Protubuf入门 --- 01基本语法与编译使用
一、预备知识
1. 序列化和反序列化
序列化:把对象转换为字节序列的过程 称为对象的序列化。
反序列化:把字节序列恢复为对象的过程 称为对象的反序列化。
2. 什么情况下需要序列化
存储数据:当你想把的内存中的对象状态保存到⼀个文件中或者存到数据库中时。
网络传输:⽹络直接传输数据,但是无法直接传输对象,所以要在传输前序列化,传输完成后反
序列化成对象。例如我们之前学习过 socket 编程中发送与接收数据。
3. 如何实现序列化
xml、json、 protobuf
什么是protobuf?
将结构化数据进行序列化的一种方式!

这就是说,我们定义PB的一些信息,此时其可以通过编译器生成对应的C++文件
二、Protobuf基本语法
指定proto语法
首行(不包括注释行)是语法指定行:(如果没有指定会使用proto2的语法)
syntax = "proto3";这里的注释方法与C/C++的注释方法一样,采用://或者/* ...*/
proto3语法比proto2语法的使用更广,支持的更多,所以接下来的学习都是以proto3语法;
package声明符
package的作用类似于类似于C++中的命名空间,标志消息在项目中的唯一性;
package contacts;定义消息类型
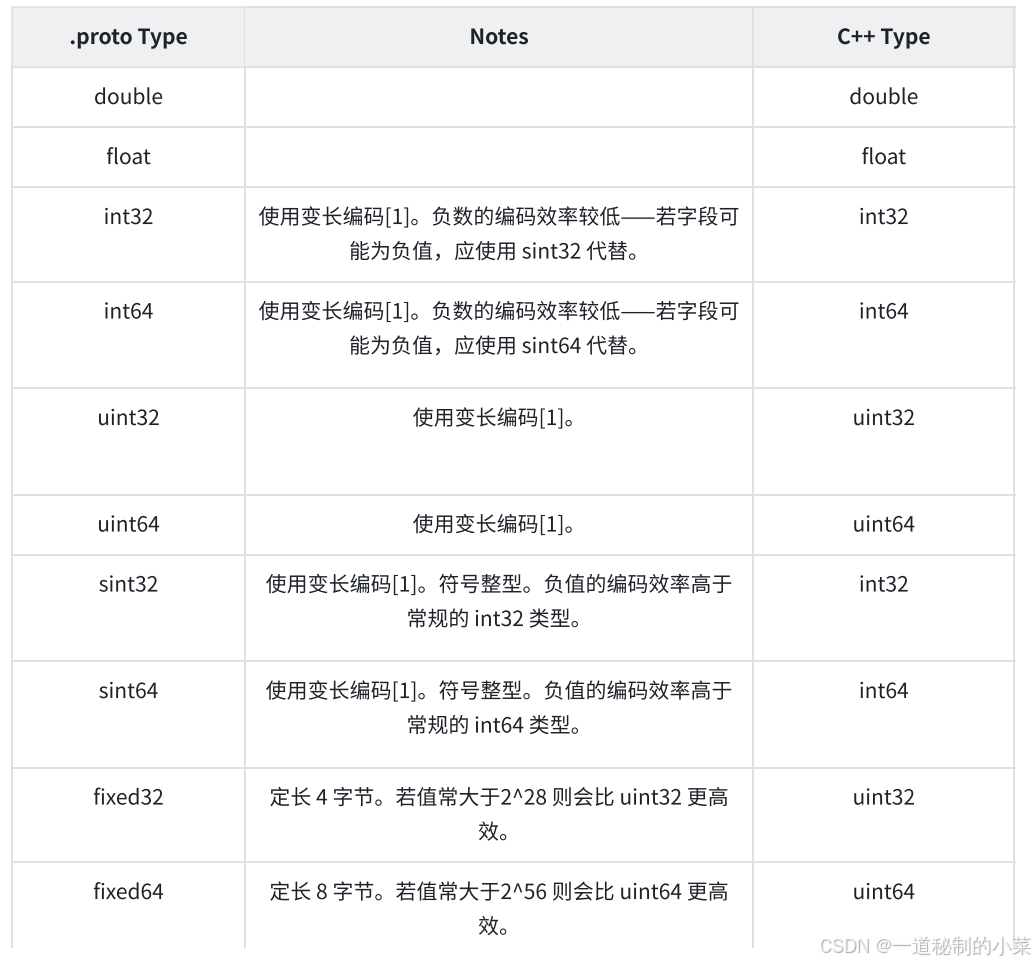
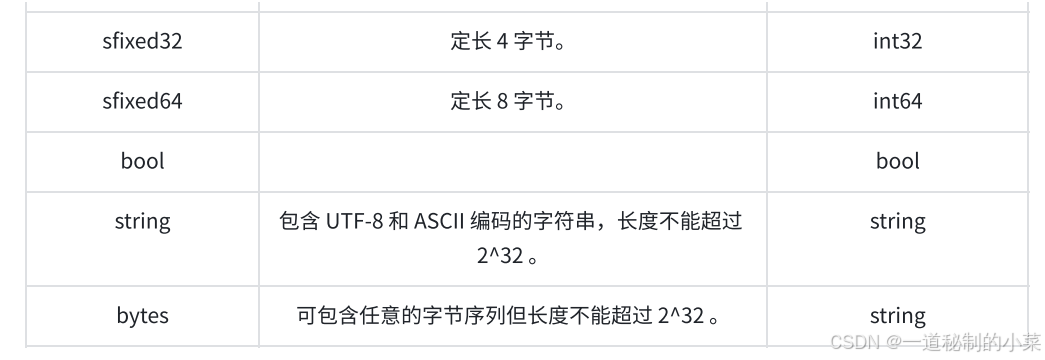
字段类型 字段名 = 字段唯一编号:
- 字段名称命名规范:全⼩写字⺟,多个字⺟之间⽤ _ 连接。
- 字段类型分为:标量数据类型 和 特殊类型(包括枚举、其他消息类型等)。
- 字段唯⼀编号:⽤来标识字段,⼀旦开始使⽤就不能够再改变。
// 定义联系人message
message PersonInfo{string name = 1;int32 age = 2;
}需要注意的是,两个字段如果使用相同的字段编号就会报错!
这里的标量数据类型与C++的内置数据类型相似,在编译后会转化为C++中对应的关系;
这里的变长编码指的是:经过protobuf 编码后,原本4字节或8字节的数可能会被变为其他字节数。 (可能4字节变成1字节,数值大小不变 --- 体现出protobuf高效性);
在这⾥还要特别讲解⼀下字段唯⼀编号的范围:
1 ~ 536,870,911 (2^29 - 1) ,其中 19000 ~ 19999 不可⽤。
19000 ~ 19999 不可⽤是因为:在 Protobuf 协议的实现中,对这些数进⾏了预留。如果⾮要在.proto ⽂件中使⽤这些预留标识号,例如将 name 字段的编号设置为19000,编译时就会报警:
// 消息中定义了如下编号,代码会告警:
// Field numbers 19,000 through 19,999 are reserved for the protobuf
implementation
string name = 19000;编译.proto文件,生成C++文件
编译的命令格式如下所示:
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
- protoc 是 Protocol Buffer 提供的命令行编译⼯具。
- --proto_path 指定 被编译的.proto⽂件所在⽬录,可多次指定。可简写成 -I
- IMPORT_PATH 。如不指定该参数,则在当前⽬录进⾏搜索。
- 当某个.proto ⽂件 import 其他.proto ⽂件时,或需要编译的 .proto ⽂件不在当前⽬录下,这时就要⽤-I来指定搜索目录。
- --cpp_out= 指编译后的⽂件为 C++ ⽂件。
- OUT_DIR 编译后⽣成⽂件的⽬标路径。
- path/to/file.proto 要编译的.proto⽂件。
这里我们举一个简单的编译指令:
protoc --cpp_out=. contacts.proto其对应一个简单的.protoc文件,如下所示:
syntax = "proto3";
package contacts;// 定义联系人message
message PersonInfo{string name = 1;int32 age = 2;
}
此时在当前目录下会生成对应的源文件和头文件;
此时我们会发现,对于每个message,都会生成一个对应的消息类!class
而在对应的消息类当中,编译器为每个字段提供了获取和设置方法,以及⼀下其他能够操作字段的方法!
例如下面所示的(这里我们对.proto.h文件中重要部分进行展示):
class PeopleInfo final : public ::PROTOBUF_NAMESPACE_ID::Message {
public:using ::PROTOBUF_NAMESPACE_ID::Message::CopyFrom;void CopyFrom(const PeopleInfo& from);using ::PROTOBUF_NAMESPACE_ID::Message::MergeFrom;void MergeFrom( const PeopleInfo& from) {PeopleInfo::MergeImpl(*this, from);}static ::PROTOBUF_NAMESPACE_ID::StringPiece FullMessageName() {return "PeopleInfo";}// string name = 1;void clear_name();const std::string& name() const;template <typename ArgT0 = const std::string&, typename... ArgT>void set_name(ArgT0&& arg0, ArgT... args);std::string* mutable_name();PROTOBUF_NODISCARD std::string* release_name();void set_allocated_name(std::string* name);
// int32 age = 2;void clear_age();int32_t age() const;void set_age(int32_t value);
};在上面的例子中:
- 每个字段都有设置和获取的⽅法, getter 的名称与⼩写字段完全相同,setter ⽅法以 set_ 开头。
- 每个字段都有⼀个 clear_ ⽅法,可以将字段重新设置回 empty 状态。
问题:序列化和反序列化对应的方法在哪里提供呢?
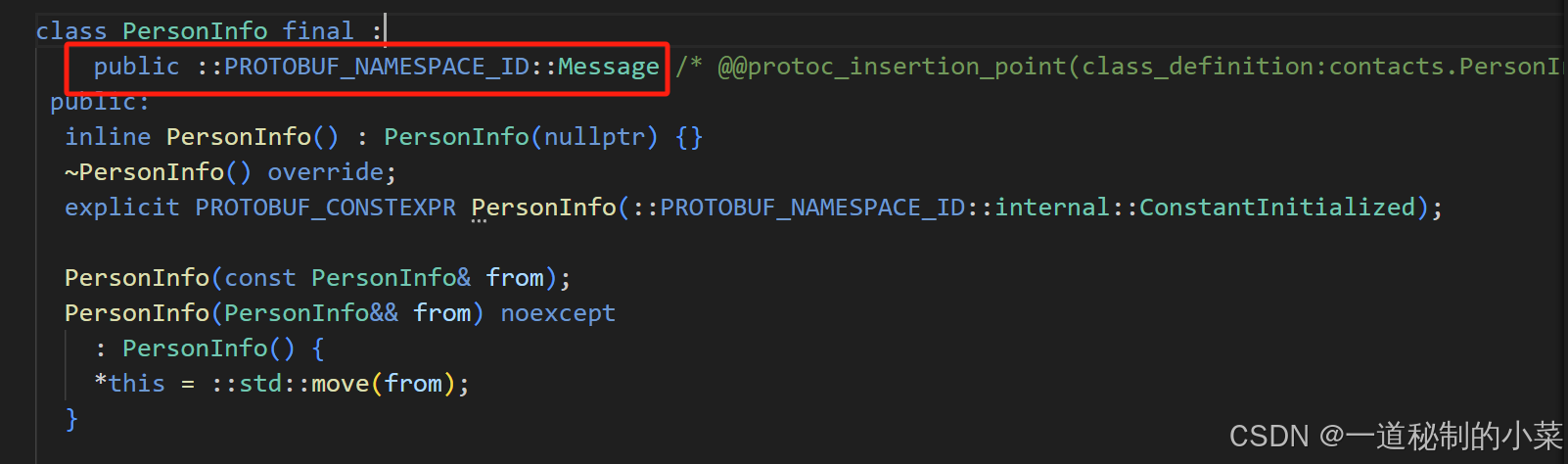
person继承了message这个父类;
这个父类继承了MessageLite这个类!
而在MessageLite这个类当中,就提供了序列化和反序列化的方法!;
代码的整体的框架如下所示:
class MessageLite {
public://序列化:bool SerializeToOstream(ostream* output) const; // 将序列化后数据写⼊⽂件
流bool SerializeToArray(void *data, int size) const;bool SerializeToString(string* output) const;//反序列化:bool ParseFromIstream(istream* input); // 从流中读取数据,再进⾏反序列化
动作bool ParseFromArray(const void* data, int size);- 序列化的结果是二进制的字节序列!不是文本格式;
- 以上三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使用。
- 序列化的 API 函数均为const成员函数,因为 序列化不会改变类对象的内容 ,而是将序列化的结果 保存到函数⼊参指定的地址中;
- 序列化是输出型函数;反序列化是输入型函数!
序列化和反序列化的使用
这里我们编写一个测试的源文件,用来显示序列化和反序列化:
#include <iostream>
#include "contacts.pb.h" // 引⼊编译生成的头文件
using namespace std; int main() {
string people_str; {// .proto⽂件声明的package,通过protoc编译后,会为编译⽣成的C++代码声明同名的命名空间// 其范围是在.proto ⽂件中定义的内容contacts::PeopleInfo people; people.set_age(20); people.set_name("张珊"); // 调⽤序列化⽅法,将序列化后的⼆进制序列存⼊string中if (!people.SerializeToString(&people_str)) { cout << "序列化联系⼈失败." << endl; }// 打印序列化结果cout << "序列化后的 people_str: " << people_str << endl;}{contacts::PeopleInfo people; // 调⽤反序列化⽅法,读取string中存放的⼆进制序列,并反序列化出对象if (!people.ParseFromString(people_str)) { cout << "反序列化出联系⼈失败." << endl; } // 打印结果cout << "Parse age: " << people.age() << endl; cout << "Parse name: " << people.name() << endl; }
}syntax = "proto3";
package contacts;// 定义联系人message
message PersonInfo{string name = 1;int32 age = 2;
}接下来我们依次对上面的代码内容进行解释:
- 可以看到由于在.proto文件中定义了package,在C++中就等效于命名空间,所以在我们想要对message进行序列化转化为2进制的时候,需要指定命名空间;
- 接下来我们对Person调用生成的方法set值;
- 接下来我们对内容进行序列化,可以发现序列化的结果的返回值bool,若序列化失败则为false;
- 接下来打印序列化的结果,因为序列化的结果是二进制,且将二进制存放到string当中,所以此时可能会出现格式的错误;
- 反序列化与序列化类似,这里我们person_str里面已经存放了二进制序列,我们对其输出为对象;
接下来我们就可以对其进行编译:
g++ main.cc contacts.pb.cc -o TestProtoBuf -std=c++11 -lprotobuf需要注意的是:这里必须要链接protibuf动态库,否则会出现链接错误;
运行结果如下所示:
