【SAM2代码解析】数据集处理3--混合数据加载器(DataLoader)
前情提要—trainer
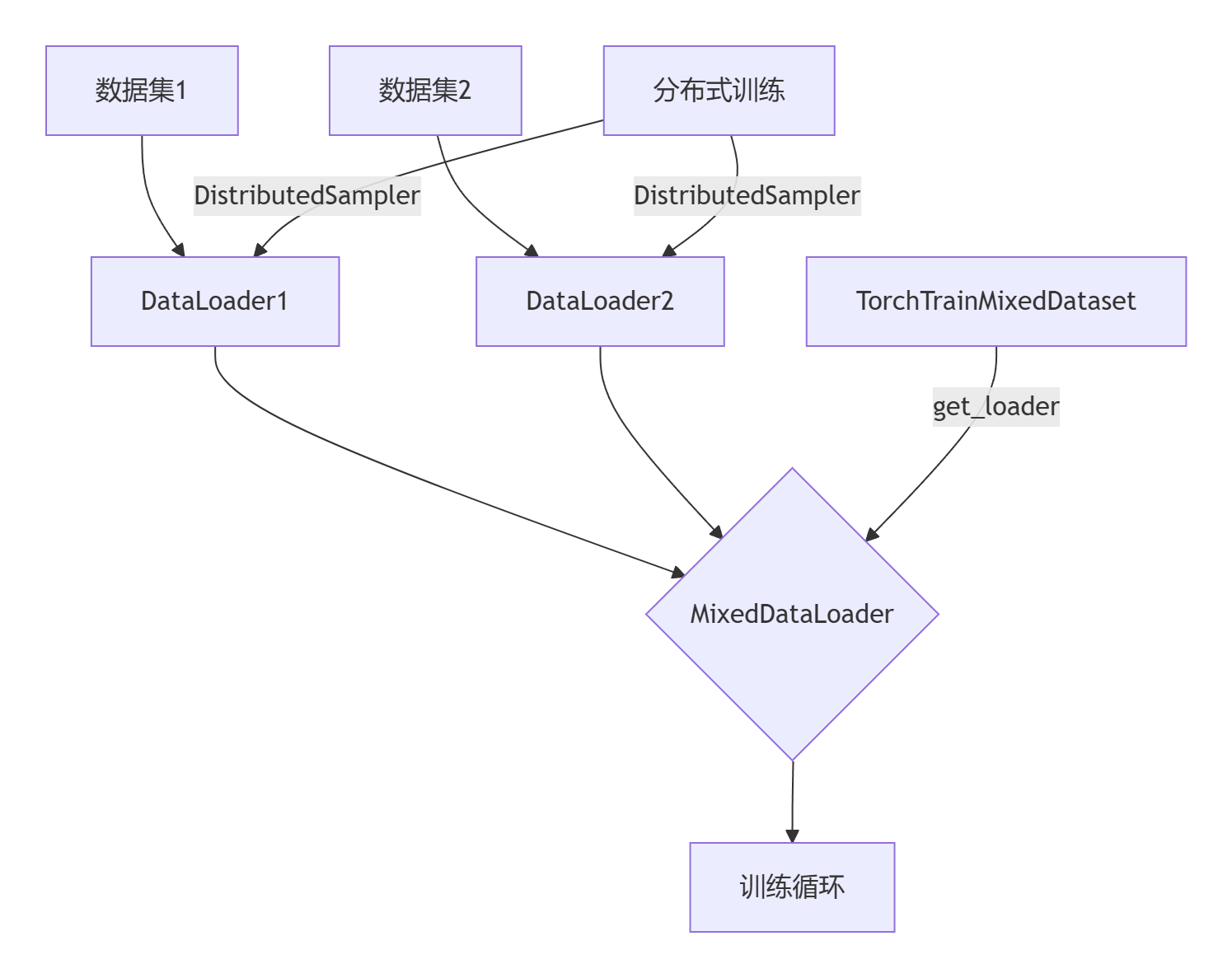
展示了在训练过程中,数据是如何流动的
1)trainer的初始化
trainer = instantiate(cfg.trainer, _recursive_=False)
-
传入的参数:
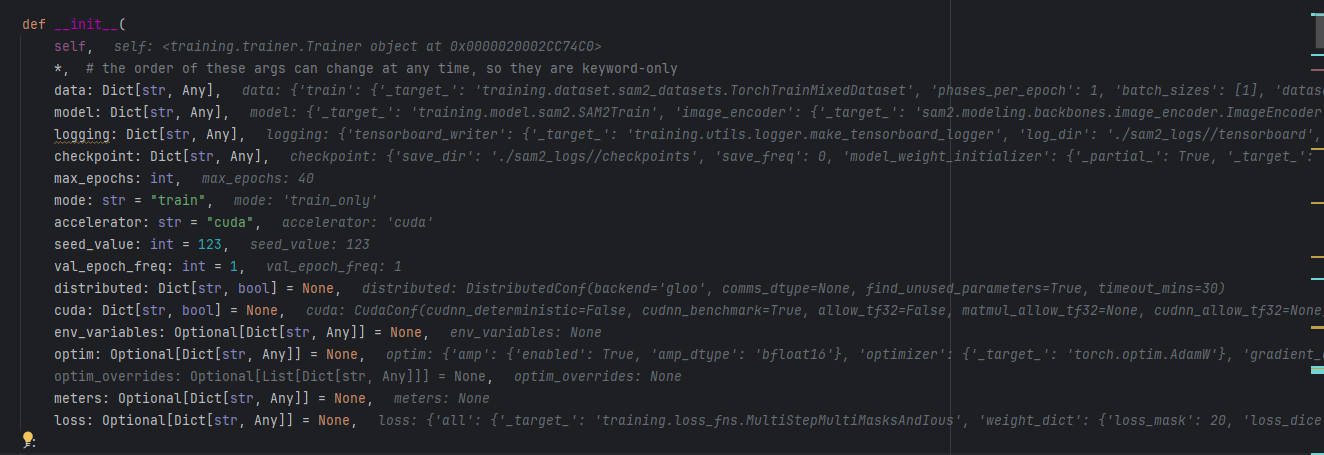
- data:training.dataset.sam2_datasets.TorchTrainMixedDataset

- model: training.model.sam2.SAM2Train
- checkpoint:…
- mode: train_only
- optim: torch.optim.AdamW
- loss: training.loss_fns.MultiStepMultiMasksAndIous
- data:training.dataset.sam2_datasets.TorchTrainMixedDataset
-
配置信息赋值给实例变量
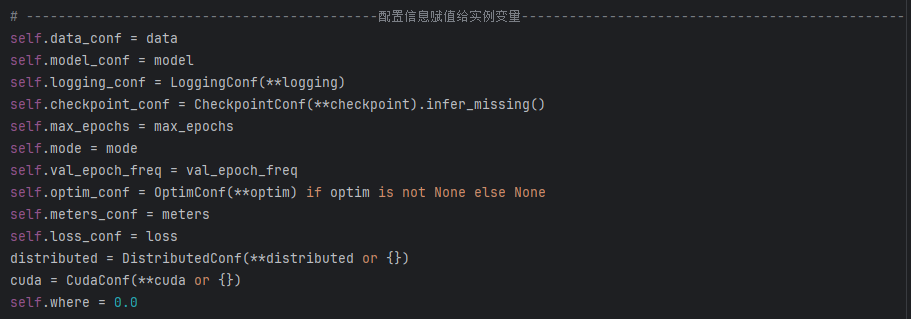
-
初始化其他配置信息…
-
self._setup_dataloaders() 设置数据加载器
- 根据mode的格式实例化train_dataset,如下图所示(
接7.1-1)的初始化模块):
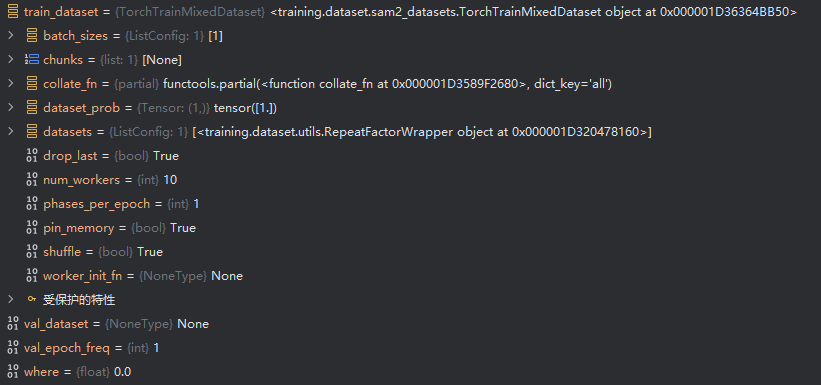
- 根据mode的格式实例化train_dataset,如下图所示(
2)trainer.run
dataloader = self.train_dataset.get_loader(epoch=int(self.epoch))-----接7.1-2)的get_loader方法
7. sam2_dataset.py
7.1 MixedDataLoader 类
1)初始化
- 传入参数
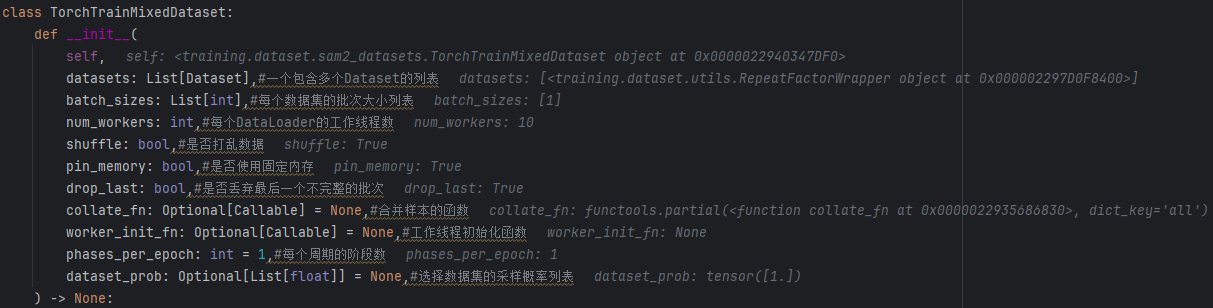
这里的传入参数就是前面trainer初始化中,data的配置信息。 - 初始化信息
- 属性赋值
- 设置数据集的周期(??没看懂这样的意义)
- sam允许训练时使用多个数据集
- 计算每个数据集的采样概率,概率为子数据集量/全部数据集量,若只有一个数据集,那么采样概率为1
2)get_loader
def get_loader(self, epoch) -> Iterable:# 初始化数据加载器列表dataloaders = []# 遍历数据集和批次大小for d_idx, (dataset, batch_size) in enumerate(zip(self.datasets, self.batch_sizes)):# 处理每个数据集# 如果每个周期的阶段数 self.phases_per_epoch 大于 1,则处理数据集的分块和设置周期。if self.phases_per_epoch > 1:# Major epoch that looops over entire dataset# len(main_epoch) == phases_per_epoch * len(epoch)# 计算主周期和局部阶段main_epoch = epoch // self.phases_per_epoch# Phase with in the main epochlocal_phase = epoch % self.phases_per_epoch# Start of new data-epoch or job is resumed after preemtion.if local_phase == 0 or self.chunks[d_idx] is None:# set seed for dataset epoch# If using RepeatFactorWrapper, this step currectly re-samples indices before chunking.self._set_dataset_epoch(dataset, main_epoch)# Separate random generator for subset samplingg = torch.Generator()g.manual_seed(main_epoch)self.chunks[d_idx] = torch.chunk(torch.randperm(len(dataset), generator=g),self.phases_per_epoch,)dataset = Subset(dataset, self.chunks[d_idx][local_phase])# 如果是新的数据周期或工作在中断后恢复,则设置数据集的周期,并为数据集创建随机分块。else:self._set_dataset_epoch(dataset, epoch)# 创建DistributedSampler采样器,用于在分布式环境中对数据集进行采样sampler = DistributedSampler(dataset, shuffle=self.shuffle)sampler.set_epoch(epoch)# 创建 BatchSampler 对象,用于从采样器中按批次大小采样数据。batch_sampler = BatchSampler(sampler, batch_size, drop_last=self.drop_last)# 创建数据加载器dataloaders.append(DataLoader(dataset,num_workers=self.num_workers,pin_memory=self.pin_memory,batch_sampler=batch_sampler,collate_fn=self.collate_fn,worker_init_fn=self.worker_init_fn,))# 返回混合数据加载器return MixedDataLoader(dataloaders, self.dataset_prob)