详解具身智能机器人开源数据集:RoboMIND
一、RoboMIND基础信息
-
RoboMIND 发布时间:2024年12月
-
创建方:国家地方共建具身智能机器人创新中心与北京大学计算机学院联合创建。
-
所使用的机器人:单臂机器人(Franka Emika Panda 、UR5e )、双臂机器人(AgileX Cobot Magic V2.0 ) 和 人 形 机 器 人 (“天工” ,配备5指灵巧双手)
-
数据集规模:包含10.7万条机器人轨迹(任务成功的轨迹),涵盖479种任务、96种物体类别和38种操作技能;
另外,数据集中还包括机器人做任务失败案例(包括由于人类操作者的原因导致执行失败的案例和机器人本身原因导致执行失败的案例)的5000条轨迹,每个失败案例都附有详细的故障原因。通过分析失败案例,不仅能够改进模型,反过来还能指导改进数据采集方法,提高数据质量。

RoboMIND开源数据集
二、RoboMIND 数据集特征
1. 机器人形态多样化
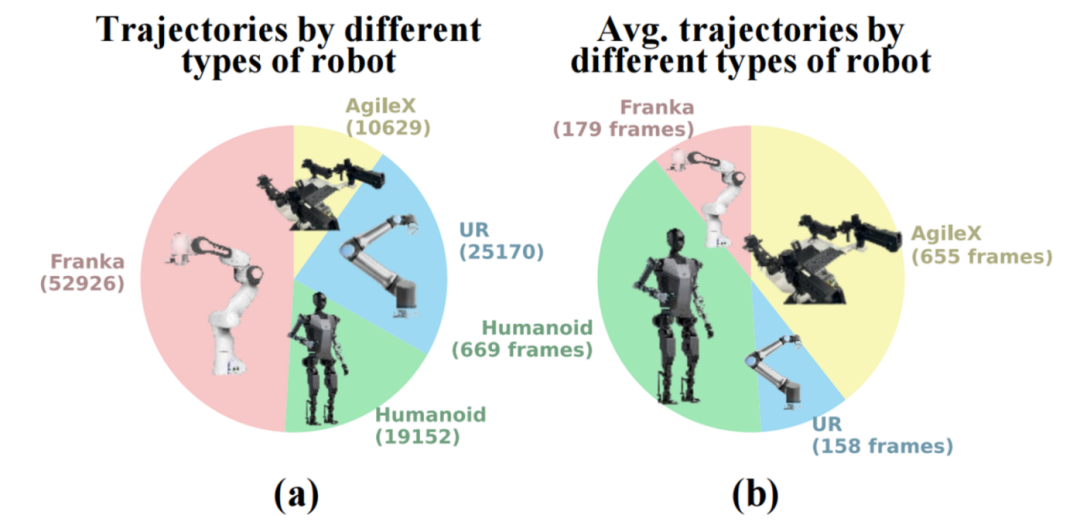
在RoboMIND数据集中,基于单臂机器人Franka Emika Panda的数据轨迹有52926条占比最高,占比将近50%,其中,超过26,070条基于数字孪生环境的模拟轨迹和26,856条通过人类远程操作收集的真实世界轨迹。
另外,拥有灵巧双手的人形机器人“天工”的轨迹有19152条,占比为17.8%,这些轨迹用于执行一系列复杂的人类操作技能。
基于双臂机器人AgileX Cobot Magic V2.0的数据轨迹有25170条,占比为23.3%,该数据用于支持协调技能和更长期任务的训练,增强了数据集的多样性和复杂性。
另外,基于单臂机器人UR5e的数据轨迹有10629条,占比为9.9%。(参看下图a)
2. 任务长度多样化
Franka Emika Panda机器人平均轨迹长度为179帧;UR5e机器人平均轨迹长度为158帧。这两款单臂机器人执行任务的轨迹相对较短(少于200个时间步),适合用于训练基础技能。相比之下,人形机器人“天工”(平均轨迹长度为669帧)和双臂机器人AgileX Cobot Magic V2.0(平均轨迹长度为655帧)执行任务的轨迹相对较长(超过500个时间步),更适合用于长时间跨度的任务训练以及技能组合。(参看下图b)
3. 任务多样性
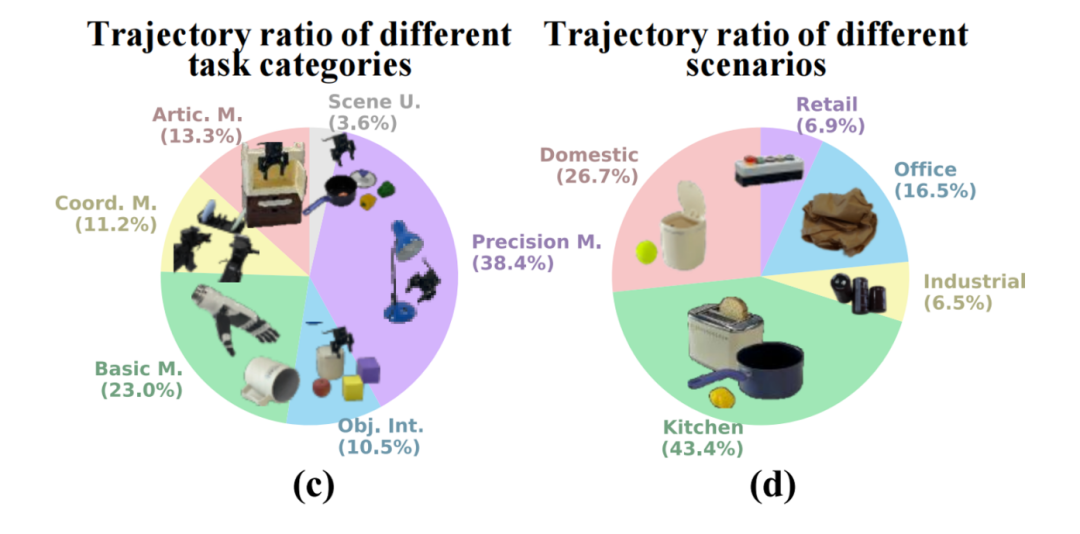
根据任务的语言描述,综合考虑动作、对象和轨迹范围等因素,将整个数据集中的任务分为六大类(参看下图c):
-
铰链式操作(Artic. M. - Articulated Manipulations ):开关抽屉、门,转动物体等。
-
协调操作(Coord. M. - Coordination Manipulations):这里主要是指双臂机器人的协同。
-
基本操作(Basic M. - Basic Manipulations):抓、握、提、放等最基本的操作。
-
多物体交互(Obj. Int.- Multiple Object Interactions):比如推一个物体撞另一个物体。
-
精准操作(Precision M. - Precision Manipulations):比如倒水,穿针引线这种需要精确控制的操作。
-
场景理解(Scene U. - Scene Understanding):比如从特定位置关门,或者把不同颜色的积木放到对应颜色的盒子里。
其中,精准操作占比最高,达38.4%;基础操作次之,占比 23.0%。通过细致的分类,得到了479项具体的任务,涵盖了从简单到复杂,从短时到长时的各种操作。
4. 物品类别多样性
RoboMIND数据集涵盖了厨房、家庭、零售、办公室以及工业五大场景里面96种不同的物品类别。其中,厨房场景的物品包括鸡蛋、草莓、香蕉和梨子等,该场景下的轨迹占比最高,达到43.4%;家庭场景次之,轨迹占比为26.7%;工业场景的轨迹占比最少,为6.5%。多样化的物体种类增加了数据集的复杂性,有助于训练模型在各种环境下执行操作的通用操控策略。(参看下图d)
三、RoboMIND 数据集评测(数据集实验验证)
RoboMIND数据集实验验证分为基于单任务模仿学习模型的评估和基于VLA视觉语言动作模型两大类。
对于单任务模仿学习模型,通过评估ACT、Diffusion Policy和 BAKU三种主流的模仿学习算法的任务成功率。
对于VLA视觉语言动作模型,通过评估OpenVLA、RDT-1B 和CrossFormer三种主流的VLA模型的泛化能力和任务成功率。
1. 单任务模仿学习模型
在实现任务设计上,Franka、Tien Kung、AgileX和UR5e分别执行15个、10个、15个和5个任务,共45个任务,既有简单任务,也有复杂任务。
在模型选择上,选用了ACT 、Diffusion Policy和BAKU 三种常用的模仿学习算法。为每个数据集从头开始训练单任务模型。训练完成后,将模型直接部署到实际环境中进行评估。最后,通过任务的成功率来评估每个模型的性能。
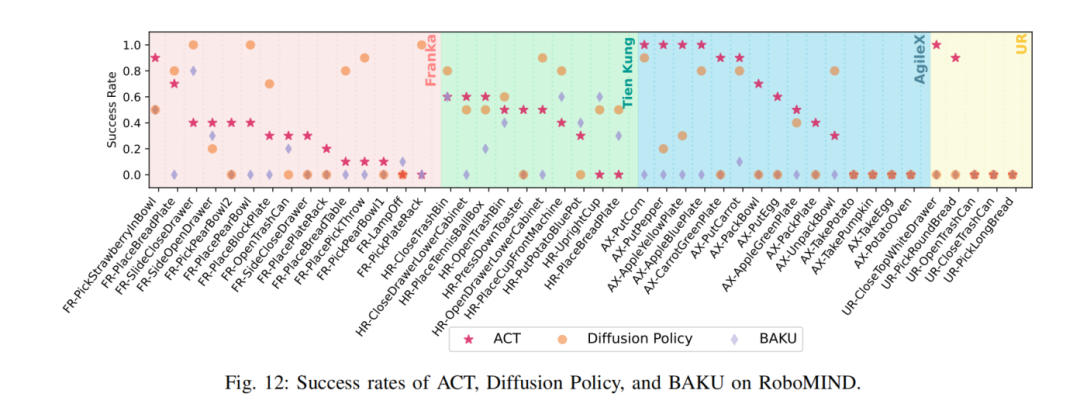
实验结果显示:ACT在AgileX的15项任务中的表现最好,平均成功率达到了55.3%。优于Franka(30.7%)、UR5e(38.0%) 和 天工(34.0%)。
Diffusion Policy也展示了其学习复杂任务的能力,在Franka和“天工”的多个任务中超越了ACT。然而,BAKU在大多数任务中的成功率较低。
整体来看,RoboMIND数据集对于提升单任务模仿学习模型的性能具有比较明显的效果。
2. VLA视觉动作语言模型
在实现任务设计上,从上面提到的单任务模仿学习实验中挑选了15个由不同类型机器人完成的任务。
在机器人构型选择上,选择单臂机器人Franka、人形机器人天工、双臂机器人AgileX三种类型的机器人。
1)单臂机器人Franka :选择任务包括常见抓取和放置、推拉基础操作任务,以及需要精确操控的更细致的任务,例如抓取不同大小的物体和准确地定位机械臂以打开垃圾桶盖等。
2)人形机器人“天工”:选择任务包括两类,一类与Franka选择的任务相似,旨在评估模型在不同类型机器人上的表现。第二类涉及使用人形机器人的灵巧双手执行精确操作,例如翻转烤面包机的开关来烘烤面包,以评估模型在定位和操控方面的准确性。
3)双臂机器人AgileX:需要协调动作的双臂任务,如左臂先从架子上取下盘子,右臂再将苹果放在盘子上。
在训练和评估设置上,研究团队选择OpenVLA、RDT-1B 和CrossFormer 这三种比较主流的VLA模型进行评估。实验采用官方预训练的VLA模型,在每种类型的机器人上对它们进行多任务数据集的微调,并通过为每个任务进行10次试验来评估它们在每个单独任务上的性能,以确定所实现的泛化程度。
对于OpenVLA ,仅在Franka单臂机器人上进行了测试。对于RDT-1B和CrossFormer,在三种类型的机器人上都进行了测试。
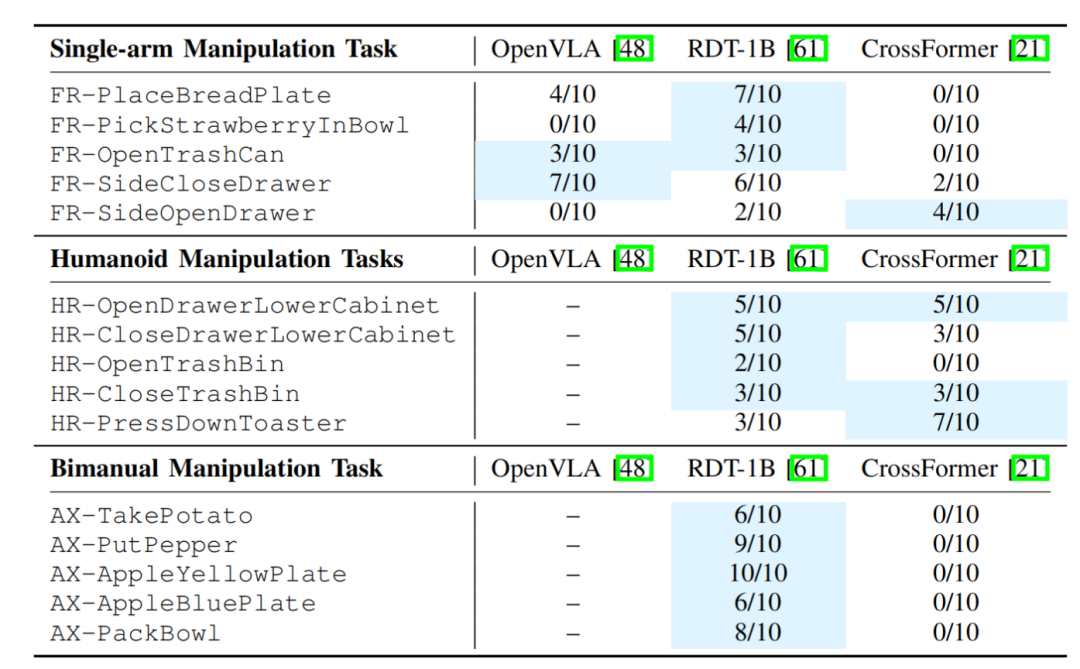
机器人使用三种不同VLA模型执行任务的成功率
备注:蓝色背景部分表示所执行任务性能为最佳;
实验结果显示:与CrossFormer和OpenVLA相比,微调后的RDT-1B在执行多种机器人模型的任务时表现出显著提升。
在单臂机器人操作任务中,尽管OpenVLA的整体表现不如RDT-1B,但在打开垃圾桶和关闭抽屉的简单任务中,两者的任务成功率水平相当。
另外,经过RoboMIND微调后,CrossFormer模型在人形机器人操作任务中性能提升的相对比较明显。
整体来看,RoboMIND数据集不仅适用于传统模仿学习算法,还能有效提升视觉语言动作模型(VLA)的泛化能力。
四、RoboMIND数据集管理
为了高效地收集、过滤和处理数据集,研究团队开发了一个智能数据管理平台,以支持大规模的数据集开发。该平台采用云原生架构和分布式计算,来处理大规模数据。该平台分为五大功能模块。
1)数据采集:利用遥操作设备从四种类型的机器人上采集数据,并将自动将采集的数据传输至数据平台。
-
单臂机器人Franka Emika Panda 和 UR5e: 采用Gello风格的遥操作设备。首先,构建与机械臂自由度(DoF)相匹配的3D打印部件和伺服电机。然后,这些3D打印部件的运动被映射到机械臂的动作,从而驱动机械臂。在此过程中,使用深度相机记录机械臂动作的RGB-D信息,并同时接收机械臂本体的状态信息。
-
双臂机器人AgileX Cobot Magic V2.0:利用与机器人Mobile ALOHA系统类似的双侧遥操作装置来采集数据集,辅助臂调节主机械臂以实现双臂操作。
-
人形机器人“天工”:结合使用Xsens动作捕捉服和Gello风格的遥操作设备。

2)数据存储:将收集的数据集以标准化HDF5 格式进行打包存储,其中包括机器人执行动作的视觉数据及机器人运动的本体感知数据。
为提升存储效率并优化数据集组织结构,研究团队将每个采集的轨迹数据(包含多视角RGB-D数据、机器人本体感知状态信息、特定末端执行器状态信息及遥操作体态信息)整合至单一HDF5格式文件中。
3)数据预处理:基于预定义标准对数据集进行过滤,评估内容包括任务执行准确性、运动轨迹平滑度,以及视觉数据中遮挡或运动模糊的存在情况。
由于数据是通过人类遥操作进行采集,那么难免就会存在由于人为原因(比如,疲劳、习惯、分心或外部干扰等)导致产生一些异常数据(比如,无效数据,或者低质量的噪声数据等)。为此,研究团队对操作员实施轮换休息制度,并提供舒适的工作环境,尽量减少人为因素带来的不利影响。
此外,研究团队定义了数据质量保证标准,并参照此标准,对收集到的数据进行全面的质量检查,以确保其可靠性。
数据质量检查包括三个步骤:
-
初步检查:快速查看视频,以确保没有明显的技术问题,如帧丢失或冻结问题。
-
详细检查:逐帧或慢动作回放视频,仔细检查是否符合质量标准。
-
数据过滤和问题记录:记录不合规数据的特定时间戳和和描述。
4)数据分类:根据机器人类型和执行的具体任务对收集的数据集进行分类。
为实现数据分类,研究团队采用任务导向型数据采集规范,将任务作为数据集的基础构成单元。数据集按任务名称进行归类,每个任务名称由以下四个核心要素共同定义:(1) 使用的具体机器人本体构型;(2) 执行的操控技能类型;(3) 任务涉及的目标物体;(4) 场景细节描述(包含物体位姿、空间拓扑关系及环境约束或干扰因子)。
Franka,Agilex 和 “天工”机器人的任务定义示例
5) 数据标注:对已采集数据集执行细粒度语言标注。
RoboMIND 数据集包含大量长周期任务,单一语义描述难以完整表征任务的复杂性与细节特征。为此,研究团队对轨迹中的每个动作提供细粒度的多层级语言标注。
标注过程包括两个主要步骤:
首先,基于Gemini 模型实现视频的时序切分与分段描述生成。该阶段根据操作序列对视频流进行时序分割,并自动生成包含操作步骤及上下文语义的文本描述。
其次,从以下关键维度对标注结果进行优化。
-
识别关键操作对象;
-
检测并描述视频中的所有关键动作;
-
操作细节描述的误差校正;
-
时间分割粒度的适应性调整;
-
时序逻辑一致性的验证与修正。
参考资料
1)论文下载链接:https://arxiv.org/pdf/2412.13877.pdf
2)项目链接 :https://x-humanoid-robomind.github.io/