【AI论文】仅通过一个训练样本对大型语言模型进行推理的强化学习
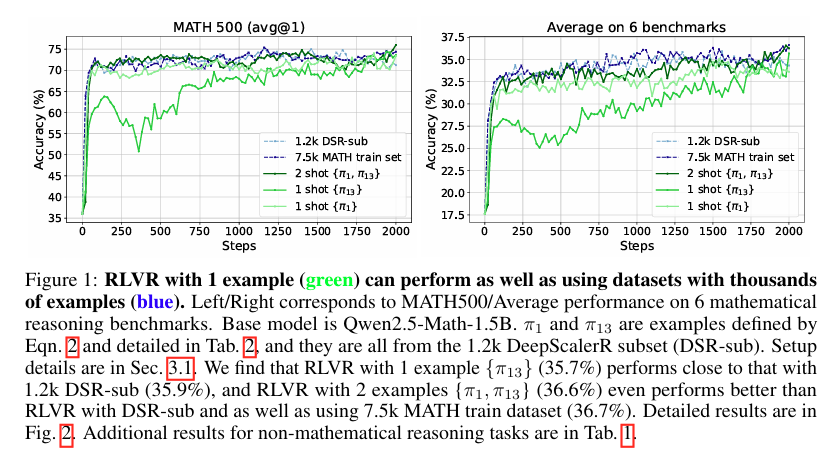
摘要:我们表明,使用一个训练示例(1-shot RLVR)进行具有可验证奖励的强化学习,在激励大型语言模型(LLM)的数学推理能力方面是有效的。 将RLVR应用于基础模型Qwen2.5-Math-1.5B,我们确定了一个例子,将模型在MATH500上的性能从36.0%提高到73.6%,并将六个常见数学推理基准的平均性能从17.6%提高到35.7%。 这一结果与使用1.2k DeepScaleR子集(MATH500:73.6%,平均:35.9%)所获得的性能相匹配,其中包括上述示例。 在各种模型(Qwen2.5-Math-7B、Llama3.2-3B-Instruct、DeepSeek-R1-Distill-Qwen-1.5B)、RL算法(GRPO和PPO)和不同的数学示例(其中许多示例在用作单个训练示例时,在MATH500上产生了大约30%或更高的改进)中,都观察到了类似的实质性改进。 此外,我们在单次强化学习虚拟现实训练中识别到了一些有趣的现象,包括跨域泛化、自我反思频率增加,以及即使在训练精度饱和后测试性能仍持续提高,这种现象我们称之为后饱和泛化。 此外,我们验证了单步强化学习强化学习算法的有效性主要来自策略梯度损失,将其与“直觉”现象区分开来。 我们还展示了在1次RLVR训练中促进探索(例如,通过添加具有适当系数的熵损失)的关键作用。 作为额外收获,我们观察到,在没有结果奖励的情况下,仅应用熵损失,就能使Qwen2.5-Math-1.5B在MATH500上的性能显著提高27.4%。 这些发现可以激发未来在RLVR数据效率方面的工作,并鼓励重新审视RLVR的最新进展和潜在机制。 我们的代码、模型和数据在One-Shot-RLVR。Huggingface链接:Paper page,论文链接:2504.20571
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在多个领域展现出了惊人的能力,包括自然语言处理、问答系统、文本生成等。然而,尽管这些模型在预训练阶段接触了海量的文本数据,它们在特定领域的推理能力,尤其是数学推理能力,仍然存在局限。数学推理要求模型不仅理解语言,还需要具备逻辑推理、符号操作和问题解决的能力,这对LLMs来说是一个巨大的挑战。
为了提升LLMs的数学推理能力,研究者们尝试了多种方法,包括微调(fine-tuning)、监督学习(supervised learning)和强化学习(reinforcement learning, RL)。其中,强化学习因其能够直接优化模型的最终输出,而不是中间表示,而备受关注。然而,传统的强化学习方法通常需要大量的训练样本,这在数学推理任务中尤为困难,因为高质量的数学推理数据集相对较少,且标注成本高昂。
研究目的
本研究旨在探索一种高效的强化学习方法,仅使用一个或极少数训练样本(即1-shot或few-shot RLVR)来显著提升大型语言模型的数学推理能力。具体来说,研究目的是:
- 验证1-shot RLVR的有效性:通过实验验证,仅使用一个精心选择的训练样本,是否能够显著提升LLMs在数学推理任务上的性能。
- 理解1-shot RLVR的工作机制:深入分析1-shot RLVR如何工作,包括策略梯度损失、熵损失等关键组件的作用,以及它们如何共同促进模型性能的提升。
- 探索数据选择策略:研究如何有效地选择训练样本,以最大化1-shot RLVR的性能提升。
- 推动RLVR数据效率的研究:通过本研究,为未来的RLVR数据效率研究提供新的思路和方向,鼓励重新审视RLVR的最新进展和潜在机制。
研究方法
数据集与模型
本研究使用了多个数学推理数据集,包括MATH500、AIME 2024、AMC 2023、Minerva Math、OlympiadBench和AIME 2025等,这些数据集涵盖了从基础数学到高级数学推理的广泛任务。模型方面,主要使用了Qwen2.5-Math-1.5B作为基础模型,并验证了其他模型(如Qwen2.5-Math-7B、Llama3.2-3B-Instruct、DeepSeek-R1-Distill-Qwen-1.5B)和RL算法(如GRPO和PPO)的泛化能力。
强化学习方法
本研究采用了基于可验证奖励的强化学习方法(RLVR),其中奖励是通过将模型的输出与标准答案进行匹配来计算的。具体来说,研究重点在于1-shot RLVR,即仅使用一个训练样本进行强化学习。为了实现这一点,研究提出了一种简单的数据选择方法,即根据训练样本的历史方差分数进行排序,选择方差最大的样本作为训练样本。
损失函数
RLVR的损失函数包括三个主要组件:策略梯度损失、KL散度损失和熵损失。策略梯度损失鼓励模型生成具有更高奖励的响应序列;KL散度损失作为正则化项,用于维持模型的一般语言质量;熵损失则用于鼓励模型生成更多样化的推理路径,增加探索性。
研究结果
1-shot RLVR的有效性
实验结果表明,仅使用一个训练样本进行1-shot RLVR,就能显著提升LLMs在数学推理任务上的性能。具体来说,在Qwen2.5-Math-1.5B模型上,1-shot RLVR将MATH500的性能从36.0%提升到73.6%,并将六个常见数学推理基准的平均性能从17.6%提升到35.7%。这一结果与使用1.2k DeepScaleR子集所获得的性能相匹配,证明了1-shot RLVR的有效性。
跨域泛化能力
研究还发现,1-shot RLVR不仅提升了模型在训练样本所属领域(如代数)的性能,还促进了跨域泛化能力。即使训练样本来自一个特定领域,模型在其他领域(如几何、数论)的性能也有显著提升。这表明1-shot RLVR能够激发模型内在的推理能力,使其能够更好地应对各种数学推理任务。
自我反思频率的增加
在1-shot RLVR过程中,研究观察到模型自我反思的频率显著增加。这表现为模型在生成响应时,更频繁地使用“重新思考”、“重新检查”和“重新计算”等词汇。这种自我反思的行为可能有助于模型在生成响应时进行更多的内部验证和修正,从而提高最终输出的准确性。
后饱和泛化现象
研究还发现了一个有趣的现象,即后饱和泛化。在训练过程中,当模型在单个训练样本上的准确率迅速达到饱和时,其在测试集上的性能仍然持续提高。这一现象表明,即使模型已经“记住”了训练样本,它仍然能够继续学习并提高在未见过的测试样本上的性能。
熵损失的重要性
通过消融实验,研究验证了熵损失在1-shot RLVR中的关键作用。熵损失不仅有助于模型生成更多样化的响应路径,还能在仅使用熵损失而不使用任何结果奖励的情况下,显著提升模型在MATH500上的性能。这一发现为未来的RLVR研究提供了新的思路,即探索如何更有效地利用熵损失来提升模型的推理能力。
研究局限
尽管本研究取得了显著的成果,但仍存在一些局限性:
- 数据集的选择:本研究主要使用了数学推理数据集进行实验,未来可以探索1-shot RLVR在其他领域(如代码生成、常识推理等)的适用性。
- 训练样本的选择:虽然本研究提出了一种简单的数据选择方法,但如何更有效地选择训练样本仍然是一个开放问题。未来的研究可以探索更复杂的数据选择策略,以最大化1-shot RLVR的性能提升。
- 模型规模的限制:本研究主要使用了中等规模的LLMs进行实验,未来可以探索在更大规模模型上应用1-shot RLVR的效果。
- 解释性的缺乏:尽管本研究观察到了许多有趣的现象,但对于1-shot RLVR如何工作的内在机制仍缺乏深入的解释。未来的研究可以尝试从理论层面解释1-shot RLVR的有效性。
未来研究方向
基于本研究的发现和局限性,未来的研究可以从以下几个方面展开:
- 探索1-shot RLVR在其他领域的应用:将1-shot RLVR应用于代码生成、常识推理等其他领域,验证其普适性和有效性。
- 改进数据选择策略:研究更复杂的数据选择方法,如基于模型不确定性的数据选择、基于课程学习的数据选择等,以最大化1-shot RLVR的性能提升。
- 研究更大规模模型上的1-shot RLVR:在更大规模的LLMs上应用1-shot RLVR,探索其性能提升的潜力和局限性。
- 深入解释1-shot RLVR的工作机制:从理论层面深入解释1-shot RLVR如何工作,包括策略梯度损失、熵损失等关键组件的作用机制,以及它们如何共同促进模型性能的提升。
- 结合其他技术提升RLVR效率:探索将1-shot RLVR与其他技术(如元学习、迁移学习等)相结合,以进一步提升RLVR的数据效率和性能。
总之,本研究通过实验验证了仅使用一个训练样本进行强化学习(1-shot RLVR)在提升大型语言模型数学推理能力方面的有效性,并深入分析了其工作机制。未来的研究可以在此基础上进一步探索1-shot RLVR的普适性、数据选择策略、模型规模限制以及内在工作机制等方面的问题,为推动RLVR数据效率的研究提供新的思路和方向。