AI Engine Kernel and GraphProgramming--知识分享1
Overview
AI引擎是一系列超长指令字(VLIW)处理器,具有单指令多数据(SIMD)向量单元,针对计算密集型应用进行了高度优化,特别是数字信号处理(DSP)、5G无线应用和机器学习(ML)等AI技术。
AI引擎阵列支持三个级别的并行性:
·指令级并行性(ILP):通过VLIW架构,允许在单个时钟周期内执行多个操作。
· SIMD:通过向量寄存器,允许并行计算多个元素(例如,八个)。
·多核:通过AI引擎阵列,允许多达400个AI引擎并行执行。
指令级并行性包括一个标量操作、最多两个移动、两个向量读取(加载)、一个向量写入(存储)和一个可执行的向量指令--每个时钟周期总共执行一条7路VLIW指令。数据级并行是通过向量级操作实现的,其中多组数据可以在每个时钟周期的基础上操作。
每个AI引擎都包含一个矢量和标量处理器、专用程序内存、本地32 KB数据内存、对本地内存的访问以及三个相邻的AI引擎,方向取决于它所在的行。它还可以访问DMA引擎和AXI 4互连交换机,以通过流与其他AI引擎或可编程逻辑(PL)或DMA进行通信。有关AI引擎阵列和接口的详细信息,请参阅 Versal Adaptive SoC AI Engine系列的前七期知识分享。
虽然大多数标准C代码都可以为AI引擎编译,但代码可能需要重新构造,以充分利用硬件提供的并行性。AI引擎的强大之处在于它能够使用两个向量执行乘法累加(MAC)操作,为下一个操作加载两个向量,存储来自前一个操作的向量,并在每个时钟周期中递增指针或执行另一个标量操作。称为intrinsic的专用函数允许您针对AI Engine矢量和标量处理器,并提供几个常见矢量和标量函数的实现,因此您可以专注于目标算法。除了向量单元,AI引擎还包括一个标量单元,可用于非线性函数和数据类型转换。
AI引擎程序由用C++编写的数据流图(自适应数据流图)规范组成。此规范可以使用AI Engine编译器编译和执行。自适应数据流(ADF)图应用程序由节点和边组成,其中节点表示计算内核函数,边表示数据连接。应用程序中的内核可以编译为在AI引擎上运行,并且是ADF图形规范的基本构建块。ADF图是一个修改后的Kahn过程网络,其中AI引擎内核并行运行。AI引擎内核对数据流进行操作。这些内核消耗输入数据块并产生输出数据块。内核行为可以使用静态数据或运行时参数(RTP)参数进行修改,这些参数可以是异步的,也可以是同步的。
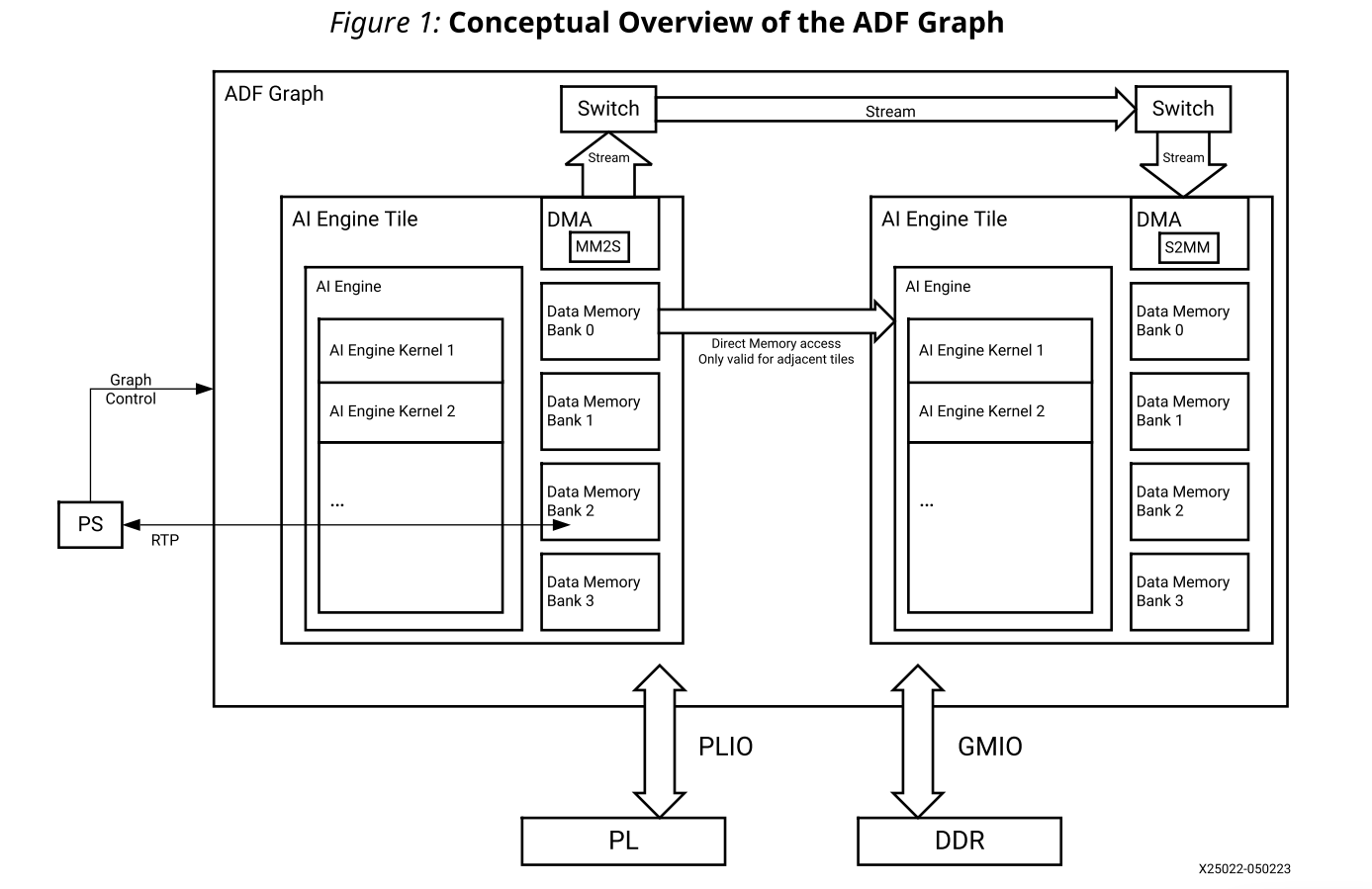
下图显示ADF图形及其与处理系统(PS)、可编程逻辑(PL)和DDR内存的接口的概念视图。它包括以下内容:
· AI引擎:每个AI引擎都是一个VLIW处理器,包含一个标量单元,一个向量单元,两个加载单元和一个存储单元。
· AI引擎内核:内核是在AI引擎中运行的C/C++编写的。
· ADF图:该图由单个AI引擎内核或通过数据流和/或缓冲区连接的多个AI引擎内核组成。它与PL、全局内存和PS交互,具有特定的结构,如PLIO(图形编程中的端口属性,用于与可编程逻辑进行流连接)、GMIO(图形编程中的端口属性,用于与全局内存进行外部内存映射连接)和RTP。
AI引擎内核AI引擎内核是一个使用专门的内在函数编写的C++程序。这些内在函数针对AI引擎处理器的不同功能单元,如VLIW矢量和标量单元。AI引擎内核代码使用AMD葡萄属™核心开发工具包中包含的AI引擎编译器进行编译。AI引擎编译器编译内核以生成在AI引擎处理器上运行的ELF文件。
AI引擎架构回顾
AI引擎阵列由AI引擎瓦片的2D阵列组成,其中每个AI引擎瓦片包含AI引擎、内存模块和瓦片互连模块。AI Engine是一款高度优化的处理器,具有单指令多数据(SIMD)和超长指令字(VLIW)指令集架构,包含六个功能单元:标量、向量、两个加载、一个存储和一个指令提取和解码。一条VLIW指令最多可以支持两个加载、一个存储、一个标量操作、一个定点或浮点向量操作以及两个移动指令。还有一个可用的内存模块,在其北、南、东或西AI引擎邻居之间共享,具体取决于阵列内瓦片的位置。AI引擎可以访问它的北、南、东或西,以及它自己的内存模块。
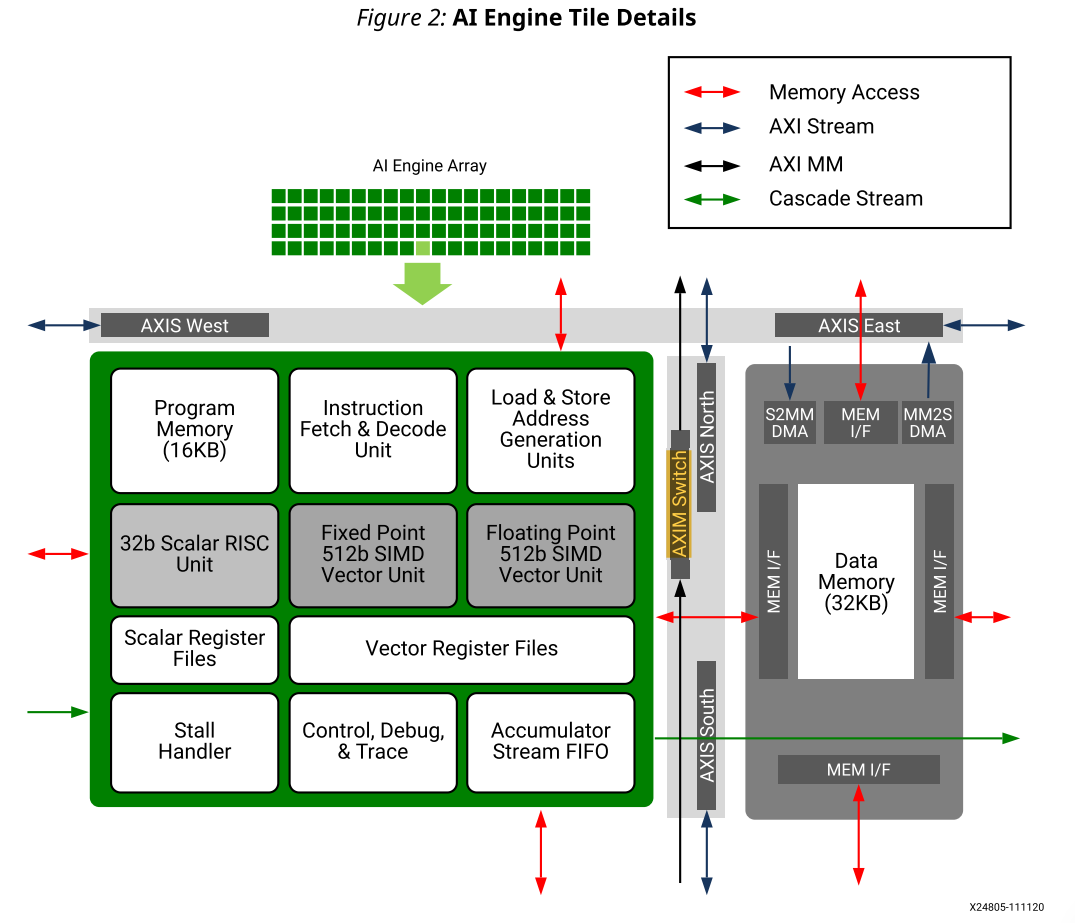
每个AI引擎模块都有一个AXI 4-Stream交换机,这是一个完全可编程的32位AXI 4-Stream交叉开关。它支持电路交换和分组交换流与背压。通过MM 2S DMA和S2 MM DMA,AXI 4-Stream开关提供了对AI Engine数据存储器的流访问。该交换机还包含两个16深33位(32位数据+ 1位TLAST)宽FIFO,通过将其中一个FIFO的输出电路交换到另一个FIFO的输入,可以将其链接形成32深FIFO。
AI引擎内存
每个AI引擎都有16 KB的程序内存,可以存储1024条128位的指令。AI引擎指令的宽度为128位(最大),支持多种指令格式,以及可变长度指令,以减少程序内存大小。优化的内部循环之外的许多指令可以使用较短的格式。
每个AI引擎模块都有8个数据存储体,其中每个存储体(单个存储体)是256字x 128位单端口存储器(总共32 KB)。每个AI引擎可以访问来自相邻区块的三个存储器,加上自己的数据存储器,总共128 kB。堆栈是数据存储器的子集。堆栈大小和堆大小的默认值为1 KB。当优化级别大于零(对于AI Engine编译器,xlopt>=1)时,编译器可以自动计算和调整堆大小。堆栈大小和堆大小可以使用编译器选项或源代码中的约束来更改。
在逻辑表示中,128 KB存储器可以被视为一个连续的128 KB块或四个32 KB块,并且每个块可以被划分为四个奇数组和四个偶数组。一个偶数存储体和一个奇数存储体被交错以包括双存储体。AI引擎阵列边缘的AI引擎具有较少的邻居,相应地可用内存较少。
每个存储器端口以256位/128位向量寄存器模式或32位/16位/8位标量寄存器模式运行。256位端口由偶数和奇数配对的存储体创建。8位和16位存储被实现为读-修改-写指令。如果每个端口访问不同的存储体,则支持所有三个端口的并发操作。
存储在内存中的数据是小端格式。
每个AI引擎都有一个DMA控制器,分为两个独立的模块,S2MM用于将流数据存储到内存(32位数据),MM2S用于将内存的内容写入流(32位数据)。每个S2MM和MM2S具有两个独立的数据通道。
单核编程
AI引擎内核是一个使用专门的内部函数编写的C++程序。这些固有函数针对AI Engine处理器的不同功能单元,例如VLIW矢量和标量单元。AI引擎内核代码使用AI引擎编译器进行编译,该编译器包含在AMD葡萄属™核心开发工具包中。AI引擎编译器编译内核以生成在AI引擎处理器上运行的ELF文件。
AI引擎支持用于矢量处理的专用数据类型和函数。通过用这些API函数和向量数据类型重构一些标量应用程序代码,可以创建快速高效的向量化代码。编译器负责将函数映射到操作,执行寄存器分配和数据移动,调度和生成微码。该微码被有效地打包成VLIW指令。以下章节介绍AI Engine内核支持的数据类型和可用的寄存器。此外,还描述了向量API函数,其初始化、加载和存储以及使用适当的数据类型对向量寄存器进行操作。
为了在AI引擎上实现最高性能,单核编程的主要目标是确保向量处理器的使用接近其理论最大值。算法的矢量化很重要,但也需要管理矢量寄存器、存储器访问和软件流水线。程序员必须努力使新操作的数据在当前操作执行时可用,因为向量处理器能够在每个时钟周期进行操作。使用编译指示可以在循环中使用软件流水线进行优化。例如,当内部循环具有顺序或循环承载的依赖关系时,可以展开外部循环并并行计算多个值。下面几节也将讨论这些概念。
AI引擎API
AI Engine API是用于AI Engine内核编程的可移植编程接口。此API接口针对当前和未来的AI引擎架构。
该接口提供了可参数化的数据类型,支持泛型编程,并以统一的方式跨不同的数据类型实现最常见的操作。与使用内部函数相比,它是一种更容易的编程接口。它被实现为一个C++头文件库,可以转换为优化的内部函数。对于需要使用intrinsic编程的高级用户,请参阅AI Engine Intrinsic User Guide(UG1078)。AI Engine API用户指南组织如下:
· API参考:
·基本类型
·内存
·存储器
·算术
·比较
·归约
·整形
·浮点转换
·初等函数
·矩阵乘法
·快速傅立叶变换(FFT)
·特殊乘法
·运算符重载
·与自适应数据流(ADF)的互操作性图形抽象

kenel 编程
AI引擎编译器支持专用指令,以实现高效的循环调度。还包括用于减少内存依赖性和删除函数层次结构的附加杂注,同时进一步优化内核性能。在本文档中可以找到使用这些杂注的示例。内核编码中使用的所有编译指示和函数的列表可以在ASIP Programmer Chess Tooler用户手册中找到,该手册可以在Versal AI Engines Secure Site中找到。
kernel 编译器
AI引擎编译器(v++-c--模式aie)用于编译AI引擎内核代码。《AI引擎工具和流程用户指南》(UG1076)中的编译AI Engine图形应用程序详细介绍了AI Engine编译器的用法、可用选项、可以传入的输入文件和预期输出。
kernel 模拟
要模拟AI Engine内核,您需要编写一个AI Engine图形应用程序,其中包含用C++编写的数据流图规范。该图包含AI Engine内核,测试台数据作为内核的输入提供。来自内核的数据输出可被捕获为模拟输出,并与黄金参考数据进行比较。该规范可以使用AI引擎编译器(v++ -c --mode aie)编译和执行。可以使用aiesimulator来模拟该应用程序。有关aiesimulator的更多详细信息,请参见《AI引擎工具和流程用户指南》(UG 1076)中的“模拟AI引擎图形应用程序”。
kernel 输入输出
AI引擎内核对数据流或数据块进行操作。AI引擎内核对特定类型的数据进行操作,例如int 32和cint 32。内核使用的数据块存储在缓冲区中。内核消耗输入流和/或缓冲区,并产生输出流和/或缓冲区。内核以逐个样本的方式访问数据流。
精彩文章,请关注订阅号:威视锐科技