《计算机系统结构》考题知识点整理
最近要考系统结构了,赶紧复习一下,把当时没弄懂的都尽量弄懂一下。
(是临时抱佛脚罢)
Chapter3 流水线技术
知识点回顾——画流水线时空图
首先我们考试里面出现的流水线一般就是五段流水线,即 IF、ID、EX(组成原理那会写作EXE,系统结构考试里还得写EX)、MEM、WB。我们画出来的时空图,横轴是时间(时钟周期),纵轴是指令。在没有冲突的情况下,每一行都是 IF-WB,如下图所示。
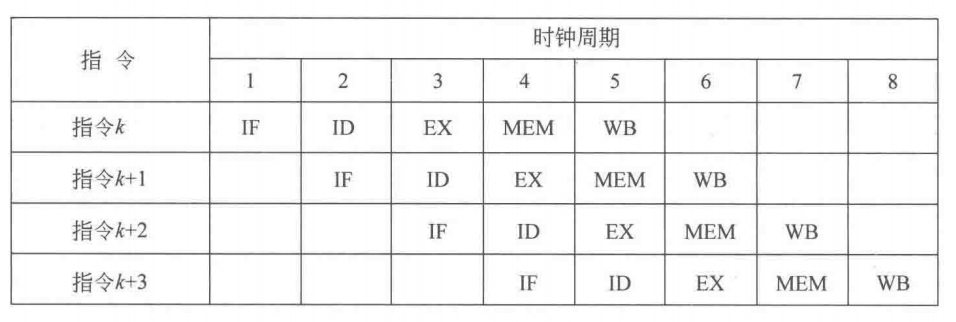
正因为有冲突的存在,时空图不可能是上面那样的。五段流水线主要是一个数据冲突,具体来说是写后读(RAW)冲突。
-
无重定向机制:RAW 的消费者指令必须老老实实待在 IF 段。等到生产者指令到 MEM 段了(此时消费者指令还在 IF 段),才可以继续流动。下一时钟周期,生产者指令到 WB 段,消费者指令到了 ID 段。由于寄存器组是在前半个时钟周期完成写,后半个时钟周期完成读,所以消费者可以读取到正确的寄存器内容。
需要特别注意,在这种情况(无重定向机制)下,不仅是相邻的指令可能存在数据冲突。有时候第 i i i 和 i + 1 i+1 i+1 条指令无冲突,第 i + 1 i+1 i+1 和 i + 2 i+2 i+2 条指令也是无冲突,但 i i i 和 i + 2 i + 2 i+2 存在冲突。这种情况也是需要特别注意的,指令 i i i 会给指令 i + 2 i+2 i+2 带来一次 stall。但是无需考虑指令 i i i 对指令 i + 3 i+3 i+3 或者更后面的指令造成的数据冲突,因为离得太远了。
-
有重定向机制:需要注意,这里的重定向机制指的是把某个流水寄存器的东西重定向到某个段的输入。比如若把 MEM/WB 流水寄存器的输出重定向到 EX 段的输入,可以做到在 t t t 周期将数据送到 MEM/WB 寄存器,然后在 t + 1 t+1 t+1 周期 EX 段采用 MEM/WB 的内容作为操作数。重定向不能跨越两个段,举个经典例子,比如下面的指令——我一开始想的是这两条指令之间不插入气泡(即不停顿),当 DSUB 在 EX 的时候,BNEZ 恰好在 ID 段。我想在一个时钟周期内,EX 的运算器计算出 R4 的结果,并当场重定向到 ID 段进行分支判断。实际上这是不行的,重定向跨了两个段,必须要将 CPU 的时钟频率降低,否则在这个例子中可能导致 ID 段任务没完成,引发错误。
DSUB R4,R3,R2 BNEZ R4,LOOP注意在这种情况下,RAW 的消费者指令未必就是等在 IF 段了。因为就算 ID 段读出来错误的数据,依然是可以通过 EX 段的重定向通路替换操作数,从而解决问题;但是如果是 EX 段根据错误的操作数得到了错误的结果,那么再用重定向去修复就很啰嗦了。所以这种情况一般都是等在 ID 段。具体来说:
- 对于大多数指令:实际上都是停在 ID 段。需要等待引发冲突的寄存器内容被计算出来,然后下一个周期便可重定向。
- 对于分支指令:分支指令是比较特殊的,可以认为它在 ID 段获得执行。如果让它停在 ID 段,那么 ID 段错误的寄存器内容会引发错误的分支行为,之后彻底不可挽回。所以分支指令必须等在 IF 段。
但是什么时候可以继续往后流动,这里的说法就有点复杂。下面对生产者指令的类型进行分类讨论:
- 生产者指令是访存指令(实际上就是 load 指令,因为 save 指令不会引发 RAW 冲突)。等生产者指令到达 MEM 段,之后可以正常流动。
- 生产者指令是其它有关寄存器运算的指令。等生产者指令到达 EX 段,之后可以正常流动。
在这种情况下(有重定向机制),是否需要特别注意“第 i i i 和 i + 1 i+1 i+1 条指令无冲突,第 i + 1 i+1 i+1 和 i + 2 i+2 i+2 条指令也是无冲突,但 i i i 和 i + 2 i + 2 i+2 存在冲突”的情况?确实需要注意,不过这种情况 i i i 如果阻塞了 i + 2 i+2 i+2,那么指令 i i i 必然是 load 指令,指令 i + 2 i+2 i+2 必然是分支指令。因此大多数情况下貌似都不会发生阻塞。
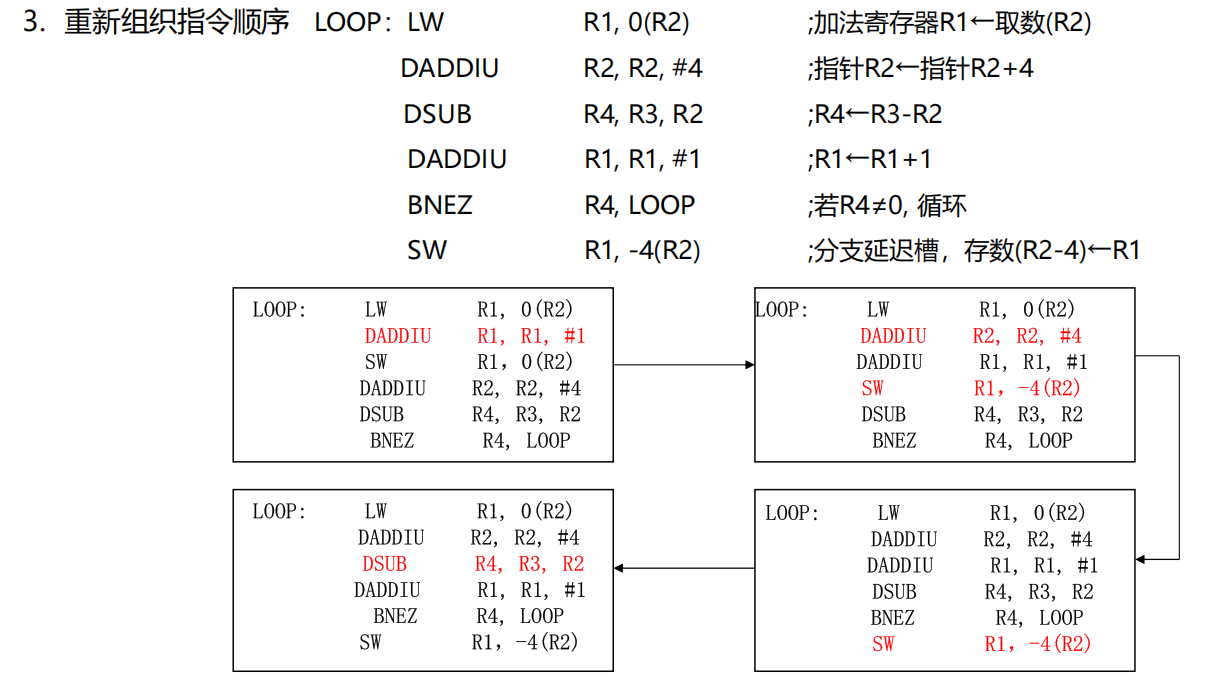
根据上面的讨论,可以判断某个指令是否要被阻塞,在哪个段被阻塞,以及何时可以让它继续流动。当它被阻塞时,时空图对应的地方填一个“S”表示 stall。然后我们就可以看下面这道题。

(1)显然,我们可以找出这么几对有数据冲突的生产者-消费者指令对:(1 LW,2 DADDIU),(2 DADDIU,3 SW),(4 DADDIU,5 DSUB),(5 DSUB,6 BNEZ)。这些指令对中,消费者指令都需要进行相应的等待。同时注意这里“排空流水线”的策略,意思是只要有分支的产生,必然会带来一个额外的时钟周期开销(因为默认顺序取指)。因此可以轻松得到答案。

(2)现在有重定向的通路,我们分析(1)中获得的 4 4 4 个生产者-消费者指令对:
- (1 LW,2 DADDIU):LW 是访存指令,到达 MEM 段后,可以允许流水线正常流动。DADDIU 不是分支指令,停在 ID 段。
- (2 DADDIU,3 SW):DADDIU 不是访存指令,到达 EX 段后,可以允许流水线正常流动。SW 不是分支指令,停在 ID 段。
- (4 DADDIU,5 DSUB):DADDIU 不是访存指令,到达 EX 段后,可以允许流水线正常流动。DSUB 不是分支指令,停在 ID 段。
- (5 DSUB,6 BNEZ):DSUB 不是访存指令,到达 EX 段后,可以允许流水线正常流动。BNEZ 是分支指令,停在 IF 段。
答案就是这样的,所以我们的总结还是很有普适性的。

(3)这种重新组织指令顺序的,一般只需要减少运行时间即可,没有必要达到最优的效果。一般自己多试一试,就能找到一种合理的答案。
Chapter7 存储系统
存储系统性能指标计算题
是考试喜欢考的一种题型,往往会给你两种 cache,给你一系列数据,要你比较两种方案的优劣。题目一般会问你两个指标:
- 平均访存时间:就是一次访存的期望时间。
- CPU 性能:一般就是计算 CPU 时间,CPU 时间短的性能会越好。注意计算 CPU 时间时需要知道 IC(指令条数),但题目一般不会给,所以我们在 CPU 时间的最终计算结果里要保留 IC 这个因子。
有一个自查的方法,一般上面这两种指标的计算结果,一种指标表示方案 A 更好,另一种指标表示方案 B 更好。而我们最终选取哪个方案,还是得看 CPU 性能。
下面给一个例题分析一下。

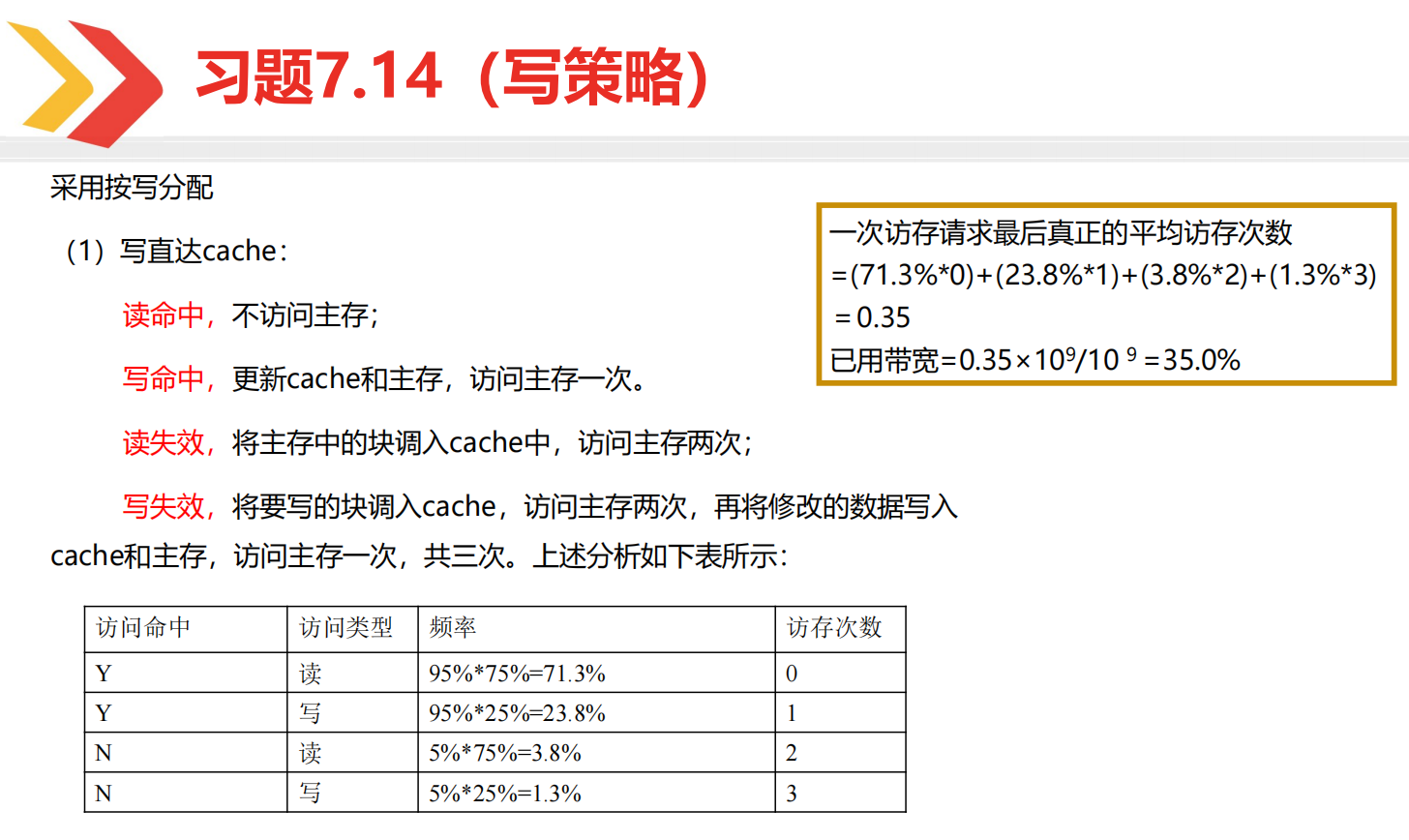
(1)计算平均访存时间。
不用死背公式,我们可以自己推的。你想,CPU 要访存首先去 cache 看,这里会有一个时间开销(命中时间)。如果 cache 命中了,那么访存总时间就是这个命中时间;如果没有命中,那就是命中时间再加上不命中开销。所以我们自然而然就推出来了:
平均访存时间 = 命中率 × 命中时间 + 不命中率 × ( 命中时间 + 不命中开销 ) = ( 命中率 + 不命中率 ) × 命中时间 + 不命中率 × 不命中开销 = 命中时间 + 不命中率 × 不命中开销 \begin{aligned}平均访存时间&=命中率\times命中时间+不命中率\times(命中时间+不命中开销)\\&=(命中率+不命中率)\times 命中时间+不命中率\times不命中开销\\&=命中时间+不命中率\times不命中开销\end{aligned} 平均访存时间=命中率×命中时间+不命中率×(命中时间+不命中开销)=(命中率+不命中率)×命中时间+不命中率×不命中开销=命中时间+不命中率×不命中开销 那么答案就很显然了。
- 直接映象平均访存时间: 2.0 + 1.4 % × 80 = 3.12 n s 2.0+1.4\%\times 80=3.12\rm{ns} 2.0+1.4%×80=3.12ns
- 二路组相联平均访存时间: 2.2 + 1.0 % × 80 = 3 n s 2.2+1.0\%\times80=3\rm{ns} 2.2+1.0%×80=3ns
(2)如何理解“理想 Cache 情况下的 CPI 为 2.0”这句话?实际上就是 cache 命中率为 100% 的时候的 CPI。所以这个 CPI 已经考虑了命中时间了,只需要在这个基础上再加上不命中开销即可。而 C P U 时间 = I C × 每条指令的执行时间 CPU时间=IC\times 每条指令的执行时间 CPU时间=IC×每条指令的执行时间。
- 直接映象每条指令执行时间: 2.0 × 2.0 + 1.2 × 1.4 % × 80 = 5.344 n s 2.0\times2.0+1.2\times1.4\%\times80=5.344\rm{ns} 2.0×2.0+1.2×1.4%×80=5.344ns
- 二路组相联每条指令执行时间: 2.2 × 2.0 + 1.2 × 1.0 % × 80 = 5.36 n s 2.2\times 2.0+1.2\times1.0\%\times 80=5.36\rm{ns} 2.2×2.0+1.2×1.0%×80=5.36ns
可以看到,平均访存时间说明二路组相联更好,而 CPU 时间又说明直接映象更好。我们最终还是选择 CPU 时间的标准,下结论直接映象更好。
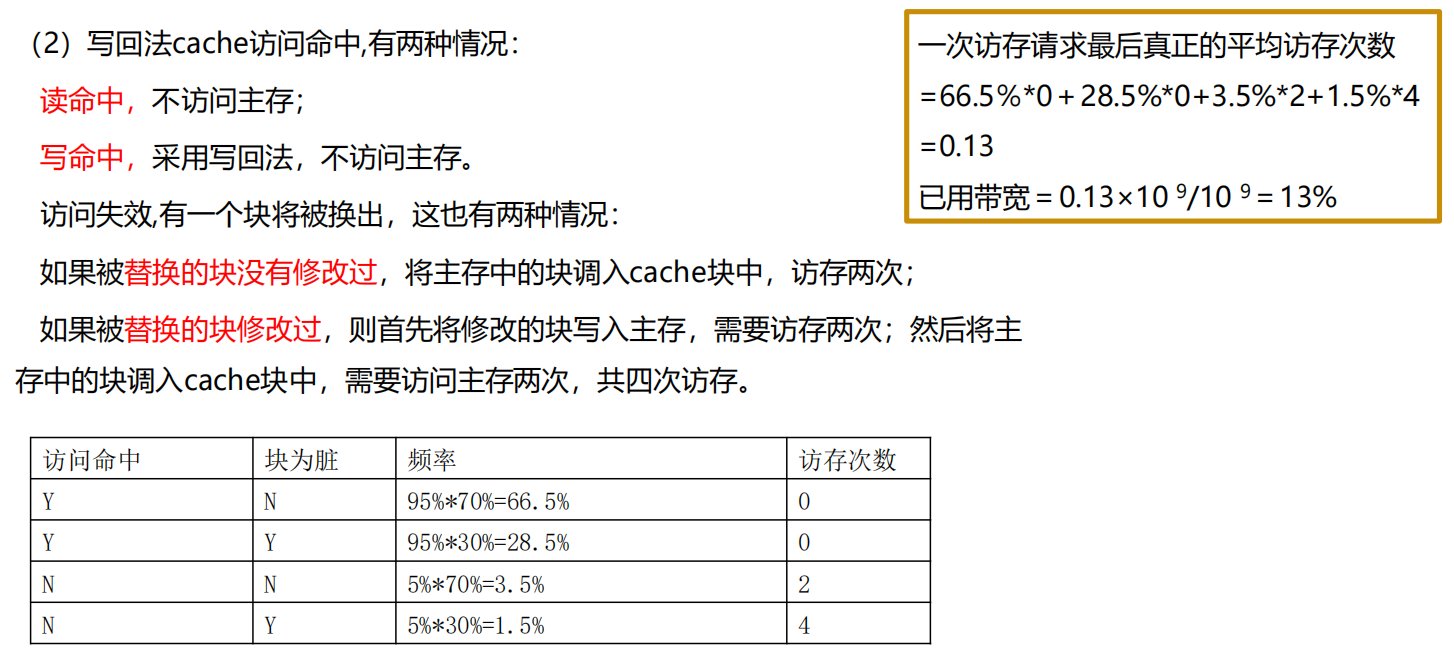
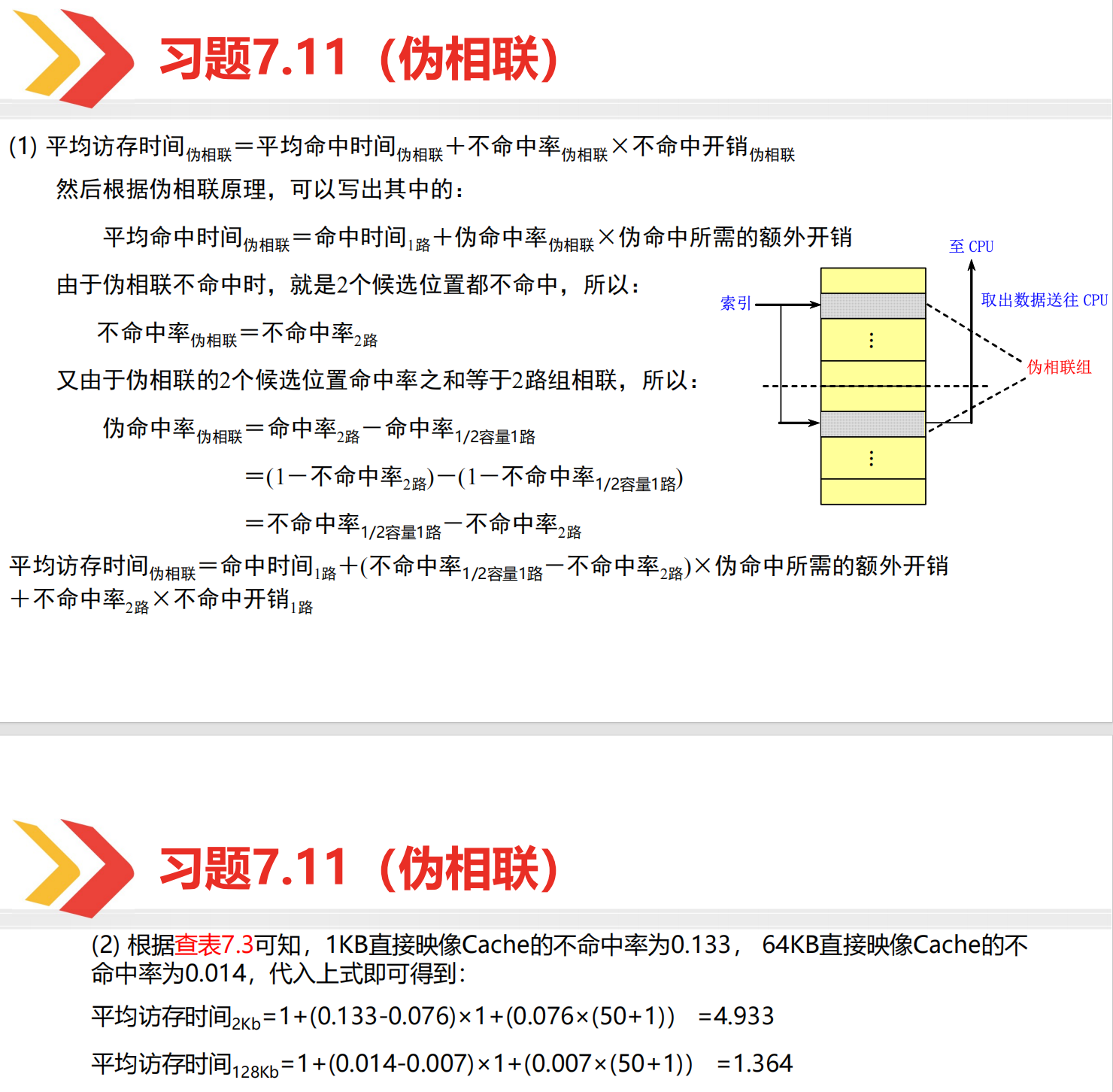
伪相联
伪相联的题目可以直接按照二级 Cache 的思想来做。在伪相联中,“正常命中”对应 L1-cache 命中,“伪命中”对应 L2-cache 命中。但是“正常命中”的概率和“伪命中”的概率分别是多少呢?很多时候,题目并不会直接告诉你这个,而是告诉你一些直接映象、二路组相联的 cache 的命中率。你可能会觉得这不是牛头不对马嘴吗,告诉我这些有什么用?
实际上我们可以用这些数据算得正常命中率和伪命中率。比如伪相联 cache 的容量是 2KB,那么这个 cache 其实分为两个 1KB 的部分:
- 正常命中率:正常访问就命中的概率。因为正常访问的 cache 容量是 1KB,伪相联又是按照直接相联的方式去把数据映射到这 1KB 的容量里面的,所以这个直接命中率就对应 1KB 直接相联 cache 的命中率。
- 伪命中率:在伪相联部分的 1KB 中找到数据的命中率。试想在正常访问的 1KB 中没有找到数据,现在又跑到另一个 1KB 的地方去寻找数据,并最终命中的概率。这是不是像极了 2KB 的二路组相联?所以整个伪相联 cache 中找到数据的概率应该就是 2KB 二路组相联的命中率。那么数据正常访问不命中、伪命中的概率就是这个“2KB 二路组相联命中率”减去“1KB 直接相联 cache 的命中率”。
具体可以参考这个例题。

答案:
写策略
首先要弄懂写策略和写分配策略是不同的概念。
-
写策略:当 CPU 发出“写”请求的时候,究竟是写到 cache 里面(写回法)还是直接写到主存里面(写直达法/写穿法)。
注意当采用“写直达”法时,如果 CPU “写”的对象在 cache 里也是存在的,那么 CPU 还需要把数据写到 cache 中。
-
写分配策略:当 CPU 发出“写”请求的时候,cache 里面没有对应的主存内容,是否需要将主存的相应块先加载到 cache 中,然后再让 CPU 去写。因此产生了“按写分配”和“不按写分配”两种策略。
一般来说,写直达 cache 采用的是不按写分配,写回法采用的是按写分配。但是其实也可以不这样,比如写直达 cache 采用按写分配——这个时候先把主存的内容读到 cache 里面,然后 CPU 把内容分别写到 cache 和主存中。亦或者写回法 cache 采用不按写分配,这是不可能的,CPU 要写的时候你不把内容加载到 cache 里面来,CPU 写到谁身上去呢?
然后还有一个概念叫读分配策略,所有的 cache 都是按读分配的,意思是当 CPU 想要读取的内容在 cache 里面没有的时候,需要把主存中相应的内容加载到 cache 里面,然后 CPU 直接读 cache 就行了。如果不按读分配,那就不能算是 cache 了。
题目常常考察你什么时候 cache 和主存的内容要进行通信,通信的数据量是多少。假设一个主存块有 n n n 个字,每次 CPU 的读写请求涉及 1 1 1 个字。具体来说,有下面四种情况:
- 读命中:CPU 直接从 cache 中获取要读的数据,不访问主存。
- 写命中:更新 cache。
- 写回法:不访问主存。
- 写直达法:需要访问主存,将 1 1 1 个字写入主存。
- 读不命中:这种情况可能需要先淘汰其他 cache 块,然后再把主存块加载进来。
- 写回法:这种情况下 cache 是会存在脏数据的,题目一般会告诉你,cache 中百分之多少的块被修改过。假设这个比例为 p p p,那么在淘汰过程中,有 p p p 的概率需要往主存里写 n n n 个字(淘汰脏数据),有 ( 1 − p ) (1-p) (1−p) 的概率不需要访问主存(淘汰非脏数据)。然后,将需要读取的内容从主存块中加载进来,又要从主存里面读 n n n 个字。总而言之,这种情况下需要对主存读写 n p + n np+n np+n 个字。
- 写直达法:这种情况下 cache 里面没有脏数据,直接淘汰就好了。只需要从主存中读 n n n 个字到 cache 中。
- 写不命中:一般都是采用写分配法。
- 写回法:和读不命中一样,也是需要读写 n p + n np+n np+n 个字。
- 写直达法:首先从主存中读 n n n 个字,然后写 cache 和主存各 1 1 1 个字。需要对主存读写 n + 1 n+1 n+1 个字。
相对来说还是比较好理解的,可以参照这个例题。

答案: