大语言模型 06 - 从0开始训练GPT 0.25B参数量 - MiniMind 实机配置 GPT训练基本流程概念
写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。

训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)
数据准备阶段
数据来源
GPT模型的效果离不开海量数据支持,主要来源包括:
• 开源网络文本(如Common Crawl)
• 开放图书(如Project Gutenberg)
• 维基百科
• 编程数据(GitHub代码库等)
• 学术文献(如arXiv)
• 对话数据、问答数据(如StackExchange、Reddit)
为了提高模型质量,OpenAI 等机构通常会使用多阶段过滤系统对数据进行清洗与优选。
数据清洗与去重
- 语言识别与筛选(仅保留英文/中文等目标语言)
- 去除重复内容(MinHash、SimHash 等技术)
- 垃圾内容过滤(色情、广告、错误文本)
- 格式标准化(HTML解析、换行统一等)
Tokenization
使用 BPE(Byte Pair Encoding) 或 SentencePiece 对文本进行子词级别的编码,转为Token序列。例如
"unbelievable" → ["un", "believ", "able"]
预训练阶段(Pretraining)
模型结构
GPT是基于 Transformer解码器结构 构建的自回归模型。主要组件包括:
- 多层 Transformer Block(如GPT-3使用96层)
- 多头自注意力(Self-Attention)
- 前馈网络(MLP)
- LayerNorm、Residual连接
训练目标
使用 自回归语言建模目标(Causal Language Modeling, CLM):
给定前 n 个 token,预测第 n+1 个 token 的概率:
Loss = − ∑ t = 1 T log P ( x t ∣ x < t ) \text{Loss} = -\sum_{t=1}^{T} \log P(x_t | x_{<t}) Loss=−t=1∑TlogP(xt∣x<t)
超参数与训练规模(以 GPT-3 为例)
- 参数量:175B(即1750亿)
- Batch Size:约3.2M tokens
- 学习率:带warm-up + cosine decay
- 训练轮数:通常为几轮完整数据遍历(epoch)
- 训练时长:数周至数月
- 硬件:高达数千块A100 GPU并行训练
优化器与技巧
- AdamW 优化器
- Mixed Precision(混合精度训练):FP16/FP8 提高训练效率
- Gradient Accumulation:减少显存使用
- ZeRO, Megatron, DeepSpeed:用于大规模分布式并行训练
指令微调(Instruction Tuning)
- 目的:让模型更好地理解人类意图与任务指令。
- 方法:引入人工构造的 指令数据集(如 self-instruct, FLAN, open-instruct),训练模型执行命令式语言。
PS:微调通常使用较小的 Batch Size 和较低学习率,避免遗忘原始语言能力。
举个例子:
指令:请总结这段文本的重点。
输入:……
输出:……
对齐阶段(Alignment)
为了使模型行为更加符合人类期望,还需要额外“对齐”步骤。
RLHF(Reinforcement Learning with Human Feedback)
流程:
- 使用多个模型输出 → 人类打分排序(偏好数据)
- 训练一个 Reward Model
- 用PPO(Proximal Policy Optimization)训练GPT主模型,最大化得分
该方法用于 GPT-3.5 / ChatGPT。
DPO(Direct Preference Optimization)
一种比RLHF更稳定的替代方法,不再使用强化学习,而是直接优化模型输出排序概率。
推理与部署
完成训练后的模型通过以下方式部署:
- 量化(Quantization):如INT8、FP8,减小模型大小
- 蒸馏(Distillation):训练小模型模拟大模型输出
- KV Cache:提升推理速度
- 并行策略:如Tensor并行、Pipeline并行
其他补充
- 多语言训练:通过多语种数据混合,GPT能掌握中文、英文等多种语言。
- 安全性与审查:在训练数据清洗、微调、对齐过程中均会加入安全审查策略,过滤不当言论和偏见。
基本介绍
https://github.com/jingyaogong/minimind.git
基本配置
克隆项目
git clone https://github.com/jingyaogong/minimind.git
cd minimind
这里是下载 ZIP 然后解压的,也可以git克隆。
环境配置
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
对应的结果如下所示,安装需要的依赖:
下载数据
(这里注意,该命令是全部的数据,目前来看是20GB+,如果不是完整的实验,可以选几个必须的即可。)
git lfs install
git clone https://www.modelscope.cn/datasets/gongjy/minimind_dataset.git
仓库的内容如下所示:
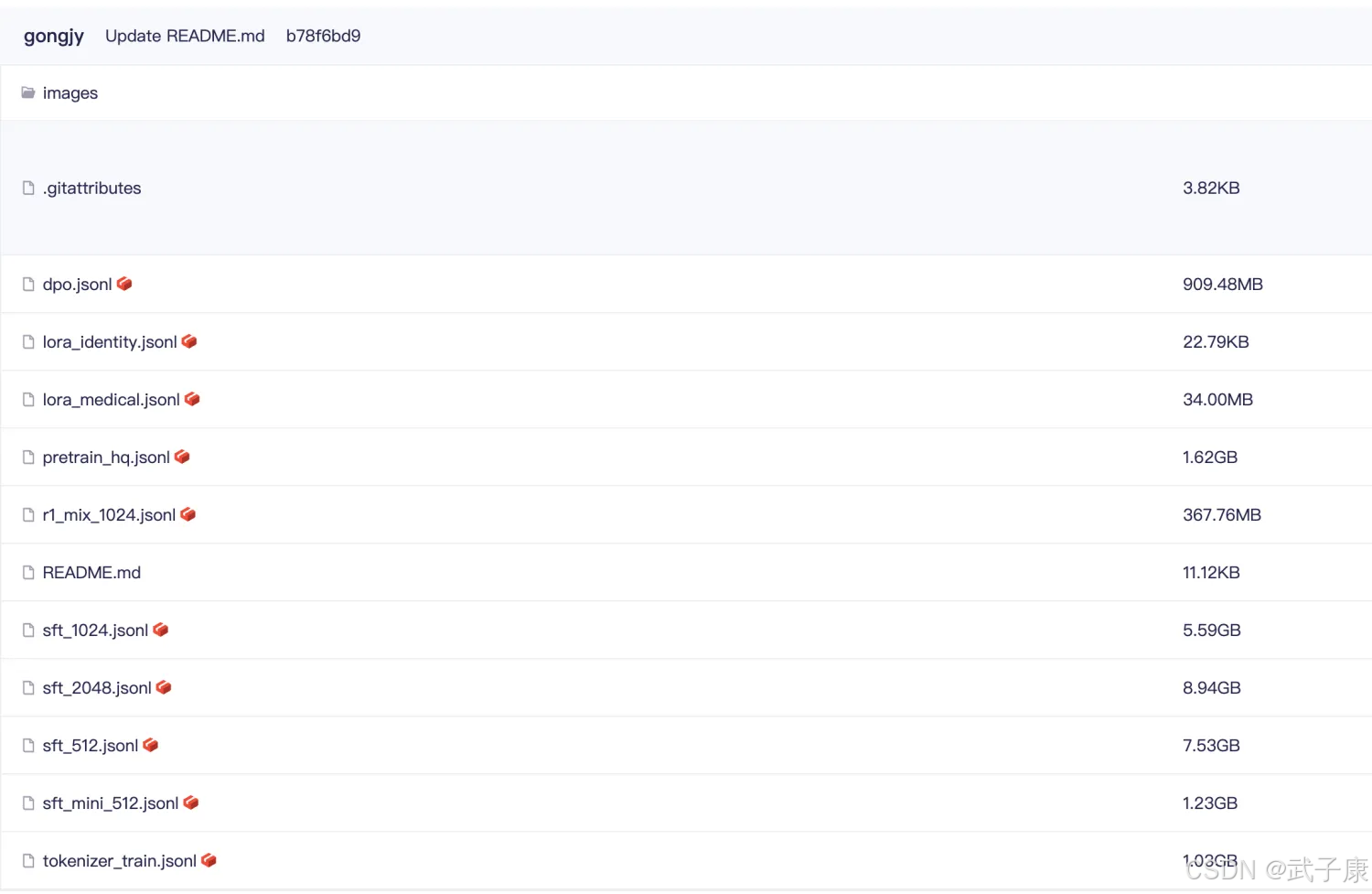
并不是都需要下载,为了最小成本启动,下载:
● pretrain_hq.jsonl 1.6GB
● sft_mini_512.jsonl 1.2GB
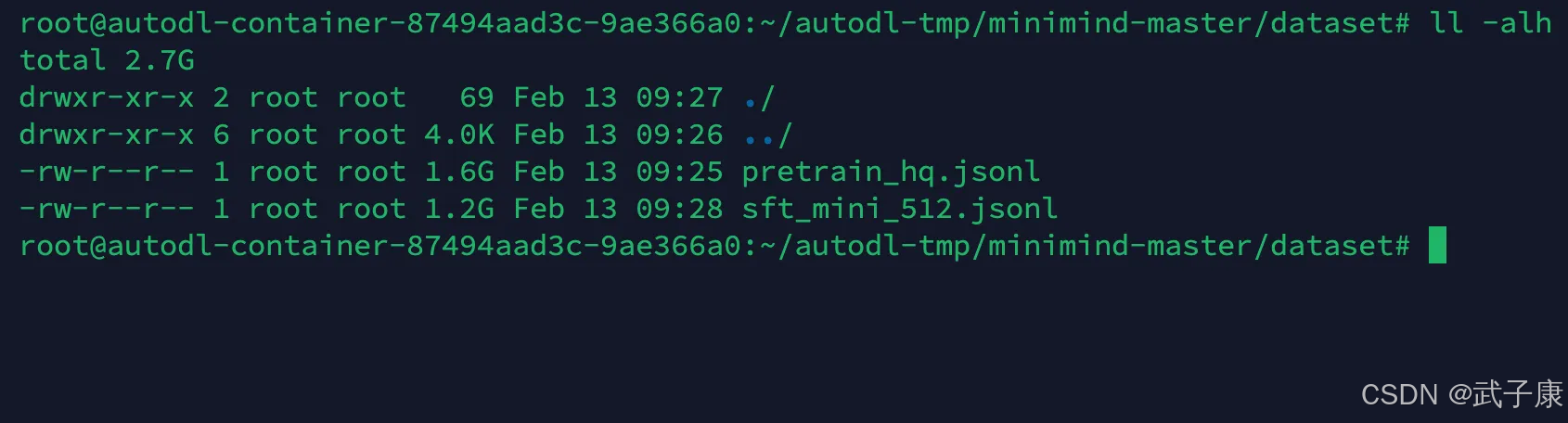
如果是最小成本下载,使用如下的方式,下载之后确认一下是否正确:
mkdir dataset
cd datasetwget https://www.modelscope.cn/datasets/gongjy/minimind_dataset/resolve/master/pretrain_hq.jsonlwget https://www.modelscope.cn/datasets/gongjy/minimind_dataset/resolve/master/sft_mini_512.jsonl正在下载pretrain_hq:
正在下载sft_mini_512:
下载完毕后,在当前路径下可以看到如下的结果,可能需要改个名: