进程与线程:05 内核级线程实现
内核级线程代码实现概述
这节课我们要讲内核级线程到底是怎么做出来的,实际上就是要深入探讨内核级线程的代码实现。
在前两节课中,我们学习了用户级线程和内核级线程是如何进行切换的,以及实现切换的核心要点。那两节课讲述的内容,是内核级线程和用户级线程切换在理论层面的样子,也就是其原理,核心在于栈的切换,是由TCB(线程控制块)引发的栈切换。而这节课,我们将重点聚焦于内核级线程的代码实现。
为什么这里主要强调内核级线程的代码实现呢?因为我们知道,进程实际上是由两部分组成的:一部分是资源,另一部分是执行序列,而执行序列实际上就是线程。由于进程必须进入内核,所以进程里的执行序列就是内核级线程。学会了内核级线程的代码实现,进程的代码实现就完成了大半,再加上资源管理(主要是内存管理)以及后面关于内存部分的内容,进程就可以在内核中,也就是在操作系统中得以实现。一旦完成进程在操作系统中的实现,一个完整的操作系统的雏形也就具备了。当然,要实现一个能完整运行的操作系统,你可以不支持内核级线程和用户级线程,但必须支持进程,因为只有支持进程,操作系统才能管理好CPU,否则就不能称之为操作系统。
简单来说,我们必须学会内核级线程的代码实现,再结合后面内存管理部分关于进程的代码实现,两部分结合,进程就能实现,而这就是整个操作系统框架中最核心的部分。我们一开始就说过,要具备编写一个基本操作系统的能力,所以这部分内容必不可少。
内核级线程实现原理回顾
接下来,我们看看内核级线程要实现代码编写,必须涉及哪些关键性代码。首先,再具体回顾一下,内核级线程要实现,在理论上应该是什么样的。
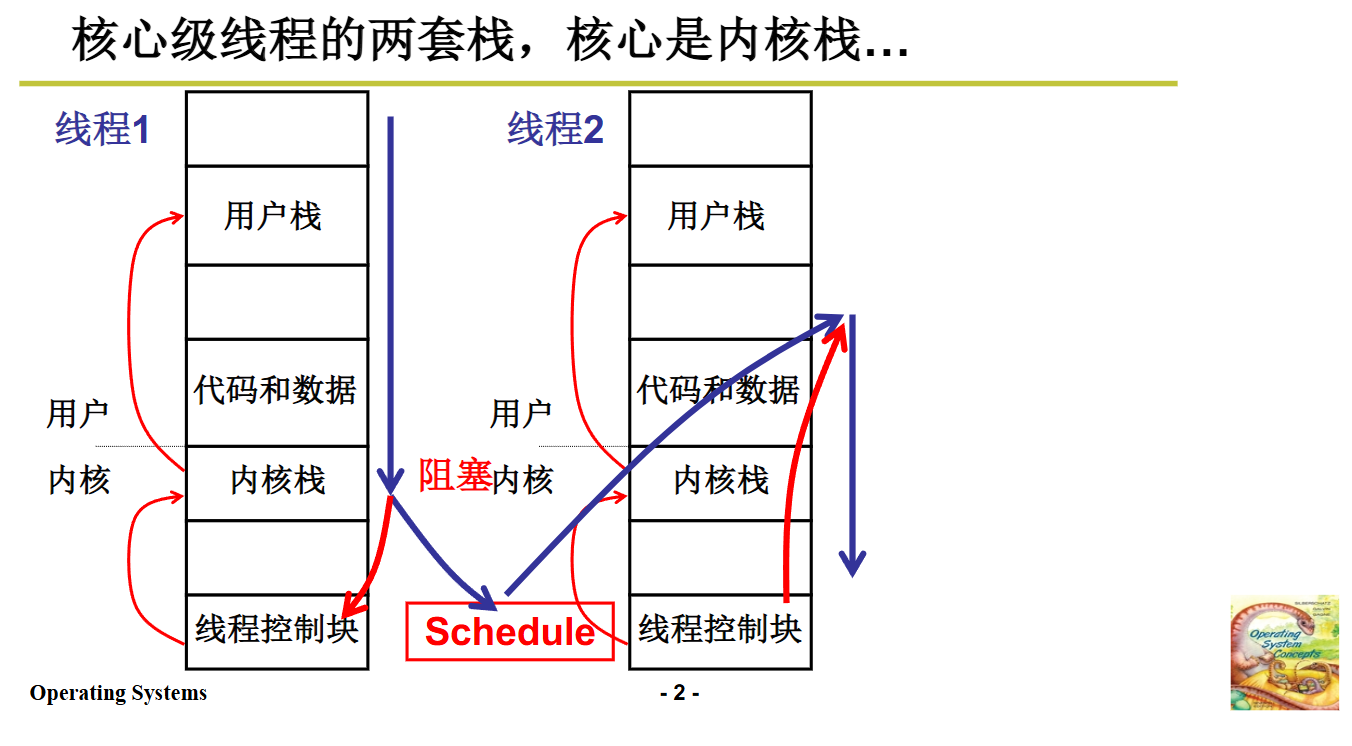
前面讲过,实现内核级线程的关键在于两套栈之间的切换。线程一旦进入内核,就使用内核栈,内核栈和用户栈通过int指令,经CPU解释后自动关联在一起。在内核中执行任务时,最终可能需要进行线程切换,也就是调度到另外一个线程去执行。
要调度到另一个线程,首先要进行TCB切换,线程控制块切换完成后,由于线程控制块里有内核栈的指针,所以内核栈也会随之切换。内核栈切换后,线程在内核栈上运行一段时间,处理完收尾工作,再通过iret指令,用户栈也跟着完成切换。
整个过程就是从用户栈到内核栈,再到TCB切换,然后内核栈切换,最后通过iret实现用户栈切换。从用户角度来看,他们看不到内核中这一系列操作,只感知到从一个栈到另一个栈的切换,同时对应的指令执行序列,即PC指针也会切换过去,整个过程包含五段,这就是我们所说的 五段论。这个图我反复讲过多次,希望大家牢记,只有在脑海中形成这个图像,后面的代码才能看懂,理解起来才会顺理成章。
以fork系统调用为例分析代码实现
选择fork的原因
接下来开始讲解代码。一个用户程序进入内核依靠的是中断,更具体地说是系统调用。当然还有其他中断,如键盘中断、时钟中断等,但这些离我们当前的内容较远,像fork这种由系统调用引起的中断更为常见,所以我们就从这个中断入手。
选择fork不仅因为它有可能引发线程切换,还因为fork是进入内核的操作,进程在内核中执行某些操作时,操作系统可能会判定当前进程不应继续执行而进行切换,比如执行到磁盘读写操作时。而且fork本身是创建进程的系统调用,进程由资源和执行序列组成,创建进程既要创建资源,也要创建执行序列,创建执行序列本质就是创建线程,所以fork对应的代码实际上就是创建线程的代码。从fork这个点切入,我们可以弄清楚两件事:一是线程如何切换,以及“五段论”在代码层面如何具体实现;二是创建一个内核级线程需要做哪些事情,是不是像前面说的,只要创造出能够切换的条件就可以。
中断入口:建立内核栈与用户栈关联
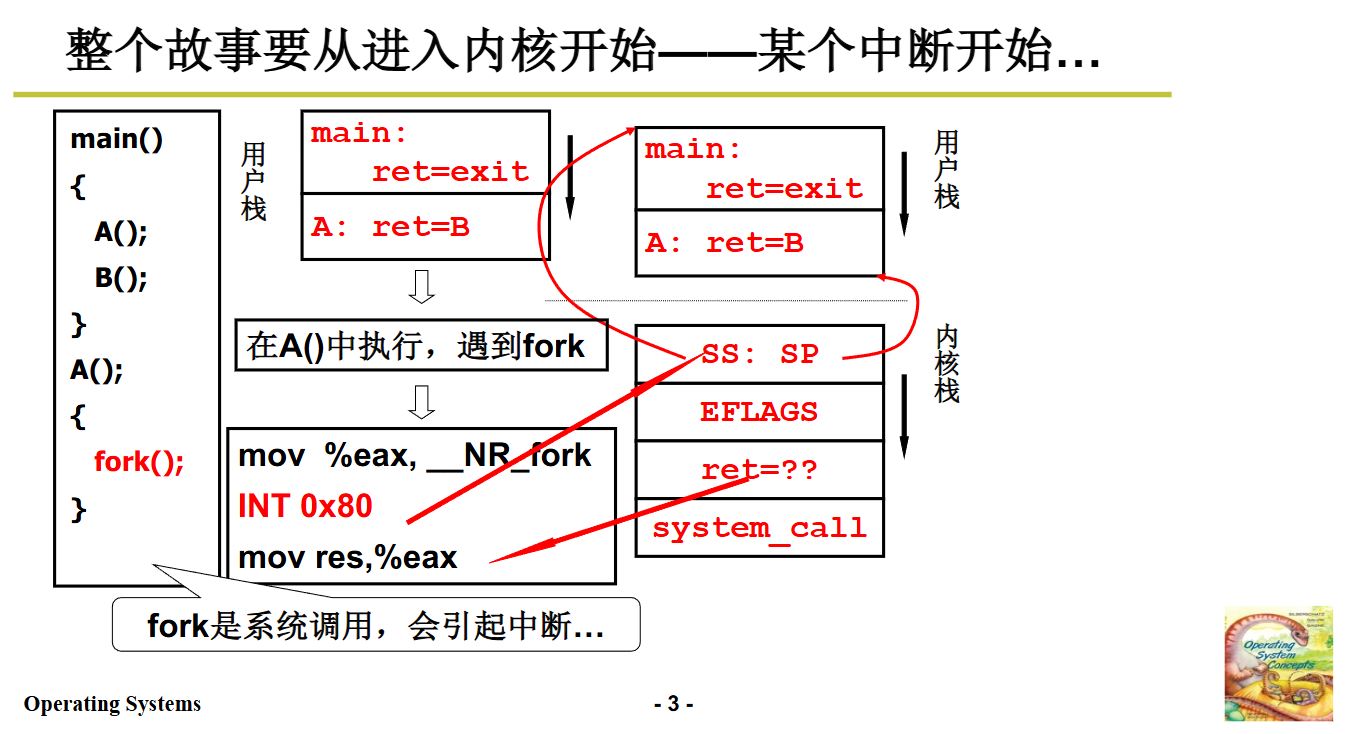
当用户程序执行到 fork 函数时,在代码层面,fork 会被编译成 int 0x80 指令。执行这条指令时,CPU 会自动进行一系列操作:找到当前的内核栈,并将当前的 SS(段选择子)和 ESP(栈指针),以及 CS(代码段寄存器)和 IP(指令指针)压入内核栈。此时,SS 和 SP 指向的是用户栈,因为 int 指令还未执行完,尚未进入内核态。这一步就完成了用户栈和内核栈的初步关联,也是 “五段论” 中的第一段。

紧接着,进入中断处理阶段,int 0x80 对应的中断处理函数是 system_call。在 system_call 函数中,还会进行一些压栈操作,目的是将用户态执行时的相关寄存器内容保存起来,以便后续能够从内核态返回到用户态时恢复现场。到这一步,用户态执行的相关信息都被保存在了内核栈中。
内核执行与调度判断
在完成上述操作后,会通过调用系统调用表(sys_call_table),进入到内核中具体处理 fork 的函数 sys_fork。在 sys_fork 执行过程中,可能会出现需要进行线程切换的情况。例如,当执行一些涉及 I/O 操作(如 read、write)的系统调用时,进程可能会因为等待 I/O 完成而被阻塞,此时就需要进行线程切换。在代码中,通过判断当前进程(current)的状态(state)来决定是否进行调度。如果 state 不为零(在 Linux 0.1 中,非零表示阻塞),就会调用 schedule 函数进行调度,这就涉及到了 “五段论” 中的中间三段。
调度与栈切换:中间三段的实现
当需要进行调度时,会执行 schedule 函数。在 schedule 函数中,首先会通过调度算法找到下一个要执行的进程(或内核级线程),这个过程我们会在后续专门讲解调度算法。找到下一个进程后,会执行 switch_to 函数来完成切换。
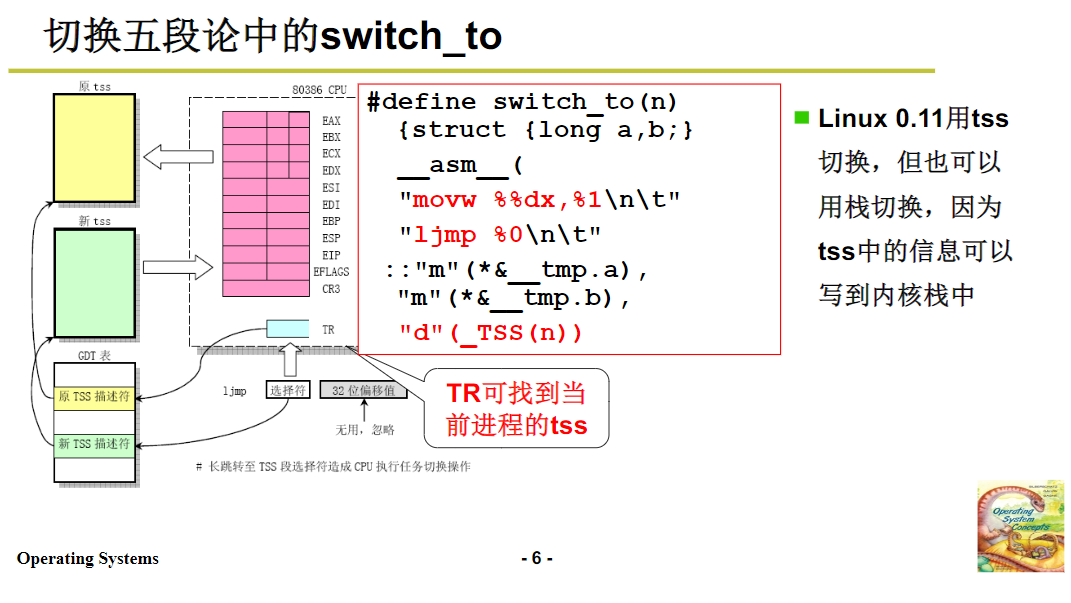
在 Linux 0.1 中,当前使用的切换方式是基于 TSS(任务段,Task Struct Segment)进行切换,不过我们实验的目标是将其改为基于内核栈的切换。基于 TSS 的切换,其原理是利用一条长跳转指令,通过修改任务段寄存器 TR 来实现。每个 TSS 段都有对应的描述符,TR 作为选择子,通过描述符找到 TSS 段。当执行长跳转指令时,会将当前 CPU 的所有寄存器状态保存到当前 TR 指向的 TSS 段中,然后将新的 TSS 段(对应下一个要执行的进程)的选择子赋给 TR,这样就完成了任务段的切换。由于 TSS 段中包含了 CPU 所有寄存器的信息,也就相当于完成了栈(ESP)和指令指针(EIP)等关键内容的切换,从而实现了线程的切换。但这种方式虽然代码编写相对简单,执行效率却比较低,这也是我们要进行改进的原因。
中断出口:完成用户栈切换
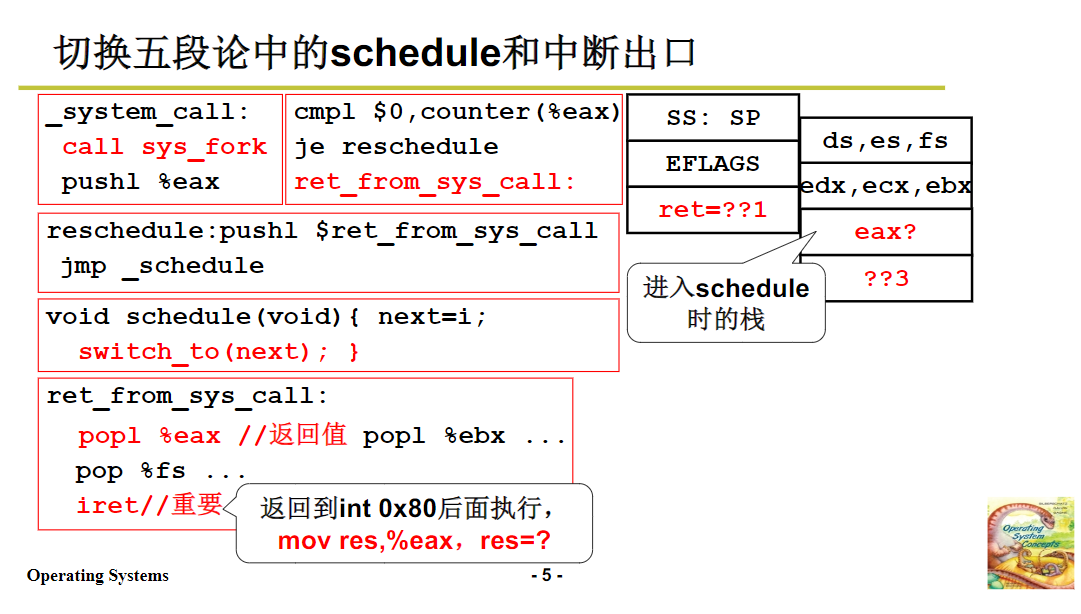
当调度完成,执行完 schedule 函数后,会返回到之前的调用点,接下来就到了中断返回阶段,这是 “五段论” 中的最后一段。在中断返回时,会执行一系列的 pop 操作,将之前保存在内核栈中的用户态寄存器内容弹出,恢复用户态的执行现场。最后执行 iret 指令,将内核栈中的 CS 和 EIP 弹出,切换回用户栈,完成整个线程切换过程,使得下一个线程能够从用户态继续执行。
fork 创建进程(线程)的具体实现
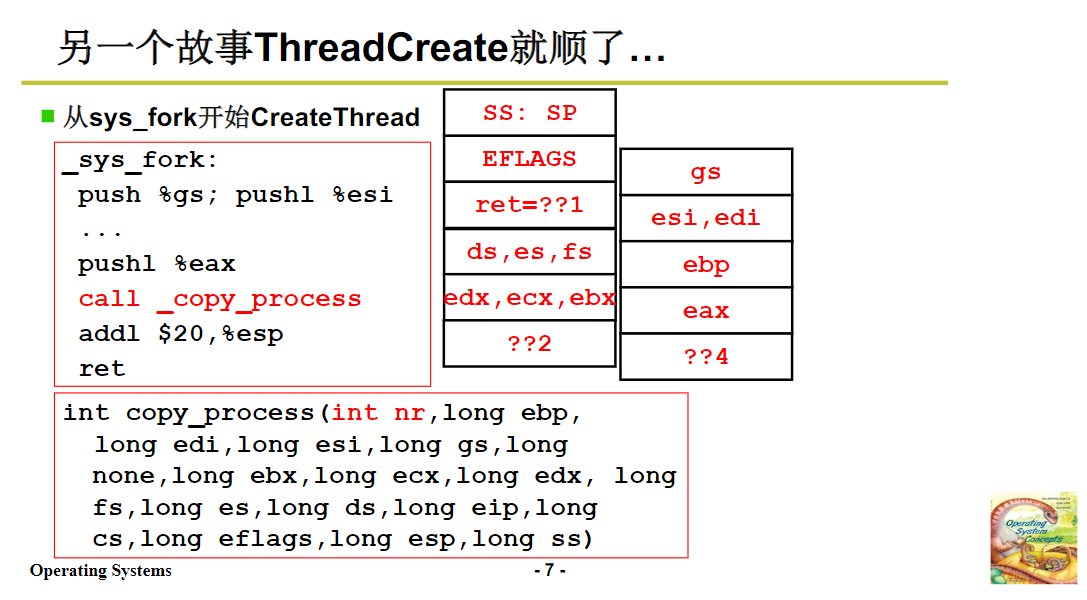
在 fork 执行过程中,调用 sys_fork 后,会进一步调用 copy_process 函数来创建子进程。copy_process 函数的参数来自于内核栈,这些参数包含了父进程在用户态执行时的相关信息,如 ESP(用户栈指针)等,通过这些参数,copy_process 函数能够创建出与父进程相似的子进程。
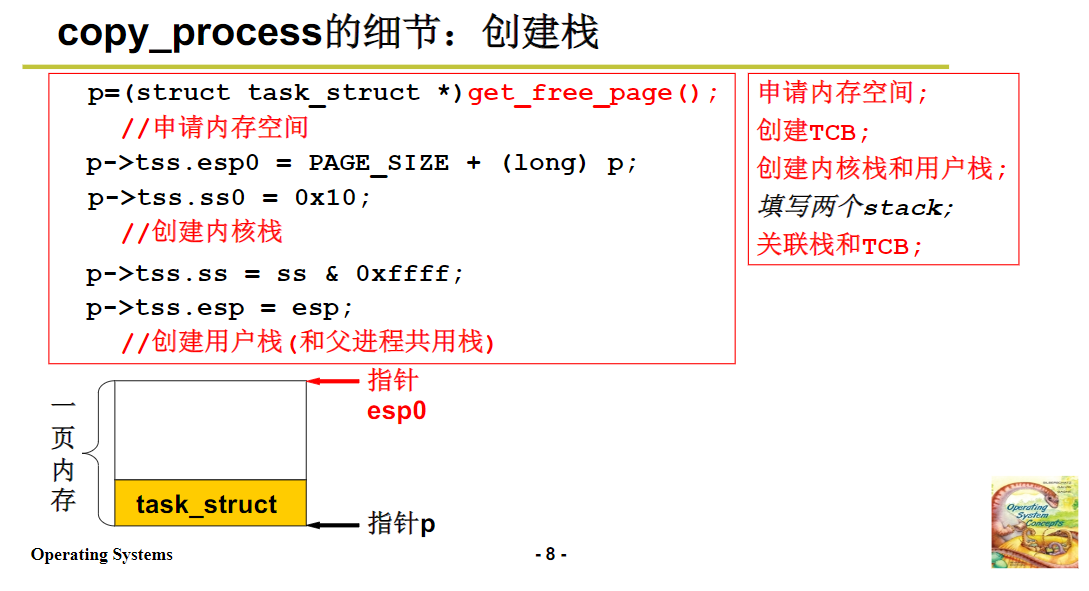
在 copy_process 函数中,首先会通过 get_free_page 函数获取一页内存,用于创建 PCB(进程控制块)。获取内存后,会进行一系列关键操作来设置 TSS:
设置内核栈: 将内核栈的栈顶指针设置为申请的内存页地址(p)加上 4K(PAGE_SIZE),即p + PAGE_SIZE,同时将内核数据段(这里内核数据段和内核堆栈段共用一个段)的选择子赋给 TSS 中的相关字段。
设置用户栈: 使用父进程传递过来的用户栈指针等信息,设置子进程的用户栈,使得子进程和父进程使用相同的用户栈(在用户态层面),但拥有独立的内核栈,这样在内核看来,它们是两个独立的进程(线程)。
关联与初始化: 通过这一系列操作,完成了 PCB、内核栈和用户栈的创建,并建立了它们之间的关联,同时也对 TSS 进行了初始化,为后续的线程切换做好了准备。
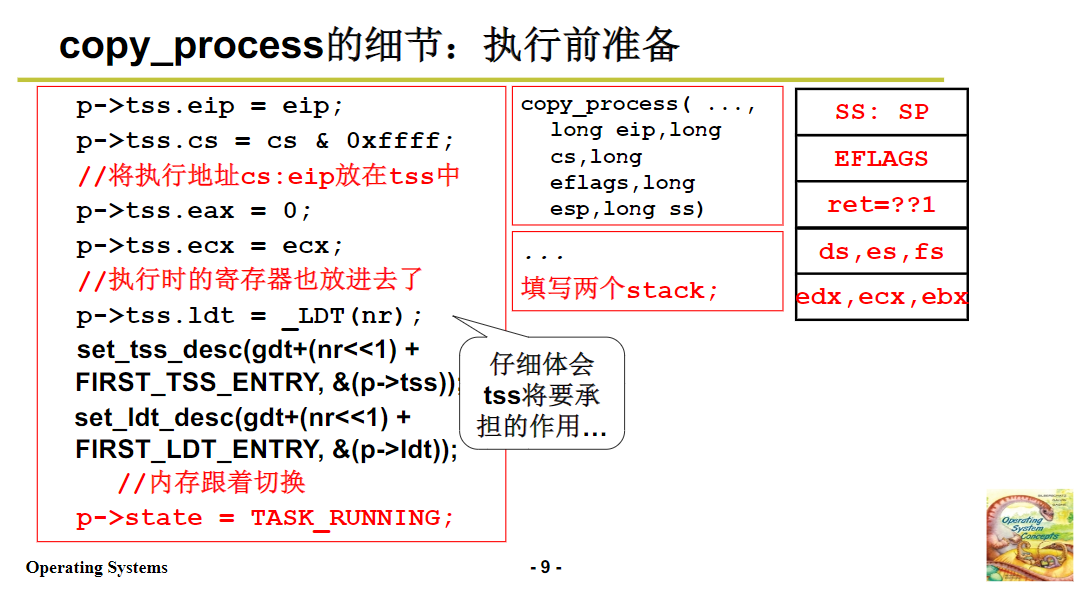
当子进程被调度执行时,通过 switch_to 函数,会将 TSS 中初始化好的内容加载到 CPU 寄存器中,其中 EIP 被设置为父进程中 int 指令执行完后的下一条指令地址,eax 被设置为 0(这是区分父子进程执行不同代码的关键)。这样,当子进程开始执行时,会根据 eax 的值(子进程为 0,父进程不为 0),执行不同的代码分支,从而实现了父子进程的不同执行逻辑,形成了 “叉子” 的两股。
exec 系统调用实现代码替换
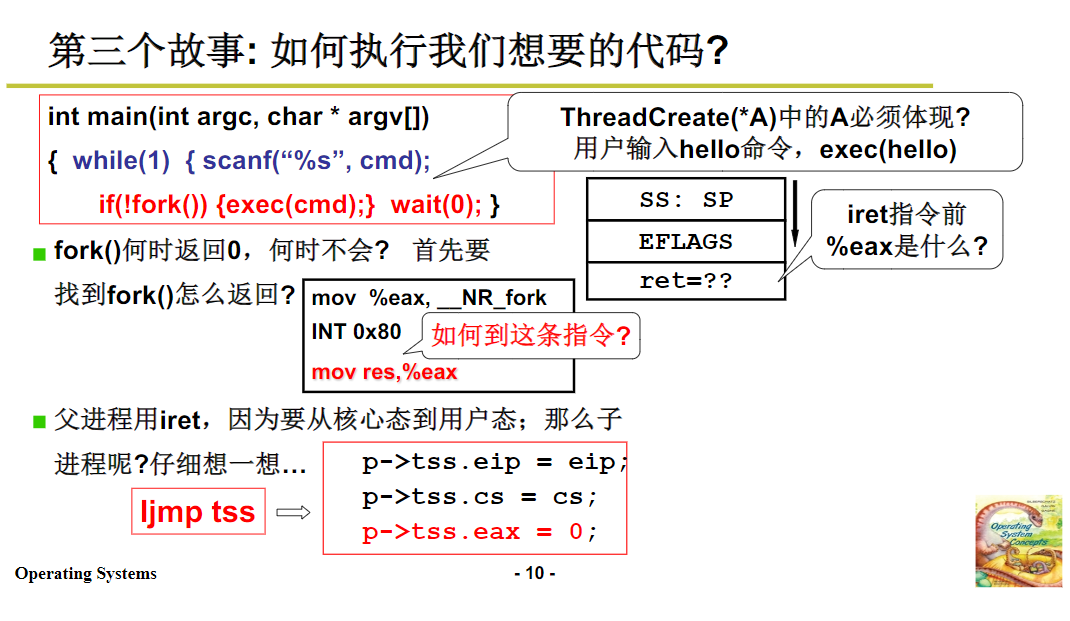
我们前面讲过,创建线程后,还需要让线程执行特定的函数。在 Linux 0.1 中,虽然不直接支持创建线程执行指定函数的功能,但进程执行时可以通过 exec 系统调用实现类似效果。
当调用 exec 系统调用进入内核后,在 exec 尚未执行实际工作之前,子进程和父进程执行的是相同的代码。而 exec 的作用,就是替换子进程的执行代码。那么它是如何做到的呢?


在 exec 系统调用对应的内核函数执行过程中,会进行一些关键操作。首先会进行压栈操作,压入的内容包括参数、当前栈指针(ESP)和一个偏移量(用于计算 EIP 地址)。通过将 ESP 加上特定的偏移量(如 0x1c,十进制为 28),可以得到要执行的新代码的入口地址(entry),将这个地址赋给 EIP。这个入口地址通常来自于可执行文件的文件头,是在编译和链接阶段写入的。在内核栈设置好相关内容后,当执行中断返回的 iret 指令时,会从内核栈中弹出 EIP 的值,赋给 CPU 的指令指针寄存器,这样 CPU 就会从新的入口地址开始执行代码,从而实现了代码的替换,使得子进程能够执行新的程序(如 ls 命令对应的程序)。
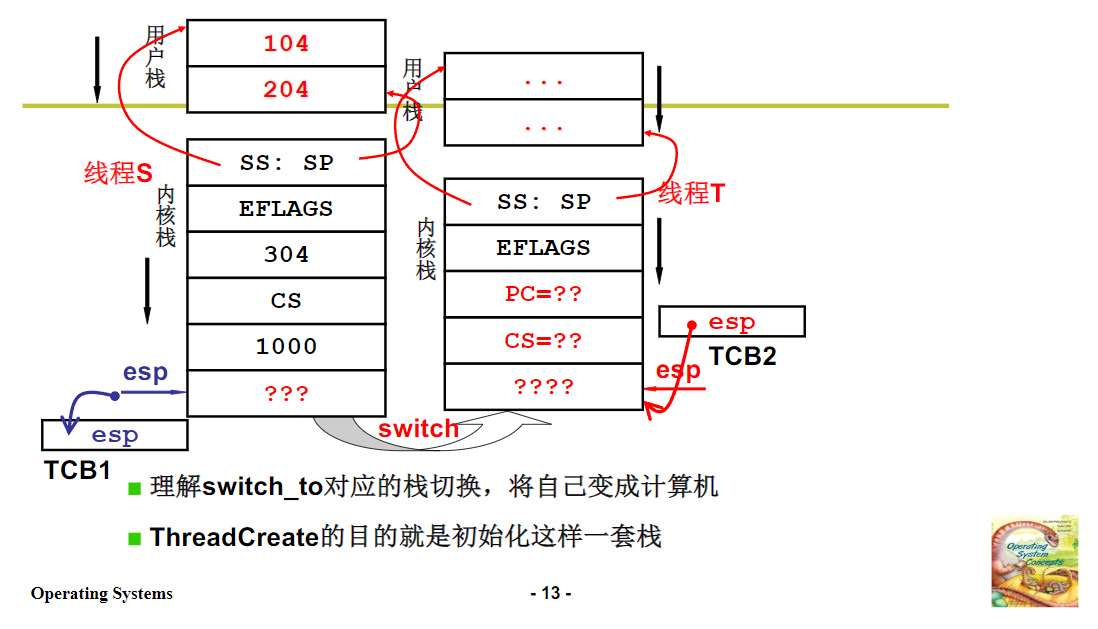
通过以上对 fork 和 exec 系统调用的分析,我们可以看到内核级线程的代码实现涉及到多个方面,包括中断处理、栈切换、进程创建与调度、代码替换等。这些操作虽然复杂,但核心代码其实并不多,主要就是 int 指令相关操作、switch_to 中的长跳转指令(或基于内核栈切换的相关代码)以及 iret 指令,再加上一些辅助代码。只要理解了这些核心代码和整体的执行逻辑,我们就能够掌握内核级线程的代码实现,进而为编写操作系统的核心部分打下坚实的基础。希望大家通过学习和实验,能够深入理解并熟练掌握这些内容,逐步实现自己的操作系统梦想。