视觉问答论文解析:《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》
《Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning》论文解析
一、研究背景与动机
近年来,“慢思考”多模态模型(如 OpenAI-o1、GeminiThinking、Kimi-1.5 和 Skywork-R1V)在数学和科学领域的复杂推理任务中取得了显著进展。这些模型通过模仿反思性认知过程,在数学和科学基准测试中的表现比“快思考”模型(如 GPT-4o 和 Claude3.5)高出 30%以上。然而,将慢思考策略扩展到多模态领域带来了新的挑战:在视觉推理任务(如 MMMU 和 MathVision)上表现提升的同时,通用感知基准测试(如 AI2D)上的性能却有所下降,且伴随着视觉幻觉现象的增加。如何在视觉 - 语言模型(VLMs)中有效促进慢思考行为而不损害其泛化能力成为关键问题。Skywork R1V2 应运而生,它通过直接强化学习(RL)而非教师模型蒸馏来获得多模态推理技能,并采用混合强化学习范式,结合混合偏好优化(MPO)和组相对策略优化(GRPO),以平衡推理能力和泛化能力。
二、研究方法
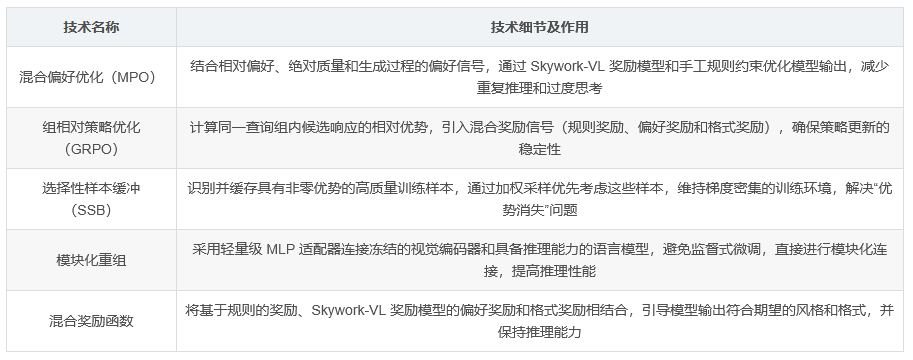
(一)高效多模态迁移的模块化重组
为减少对大规模多模态推理数据的依赖,Skywork R1V2 将视觉 - 语言表示的对齐与推理能力的保持解耦。具体来说,引入轻量级多层感知机(MLP)适配器(fc)来连接冻结的视觉编码器(fv)和具备推理能力的语言模型(fl)。其中,视觉编码器选用 InternViT-6B,语言模型选用 QwQ-32B。给定视觉输入 xv 和文本输入 xt,整体过程表示为 y = fl(fc(fv(xv)), xt)。与第一代 R1V 不同,R1V2 省略了监督式微调(SFT)阶段,而是采用模块化方法直接连接预训练推理语言模型与视觉适配器。实验表明,文本和视觉能力具有高度迁移性,改进某一模态可直接使另一模态受益。
(二)混合偏好优化(MPO)
MPO 是 R1V2 优化流程中的关键部分,其损失函数可表示为 L = w1Lpreference + w2Lquality + w3Lgeneration。其中,Lpreference 为 DPO 损失,用于优化正负样本之间的相对偏好;Lquality 为 BCO 损失,有助于模型理解单个响应的绝对质量;Lgeneration 为负对数似然损失(NLL),指导模型学习所选响应。MPO 策略能够将 Skywork-VL 奖励模型的偏好信号与手工规则约束相结合,使模型输出更好地符合风格偏好和事实要求。
(三)强化微调
在强化微调阶段,主要采用 GRPO 算法,并引入选择性样本缓冲(SSB)机制以增强强化学习过程的效率。
-
GRPO 算法与混合奖励信号 :GRPO 是一种策略优化算法,通过在特定查询的生成响应组内进行比较来计算逐标记优势估计。对于给定输入实例 x,行为策略 πθold 采样一批候选响应 {yi}Ni=1。第 i 个响应在时间步 t 的优势 Ai,t 通过标准化响应组内获得的奖励来确定。为减轻推理能力的“对齐税”,再次利用 Skywork-VL 奖励模型引入偏好奖励信号 rθ,补充基于规则的奖励 rrule,并加入格式奖励 rformat 以使模型输出与 DeepSeek R1 风格的聊天模板对齐。最终的混合奖励函数定义为 r(x, yi) = rrule(x, yi) + rθ(x, yi) + rformat(x, yi)。GRPO 优化目标包含一个剪切代理损失项和 KL 惩罚项,以确保策略更新的稳定性。
-
通过 SSB 解决“优势消失”问题 :直接将 GRPO 应用于 VLMs 时,会遇到“优势消失”现象,即查询组内所有响应趋向于统一正确或错误,导致相对优势信号减弱,阻碍基于梯度的策略更新。SSB 机制通过识别并缓存之前迭代中具有非零优势的高质量训练样本,并通过加权采样优先考虑这些样本,将其重新引入策略更新中,从而维持梯度密集的训练环境,提高训练效率。
三、实验
(一)实验设置
-
基准测试 :在文本推理基准测试方面,包括 AIME 2024、LiveCodebench、LiveBench、IFEVAL 和 BFCL;在多模态推理基准测试方面,包括 MMMU、MathVista、OlympiadBench、MathVision 和 MMMU-Pro。所有基准测试的最大生成长度均设置为 64K 令牌,采用统一的评估框架 LLM Judge(OpenAI-o4)进行评估,报告的性能指标为 Pass@1 分数,平均 5 次独立运行结果,以确保统计可靠性。
-
基线模型 :与包括 Claude-3.5-Sonnet、OpenAI-o4-mini、OpenAI-o1、Gemini 2 Flash 和 Kimi k1.5 longcot 等在内的多种专有模型,以及 Skywork-R1V1、InternVL3-38B、QvQ-Preview-72B、Deepseek R1 和 Qwen2.5-VL-72B-Instruct 等先进开源模型进行比较。
(二)主要结果
-
文本推理性能 :Skywork R1V2 在 AIME24 上达到 78.9%,在 LiveCodebench 上达到 63.6%,在 LiveBench 上达到 73.2%,在 IFEVAL 上达到 82.9%,在 BFCL 上达到 66.3%,相较于前代模型 R1V1 在各基准测试中均有显著提升,且在 LiveBench 和 BFCL 上优于参数规模更大的 Deepseek R1。
-
多模态推理性能 :在 MMMU 上取得 73.6%,在 MathVista 上取得 74.0%,在 OlympiadBench 上取得 62.6%,在 MathVision 上取得 49.0%,在 MMMU-Pro 上取得 52.0%,超出同类参数规模的开源模型,并在 MMMU 上超越 Qwen2.5-VL-72B 和 QvQ-Preview-72B 等更大模型。与专有模型相比,在 MMMU 基准测试中超越 Claude 3.5 Sonnet、Gemini 2 Flash 和 Kimi k1.5 longcot,在 MathVista 上与 Gemini 2 Flash 和 Kimi k1.5 longcot 竞争,缩小了与 OpenAI-o4-mini 等更大专有模型的差距。
-
通用视觉任务性能 :尽管 R1V2 专注于推理能力,但在文档理解任务上仍保持竞争力,在 AI2D 上达到 81.3%,在 ChartQA 上达到 79.0%,在 TextVQA 上达到 79.0%;在视频理解方面,VideoMME 上达到 60.2%,MVBench 上达到 61.5%,在需要时间推理的任务中表现出色,MMBench-Video 上得分为 1.92。通过 MPO 方法,幻觉率从标准 SFT 的 18.4% 降低到 8.7%,在保持合理事实准确性(RealWorldQA 上为 68.9%)的同时,在复杂推理任务上表现出色。
(三)定性分析
通过物理推理示例和数学推理示例展示了 R1V2 的推理能力。在物理推理方面,面对涉及旋转磁场和交流发电机的电磁问题,R1V2 能够正确识别交流电频率取决于磁铁的旋转速度而非线圈匝数;在数学推理方面,针对中国高考中的三维几何问题,R1V2 能够系统地分解问题、进行精确数学计算并验证解决方案的正确性。
(四)消融研究
-
选择性样本缓冲(SSB)机制的效果 :SSB 机制显著提高了模型性能,在 MMMU 上达到 73.6%(无 SSB 时为 73.4%),在保持 MathVista 强劲性能(74.0%)的同时,有效样本比例保持在 60% 以上,而无 SSB 时低于 40%,有效解决了“优势消失”问题。
-
SFT 与 MPO 与混合方法的比较 :MPO 在减少事实错误方面表现出色,幻觉率仅为 8.7%,在复杂数学推理任务上,MPO 在 AIME 2024 上达到 79.0%,在 OlympiadBench 上达到 60.6%,显著优于 SFT。混合方法(MPO+GRPO)进一步提高了泛化能力,在 OlympiadBench 上达到 62.6%,在 AIME 2024 上接近最优性能(78.9%),成功平衡了推理能力与泛化能力。
-
组件激活配置分析 :仅激活适配器的训练方式在所有基准测试中均取得了最佳结果,而激活语言模型(LLM)+ 适配器或适配器 + 视觉编码器的配置性能较低,表明主要收益来自改善视觉特征与语言处理之间的对齐,而非增强视觉编码本身。
-
MPO 阈值分析 :较高的阈值(如 15)相较于较低阈值(如 7)可使训练动态更稳定,模型在较少迭代次数下取得更好最终性能。较低阈值会出现初始性能提升随后下降的现象,而较高阈值能保持更一致的性能,这与奖励黑客现象观察结果一致。
四、结论与未来工作
Skywork R1V2 通过结合 GRPO、SSB 和 MPO 的混合强化学习方法,在多个推理和视觉基准测试中取得显著进步,为开源多模态模型设立了新标准。MPO 借助 Skywork-VL 奖励模型增强了 R1V 模型的对齐,有效减少了重复推理,同时保持了稳健的泛化能力;SSB 通过战略性保留具有明显优势信号的高质量示例,实现了稳定的策略更新。研究发现推理能力和视觉幻觉之间存在重要权衡,凸显了强化学习过程中精心校准奖励的必要性。未来工作将探索视觉与文本模态之间更复杂的集成机制,进一步细化推理与泛化之间的平衡,并将混合强化学习方法扩展到其他领域和模态。