DeepSeek实战--各版本对比
1.对比
| 版本 | 参数量 | 优势 | 劣势 | 使用场景 | 竞品 |
|---|---|---|---|---|---|
| DeepSeek-V3 | 6710亿(MoE架构,激活370亿) | 开源、高效推理(60 TPS)、低成本(API费用低)、中文处理能力突出(90%准确率 | 多模态能力有限 | 通用任务(聊天、编码、多语言翻译)、长文本处理、编程竞赛 | GPT-4o(通用性稍弱,但成本更低)、Claude 3.5 Sonnet |
| DeepSeek-R1(满血版) | 6710亿(全激活) | 复杂逻辑推理(数学、编程)、支持多模态、展示推理过程 | 部署成本高、推理速度慢、代码生成稳定性欠佳 | 科研前沿、决策支持、教育工具(如数学竞赛、密码解密) | OpenAI o1(推理能力接近)、Google Gemini Advanced |
| DeepSeek-R1(蒸馏版) | 1.5B–32B | 低成本部署、响应速度快、适合资源受限环境 | 推理能力弱于满血版,精度有所牺牲 | 企业客服、移动端应用(如智能家居)、实时交互场景 | GPT-3.5 Turbo(性价比更高)、Llama 2-7B |
| DeepSeek-V2 | 2360亿 | 中文能力领先开源模型、轻量化设计、训练成本低(GPT-4的1%) | 多模态支持有限、推理速度较慢 | 中文NLP任务(法律分析、医学研究)、多任务场景 | GPT-4(中文能力更强)、LLaMA3-70B(英文相当) |
| DeepSeek-VL | 10亿–45亿(多规格) | 多模态融合(图文联合处理)、小参数高性能 | 参数规模较小,复杂任务处理有限 | 视觉问答(VQA)、文档理解、OCR | LLaVA(性能更优)、GPT-4V(多模态能力更强) |
| DeepSeek-Coder | 670亿 | 代码生成准确性高(HumanEval通过率65.2%)、支持多编程语言 | 复杂推理能力弱于通用模型 | 代码补全、纠错、生成(软件开发、教育) | GitHub Copilot(功能相似但更灵活)、CodeLlama |
截止:2025/05/02
2.什么是蒸馏?
1)知识迁移机制
大模型蒸馏借鉴“师生教学”模式,教师模型通过输出软标签(概率分布)、中间层特征或注意力权重,指导学生模型的学习。软标签不仅包含类别信息,还传递类别间的关系,使学生模型能捕捉更复杂的决策逻辑。
- 软标签:教师模型输出的概率分布,通过温度参数(Temperature)调整平滑程度,增强学生模型对模糊边界的理解。
- 中间层对齐:模仿教师模型的隐藏层激活或注意力机制,提升学生模型的内部特征表达能力。
2)实施步骤
- 训练教师模型:先训练一个高性能的大模型(如GPT-4、DeepSeek-R1)。
- 生成软标签:用教师模型对训练数据推理,生成包含知识输出的软标签。
- 训练学生模型:结合软标签和真实标签,通过损失函数(如KL散度与交叉熵的加权组
合)优化学生模型。
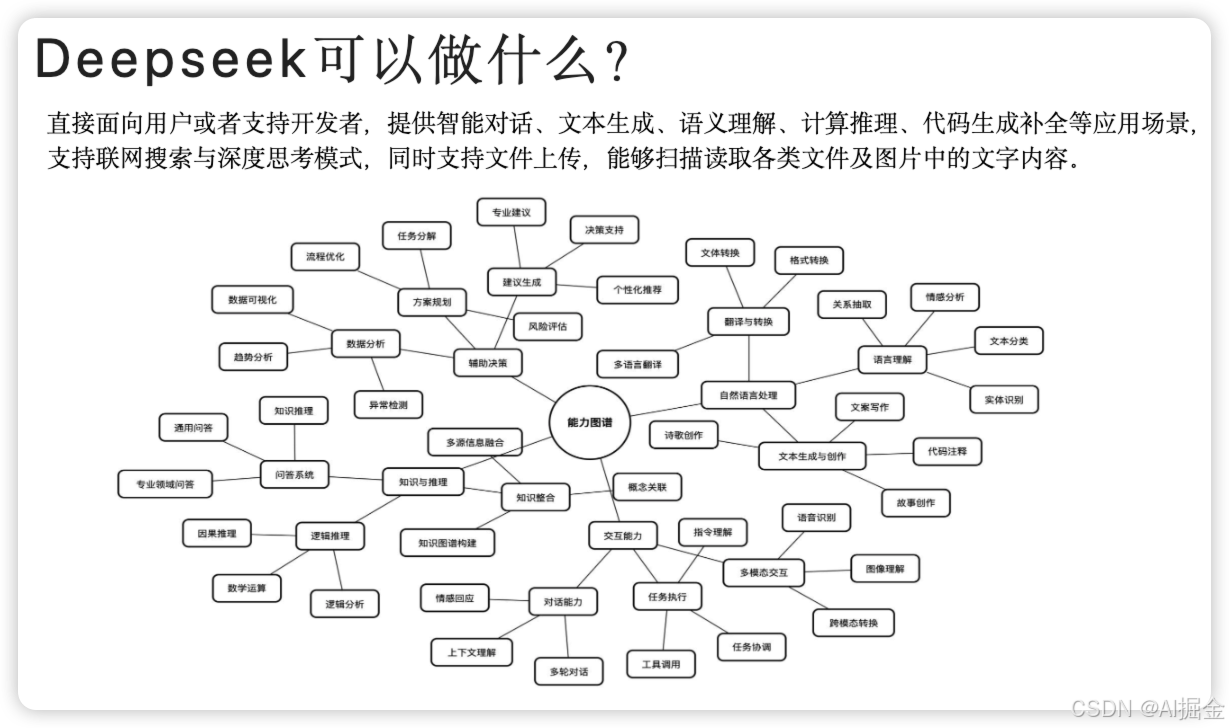
3.DeepSeek 可以做什么 ?
借用清华大学的总结,说明一下
链接:https://pan.quark.cn/s/3e804ec46889#/share/doc/560b7613c3f84a3c8c88baad0f25dbfd