使用通义千问大模型做结构化输出报错的分析
在LangChain官方网站学习调用大语言模型 从文本提取信息 。代码如下
import getpass
import os from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model if not os.environ.get("OPENAI_API_KEY"): os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter OpenAI API key: ") llm = init_chat_model("gpt-4o-mini", model_provider="openai") tagging_prompt = ChatPromptTemplate.from_template( """ Extract the desired information from the following passage.Only extract the properties mentioned in the 'Classification' function.Passage:{input}"""
) class Classification(BaseModel): sentiment: str = Field(description="The sentiment of the text") aggressiveness: int = Field(description="How aggressive the text is on a scale from 1 to 10") language: str = Field(description="The language the text is written in") structured_llm = llm.with_structured_output(Classification) inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
prompt = tagging_prompt.invoke({"input": inp})
response = structured_llm.invoke(prompt)
print(response)
这段代码使用gpt-4o-mini这个模型来分析一段西班牙文字,想提取出文字中的情绪、进攻性和文字的语言。
尝试把大模型从gpt换成通义千问,于是修改构造chat model的代码。从
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
改为
llm = init_chat_model( model_provider="openai", model="qwen-plus-2025-04-28", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", api_key=os.environ["QWEN_API_KEY"]
)
执行代码,发现报错
openai.BadRequestError: Error code: 400 - {'error': {'code': 'invalid_parameter_error', 'param': None, 'message': "<400> InternalError.Algo.InvalidParameter: 'messages' must contain the word 'json' in some form, to use 'response_format' of type 'json_object'.", 'type': 'invalid_request_error'}, 'id': 'chatcmpl-515a50a0-25a6-9cc2-aa7d-03884b01e6ee', 'request_id': '515a50a0-25a6-9cc2-aa7d-03884b01e6ee'}从错误代码400推测是通义千问大模型服务返回的错误,于是查询 通义千问结构化输出的文档 ,在 使用方法 里列出了两个条件
- 设置参数
您需要设置请求参数response_format为{“type”: “json_object”}。 - 提示词指引
您需要在提示词中指引模型输出 JSON 字符串,否则会报错:‘messages’ must contain the word ‘json’ in some form, to use ‘response_format’ of type ‘json_object’.
按照要求添加了请求参数,修改了提示词,运行发现了新的错误(证明通义千问给出的解决方案是有效的)。
pydantic_core._pydantic_core.ValidationError: 1 validation error for Classification
aggressivenessField required [type=missing, input_value={'language': 'Spanish', 'sentiment': 'positive'}, input_type=dict]
从错误提示看,大模型服务端返回的信息中只有我们需要的 sentiment 和 language ,但没有包含我们需要的 aggressiveness 。于是注释了代码中aggressive那一行。
随后多次运行了程序,每次运行的结果可能会有差异,总共发现了下面三种结果。
sentiment='positivo' language='español'
这个结果确实返回了我们需要的信息,但信息(positivo 和 español)是西班牙语。
pydantic_core._pydantic_core.ValidationError: 1 validation error for Classification
sentimentField required [type=missing, input_value={'emotion': 'positive', 'language': 'Spanish'}, input_type=dict]这个错误结果中没有我们需要的 sentiment ,但多了一个我们不需要的 emotion 。
sentiment='positive' language='Spanish'
这个结果也返回了我们需要的信息,而且信息通过英语返回的。
通义千问API返回的信息这么不稳定吗?直接找通义千问的文本对话试试看吧。结果如下
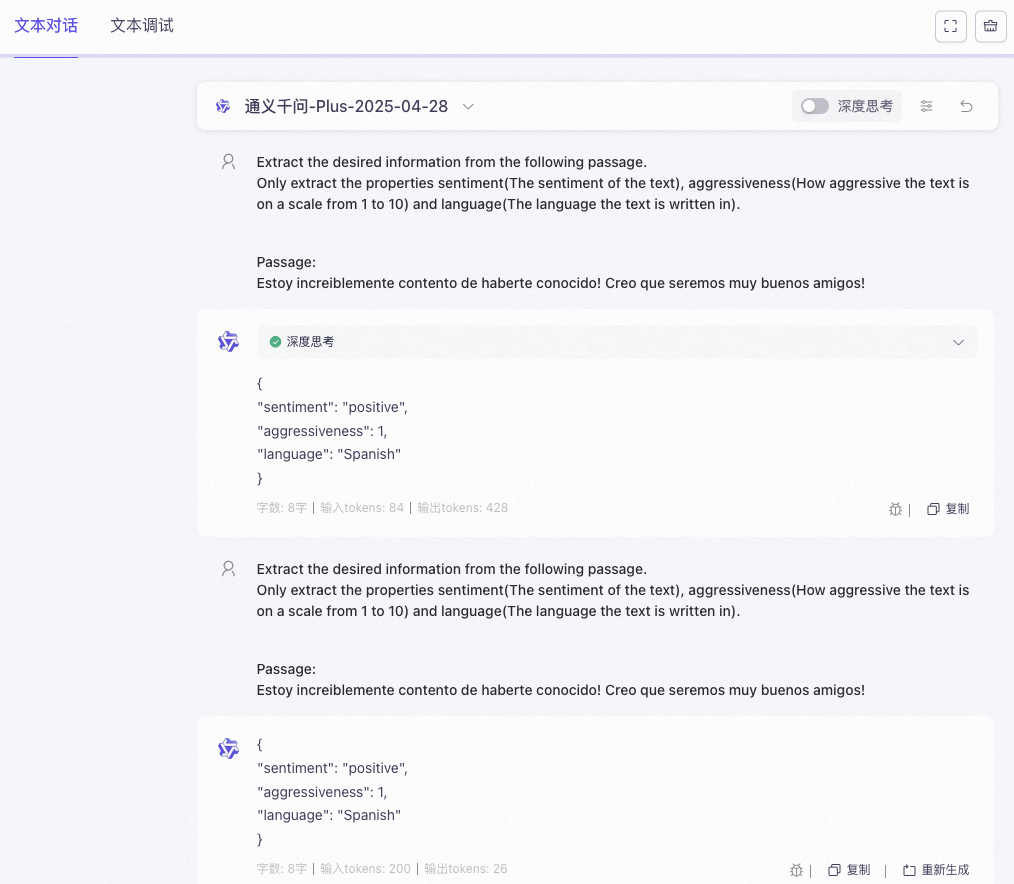
因为这里是和大模型直接聊天,所以我对提示词做了一些修改。看得出通义是能够提取 aggressiveness的,结果也是挺稳定的。那为什么使用代码和文本聊天得到的结果有这么大的差别呢?在文本聊天中,我们在提示词里明确写出了需要从文本中提取的属性。反观我们通过代码向通义发出的API request body是这样的
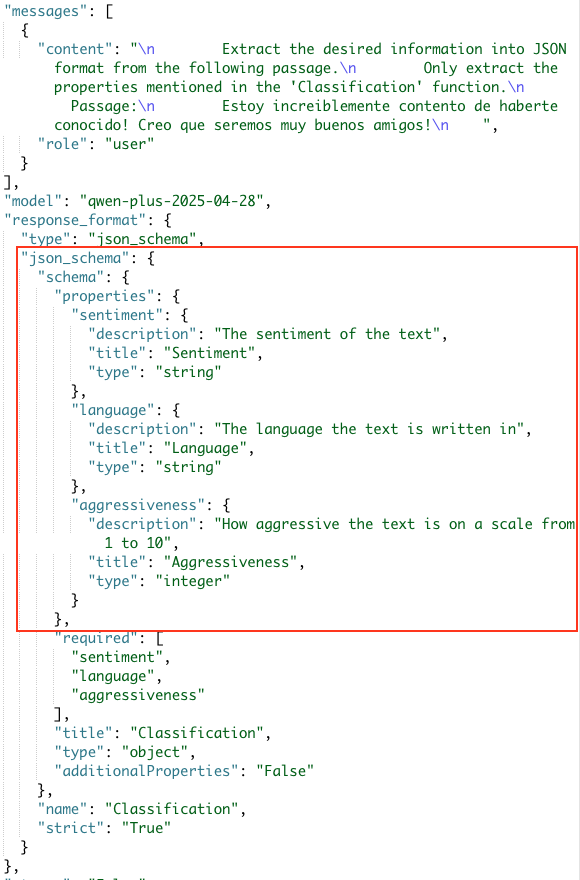
要提取的文本属性并不在提示词里,而是放在了json_schema参数里。而 通义千问结构化输出的文档 明确说明了它不支持json_schema

这意味着在使用通义千问大模型时,代码在Classification类里指定要提取的文本属性统统不生效。至此,疑惑都解开了。由此可见,虽然Langchain的存在统一了我们和大模型交互的代码实现,但各家大模型服务还是存在一定的差异的,前路漫漫啊~~