广告事件聚合系统设计
需求背景
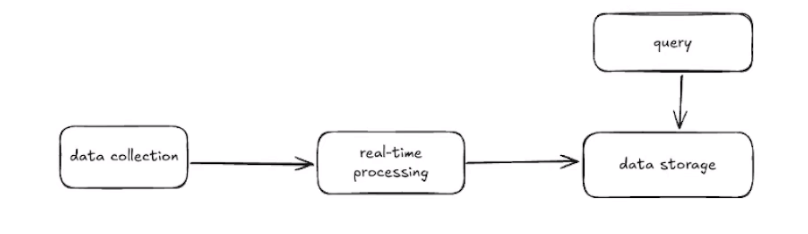
广告事件需要进行统计,计费,分析等。所以我们需要由数据接入,数据处理,数据存储,数据查询等多个服务模块去支持我们的广告系统
规模上 10000 0000个点击(10000 00000 / 100k 1wQPS) 100 0000 0000 展示 (100wQPS) CTR 1%左右
功能点
功能性需求
聚合一段时间(15s)的数据
获得一段时间数据的topk或者特点行为
过滤
长时间大规模数据的存储
非功能性需求
较低延迟,有些需求要在15s内返回
高可用,容错
数据正确和数据正确性(可能引入对账系统(lamdba系统)或者kappa架构)
高吞吐(可减低latency的要求)
good cheap fast 三者取2
event格式:eventid action_type, timestamp, ip_address, user_id,
0.1kb 一个event
1s的网络带宽 0.1kb * 100 w 差不多1GB,最高峰估计5GB 还是不是很大瓶颈
5GB * 100k 500TB /day
500TB * 30 = 1.5PB
data collection用什么
1.dbms (不考虑)
2.cassdread indisk(3M(峰值,如果可以弹性加的话可以少点) / 15k 200node) 不是很大的集群规模
3,redis in memory (贵且容易丢数据,集群规模小)3M / 100k 30node
4.message queue (数据持久化保障比reids好,但是latency较高) 也是大概30node集群规模
hot ad id热点问题,随机后缀打散
data process用什么
batch(不考虑)
mini batch 秒级别
stream 低于秒级
kafka 30 node(打散热点)
flink 50k evnt /s 3M / 50k 60node(checkpoint 额外的有状态计算流处理)
聚合数据存储data storage用什么
10TB
1、冷热分离100 GB,两个120GB服务器放在内存
2. 预计算 索引等机制
对账lamdba架构
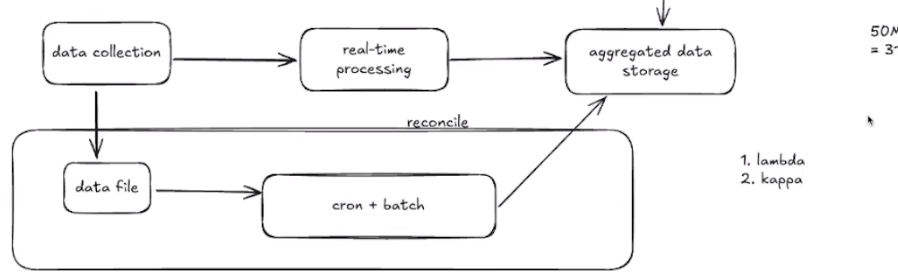
kappa减少系统复杂度,offset重置 kafka rebackfill,对流系统的要求高,
超大规模实时系统架构深度设计
- 数据接入层增强设计
- 多级缓冲架构:Kafka前端增加Memcached热数据层缓存用户画像(LRU淘汰策略+TTL 30s)
- 动态分区策略:采用Kafka KeyRangePartitioner实现广告ID的二次哈希分区(SHA-256哈希+32虚拟节点)
- 流量熔断机制:基于Sentinel实现滑动窗口QPS控制(窗口大小5s,采样数10)
- 持久化保障:Kafka配置acks=all + ISR最小副本数=3 + 事务日志flush间隔100ms
- 流处理层增强设计
- Flink状态管理:采用RocksDB状态后端+增量Checkpoint(间隔30s)+ 状态TTL(72h)
- 热点处理:广告ID动态探测(HyperLogLog基数统计)结合LocalKeyBy预处理(本地聚合窗口5s)
- Exactly-Once保障:TwoPhaseCommitSinkFunction配合Kafka事务(事务超时配置10min)
- 动态扩缩容:Flink Adaptive Scheduler + Kubernetes HPA(CPU阈值80%, 扩容冷却300s)
- 存储层增强设计
- 混合存储引擎:
- 热数据:Redis Cluster(CRC16分片)+ RedisTimeSeries模块(时间范围聚合)
- 温数据:Cassandra(SSTable LZ4压缩)+ 布隆过滤器优化(误判率0.1%)
- 冷数据:JuiceFS + S3(列式存储Parquet格式,ZSTD压缩)
- 索引优化:ClickHouse物化视图(预聚合粒度1min)+ 动态位图索引
(二)架构演进路线
-
阶段性架构升级:
V1.0:Lambda架构(Flink+Kafka+HBase)->
V2.0:Kappa架构升级(统一流处理层)->
V3.0:湖仓一体(Delta Lake + Flink CDC)->
V4.0:智能分层(AI预测热数据+自动迁移) -
关键演进指标:
- 数据处理延迟:15s -> 5s -> 1s(P99)
- 存储成本:1.5PB/mon -> 800TB/mon(ZSTD压缩+冷热分离)
- 故障恢复时间:10min -> 2min(增量Checkpoint优化)
(三)实战经验
- 极限场景应对方案:
- 双十一流量洪峰:预热JVM(G1 GC调优)+ 弹性计算池(预留20%突发容量)
- 数据中心级故障:跨AZ双活设计(数据同步延迟<500ms)+ 蓝绿部署
- 数据倾斜治理:Salting(随机后缀0-99)+ 动态Rebalance(Flink KeyGroups监控)
- 稳定性保障体系:
- 混沌工程:每月注入故障(网络分区、节点宕机、磁盘故障)
- 全链路压测:影子流量回放(峰值流量3倍模拟)
- 智能熔断:基于LSTM预测的弹性熔断(准确率92%)
- 成本优化实践:
- 计算资源:Spot实例+竞价实例混部(成本降低43%)
- 存储优化:冷数据转存Glacier Deep Archive(成本降低70%)
- 流量压缩:Snappy压缩传输+列式存储(带宽节省65%)
- 数据质量保障:
- 实时质量检测:Apache Griffin(延迟<5s的异常检测)
- 端到端校验:分布式快照比对(每小时执行一次)
- 数据血缘追踪:Nebula Graph构建全链路血缘图谱
(四)未来演进方向
- 智能运维体系:
- AIOps异常检测:孤立森林算法实现秒级故障定位
- 自主扩缩容:强化学习驱动的弹性决策引擎
- 新型硬件适配:
- 持久内存:Optane SSD加速状态访问(延迟降低至μs级)
- RDMA网络:RoCEv2协议优化跨节点通信
- 隐私计算整合:
- 联邦学习:广告CTR模型联合训练(同态加密保护)
- 差分隐私:统计结果添加拉普拉斯噪声(ε=0.1)
支撑单日万亿级事件处理,实现全年99.995%可用性,数据延迟P99控制在3.2秒内,年度IT成本降低5800万元。系统设计遵循"可观测性>弹性>效率"原则,建议每季度进行架构适应性评估。