GPU集群中的超节点
一、 什么是超节点?
超节点,英文名叫SuperPod,是英伟达公司最先提出的概念。
GPU是重要的算力硬件,为AIGC大模型的训推提供了有力的支撑。
随着大模型参数规模的不断增长,对GPU集群的规模需求,也在不断增长。从千卡级到万卡级,再到十万卡级,将来甚至可能更大。
二、如何构建规模越来越大的GPU集群呢?
答案很简单,就是Scale Up和Scale Out。
Scale Up,是向上扩展,也叫纵向扩展,增加单节点的资源数量。Scale Out,是向外扩展,也叫横向扩展,增加节点的数量。
Scale Up:每台服务器里,多塞几块GPU,这就是Scale Up。这时,一台服务器就是一个节点。
Scale Out:通过网络,将多台电脑(节点)连接起来,这就是Scale Out。
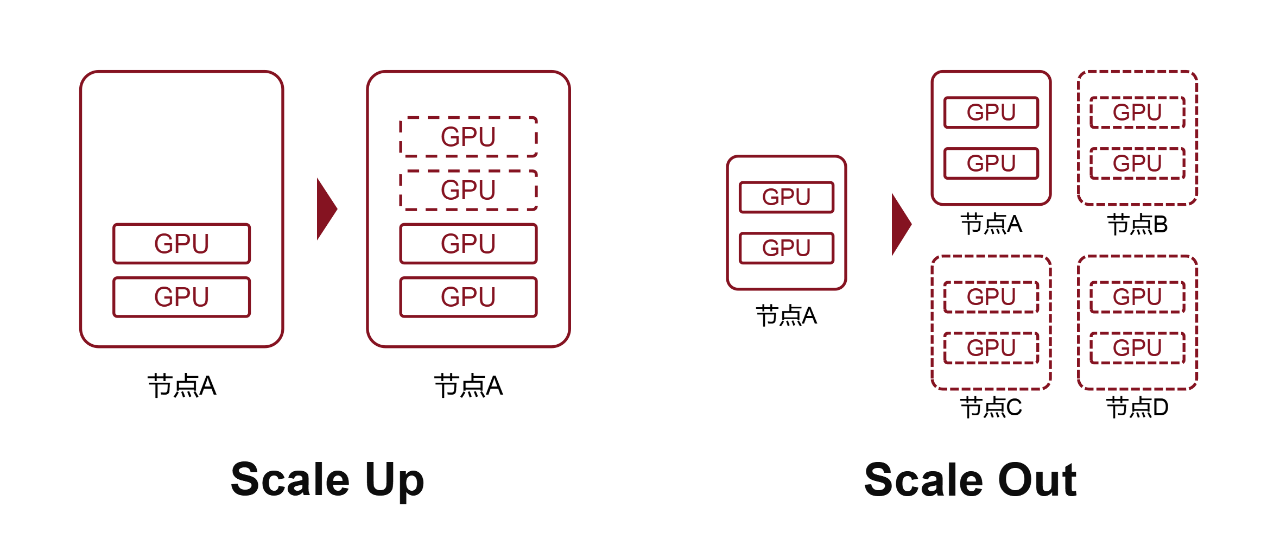
Scale Up:对于单台服务器来说,受限于空间、功耗和散热,能塞入的GPU数量是有限的,一般也就8卡、12卡。
塞入这么多块GPU,还要考虑服务器的内部通信能力是否能够支持。如果GPU互连存在瓶颈,那么就达不到Scale Up的预期效果。
计算机内部主要基于PCIe协议,数据传输速率慢,时延高,根本无法满足要求。英伟达为了解决这个问题,专门推出了自家私有的NVLINK总线协议。NVLINK允许GPU之间以点对点方式进行通信,速度远高于PCIe,时延也低得多
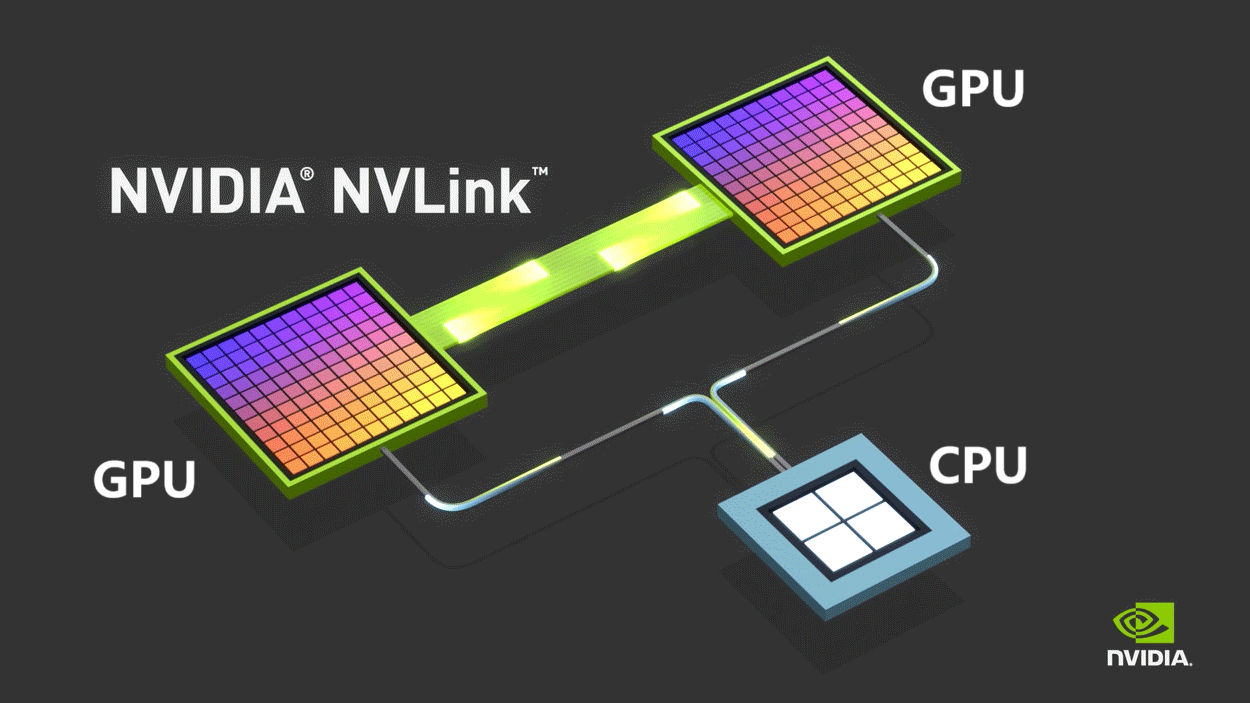
刚开始,NVLINK原本只用于机器内部通信
后来,英伟达将NVSwitch芯片独立出来,变成了NVLink交换机,用于连接服务器之间的GPU设备。这意味着,节点已经不再仅限于1台服务器了,而是可以由多台服务器和网络设备共同组成
超节点:这些设备处于同一个HBD(High Bandwidth Domain,超带宽域)。英伟达将这种以超大带宽互联16卡以上GPU-GPU的Scale Up系统,称为超节点。
三、超节点,有哪些优点?
超节点这种加强版的Scale Up,是因为在性能、成本、组网、运维等方面,能带来巨大优势。
Scale Out,考验的是节点之间的通信能力。目前,主要采用的通信网络技术,是Infiniband(IB)和RoCEv2。
这两个技术都是基于RDMA(远程直接内存访问)协议,拥有比传统以太网更高的速率、更低的时延,负载均衡能力也更强。
IB是英伟达的私有技术,起步早,性能强,价格贵。RoCEv2是开放标准,是传统以太网融合RDMA的产物,价格便宜。两者之间的差距,在不断缩小。
在带宽方面,IB和RoCEv2仅能提供Tbps级别的带宽。而Scale Up,能够实现数百个GPU间10Tbps带宽级别的互联。
在时延方面,IB和RoCEv2的时延时延高达10微秒。而Scale Up对网络时延的要求极为严苛,需要达到百纳秒(100纳秒=0.1微秒)级别。
在AI训练过程中,包括多种并行计算方式,例如TP(张量并行)、 EP(专家并行)、PP(流水线并行)和DP(数据并行)。
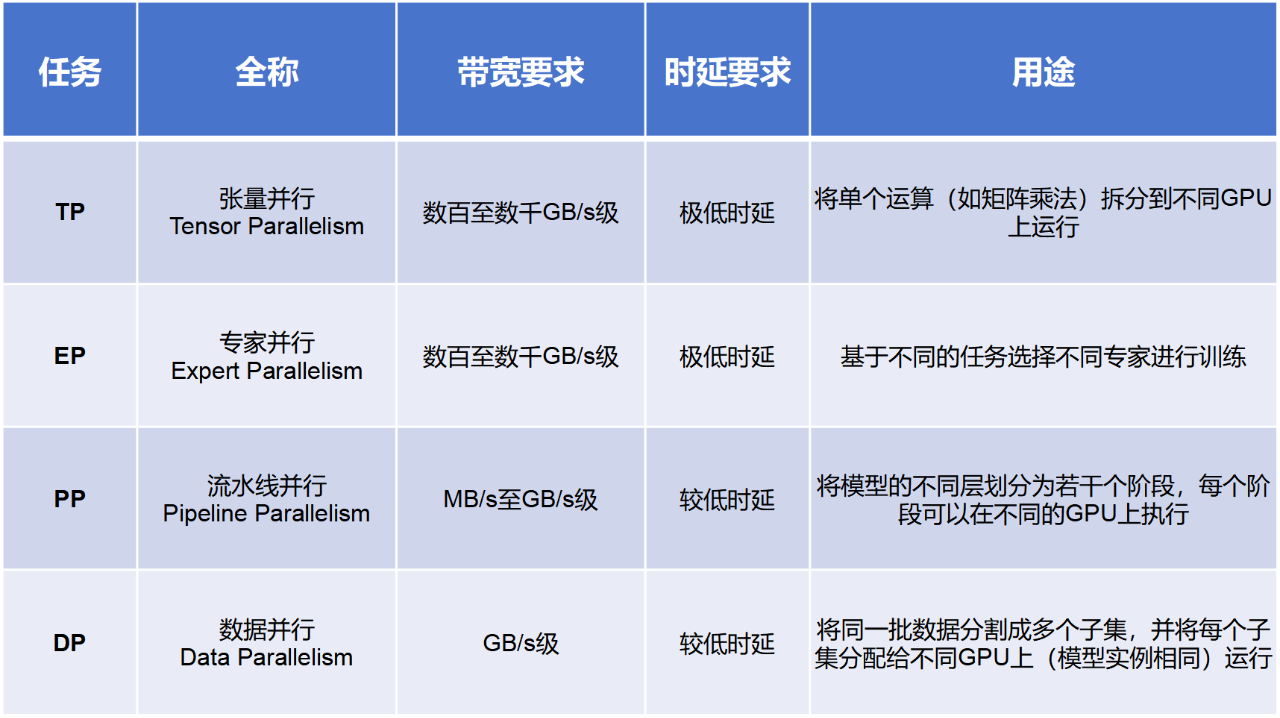
通常来说,PP和DP的通信量较小,一般交给Scale Out搞定。而TP和EP的通信量大,需要交给Scale Up(超节点内部)搞定
超节点,作为Scale Up的当前最优解,通过内部高速总线互连,能够有效支撑并行计算任务,加速GPU之间的参数交换和数据同步,缩短大模型的训练周期。
超节点一般也都会支持内存语义能力,GPU之间可以直接读取对方的内存,这也是Scale Out不具备的。
超节点一般也都会支持内存语义能力,GPU之间可以直接读取对方的内存,这也是Scale Out不具备的。
四、站在组网和运维的角度来看,超节点也有明显优势。
超节点的HBD(超带宽域)越大,Scale Up的GPU越多,Scale Out的组网就越简单,大幅降低组网复杂度。
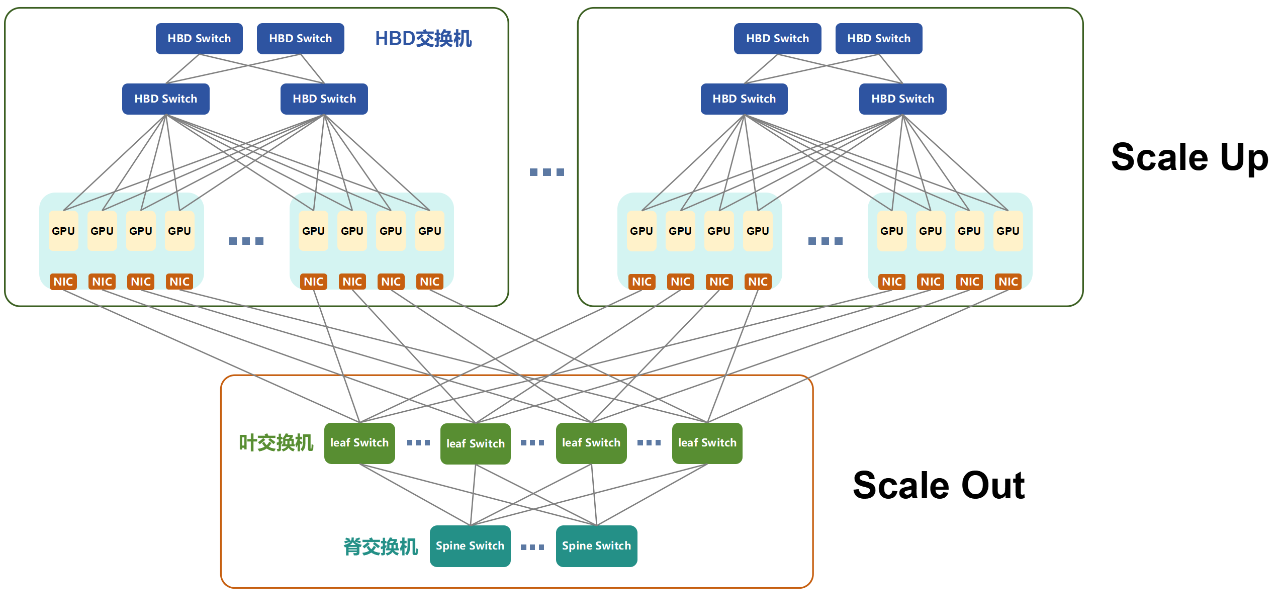
超节点的优势,就是增加局部的带宽,减少增加全局带宽的成本,以此获得更大的收益。
五、 超节点,有哪些可选的方案
1、私有协议方案
华为 发布的AI核弹级技术——CloudMatrix 384超节点,也属于私有协议。
CloudMatrix 384以384张昇腾算力卡组成一个超节点,在目前已商用的超节点中单体规模最大,可提供高达300 PFLOPs的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。

2、开放组织方案。
有私有协议,当然就会有开放标准。互联网时代,开放解耦是大势所趋。
私有协议往往意味着高昂的成本。对于AI这个热门方向来说,发展开放标准,有利于降低行业门槛,帮助实现技术平权。
目前来看,超节点的开放标准还不止一个,但基本上都是以以太网技术(ETH)为基础。因为以太网技术最成熟、最开放,也拥有最多的参与企业。
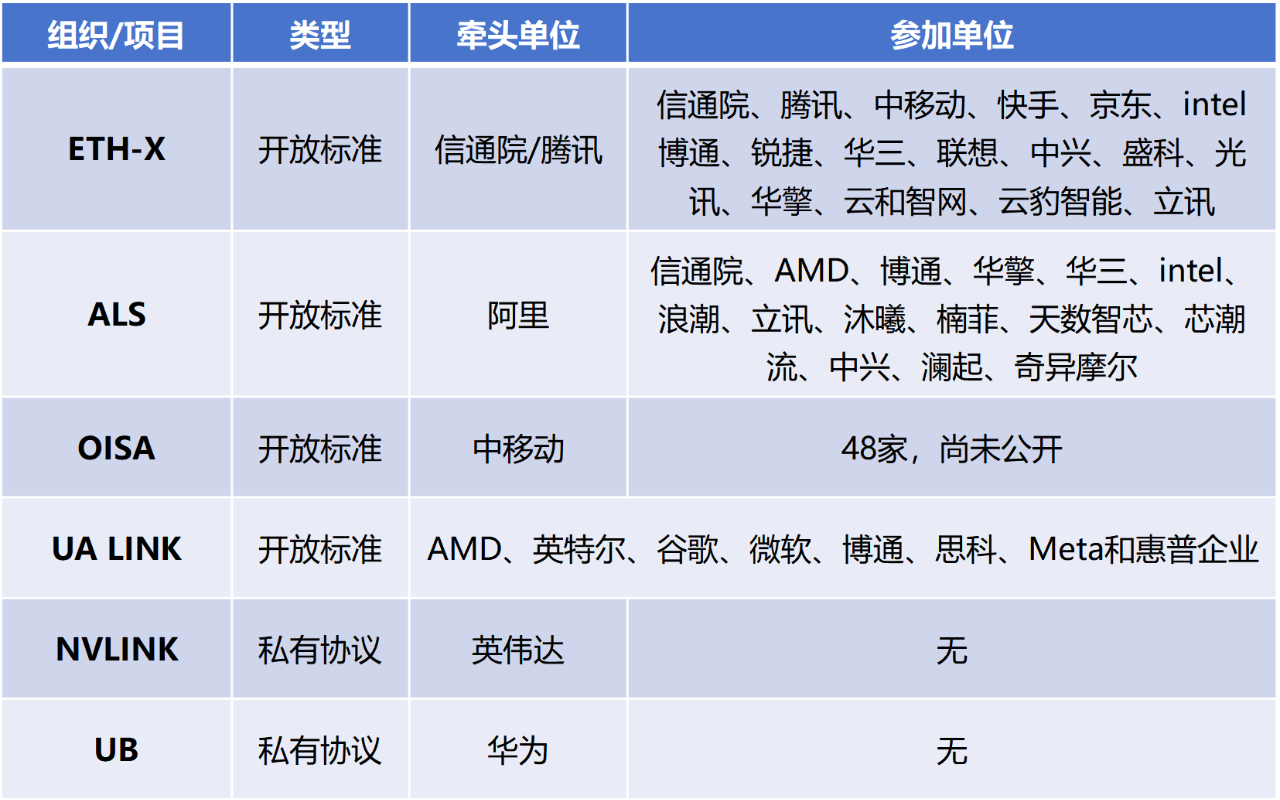
ETH-X不仅包括了Scale Up,也包括了Scale Out。典型的组网拓扑,如下图所示:
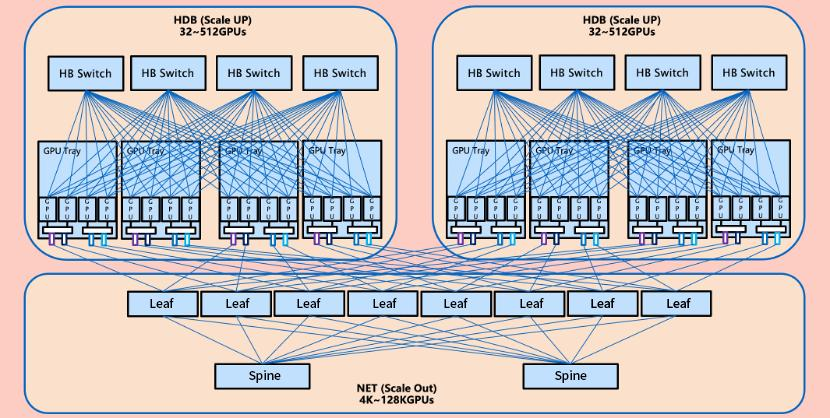
ETH-X开放超节点的实物架构
机柜包括计算节点、交换节点和关键组件。
关键组件中,Cable Tray

ETH-X超节点AI Rack采用机柜铜连接方案。而Cable Tray,就是实现各个子系统硬件互通的高速铜缆方案,也是提供高速互连能力的重要连接器硬件。
英伟达的最新NVLINK方案,也用的Cable Cartridge方案。在短距传输场景,相对于光纤,机柜内采用铜连接,可以实现高可靠性和低成本(减少了光模块的使用),也有利于布线。目前看来,在Scale Up内部使用铜缆直连技术,已经是一个主流趋势。