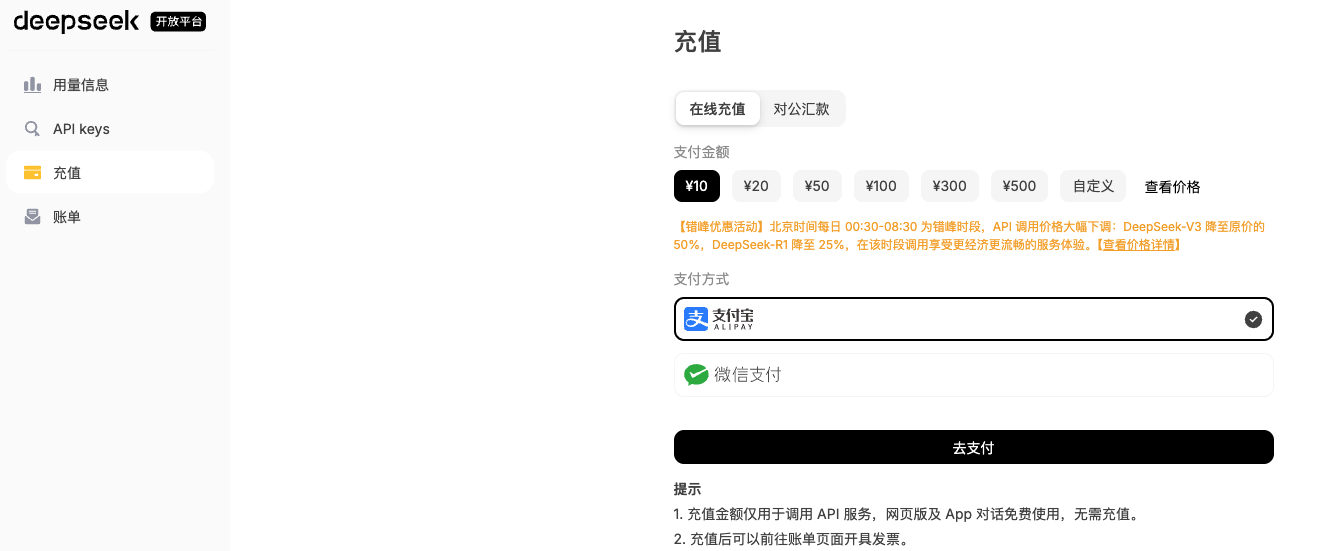
API-KEY的获取
进入DeepSeek开放平台 DeepSeek ,完成账号的注册与充值(开发学习时可以少充一点费用),点击 API keys创建个人专属API key 并保存下来

curl手动执行
填写上正确的Key后执行curl发起Http请求,快速得到响应结果
curl https://api.deepseek.com/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer <DeepSeek API Key>" \-d '{"model": "deepseek-chat","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "讲一个笑话"}],"stream": false}'{"id": "0e8dd4b9-694e-417b-888a-7be54a77633f","object": "chat.completion","created": 1742744584,"model": "deepseek-chat","choices":[{"index": 0,"message":{"role": "assistant","content": "当然!这是一个经典的笑话:\n\n有一天,小明去面试。面试官问他:“你有什么特长吗?”\n\n小明想了想,认真地说:“我会预测未来。”\n\n面试官笑了笑:“那你预测一下,你什么时候能被录用?”\n\n小明淡定地回答:“这个嘛……我预测我不会被录用。”\n\n面试官愣了一下,笑着说:“你被录用了!我们需要你这样的人才!”\n\n😄"},"logprobs": null,"finish_reason": "stop"}],"usage":{"prompt_tokens": 12,"completion_tokens": 74,"total_tokens": 86,"prompt_tokens_details":{"cached_tokens": 0},"prompt_cache_hit_tokens": 0,"prompt_cache_miss_tokens": 12},"system_fingerprint": "fp_3a5770e1b4_prod0225"
}返回数据以JSON格式,解析格式中的content内容得到为大模型给我们讲的笑话。
2.2 代码自动发起
创建第一个Spring AI工程
访问 https://start.spring.io/ 按截图所示勾选依赖,生成代码框架
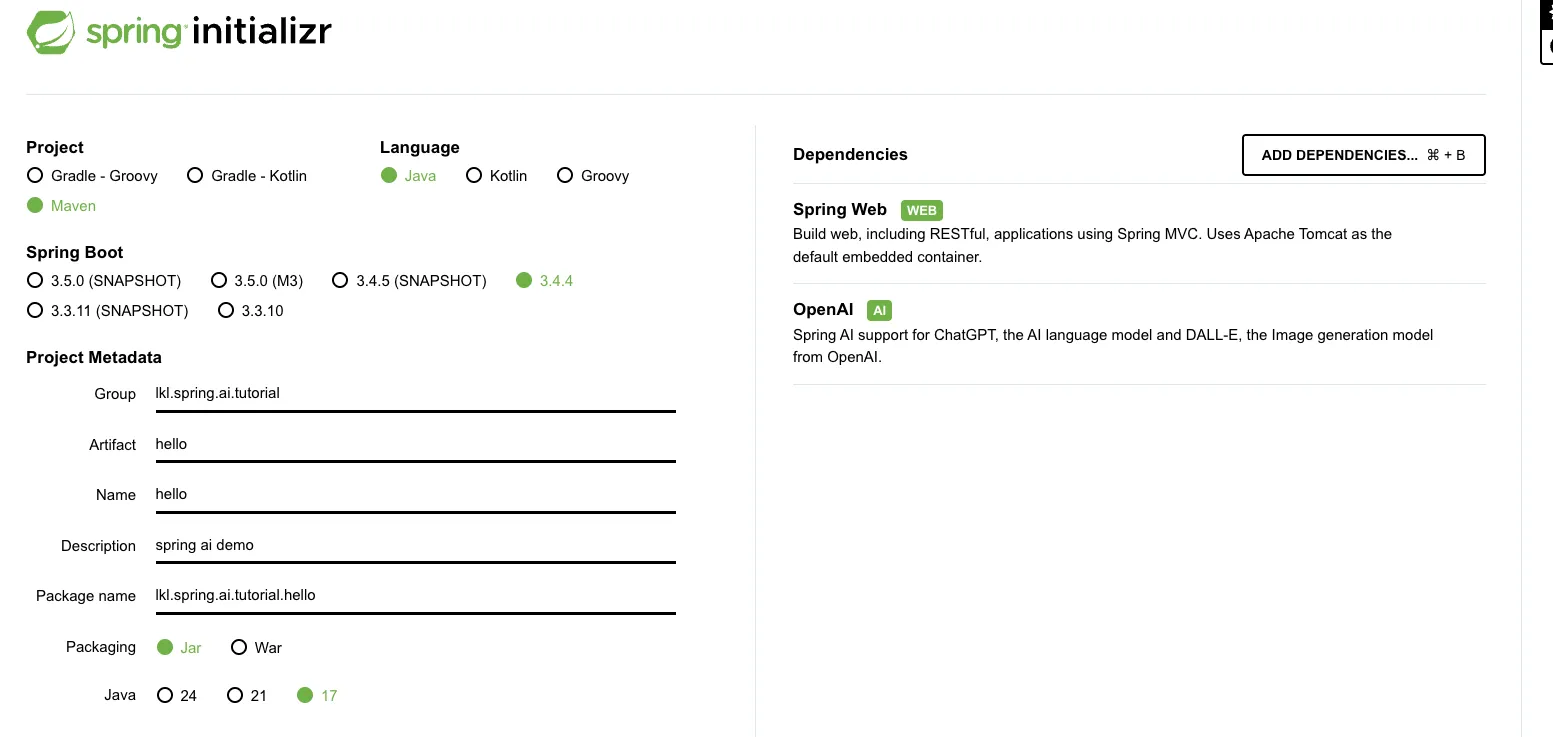
Spring Boot 3.x
JDK 17+
spring-ai-openai-starter(是的,它能兼容DeepSeek)
将生成的代码导入到IDEA中,启动应用
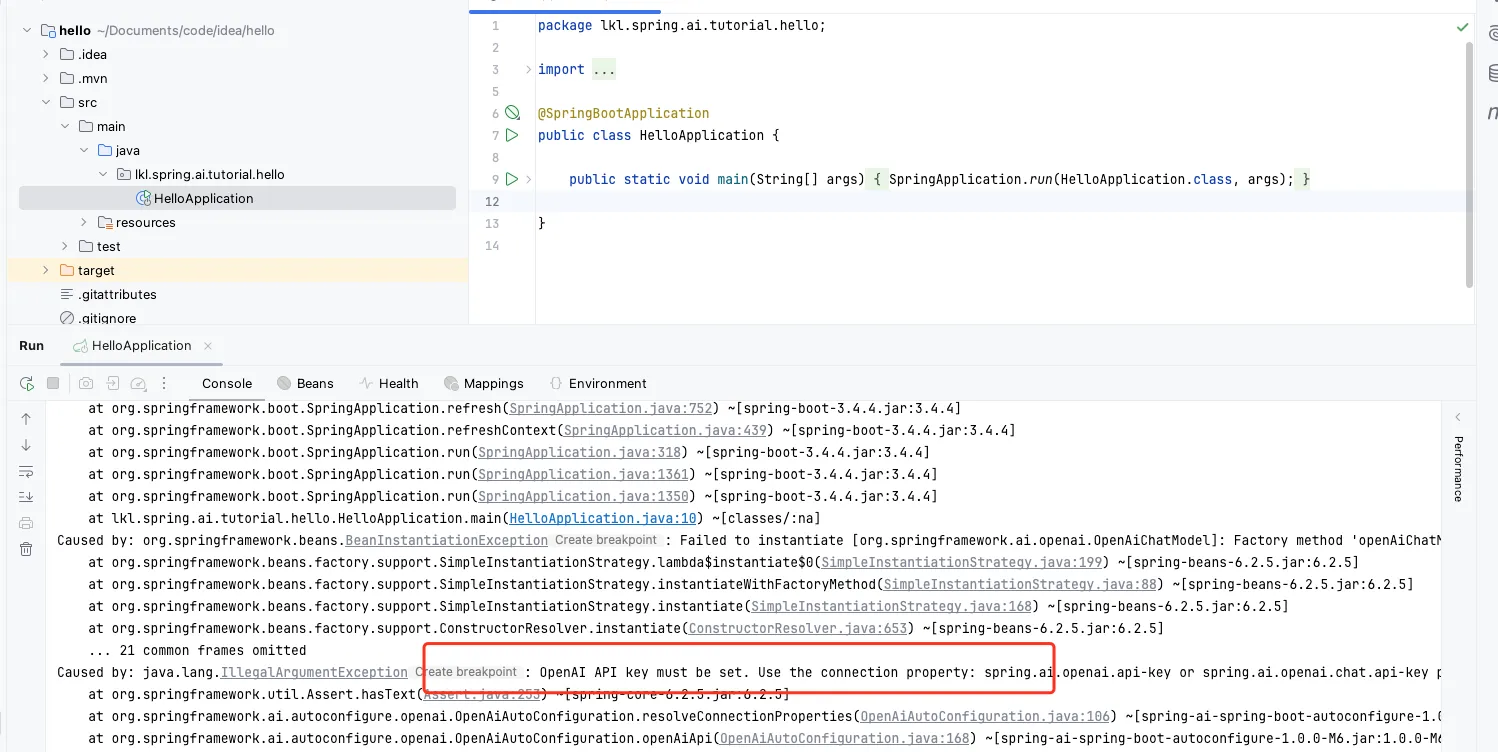
很遗憾,竟然没有启动起来,出现一个OpenAI API key must be set. Use the connection property: spring.ai.openai.api-key or spring.ai.openai.chat.api-key property的错误,
很明显是没有配置对应的API key,打开application.properties进入参数配置后发现启动成功
配置application.properties
spring.application.name=hellospring.ai.openai.api-key=换成个人的DeepSeek API keyspring.ai.openai.base-url=https://api.deepseek.comspring.ai.openai.chat.options.model=deepseek-chat编写Controller
@RestController
public class HelloController {private ChatClient chatClient;public HelloController(ChatClient.Builder builder) {this.chatClient = builder.build();}@GetMapping("/hello")public String hello(@RequestParam(value = "input", defaultValue = "讲一个笑话") String input) {return chatClient.prompt(input).call().content();}
}打开浏览器访问 http://localhost:8080/hello 得到结果

三、流式响应-打字机效果
3.1 Reactor初体验
通常大模型的响应耗时较长,为了优化用户体验,ChatGPT等厂商纷纷采用流式输出;我们可以通过Reactor框架来实现,它是一个响应式编程库,提供构建异步和非阻塞应用程序的能力。
private ExecutorService executor = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MICROSECONDS, new LinkedBlockingQueue<>(10));@GetMapping(value = "/mock/stream", produces = "text/html;charset=UTF-8")
public Flux<String> mockStream() {Sinks.Many<String> sink = Sinks.many().multicast().onBackpressureBuffer();executor.submit(() -> {for (int i = 0; i < 100; i++) {sink.tryEmitNext(i + " ");try {Thread.sleep(100);} catch (InterruptedException e) {throw new RuntimeException(e);}}});return sink.asFlux();
}Sinks.Many 用于创建多值(Multi-Value)的发布者(Publisher)的一种机制,它允许用户将数据从一个地方发送到多个订阅者,示例中启动异步线程做写入操作,通过asFlux获取Flux对象;启动看效果:

3.2 大模型的流式输出
@GetMapping(value = "/hello/stream", produces = "text/html;charset=UTF-8")public Flux<String> helloStream(@RequestParam(value = "input", defaultValue = "讲一个笑话") String input) {return chatClient.prompt(input).stream().content();}把前面的call方法修改为stream即可,最终返回一个Flux对象,搞定流式输出~

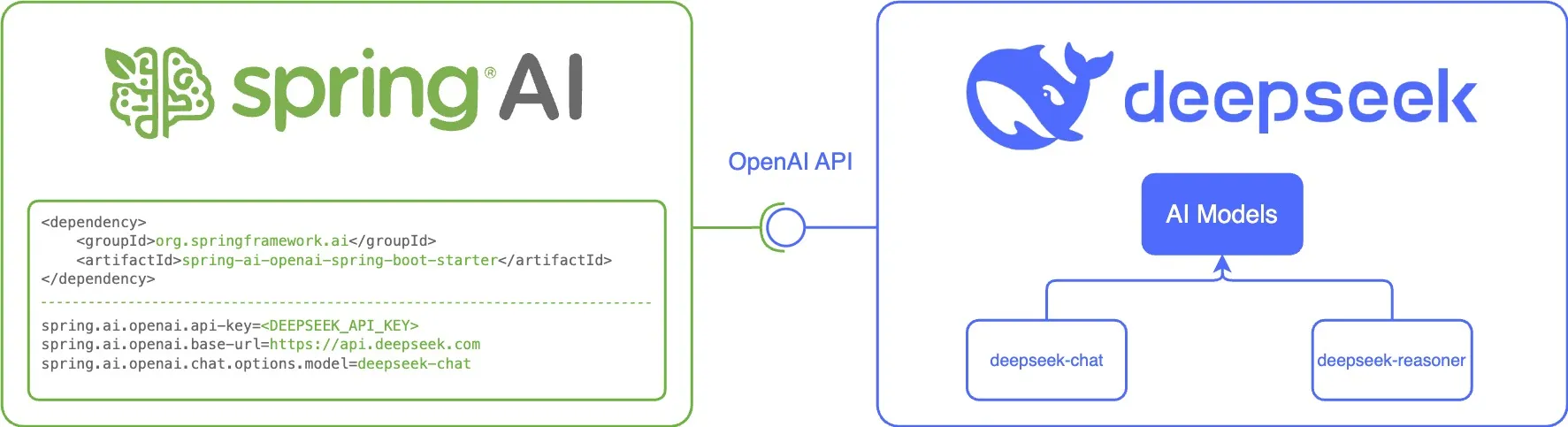
四、OpenAI的starter兼容DeepSeek?
DeepSeek
观察pom.xml文件发现配置的是spring-ai-openai-starter却配置DeepSeek的URL,是不是觉得有点魔幻?
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>其实这是Spring AI的"障眼法":
- OpenAI的API规范已成为事实标准
- DeepSeek等国内服务兼容这套规范
- Spring AI利用"可移植API"设计,实现一套代码多处使用
就像JDBC驱动可以连接不同数据库,Spring AI的客户端也能适配不同AI服务。
通义千问
类似的,阿里系通义大模型也同样适用OpenAI这套访问规范。
在百炼控制台 创建个人专属API-KEY(有免费的额度)

在application.properties修改配置
spring.ai.openai.api-key=sk-xxxspring.ai.openai.base-url=https://dashscope.aliyuncs.com/compatible-mode
# 指定模型
spring.ai.openai.chat.options.model=qwen-plus
五、生产环境必备 - 给你的AI装上监控
老板问:"AI花了多少钱?效果怎么样?" ,不用慌,可以通过监控来解决
添加监控依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId>
</dependency>启动监控
management.endpoints.web.exposure.include=health,metrics,prometheus
spring.ai.observability.enabled=true访问/actuator/prometheus,将看到:(如何配合grafana可视化效果会更加直观)

结语:未来以来
Spring AI的出现,为Java开发者提供一整套大模型应用研发基础底座,为众多Java生态企业级的应用迈向AI领域开辟一条航向; AI时代已然到来,让我们一起扬帆起航~~~