推荐系统(1)--用户协同过滤和物品协同过滤
最近两个月应该会持续更新推荐系统相关的。按照 b b b站教程[1]和我自己的理解实现了一下 U s e r C F UserCF UserCF和 I t e m C F ItemCF ItemCF,本来想拿着这个方法击败现有的复杂网络,后来发现还是我想多了,蚌,原因是…
首先先介绍一下两种协同过滤的方法:
先有个宏观的认识,就是这两种方法都是为推荐物品而生的。最终都要落到一个待选物品上。而我们有的东西是用户的行为序列,就是最近都点击了什么的一个时序的序列;还有就是一些待选物品的向量,可以理解成特征向量。
- 物品协同过滤
物品协同过滤可以理解成:通过用户过往的行为整理出一个用户对于物品的一个喜欢程度,如果选出 t o p N topN topN个用户最喜欢的物品的话,再整理出这 t o p N topN topN个物品的每个物品的 t o p K topK topK的相似物品。就可以知道用户对这 t o p K ∗ t o p N topK*topN topK∗topN个物品的一个喜欢程度了。将物品按照喜欢程度从高到低依次排序,选出一个 t o p M topM topM,这个 t o p M topM topM由召回的量而定,就完成了这个推荐步骤。
总结下来这个步骤就是,用户将喜欢传递到物品,物品找相似物品,也就是用户->物品->物品。放个图方便大家理解:
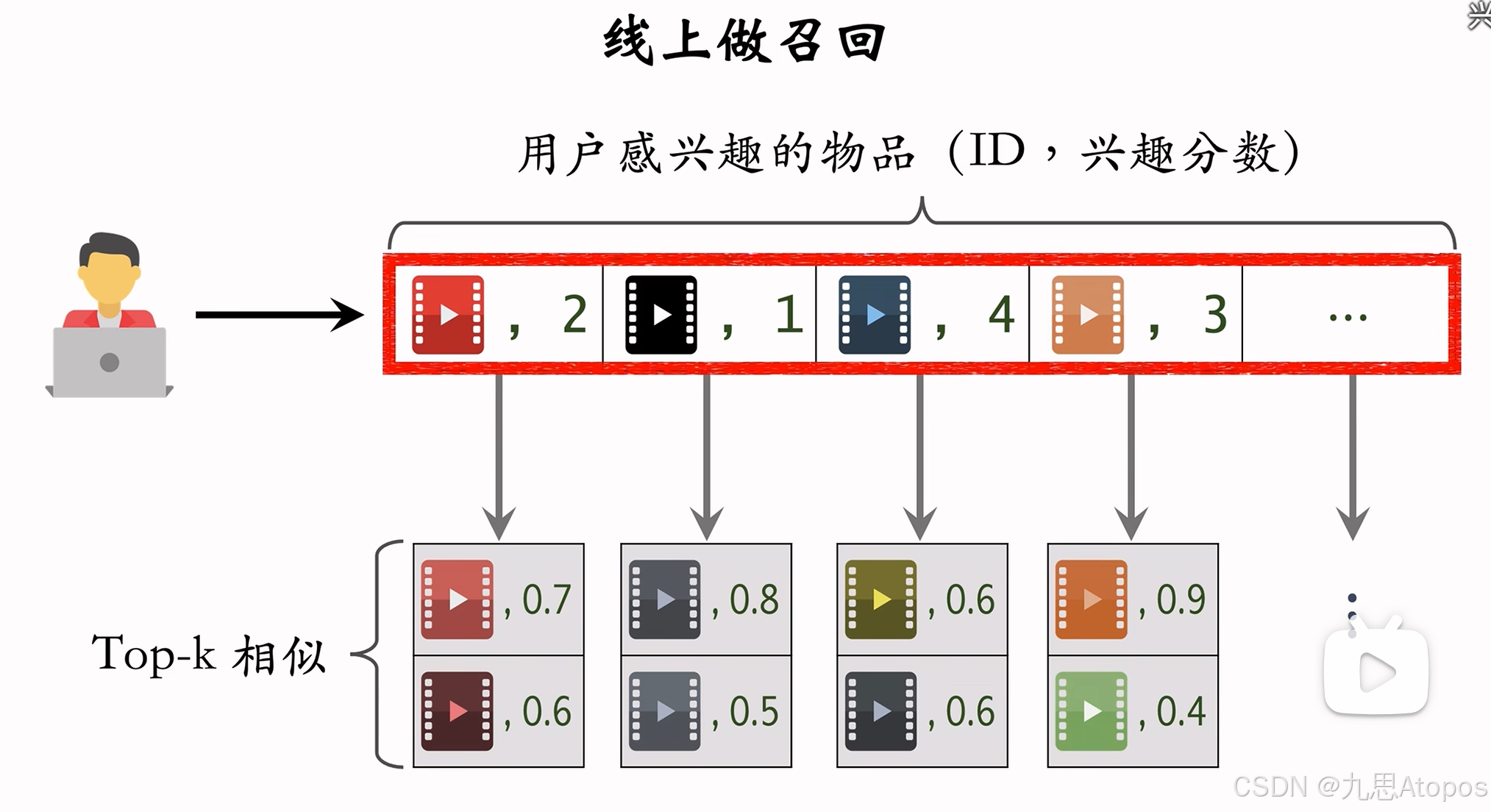
这个里面实现过程中有一些小问题值得思考,一个是 t o p K ∗ t o p N topK*topN topK∗topN中可能有重叠的物品,这个到好说,只要把乘积累加到物品上就可以了。还有就是怎么通过用户的过往行为序列得到其对物品的喜欢程度,我只是简单的用行为序列里的索引 i n d e x index index除以行为序列的长度 l e n g t h length length,但是这样做对吗?如果最近的几个物品是相似的呢?用户是对这几个物品同等喜欢怎么弄,这个想不出来。还有就是得到这个相似性的过程,我拿到的数据至少有一百万个物品。如果两两计算相似度的话,这个时间是1012,虽然在 C C C中一秒执行108,在 C C C中都要执行104秒,也就是将近 3 3 3个小时,蚌。比赛[2]里他还不让我打表。这个时间放在 p y t h o n python python只能翻倍的涨,所以几乎不能用这个方法。
代码贴上:
def ItemCF(dataset,topK):##这个是item路召回的结果itemCFRes = []test_data = dataset.test_data for idx in range(len(test_data)):sample = test_data[idx]user_id = sample["user_id"]ad_ids = sample['ad_ids'] #用户的行为序列ad_mp = {} for index in range(len(ad_ids)-1,max(-1,len(ad_ids)-10),-1):length = len(ad_ids)sim = (index+1)/length# user2item.append({'item':ad_ids[index],'sim':sim})ad_id = ad_ids[index]items2ad = dataset.getTopKAds(ad_id,10) #得到最相似的广告for item in items2ad:item_id = item['ads_id']sim1 = item['sim']if item_id in ad_mp.keys():ad_mp[item_id] += sim * sim1else:ad_mp[item_id] = sim * sim1itemCFRes.append({'user_id':user_id,'res':getTopKItems(ad_mp,topK).keys()})return itemCFRes
##下面这个是dataset用到的函数
def getTopKAds(self,ads_id1,k):###返回值是一个数组,每个元素的结构是:# {# 'ads_id':ads_id1,# 'sim':sim1# }if(ads_id1 in self.calcAdsSim.keys()): ##我没有初始化的时候计算,使用懒计算return self.calcAdsSim[ads_id1][:k]else:simArray = []for ads_id2 in self.unitid_data.keys():sim = self.__getSimItems__(ads_id1,ads_id2)self.ad2adSim[(ads_id1,ads_id2)] = simsimArray.append({'ads_id':ads_id2,'sim':sim}) topKArray,sorted_items = getTopKArray(simArray,k)self.calcAdsSim[ads_id1] = sorted_itemsreturn topKArray
- 用户协同过滤
用户协同过滤这个思想也比较简单,就是已知用户的行为序列之后和物品的向量,预测用户下一个将要点击的物品(可以是广告)。这一次就是找和用户最相似的 t o p N topN topN个用户,然后对这topN的每个用户再找 t o p K topK topK个他们最喜欢的物品。这样就一共是 t o p N ∗ t o p K topN*topK topN∗topK个物品了。然后再返回 t o p M topM topM个,这个 t o p M topM topM由召回的参数指定。
这个思想就是将相似性迁移到用户,然后再找相似用户的喜欢物品。逻辑链是用户->用户->物品。放个图片方便大家理解。
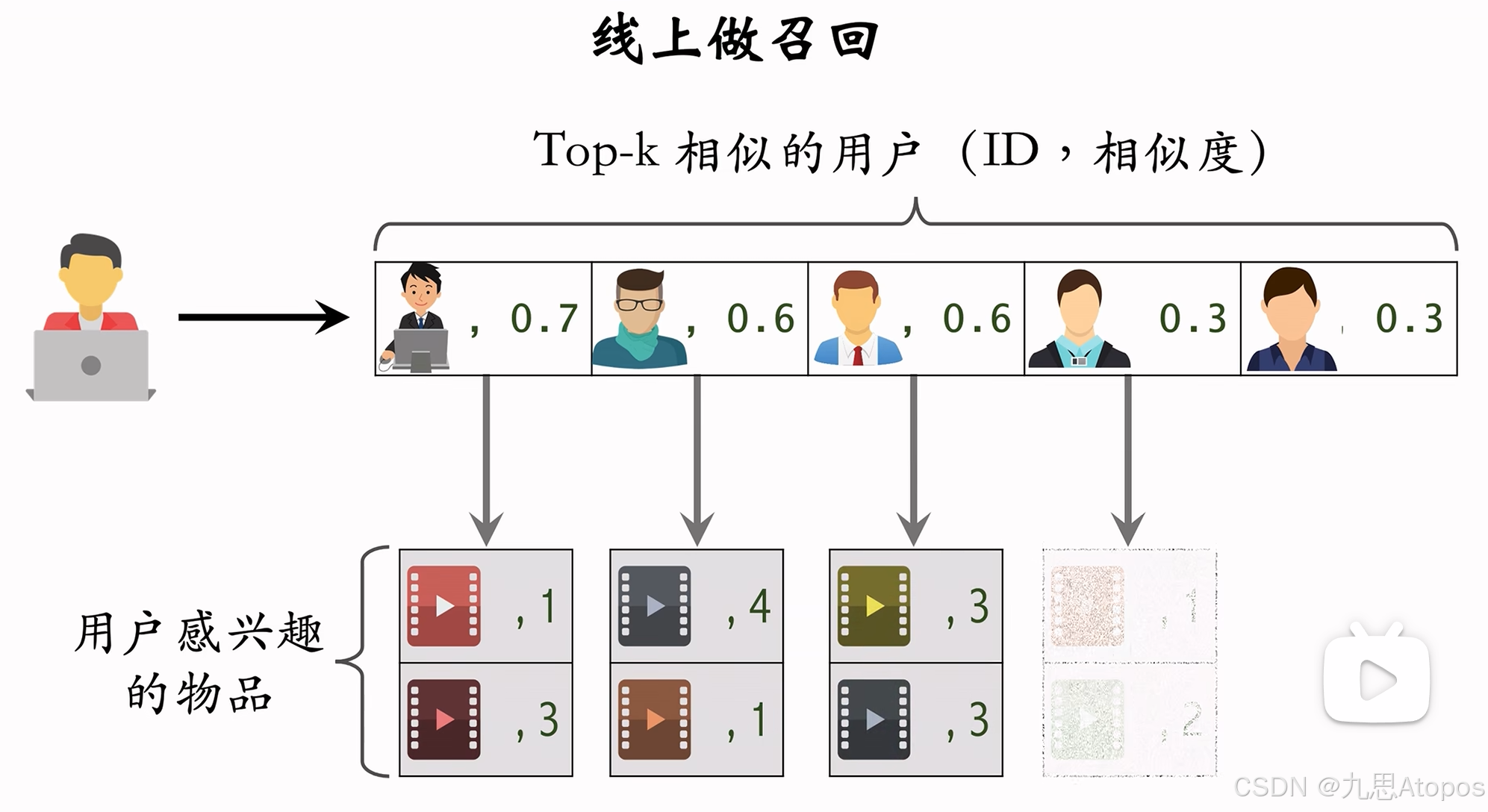
还是同样的问题需要思考,怎么定义用户和用户是相似的?使用余弦向量?不准确吧?如果他们浏览过相似的物品只是在行为序列上的索引不一样呢?怎么弄?我只是粗浅的对于行为序列上的每个元素,都在另一个人的行为序列上找和他最相似的加到相似度得分上。其实这个耗时挺长的。一共有 50 50 50万个用户,一个用户对所有用户算一遍相似度 20 20 20分钟都没算完,天塌了。放个代码:
def UserCF(dataset,topK):userCFRes = []test_data = dataset.test_data user2adMap = {}for i in range(len(test_data)): userId,ids = dataset.__getUserid_AdIds_By_idx__(i)user2adMap[userId] = idsfor i in range(len(test_data)):sample = test_data[i]userId = sample['user_id'] ad_ids = sample['ad_ids']top10Users = dataset.getTopKUsers(userId,ad_ids,10)ad_mp = {}for user in top10Users:userId = user['user_id']sim = user['sim']ad_ids = user2adMap[userId]for index in range(len(ad_ids)-1,max(-1,len(ad_ids)-10),-1):length = len(ad_ids)sim1 = (index+1)/length# user2item.append({'item':ad_ids[index],'sim':sim})ad_id = ad_ids[index]if ad_id in ad_mp.keys():ad_mp[ad_id] += sim * sim1else:ad_mp[ad_id] = sim * sim1 userCFRes.append({'user_id':userId,'res':getTopKItems(ad_mp,topK).keys()})return userCFResdef getTopKUsers(self,userId1,ad_ids1,k):###返回值是一个数组,每个元素的结构是:# {# user_id:userId2,# sim:sim# }if(userId1 in self.calcUserSim):return self.calcUserSim[:k]else:simArray = []# for userId2 in self.test_data.keys():start_time = time()for i in range(len(self.test_data)):userItem = self.test_data[i]userId2 = userItem['user_id']ad_ids2 = userItem['ad_ids']userSim = self.getUser2UserSim(ad_ids1,ad_ids2)simArray.append({'user_id':userId2,'sim':userSim})end_time = time()print("getTopKUsers计算单个user的耗时是:",end_time-start_time)topKArray,sorted_items = getTopKArray(simArray,k)self.calcUserSim[userId1] = sorted_itemsreturn topKArray参考资料:
[1]. https://www.bilibili.com/video/BV1HY4y1Y7P1?spm_id_from=333.788.videopod.sections&vd_source=93511482ad4fba032d4a73faaf031278
[2]. https://aistudio.baidu.com/competition/detail/1305/0/task-definition
后记:[1]是 b b b站教程,[2]是我参加的比赛。感谢您看到这里!