『深夜_MySQL』详解数据库 探索数据库是如何存储的
1. 数据库基础
1.1 什么是数据库
存储数据用文件就可以了,那为什么还要弄个数据库?
一般的文件缺失提供了数据的存储功能,但是文件并没有提供非常好的数据管理能力(用户角度,内容方面)
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
数据库存储介质:
- 磁盘
- 内存
为例解决上述问题,专家们设计出更加利于管理数据的东西——数据库,它能更有效的管理数据。数据库的水平是衡量一个程序员水平的重要指标。
1.2 主流数据库
- SQL Sever: 微软的产品,.Net程序员的最爱,中大型项目。
- Oracle: 甲骨文产品,适合大型项目,复杂的业务逻辑,并发一般来说不如MySQL。
- MySQL:世界上最受欢迎的数据库,属于甲骨文,并发性好,不适合做复杂的业务。主要用在电商,SNS,论坛。对简单的SQL处理效果好。
- PostgreSQL :加州大学伯克利分校计算机系开发的关系型数据库,不管是私用,商用,还是学术研究使用,可以免费使用,修改和分发。
- SQLite: 是一款轻型的数据库,是遵守ACID的关系型数据库管理系统,它包含在一个相对小的C库中。它的设计目标是嵌入式的,而且目前已经在很多嵌入式产品中使用了它,它占用资源非常的低,在嵌入式设备中,可能只需要几百K的内存就够了。
- H2: 是一个用Java开发的嵌入式数据库,它本身只是一个类库,可以直接嵌入到应用项目中。
数据库大体可以分为关系型数据库和非关系型数据库。
- 关系型数据库: 是指采用了关系模型来组织数据的数据库。简单来说,关系模型指的就是二维表格模型,也就是由二维表格及其之前的联系所组成的一个数据组织。
关系型数据库基于标准的SQL实现,但内部的一些实现有所区别,常用的关系型数据库有:Oracle、MySQL、SQL Server、MariaDB。
- 非关系型数据库:不规定基于SQL实现,现在更多是指NoSQL(Not Only SQL)数据库,例如
- 基于键值对(Key-Value):如memcached、redis
- 基于文档型:如mongodb
- 基于列族:如hbase
- 基于图型:如neo4j
关系型数据库与非关系数据库的区别如下所示:
| 关系型数据库 | 非关系型数据库 | |
|---|---|---|
| 使用SQL | 是 | 不强制要求,一般不基于SQL实现 |
| 事务支持 | 支持 | 不支持 |
| 复杂操作 | 支持 | 不支持 |
| 海量读写操作 | 效率低 | 效率高 |
| 基于结构 | 基于表和列,结构固定 | 灵活性比较高 |
| 使用场景 | 业务方面的OLTP系统 | 用于数据的缓存、或基于统计分析的OLAP系统 |
注: OLTP(On-Line Transaction Procesing)是指联机事务处理,OLAP(On-Line Analytical Processing)是指联机分析处理。
注: 我们的测试版本是Mysql 8.0.41 arm64版本,下面结果可能会和旧版本结果有所不同,属于正常现象
1.3 基本使用
1.3.1 连接服务器
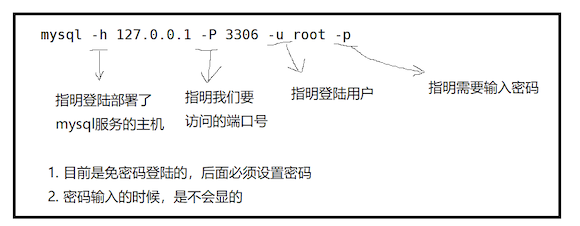
输入:
mysql -h 127.0.0.1 -P 3306 -u root -p
注意: 如果没有写-h 127.0.0.1 则默认是连接本地
如果没有写-P 3306 则默认是连接3306端口号
1.3.2 认识数据库
我们输入
ps ajx | grep mysql

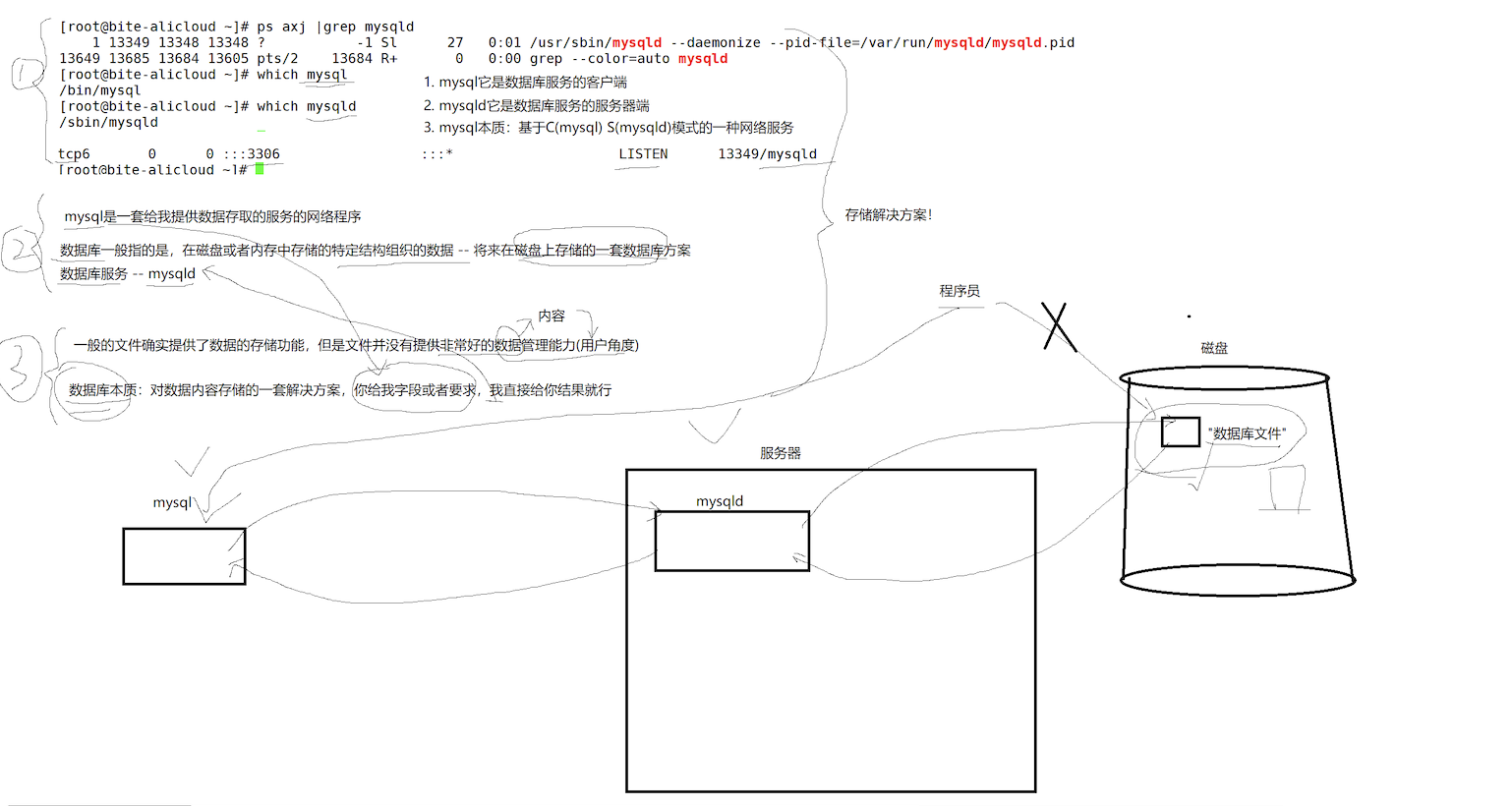
可以看到我们的后台同时启动了 mysqld 以及mysql, 那么他们有什么区别呢?
- mysql它是数据库服务的客户端
- mysqld它是数据库服务的服务器端
- mysql本质:基于C(mysql)S(mysqld)模式的一种网络服务。
mysql 就是一套给我提供数据存取服务的网络程序。
数据库一般指的是,在磁盘或者内存中存储的特定结构组织的数据 -- 将来在磁盘上存储的一套数据库方案。
数据库服务提供者--mysqld
数据库本质:对数据内容存储的一套解决方案,你给我字段或者要求,我直接给你结果就行
由此,我们访问存取数据的操作,不再是对于磁盘进行操作了,而是对mysql客户端进行操作,mysql客户端在将我们的操作提交给服务器,服务器在根据我们的操作,进行存取访问磁盘数据,将结果返回给客户端。
1.3.3 见一见数据库
我们左边启动mysql客户端,右边进入mysql/data文件夹中
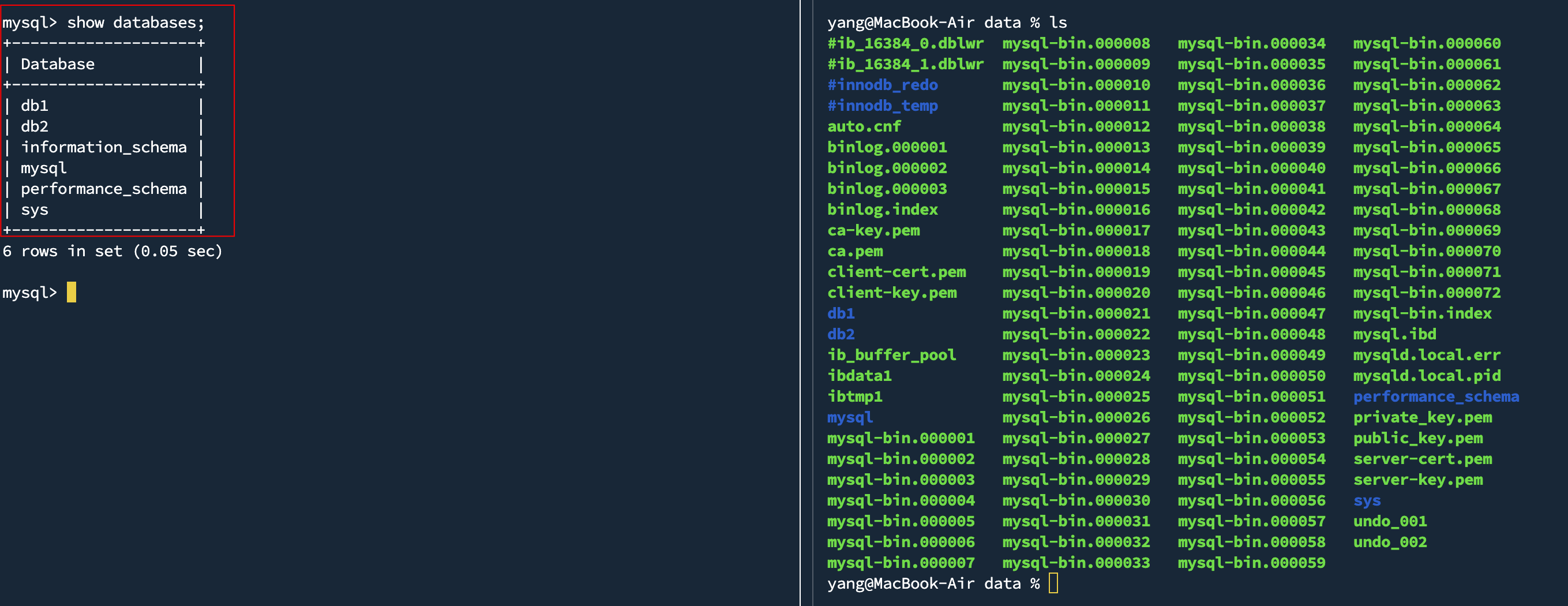
我们查看所有数据库,与右边对比查看,发现数据库对应着就是Linux下的一个目录
我们打开一个数据库,在里面建一个表
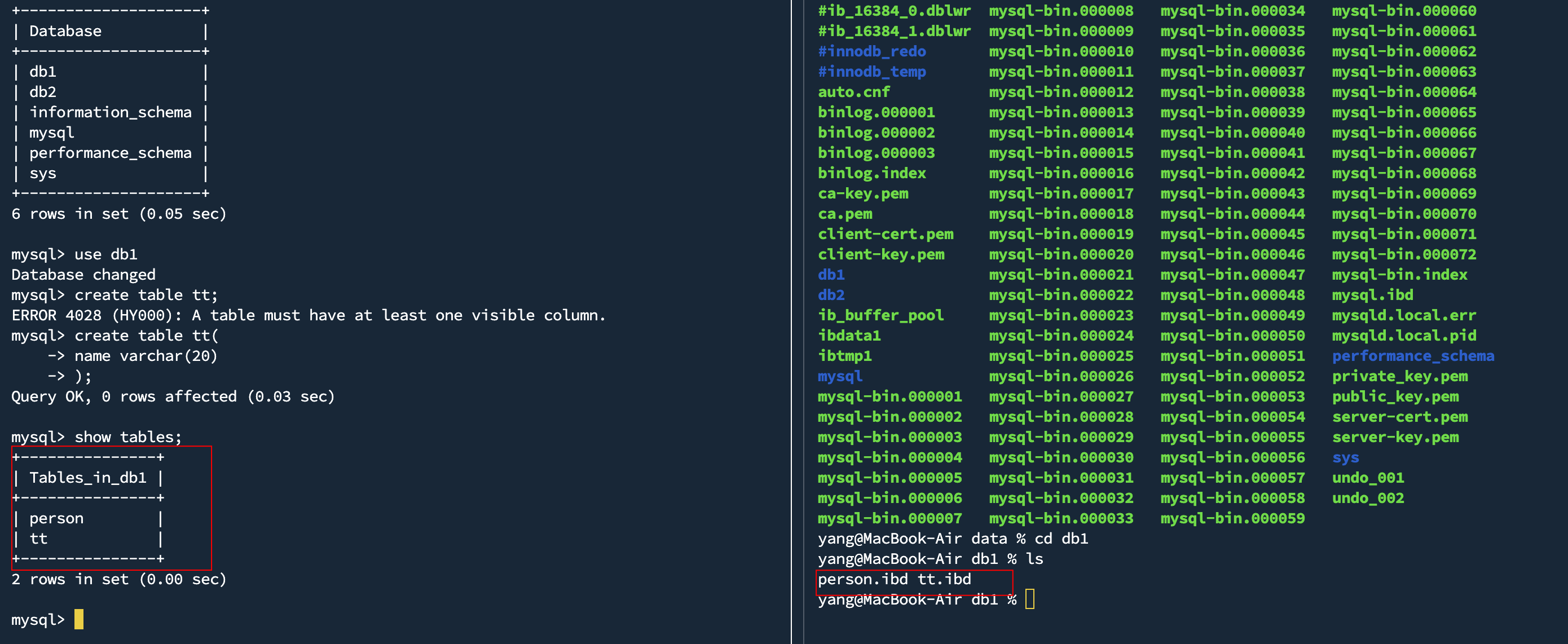
我们发现在数据库中的表,对应就是Linux下的一个文件
由此我们得出结论
- 建立数据库,本质就是Linux下的一个目录
- 在数据库内建立表,本质就是在Linux下创建对应的文件
- 数据库本质其实也是文件! 只不过这些文件并不由程序员直接操作,而是由数据库服务帮我们进行操作
那么,我们还有一个疑惑,我们并没有创建文件,创建目录啊,这个工作是谁做的?
mysqld服务帮我们做的

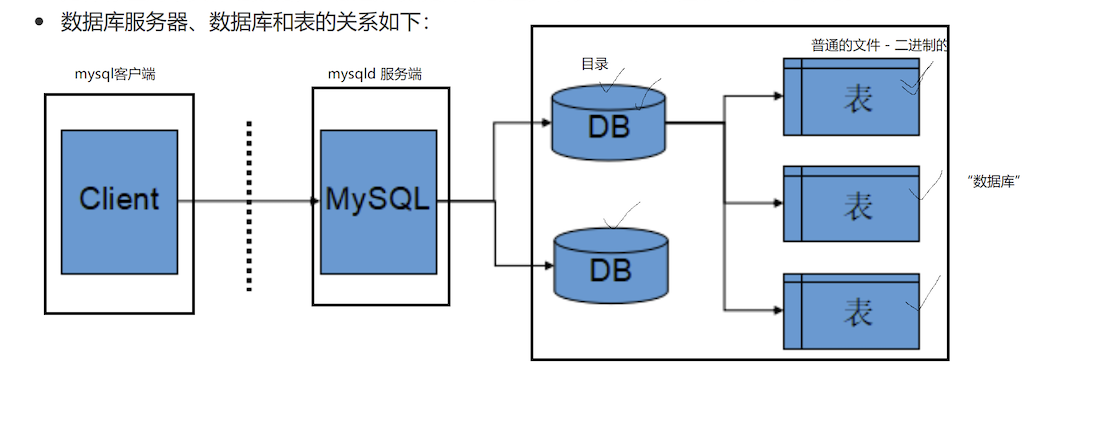
1.3.4 服务器、数据库、表关系
所谓安装数据库服务器,只是在机器上安装了一个数据库管理系统程序,这个管理程序可以管理多个数据库,一般开发人员会针对每一个应用创建一个数据库。
为保存应用中实体的数据,一般会在数据库中创建多个表,以保存程序中实体的数据。
1.3.5 使用案例
- 创建数据库
create database helloworld;
- 使用数据库
use helloworld;
- 创建数据库表
create table personInfo(
id varchar(4),
name varchar(32),
gender varchar(2)
);
完成表创建后,我们发现在helloworld目录下,多出来一个与表personInfo同名的文件

注意:在Linux下,5.7 版本中 会产生两个同名文件 .frm和.ibd

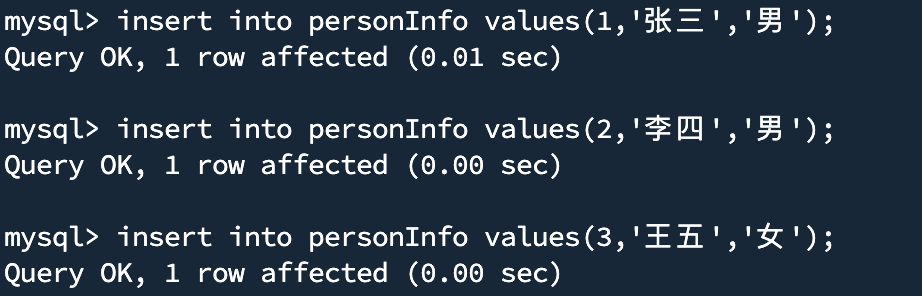
- 在表中插入数据
insert into personInfo values(1,'张三','男');
insert into personInfo values(2,'李四','男');
insert into personInfo values(3,'王五','女');
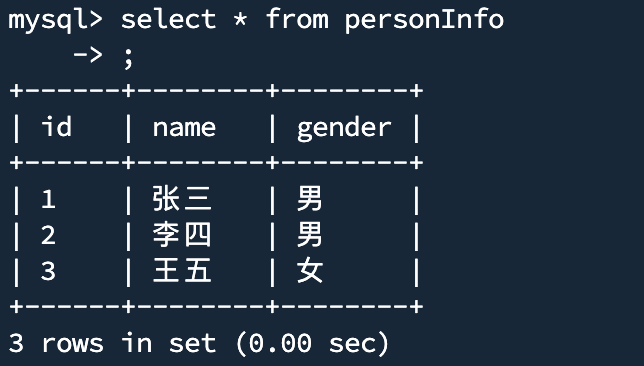
- 查询表中的数据
select * from personInfo
1.3.6 数据逻辑存储
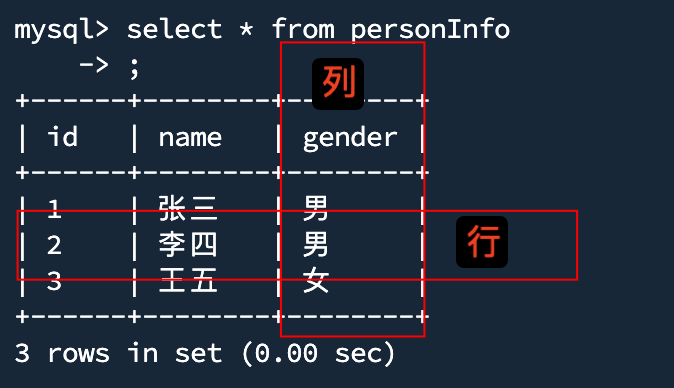
在mysql中数据的存储是按照二维表格的逻辑进行存储的。
1.4 MySQL 架构
MySQL是一种可移植的数据库,几乎能在当前所有的操作系统上运行,如Unit/Linux、Windows、Mac和Solaris。各种操作系统在底层实现方面各有不同,但是MySQL基本上能保证在各个平台上的物理体系结构的一致性。
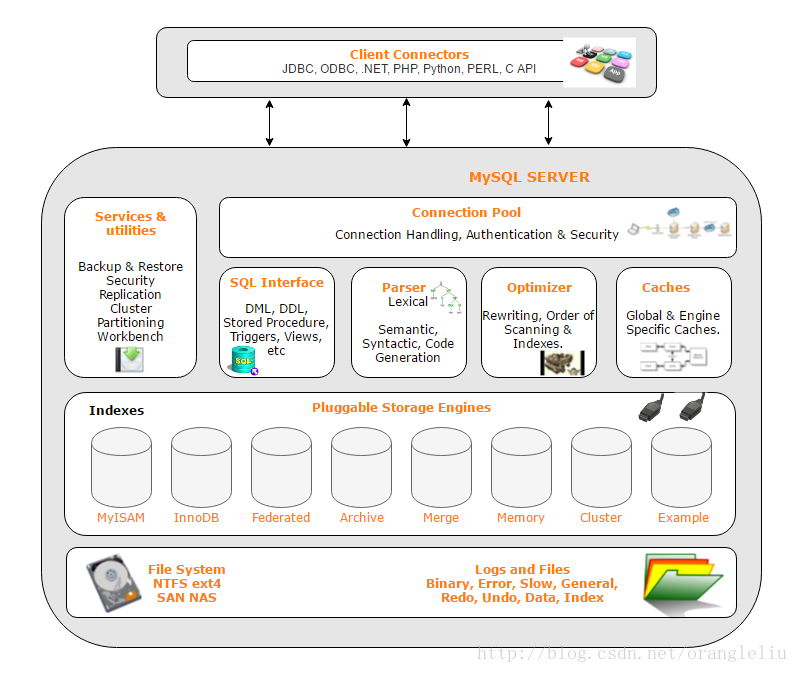
由于MySQL Server 会接收大量的查询、增加、删除、修改操作,需要使用Connection Pool 管理各个数据库请求。而再往下的SQL Interface、Parser、Optimizer、Cashes完成对SQL执行语句的解析操作,再将解析后的指令操作交由下层的各个数据库引擎执行(数据库引擎是可选的,用户选择哪个存储引擎,就由该存储引擎执行对应的操作,该操作表明存储引擎是支持热插拔的),存储引擎类似于操作系统中的驱动程序,可对磁盘等存储设备做出操作。
1.5 SQL分类
下面对各个SQL操作语句做出列分类,关于各个操作语句如何使用,将于后续文章介绍。
- DDL(data definition language) 数据定义语言,用来维护存储数据的结构 代表指令:create,drop,alter
- DML(data manipulation language) 数据操纵语言,用来对数据进行操作,代表指令:insert、delete、updata
- DML中又单独分列一个DQL,数据查询语言,代表指令:select
- DCL(Data Control Language) 数据控制语言,主要负责全新啊管理和事物。代表指令:grant、revoke、commit
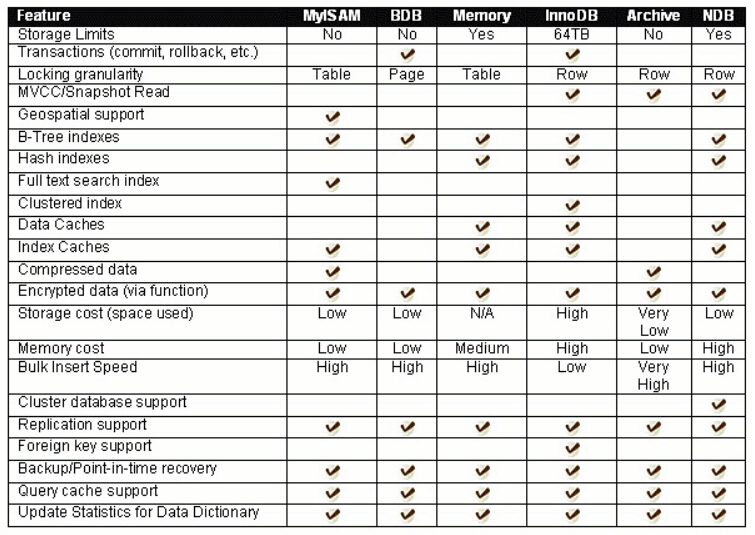
1.6 存储引擎
1.6.1 存储引擎
存储引擎是:数据库管理系统如何存储数据,如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL的核心就是插件式存储引擎,支持多种存储引擎。
1.6.2 查看存储引擎
show engines;

下表列出各存储引擎的特性,本个专栏中只介绍InnoDB和MyISAM,因为Mysql中大部分场景都只使用这两个就可以解决问题,余下存储引擎不做介绍。关于InnoDB和MyISAM的特点,将于后序文章中详细介绍。