机器学习常用评价指标
1. 指标说明
(1) AccuracyClassification(准确率)
• 计算方式:accuracy_score(y_true, y_pred)
• 作用:
衡量模型正确预测的样本比例(包括所有类别)。
公式:
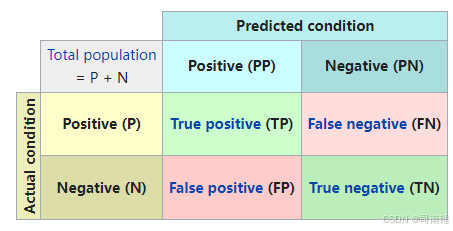
Accuracy = TP + TN TP + TN + FP + FN \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} Accuracy=TP+TN+FP+FNTP+TN
• 适用场景:
类别分布平衡时有效,但在类别不平衡时可能误导(例如多数类占比过高)。
(2) PrecisionClassification(精确率,宏平均)
• 计算方式:precision_score(y_true, y_pred, average='macro')
• 作用:
衡量模型预测为正的样本中实际为正的比例,按类别计算后取宏平均(各类别权重相同)。
公式(单类别):
Precision = TP TP + FP \text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}} Precision=TP+FPTP
• 适用场景:
关注减少误报(FP),例如垃圾邮件分类中避免将正常邮件误判为垃圾邮件。
(3) RecallClassification(召回率,宏平均)
• 计算方式:recall_score(y_true, y_pred, average='macro')
• 作用:
衡量实际为正的样本中被正确预测的比例,宏平均。
公式(单类别):
Recall = TP TP + FN \text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}} Recall=TP+FNTP
• 适用场景:
关注减少漏报(FN),例如疾病诊断中避免漏诊。
(4) F1Classification(F1分数,宏平均)
• 计算方式:f1_score(y_true, y_pred, average='macro')
• 作用:
精确率和召回率的调和平均值,平衡两者。
公式(单类别):
F 1 = 2 × Precision × Recall Precision + Recall F1 = 2 \times \frac{\text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} F1=2×Precision+RecallPrecision×Recall
• 适用场景:
需要同时兼顾精确率和召回率,尤其在类别不平衡时。
(5) ROCAUC(ROC曲线下面积,宏平均)
• 计算方式:roc_auc_score(y_true, y_proba, average='macro', multi_class='ovr')
• 作用:
通过多分类的One-vs-Rest策略计算AUC,衡量模型对不同类别的区分能力。
• 适用场景:
需要评估模型在不同阈值下的整体性能(如二分类或多分类概率输出)。
(6) AverageAccuracy(平均精度,AA)
• 计算方式:
对每个类别的准确率单独计算后取平均(忽略类别样本数差异)。
• 作用:
避免多数类主导整体准确率,更关注少数类的表现。
• 与Accuracy的区别:
• Accuracy:所有样本的全局正确率。
• AA:每个类别的正确率平均(更公平评估类别不平衡数据)。
(7) Kappa(Cohen’s Kappa系数)
• 计算方式:cohen_kappa_score(y_true, y_pred)
• 作用:
衡量模型预测与真实标签的一致性,排除随机猜测的影响。
公式:
κ = p o − p e 1 − p e \kappa = \frac{p_o - p_e}{1 - p_e} κ=1−pepo−pe
其中 (p_o) 是观察一致率,(p_e) 是随机一致率。
• 适用场景:
需要评估模型预测是否显著优于随机猜测(例如医学诊断或评估者间一致性)。
2. 是否存在重复?
• Accuracy vs AverageAccuracy:
• Accuracy是全局指标,AA是类别均衡的指标。两者互补,尤其在类别不平衡时需同时使用。
• 示例:若90%样本属于A类,模型全预测A类时:
◦ `Accuracy`=90%,但`AA`=50%(B类精度为0%)。 ◦ 此时`AA`更能暴露问题。
• Precision/Recall/F1(宏平均):
• 三者均基于类别宏平均,但侧重点不同(精确率、召回率、调和平均),无重复。
• 若需微平均或加权平均,需调整average参数(如average='weighted')。
• ROCAUC与其他指标:
• ROCAUC基于概率输出,其他指标基于硬标签预测,两者角度不同(概率 vs 分类结果)。
• Kappa vs Accuracy:
• Kappa考虑了随机一致性,比Accuracy更严格。例如:
◦ 若两个类别占比各50%,随机猜测的`Accuracy`=50%,`Kappa`=0。 ◦ `Kappa`能反映模型是否真正优于随机。
• 推荐组合:
• 类别平衡数据:Accuracy + F1 + ROCAUC。
• 类别不平衡数据:AA + F1(宏平均) + Kappa。
• 需减少误报:关注Precision;需减少漏报:关注Recall。
以下是针对图像分割任务的三个评价指标(PixelAccuracy、IoU、DiceCoefficient)的详细分析,包括它们的计算逻辑、适用场景以及是否存在重复或互补关系。
1. 指标说明
(1) PixelAccuracy(像素准确率)
• 计算方式:
PA = ∑ 正确预测的像素数 ∑ 总像素数 \text{PA} = \frac{\sum \text{正确预测的像素数}}{\sum \text{总像素数}} PA=∑总像素数∑正确预测的像素数
• 特点:
• 直接统计所有像素中预测正确的比例。
• 优点:计算简单,直观反映全局分割精度。
• 缺点:对类别不平衡敏感(例如背景像素占主导时,高PA可能掩盖前景类别的性能差)。
• 适用场景:
初步评估分割质量,但需结合其他指标使用。
(2) IoU(交并比,平均IoU)
• 计算方式(单类别):
IoU c = ∣ A c ∩ B c ∣ ∣ A c ∪ B c ∣ \text{IoU}_c = \frac{|A_c \cap B_c|}{|A_c \cup B_c|} IoUc=∣Ac∪Bc∣∣Ac∩Bc∣
其中 (A_c) 是真实类别 (c) 的像素集合,(B_c) 是预测类别 (c) 的像素集合。
• 宏平均:对所有类别的IoU取均值。
• 特点:
• 衡量预测区域与真实区域的重叠程度。
• 优点:对类别不平衡不敏感,直接评估分割边界质量。
• 缺点:若某类别在图像中不存在(并集为0),需特殊处理(代码中设为0)。
• 适用场景:
分割任务的核心指标,尤其关注边界准确性(如医学图像分割)。
(3) DiceCoefficient(Dice系数,平均Dice)
• 计算方式(单类别):
Dice c = 2 ∣ A c ∩ B c ∣ ∣ A c ∣ + ∣ B c ∣ \text{Dice}_c = \frac{2|A_c \cap B_c|}{|A_c| + |B_c|} Dicec=∣Ac∣+∣Bc∣2∣Ac∩Bc∣
• 与IoU的关系:(\text{Dice} = \frac{2 \times \text{IoU}}{1 + \text{IoU}})。
• 宏平均:对所有类别的Dice取均值。
• 特点:
• 类似IoU,但更强调预测与真实区域的交集。
• 优点:对分割区域的体积差异更敏感(例如小目标分割)。
• 缺点:与IoU高度相关,可能提供冗余信息。
• 适用场景:
医学图像分割(如肿瘤检测),需强调目标区域的匹配度。
2. 指标对比与潜在重复
| 指标 | 敏感性(类别不平衡) | 侧重方向 | 与IoU的关系 |
|---|---|---|---|
PixelAccuracy | 高敏感 | 全局像素正确率 | 无关 |
IoU | 低敏感 | 区域重叠精度 | 基准指标 |
DiceCoefficient | 低敏感 | 区域体积匹配度 | 与IoU强相关(数学可转换) |
• IoU vs Dice:
• 两者均衡量预测与真实区域的重叠,存在强相关性。Dice对交集更敏感,但实际应用中差异可能不显著。
• 是否冗余:
◦ 若仅需一个区域重叠指标,优先选择`IoU`(更通用)。 ◦ 若需强调小目标或医学分割,可保留`Dice`(但需注意解释时避免重复)。
• PixelAccuracy vs IoU/Dice:
• PA与后两者无直接重复,但需注意:
◦ 高`PA`可能掩盖低`IoU`(如背景主导时模型只预测背景)。 ◦ 建议同时报告`PA`和`IoU`以全面评估。
3. 改进建议
-
避免冗余:
• 若需简化指标集,可仅保留IoU(因其与Dice功能重叠)。• 若需保留
Dice,建议在文档中说明其与IoU的差异(例如对小目标的敏感性)。 -
增强鲁棒性:
• 在IoU和Dice中,对num_classes的输入增加校验(如自动推断类别数):if num_classes is None:num_classes = len(np.unique(y_true)) -
处理极端情况:
• 当某类别在真实和预测中均不存在时(union=0),当前代码返回IoU=0,但也可考虑跳过该类别(避免拉低均值)。
4. 示例场景
• 医学图像分割(类别不平衡):
• 报告IoU(评估边界) + Dice(评估体积匹配) + PA(辅助验证全局精度)。
• 街景分割(多类别平衡):
• 优先IoU + PA,可省略Dice。
总结
• 核心指标:IoU(必选),Dice(可选,与IoU二选一)。
• 辅助指标:PixelAccuracy(需结合其他指标解读)。
• 无严格重复,但需根据任务需求精简指标集以避免冗余。
1. 指标说明
(1) MSE(均方误差,Mean Squared Error)
• 公式:
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
• 特点:
• 对误差进行平方,放大较大误差的惩罚(对异常值敏感)。
• 输出值无单位(平方后量纲),需结合其他指标解释。
• 适用场景:
• 需要强调避免大误差的任务(如金融风险预测)。
• 与梯度下降法兼容(平方函数可导,利于优化)。
(2) RMSE(均方根误差,Root Mean Squared Error)
• 公式:
RMSE = MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\text{MSE}} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2} RMSE=MSE=n1i=1∑n(yi−y^i)2
• 特点:
• 是 MSE 的平方根,恢复原始数据的单位(更直观)。
• 同样对较大误差敏感,但数值比 MSE 小(因平方根压缩)。
• 适用场景:
• 需要与目标变量同量纲的解释(如房价预测的误差以“万元”为单位)。
• 比 MSE 更贴近实际误差规模。
(3) MAE(平均绝对误差,Mean Absolute Error)
• 公式:
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
• 特点:
• 直接计算绝对误差,对异常值不敏感(线性惩罚)。
• 单位与原始数据一致,解释性强。
• 适用场景:
• 数据中存在异常值或误差分布不均匀时(如传感器噪声)。
• 需要鲁棒性强的评估(如医疗诊断中的误差容忍)。
2. 指标对比
| 指标 | 敏感性(异常值) | 单位一致性 | 数学性质 | 典型用途 |
|---|---|---|---|---|
MSE | 高敏感 | 无 | 可导,凸函数 | 模型优化、理论分析 |
RMSE | 高敏感 | 有 | 可导,凸函数 | 结果解释、业务场景汇报 |
MAE | 低敏感 | 有 | 不可导,非光滑 | 鲁棒性评估、异常数据 |
3. 如何选择指标?
-
优先
RMSE:
• 如果需直观解释误差规模(如报告“平均误差为 5 元”),且数据较干净。 -
优先
MAE:
• 如果数据含异常值或需均衡对待所有误差(如医疗场景)。 -
优先
MSE:
• 如果模型训练需梯度下降(如神经网络),或需理论分析(如分解偏差-方差)。
4. 代码优化建议
当前实现已简洁高效,但可补充以下功能:
(1) 多输出支持
若任务是多目标回归(如预测房价和面积),可扩展为逐维度计算指标:
class MSE:def calculate(self, y_true, y_pred, axis=0):return np.mean((y_true - y_pred) ** 2, axis=axis)
(2) 加权误差
对某些样本的误差赋予不同权重(如时间序列中的近期数据更重要):
class WeightedMAE:def calculate(self, y_true, y_pred, weights):return np.average(np.abs(y_true - y_pred), weights=weights)
5. 示例场景
• 房价预测:
• 报告 RMSE=50万元(直观),同时监控 MAE 以排除极端异常影响。
• 股票价格预测:
• 使用 MSE 训练模型(惩罚大误差),但用 MAE 评估鲁棒性。
• 传感器校准:
• 优先 MAE(因噪声普遍存在,需均衡误差)。
总结
• MSE/RMSE/MAE 三者互补,无严格冗余,但需根据任务需求选择:
• 训练阶段:常用 MSE(可导性)。
• 最终评估:结合 RMSE(直观)和 MAE(鲁棒)。
• 扩展性:当前实现可支持多维度或加权计算,灵活适配复杂场景。