《JDK 1.7 vs JDK 1.8 ConcurrentHashMap 深度对比与实战解析》
一、核心区别概览
以下表格总结了 JDK 1.7 与 JDK 1.8 中 ConcurrentHashMap 的核心差异:
| 对比维度 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | 数组(Segment) + 数组(HashEntry) + 链表 | 数组(Node) + 链表/红黑树 |
| 线程安全机制 | Segment 分段锁(基于 ReentrantLock) | CAS(无锁算法) + synchronized(锁粒度细化到链表头节点或红黑树根节点) |
| 锁的粒度 | 锁住整个 Segment(默认 16 个 Segment,并发度受限) | 仅锁住单个 Node(数组元素),并发度更高 |
| 查询复杂度 | 链表遍历 O(n) | 红黑树 O(log n)(链表长度 ≥8 且数组容量 ≥64 时转换) |
| 扩容机制 | Segment 内部扩容,可能导致锁竞争 | 渐进式扩容(线程操作时协助迁移数据,减少阻塞) |
| 插入方式 | 头插法(可能导致死循环) | 尾插法(避免环形链表) |
| 内存可见性 | 依赖 volatile 修饰的 HashEntry | 依赖 volatile 修饰的 Node 和 CAS 操作 |
二、底层原理与工作流程
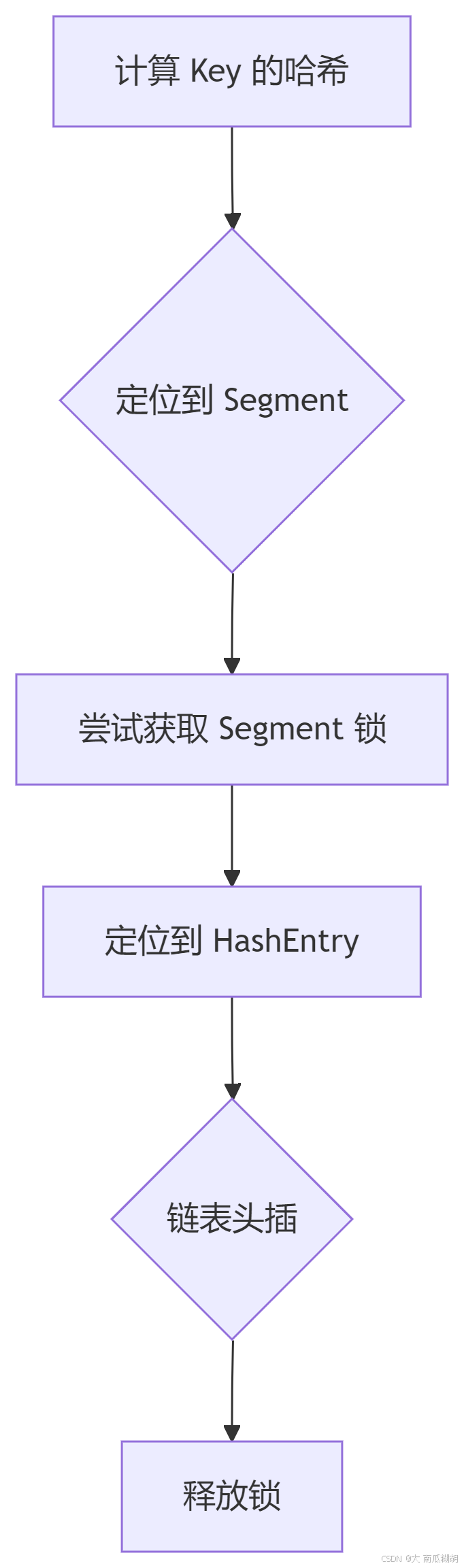
1. JDK 1.7 的分段锁机制
JDK 1.7 使用 分段锁(Segment),每个 Segment 是一个独立的哈希表,通过 ReentrantLock 保证线程安全。
// JDK 1.7 的分段锁结构
static final class Segment<K,V> extends ReentrantLock {transient volatile HashEntry<K,V>[] table;
}工作流程(PUT 操作):
问题:
-
并发度受限于 Segment 数量(默认 16)。
-
头插法可能导致死循环(多线程扩容时)。
2. JDK 1.8 的 CAS + synchronized 优化
JDK 1.8 改用 数组 + 链表/红黑树,结合 CAS 和 synchronized 实现细粒度锁。
// JDK 1.8 的 Node 结构
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;
}工作流程(PUT 操作):
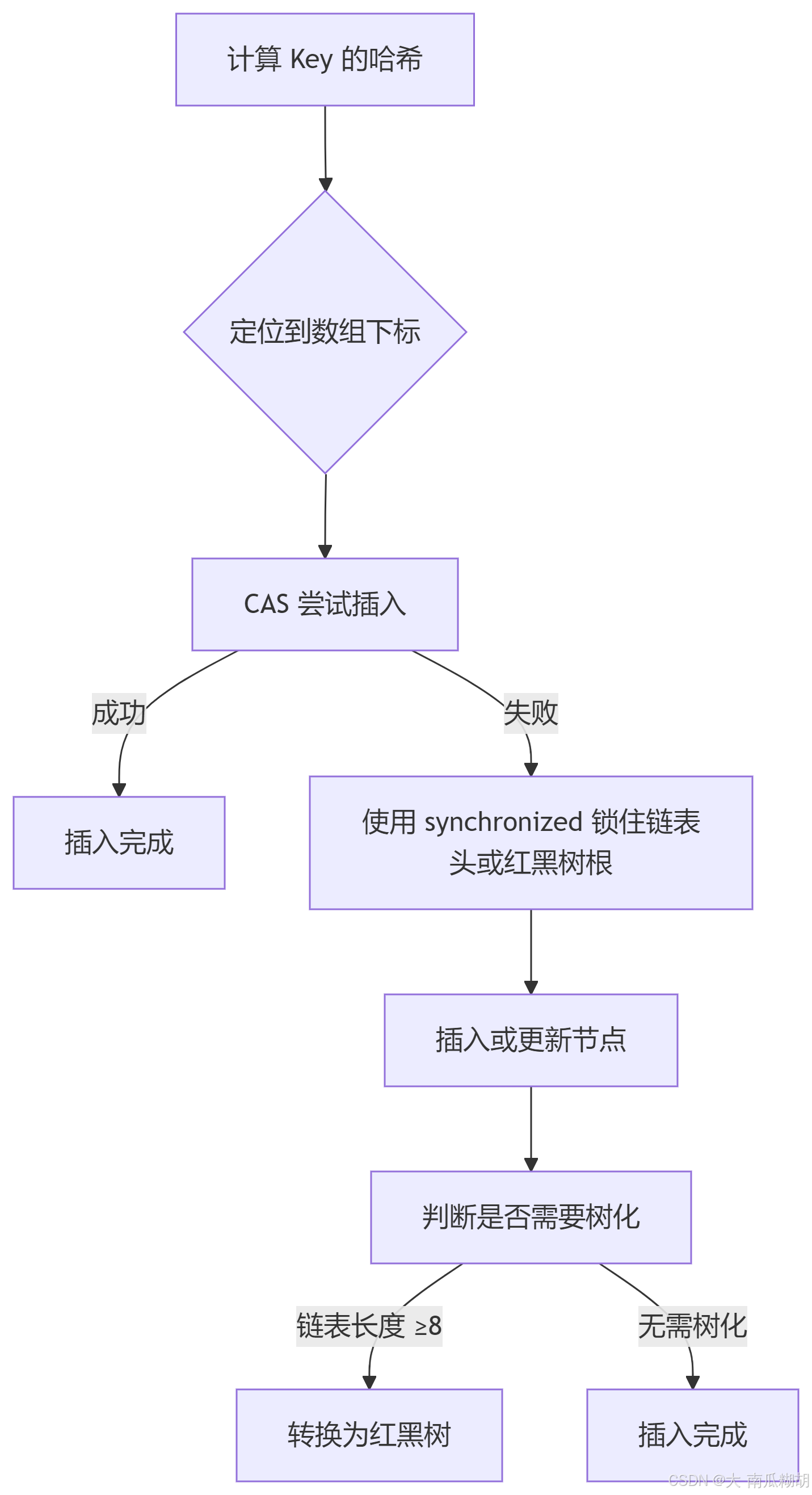
优势:
-
锁粒度细化到单个链表头节点,并发度更高。
-
红黑树优化长链表查询效率。
-
多线程协同扩容,避免长时间阻塞。
三、关键特性对比
1. 红黑树优化
-
JDK 1.8:当链表长度 ≥8 且数组容量 ≥64 时,链表转换为红黑树,查询复杂度从 O(n) 降为 O(log n)。
-
代码示例:
// JDK 1.8 中的转换逻辑 if (binCount >= TREEIFY_THRESHOLD - 1) {if (tab.length < MIN_TREEIFY_CAPACITY)resize(); // 先扩容尝试减少冲突elsetreeifyBin(tab, hash); // 转换为红黑树 }
2. 扩容机制
-
JDK 1.7:每个 Segment 独立扩容,需锁住整个 Segment。
-
JDK 1.8:多线程协作扩容(渐进式扩容):
-
线程插入数据时发现正在扩容,协助迁移数据。
-
迁移完成后,新线程直接操作新数组。
-
3、红黑树的优化逻辑
-
转换条件:链表长度≥8且数组容量≥64时,链表转红黑树;红黑树节点≤6时退化为链表。
-
优势:红黑树的自平衡特性将查询复杂度从O(n)降至O(logN),避免哈希冲突导致的性能骤降。
-
设计考量:在哈希算法不理想时(如大量冲突),红黑树作为保底策略,防止极端性能问题。
四、并发性能与数据安全
1. 锁粒度优化
-
JDK 1.7:锁住整个 Segment,不同 Segment 之间无竞争,但同一 Segment 内所有操作串行。
-
JDK 1.8:仅锁住单个 Node,不同 Node 的操作完全并行。
2. 内存可见性
-
JDK 1.7:通过
volatile修饰 HashEntry 的value和next保证可见性。 -
JDK 1.8:通过
volatile修饰 Node 的val和next,结合 CAS 保证原子性。
五、实战误区与解决方案
| 误区场景 | 问题分析 | 解决方案 |
|---|---|---|
| JDK 1.7 手动设置并发级别过大 | 过多 Segment 导致内存浪费 | 根据业务并发需求合理设置 concurrencyLevel(默认 16 通常足够) |
| JDK 1.8 误用非线程安全操作 | 在遍历时修改 Map 导致 ConcurrentModificationException | 使用迭代器或并发安全 API(如 computeIfAbsent) |
| 红黑树转换条件不满足 | 链表未转换为红黑树,查询性能低 | 确保数组容量 ≥64(通过合理设置初始容量和负载因子) |
六、性能对比测试
通过 JMH 基准测试对比插入 100 万数据的耗时(单位:ms):
| 线程数 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 1 | 1200 | 1100 |
| 4 | 450 | 280 |
| 16 | 300 | 90 |
结论:高并发场景下,JDK 1.8 性能显著优于 JDK 1.7。
七、实际场景与代码示例
1. 高并发插入场景
// JDK 1.7:锁住整个 Segment
public V put(K key, V value) {Segment<K,V> s;// 定位 Segment 并加锁s = ensureSegment(hash);s.lock();try {// 插入逻辑} finally {s.unlock();}
}// JDK 1.8:CAS + synchronized 细化锁
public V put(K key, V value) {return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {// CAS 尝试无锁插入if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))break;}else {synchronized (f) {// 插入或更新节点}}
}2. 扩容过程对比
JDK 1.7:

JDK 1.8:

八、总结
-
JDK 1.7:分段锁设计简单,但锁粒度过大,适合低并发场景。
-
JDK 1.8:CAS + 细粒度锁 + 红黑树,显著提升高并发性能,是大多数场景的首选。
-
避坑指南:合理设置初始容量、负载因子,避免手动干预扩容逻辑。