[一文解决大模型微调+部署+RAG] LLamaFactory微调模型后使用Ollama + RAGFlow在Windows本地部署
1、LLamaFactory部分
1-1 LLamaFactory说明
LLaMA Factory 是一个开源的全栈大模型微调框架,简化和加速大型语言模型的训练、微调和部署流程。它支持从预训练到指令微调、强化学习、多模态训练等全流程操作,并提供灵活的配置选项和高效的资源管理能力,适合开发者快速定制化模型以适应特定应用场景。下面通过微调Qwen2.5-3B-instruct模型的示例来展示如何使用 LLaMA Factory 进行模型微调并部署至 Ollama。
1-2 环境搭建与配置
最好先创建虚拟环境,在虚拟环境中进行环境搭建与配置的操作(下面我创建了一个python版本为3.10的,名字叫llafac的虚拟环境)
conda create -n llafac python=3.10接着激活虚拟环境
conda activate llafac以下内容均在虚拟环境中完成:克隆 LLaMA Factory 的 Git 仓库,创建Python 虚拟环境并安装依赖。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics,gptq]"
安装完成后,在 Python 终端执行以下代码,检查 PyTorch 是否为 GPU 版本,如果不是则需要手动安装。
import torch
print(torch.__version__) # '2.6.0+cu126'
print(torch.cuda.is_available()) # True
在命令行中使用以下命令运行 LLaMA Factory。
llamafactory-cli webui
1-3 数据集准备
微调数据集使用医疗数据集FreedomIntelligence/medical-o1-reasoning-SFT · Datasets at Hugging Face,是使用 GPT-4o 构建的,给出可验证医疗问题的解决方案,并通过医疗验证器对其进行验证。微调模型使用阿里的 Qwen2.5-3B-instruct 模型。数据集示例:
[
{"Question": "哪种中药方剂最适合小儿使用,具有清热养阴、利水不伤阴、泻火不伐胃、滋阴不恋邪的特点?","Complex_CoT": "小儿要用的中药方剂,不仅得考虑到它的药效,还得温和不伤身体。\n\n哦,问题中提到的清热养阴、利水不伤阴、泻火不伐胃、滋阴不恋邪这些特点,咱们得好好找找。\n\n一想到这种方子,脑海中立刻浮现出那些既能清热又不损阴的方剂。\n\n知柏地黄汤这种感觉不太适合小儿用,太补了会不会不太行?\n\n竹叶石膏汤倒是不错,清热的同时还能生津,就怕不够治本。\n\n对小儿来讲,我们最好找那种针对性强一点的,药性又平和的。\n\n忽然想到六味地黄丸,它补阴又不怎么热,会不会合适呢?\n\n但是,这个方子主要是滋阴补肾,针对的是那种久病体虚的,不太符合我们的条件。\n\n得找个能即刻解决清热的问题,同时不用担心阴虚的方子。\n\n再翻一下常用的,有没有什么特别适合小孩子的呢?\n\n看到麦门冬汤,它滋阴又清热,是个不错的选择。\n\n不过,我们还需要那种能更全面解决问题,尤其是在泻火和利水上更有针对性的。\n\n要不再看看导赤散呢?它清热方面挺强的,特别是对清心火、利小便很有用。\n\n这倒是切合清热养阴而又不伤身体的思路。\n\n嘿,导赤散这似乎就是我们要找的!具备了清热、利尿而不损阴液的特点,这样小孩子才能用的更安心。","Response": "在考虑适合小儿使用的中药方剂时,您提到的几个方面都需要综合权衡。导赤散在这其中,确实是一种较为合适的选择。它以生地、木通、甘草和竹叶等药材组成,具有清心火、利水通便的作用,且不易损害阴液,非常适合用于小儿清热。\n\n导赤散有助于解决小儿因心火旺盛而引发的相关问题,同时也能温和地利水,不至于损伤肠胃。因此,它在满足清热养阴、泻火不伐胃、利水不伤阴的需求上,表现得较为平衡,是个不错的选择。\n\n当然,每个小儿的具体体质和病情都可能有所不同,使用任何方剂前应咨询专业中医师,以确保剂量和配伍合适于个体需要。"},{"Question": "一名17岁男性患者,经历受凉后出现咽痛、咳嗽、少量黏痰、发热、食欲不振和肌肉酸痛5天,经过4天青霉素治疗无明显疗效,胸片显示左下肺肺段性分布浸润灶,该患者最适合使用哪种药物进行治疗?","Complex_CoT": "这个17岁的小伙子,感冒之后,喉咙痛、咳嗽,还发烧,肌肉也疼。嗯,喝了四天的青霉素,居然没啥效果,看来得换药。\n\n看到他的胸片,左下肺有个浸润灶,这不太妙,看着像是非典型肺炎。非典型肺炎一般由支原体或衣原体引起,病毒也可能,不过我们更常见的是支原体。\n\n对了,如果是支原体引起的,那青霉素肯定不管用,得考虑换一种药物,比如大环内酯类抗生素,这类药对支原体非常有效。\n\n想想看,阿奇霉素或者克拉霉素怎么样?感觉效果不错呢,因为它们可以对付支原体。如果这样想,也许阿奇霉素是个好选择,因为它常用于这种情况。\n\n不过,慢着,回忆一下,当初我们学的时候,红霉素可是治疗支原体感染的经典药物,特别在青少年中常用。\n\n所以从理论和临床看,红霉素在这种情况下应该也行。考虑到这个小伙子是青少年,红霉素的安全性和效果都不错。\n\n嗯,对,选红霉素更合适。反正目前青霉素没效果,而红霉素在非典型肺炎,特别是支原体感染上是个可靠的选择。\n\n想到这里,红霉素应该是最适合他的,针对他的病情,应该是个明智的举动。","Response": "根据患者的症状和病史,他的感染可能是由支原体引起的非典型肺炎。由于患者在接受青霉素治疗后无明显好转,而青霉素对支原体感染无效,因此需要选择另一种更有效的抗生素进行治疗。大环内酯类抗生素,如阿奇霉素、克拉霉素和红霉素,是治疗支原体感染的常用药物。\n\n考虑到患者是青少年,红霉素是治疗支原体感染的经典药物,尤其常用于青少年患者,具有良好的安全性和疗效。因此,红霉素是这个17岁患者在这种情况下的合适选择。"}
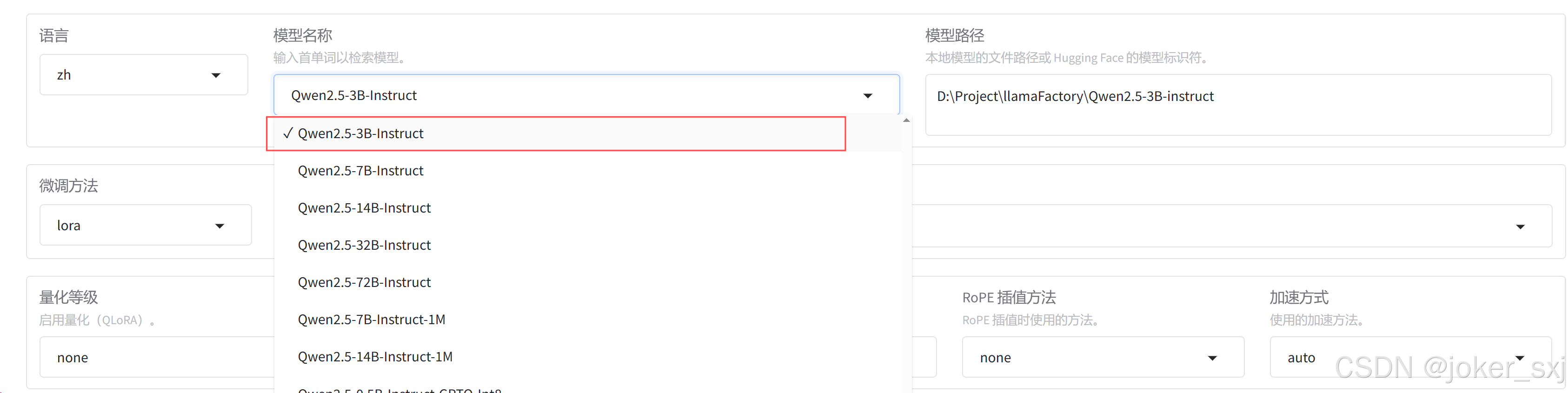
]模型在webui可以直接索引到,选择该模型就会在本地下载:
下载好的数据集还需要在 LLaMA Factory 中进行配置。LLaMA Factory 支持 Alpaca 和 ShareGPT 两种数据格式,分别适用于指令监督微调和多轮对话任务。
- Alpaca 格式:适用于单轮任务,如问答、文本生成、摘要、翻译等。结构简洁,任务导向清晰,适合低成本的指令微调。
{"instruction": "计算这些物品的总费用。","input": "输入:汽车 - $3000,衣服 - $100,书 - $20。","output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
}
- ShareGPT 格式:适用于多轮对话、聊天机器人等任务。结构复杂,包含多轮对话上下文,适合高质量的对话生成和人机交互任务。
[{"instruction": "今天的天气怎么样?","input": "","output": "今天的天气不错,是晴天。","history": [["今天会下雨吗?","今天不会下雨,是个好天气。"],["今天适合出去玩吗?","非常适合,空气质量很好。"]]}
]
数据集中的字段含义如下:
- instruction(必填):明确的任务指令,模型需要根据该指令生成输出。
- input/question(可选):与任务相关的背景信息或上下文。
- Complex_CoT(可选):思维链,说明input与output的联系
- output/response(必填):模型需要生成的正确回答。
- system(可选):系统提示词,用于定义任务的上下文。
- history(可选):历史对话记录,用于多轮对话任务。
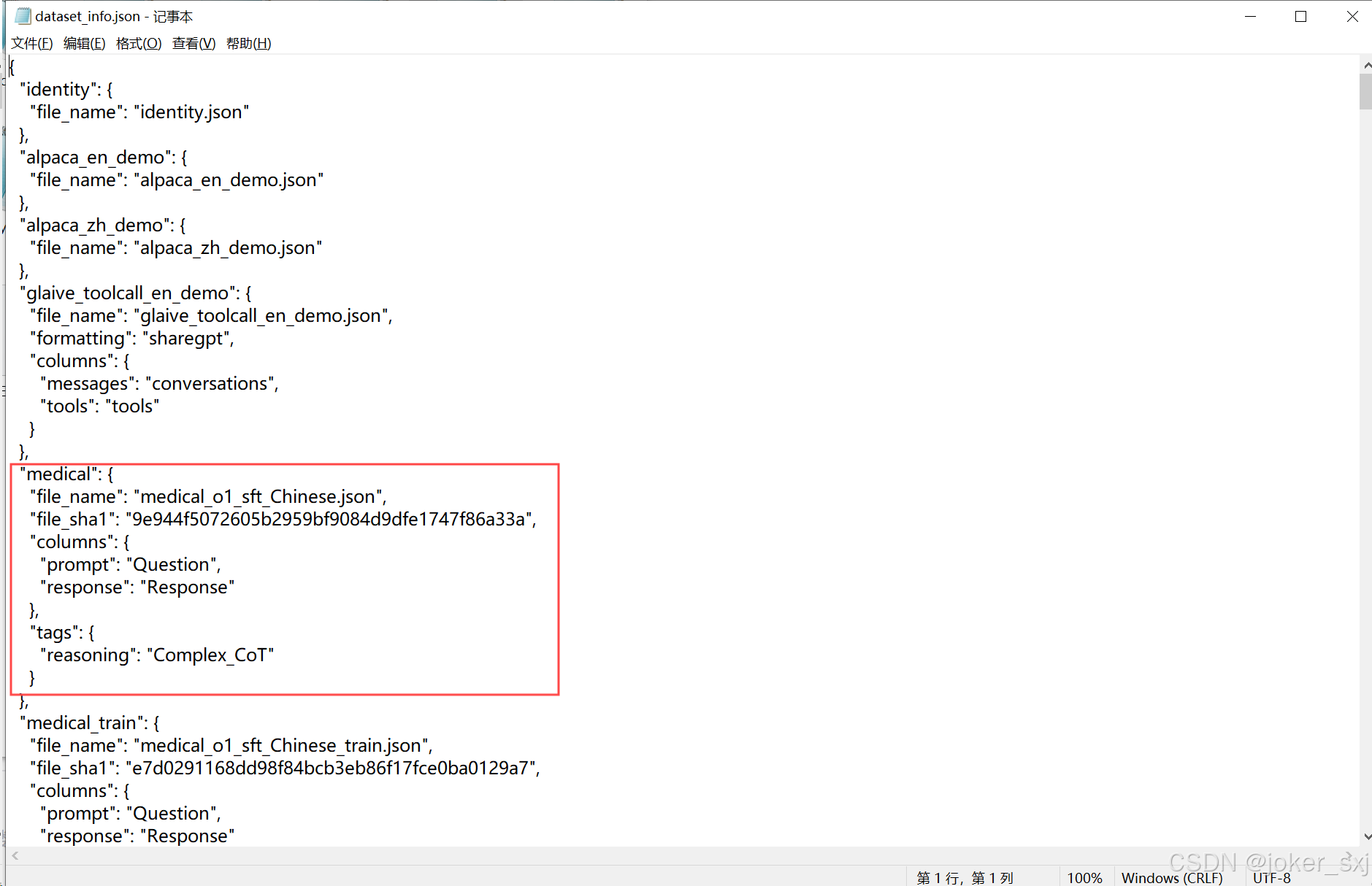
将下载好的 JSON 数据集放入 LLaMA-Factory/data 目录下,并在 LLaMA-Factory/data/data_info.json 中注册数据集。不过需要计算sha1编码,这里我给出工具SHA1 在线加密工具 | 菜鸟工具
1-4 WebUI 配置微调参数
访问 http://localhost:7860/ ,进入 LLaMA Factory 的 WebUI 界面。WebUI 主要分为四个界面:训练(Train)、评估与预测(Evaluate & Predict)、对话(Chat)、导出(Export)。
先设置页面上半部分的内容。
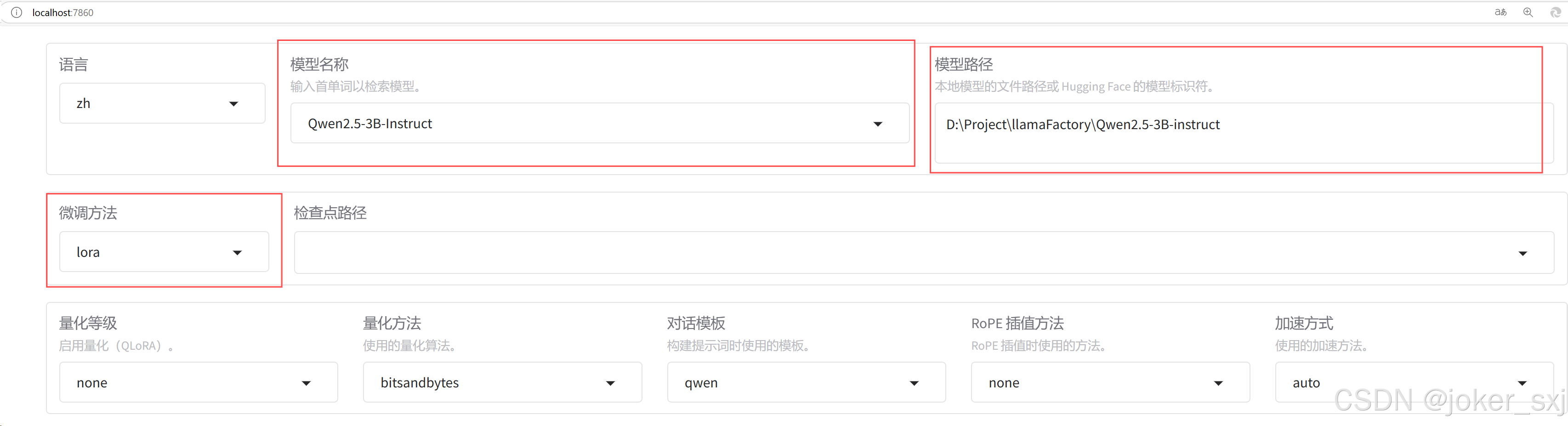
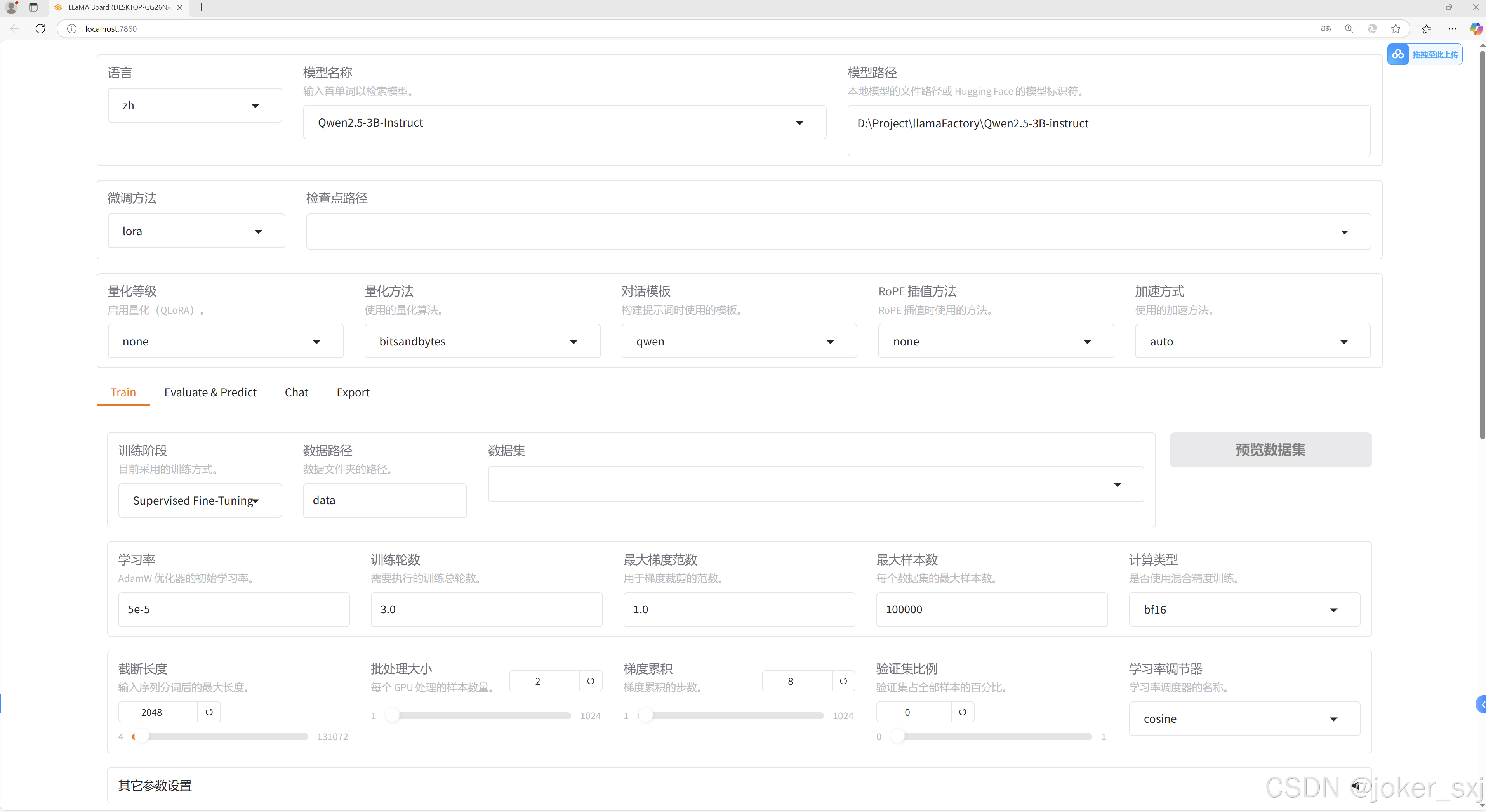
模型名称选择为待训练的模型名称,这里设置为 Qwen2.5-3B-Instruct。模型路径设置为上面下载的模型路径,例如在绝对路径 D:\Project\llamaFactory\ 目录下新建一个 Qwen2.5-3B-instruct 文件夹,将下载的模型移动到此文件夹内。微调方法支持 lora/freeze/full 方法,这里选择 lora 方法,其他方法对计算机配置要求较高,对个人电脑来说一般不适用。
- LoRA(Low-Rank Adaptation):通过在模型的某些层中添加低秩矩阵来实现微调。
- 全量微调(Full Fine-Tuning):对模型的所有参数进行微调。
- 冻结微调(Freeze Fine-Tuning):冻结模型的某些层或全部层,仅微调特定的参数。
下面设置 Train 选项卡中的参数。
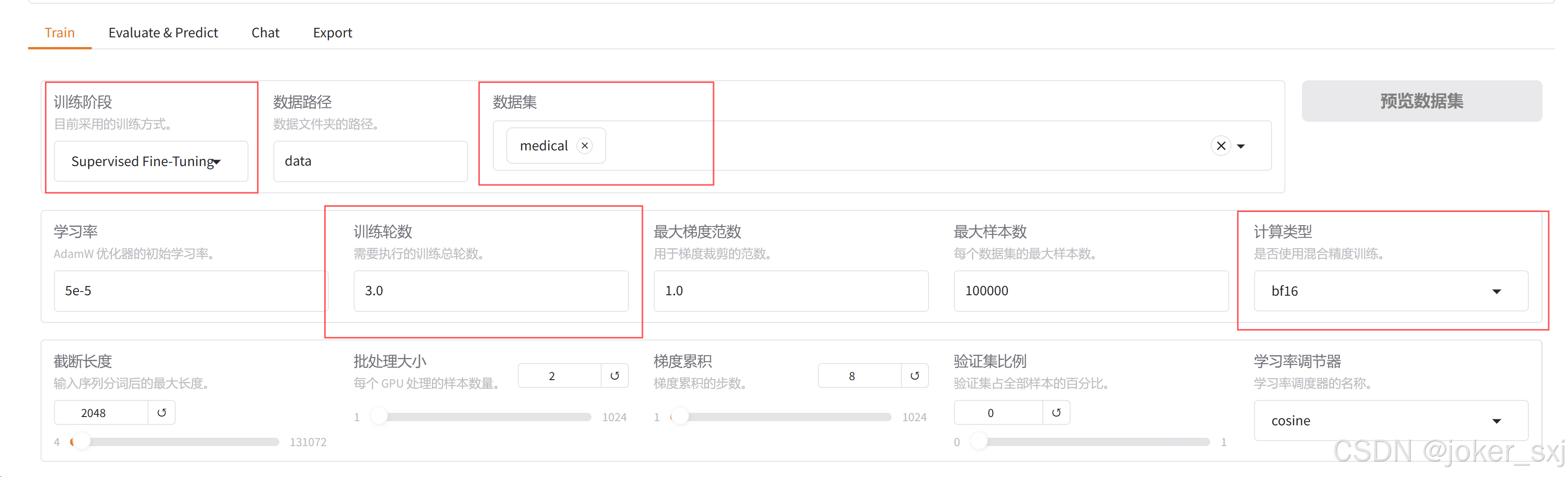
训练阶段设置为 Supervised Fine-Tuning。
- Supervised Fine-Tuning:监督微调是最常见的微调方法,使用标注好的数据对预训练模型进行进一步训练,以适应特定任务(如分类、问答等)。
- Reward Modeling:奖励建模是一种用于优化模型输出质量的方法,通常用于强化学习的上下文中。
- PPO(Proximal Policy Optimization):PPO 是一种基于强化学习的微调方法,用于优化模型的输出策略。
- DPO (Direct Preference Optimization):DPO 是一种基于人类偏好的直接优化方法,用于训练模型以生成更符合人类偏好的输出。
- Pre-Training:预训练是指从头开始训练一个大模型,通常使用大量的无监督数据(如文本语料库)。预训练的目标是让模型学习通用的语言知识和模式。
数据集选择上文注册的数据集名称,这里设置为 medical。训练轮次根据数据集大小调整,这里设置为 100。学习率通常设置为 1e-4 或 5e-5。计算类型设置为 bf16,如果你的硬件不支持,可以选择 fp16,基本上 2020 年之后的 GPU 都支持 bf16。
接着对 LoRA 参数进行设置。其中关键的参数是秩(rank),秩的大小直接影响模型的性能和资源消耗。秩越大,引入的可训练参数越多,模型对新数据的适应能力越强,但也增加了计算和内存的需求,可能导致过拟合。秩越小,引入的可训练参数较少,减少了计算和内存的需求,但可能不足以充分适应新数据,影响模型性能。可以从较小的值开始(如8、10、12),逐步增加,观察模型性能的变化。
参数配置好后,点击开始,即可进行训练。训练时可以观察右侧的损失曲线,曲线长时间不下降时,即可考虑退出训练。
模型训练好后,会保存至 LLaMA-Factory 的 saves 文件夹中。
1-5 模型导出与量化
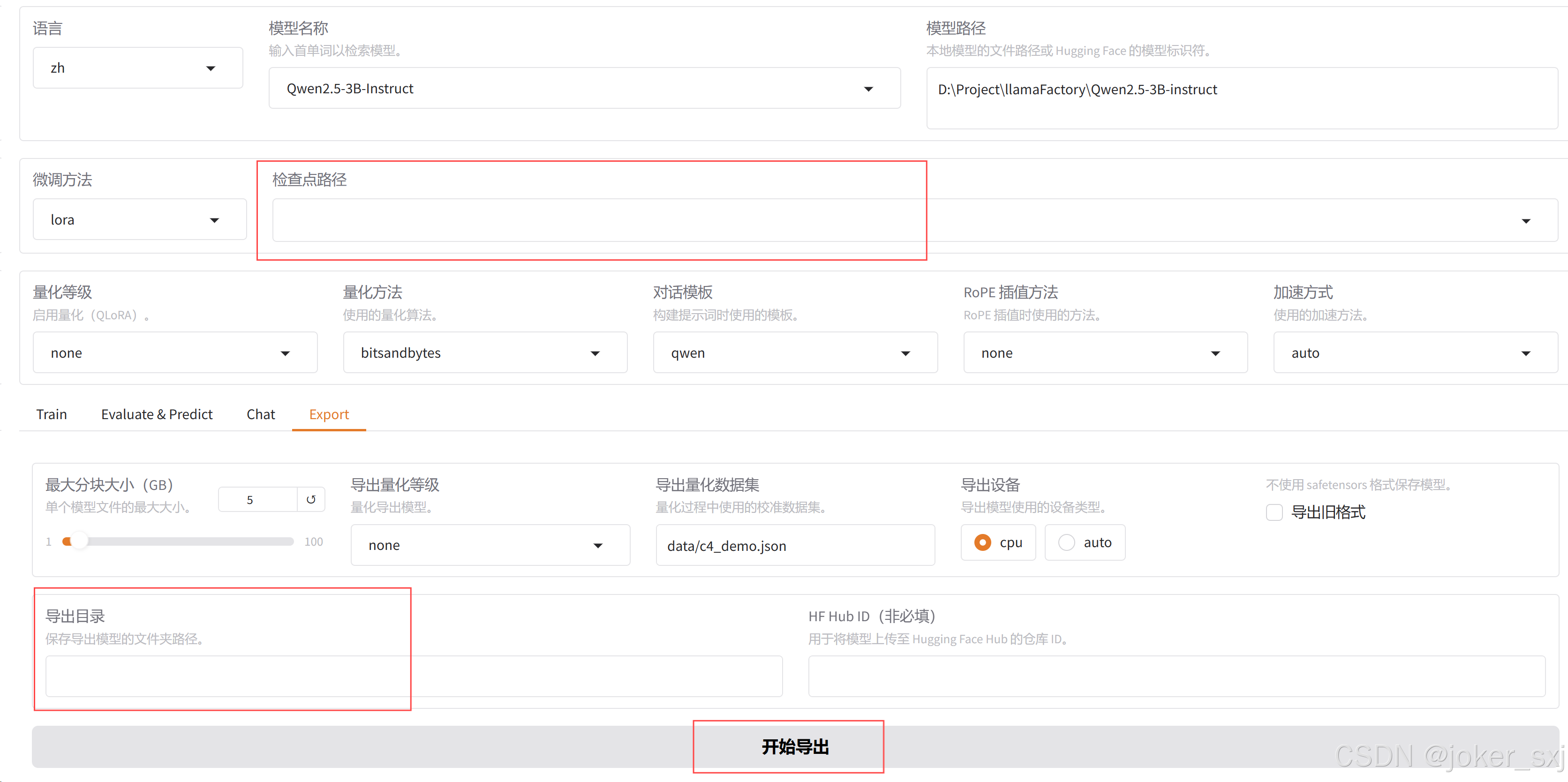
下面切换至 Export 选项卡,设置导出参数。补全检查点路径与导出目录,点击开始导出。到此为止,模型已经具备了使用能力。
大语言模型的参数通常以高精度浮点数(如32位浮点数,FP32)存储,这导致模型推理需要大量计算资源。量化技术通过将高精度数据类型存储的参数转换为低精度数据类型(如8位整数,INT8)存储,可以在不改变模型参数量和架构的前提下加速推理过程。这种方法使得模型的部署更加经济高效,也更具可行性。
量化前需要先将模型导出后再量化。修改模型路径为导出后的模型路径,导出量化等级一般选择 8 或 4,太低模型会答非所问。
2、Ollama部分
2-1 Ollama环境配置
Ollama默认模型文件是存到C盘的,这一步是为了后续Ollama的模型安装可以放在我们自定义的路径里,不需要的可以跳过这一步骤。
(1)打开编辑系统环境变量(可以直接搜索找到,也可以“此电脑”右键属性——高级系统设置)
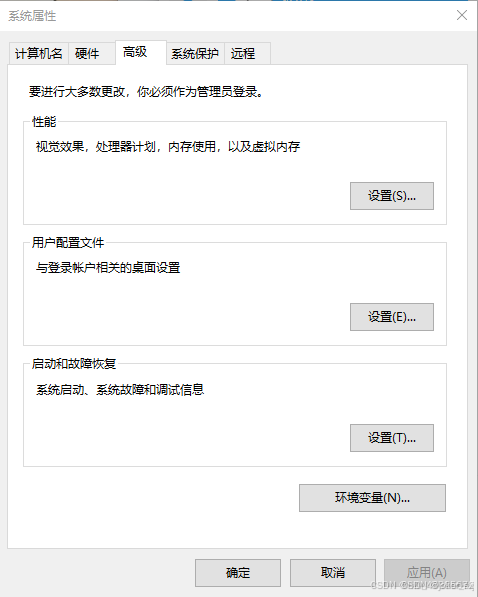
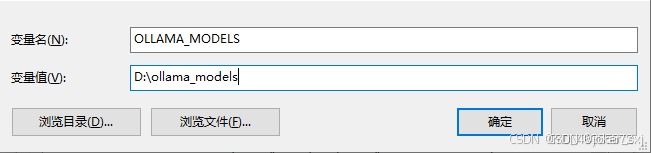
(2)点击“环境变量”,在下方的“系统变量”点击新建,新建如图系统变量后一路点总共三次确定结束(变量值可以自己选文件夹,变量名务必保持一致)
进入Ollama官网:Ollama,点击Download选择Windows下载,下载完成后直接双击运行安装就可以完成Ollama的安装
2-2 模型导入 Ollama
新版的 Ollama 可以直接导入 safetensors 模型,首先需要准备 Modelfile 文件。Modelfile 文件是一个文本文件,包含了模型的基本信息和配置参数。不过 LLaMA Factory 导出时也已经生成了 Modelfile 文件,直接使用即可。你也可以看看我的文档。
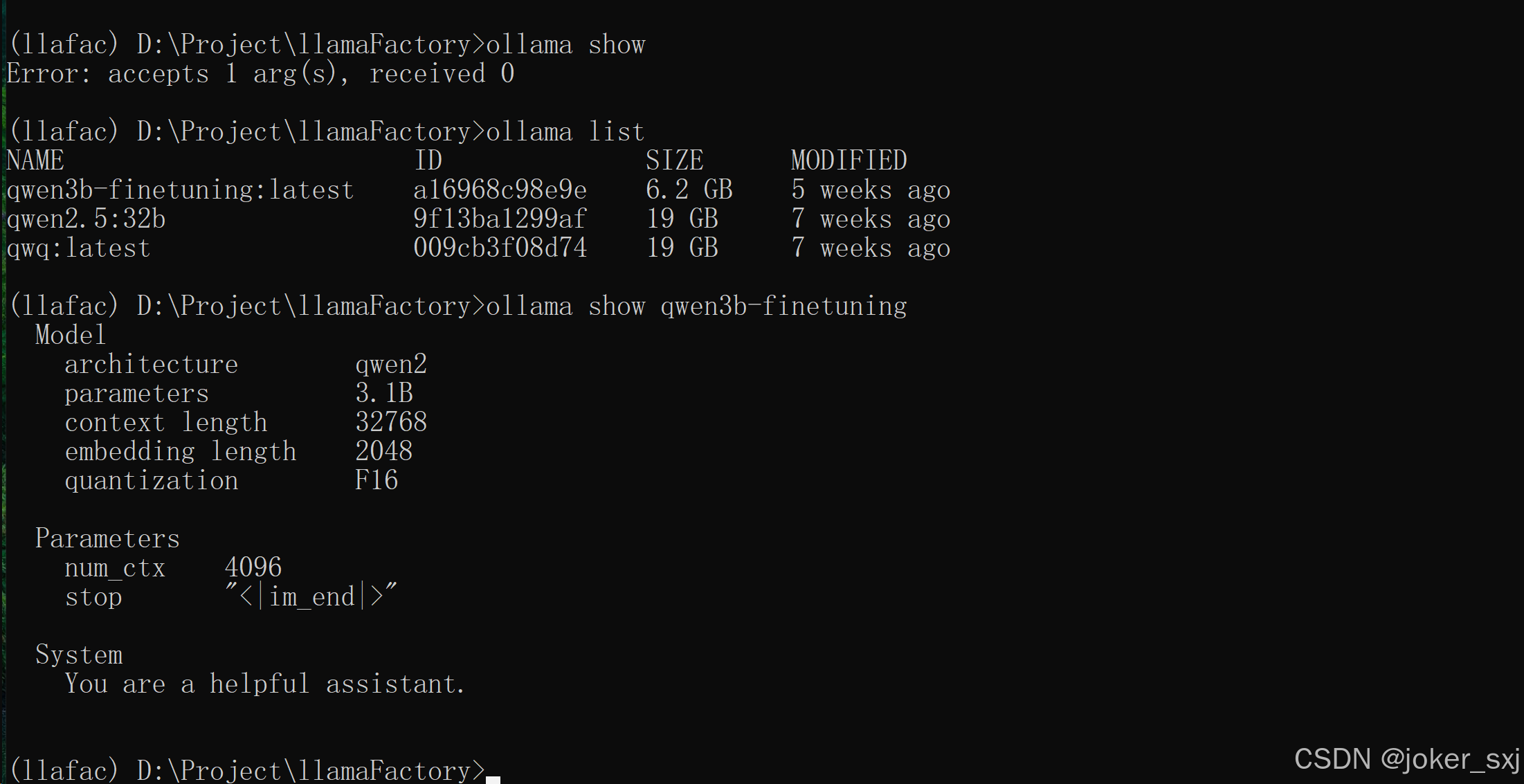
将命令行切换到导出模型的目录,执行下面的命令,导入模型。
ollama create qwen3b-finetuning -f Modelfile
最后运行微调前和微调后的模型,比较一下效果
ollama run qwen3b-finetuning
3、RAGFlow部分
3-1 docker desktop的下载安装
(1)进入docker官网:Docker: Accelerated Container Application Development,下载适合自己电脑的版本
(2)下载完成后双击installer完成安装
但是本人直接安装完的docker一直出现Engine stopped的提示,无法正常运行。
所以建议在运行docker安装前先检查自己电脑的hyper-v有没有正常打开,同时检查自己的WSL有没有升级到WSL2,确保Hyper-v打开和WSL升级到WSL2再运行docker installer,一般这样就能正常打开docker desktop了。
I、Hyper-v的打开
本人当时按这个教程(https://www.xitongzhijia.net/xtjc/20220102/237013.html)检查发现电脑根本没有Hyper-v
所以又先绕路安装了一下Hyper-v,参考博客:https://www.cnblogs.com/ZaraNet/p/11918807.html
II、WSL的升级
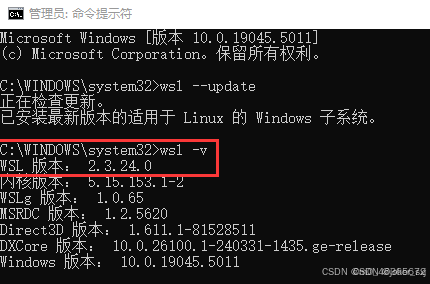
用管理员身份运行打开Power Shell,执行: wsl --update
系统就会开始自动升级到WSL2,升级完后可以执行: wsl -v 检查结果
Hyper-v和WSl2都正常的情况下运行刚刚下载的docker installer,“同意协议”后可以直接点击“continue without signing in”进入docker(当然也可以注册再登录,不过注册界面我总刷不出来),docker左下角显示“Engine running”代表正常
3-2 RAGFlow的拉取运行
git克隆仓库完成拉取
git clone https://github.com/infiniflow/ragflow.git
运行
cd ragflow/docker
docker compose up -d
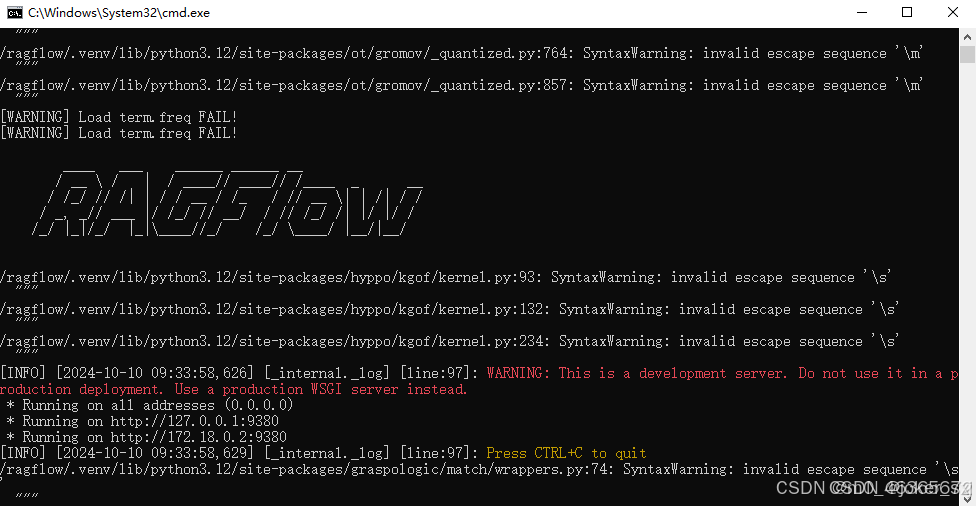
完成后运行检查服务器状态
docker logs -f ragflow-server
有类似下图输出并且无报错即可
此时docker中也可以看到容器正常运行起来了
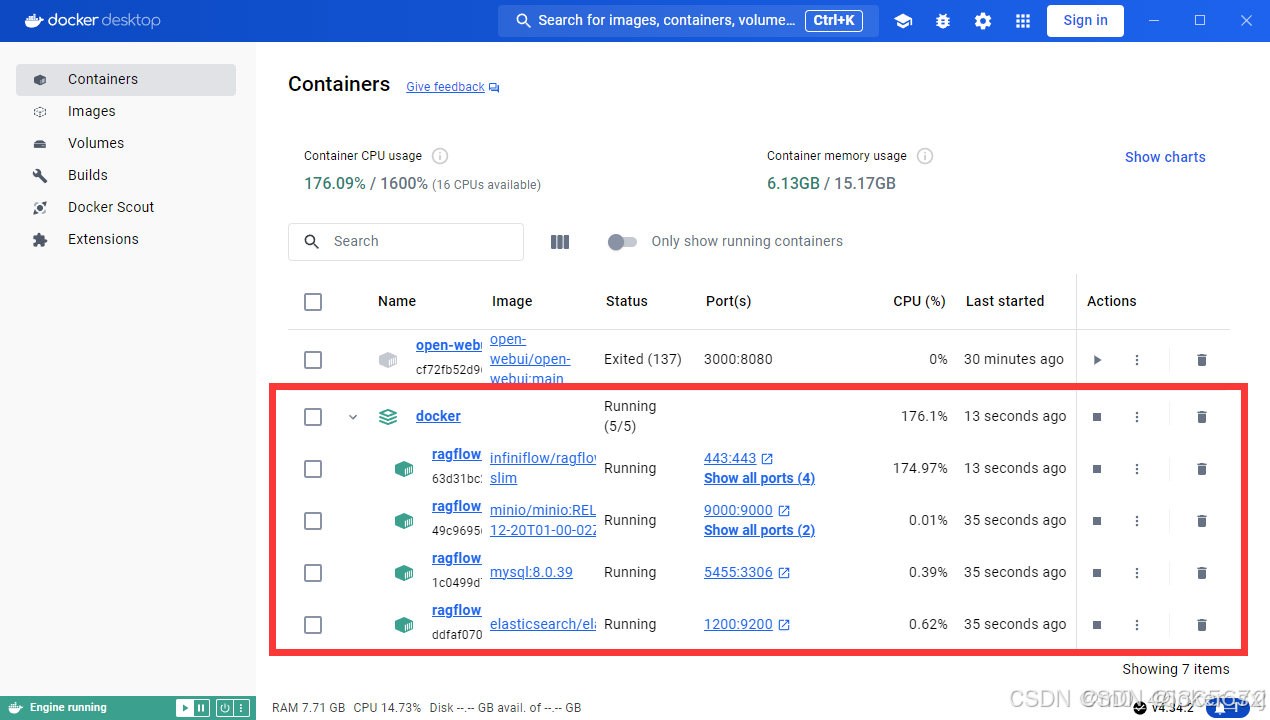
在浏览器网址栏输入localhost/knowledge即可访问RAGFlow开始使用
最后在RAGFlow的webUI界面注册登录,上传自己的数据集,加载本地ollama模型即可实现本地化部署运行。