归并排序排序总结
1. 归并排序
1.1 基本思想
归并排序(Merge Sort)是采用分治法(Divide and Conquer)的一个非常典型的应用。它的基本思想是将一个数组分成两个子数组,分别对这两个子数组进行排序,然后将排好序的子数组合并成一个最终的有序数组。具体来说,归并排序主要分为两个步骤:
- 分解(Divide):将当前数组从中间分成两个子数组,递归地对这两个子数组进行分解,直到每个子数组只包含一个元素(因为单个元素的数组是有序的)。
- 合并(Merge):将两个有序的子数组合并成一个更大的有序数组。不断重复这个合并过程,直到所有子数组合并成一个完整的有序数组。
1.2 算法步骤
- 分解阶段:
- 找到数组的中间位置
mid,将数组分为左右两部分,即left = arr[0...mid]和right = arr[mid + 1...n-1],其中n是数组的长度。 - 递归地对
left和right子数组进行分解,直到子数组的长度为 1。
- 找到数组的中间位置
- 合并阶段:
- 创建一个临时数组
temp用于存储合并后的结果。 - 比较
left和right子数组的元素,将较小的元素依次放入temp数组中。 - 重复步骤 2,直到
left或right子数组中的元素全部放入temp数组。 - 将剩余的元素(如果有)直接放入
temp数组的末尾。 - 将
temp数组中的元素复制回原数组。
- 创建一个临时数组
1.3 代码实现
#include <iostream>
#include <vector>// 合并两个有序数组
void merge(std::vector<int>& arr, int left, int mid, int right) {int n1 = mid - left + 1;int n2 = right - mid;// 创建临时数组std::vector<int> L(n1), R(n2);// 复制数据到临时数组 L[] 和 R[]for (int i = 0; i < n1; i++)L[i] = arr[left + i];for (int j = 0; j < n2; j++)R[j] = arr[mid + 1 + j];// 归并临时数组到 arr[left..right]int i = 0; // 初始化第一个子数组的索引int j = 0; // 初始化第二个子数组的索引int k = left; // 初始归并子数组的索引while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 复制 L[] 的剩余元素while (i < n1) {arr[k] = L[i];i++;k++;}// 复制 R[] 的剩余元素while (j < n2) {arr[k] = R[j];j++;k++;}
}// 归并排序函数
void mergeSort(std::vector<int>& arr, int left, int right) {if (left < right) {// 找到中间点int mid = left + (right - left) / 2;// 递归排序左半部分mergeSort(arr, left, mid);// 递归排序右半部分mergeSort(arr, mid + 1, right);// 合并已排序的两部分merge(arr, left, mid, right);}
}// 打印数组
void printArray(const std::vector<int>& arr) {for (int num : arr)std::cout << num << " ";std::cout << std::endl;
}int main() {std::vector<int> arr = {38, 27, 43, 3, 9, 82, 10};std::cout << "Original array: ";printArray(arr);int n = arr.size();mergeSort(arr, 0, n - 1);std::cout << "Sorted array: ";printArray(arr);return 0;
}
1.4 复杂度分析
- 时间复杂度:归并排序的时间复杂度始终为 O ( n l o g n ) O(n log n) O(nlogn),无论输入数组的初始状态如何。这是因为每次分解数组的时间复杂度为 O ( l o g n ) O(log n) O(logn),而每次合并数组的时间复杂度为 O ( n ) O(n) O(n),所以总的时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn)。
- 空间复杂度:归并排序的空间复杂度为 O ( n ) O(n) O(n),主要用于临时数组
temp的存储。
1.5 优缺点
- 优点:
- 时间复杂度稳定,为 O ( n l o g n ) O(n log n) O(nlogn),适用于大规模数据的排序。
- 是一种稳定的排序算法,即相等元素的相对顺序在排序后不会改变。
- 缺点:
- 需要额外的 O ( n ) O(n) O(n) 空间来存储临时数组,空间开销较大。
1.6 示意图
假设我们有一个数组 [38, 27, 43, 3, 9, 82, 10],下面是归并排序的详细示意图:
分解阶段
原始数组: [38, 27, 43, 3, 9, 82, 10]/ \[38, 27, 43, 3] [9, 82, 10]/ \ / \[38, 27] [43, 3] [9, 82] [10]/ \ / \ / \
[38] [27] [43] [3] [9] [82]
合并阶段
合并 [38] 和 [27] -> [27, 38]
合并 [43] 和 [3] -> [3, 43]
合并 [9] 和 [82] -> [9, 82]合并 [27, 38] 和 [3, 43] -> [3, 27, 38, 43]
合并 [9, 82] 和 [10] -> [9, 10, 82]合并 [3, 27, 38, 43] 和 [9, 10, 82] -> [3, 9, 10, 27, 38, 43, 82]
通过不断地分解和合并,最终得到一个有序的数组。这个过程可以清晰地展示归并排序的分治思想。
2. 非比较排序 *
再此我们了解一下
非比较排序是一类不通过直接比较元素大小来确定元素顺序的排序算法,在某些特定场景下,它们的时间复杂度可以优于基于比较的排序算法(如快速排序、归并排序等,其最优时间复杂度为 O ( n l o g n ) O(n log n) O(nlogn))。下面详细介绍几种常见的非比较排序算法。
2.1 计数排序(Counting Sort)
原理
计数排序的核心思想是统计每个元素出现的次数,借助额外数组记录每个元素在序列中出现的频次,再依据统计结果将元素有序地放回原数组。该算法适用于整数序列,且元素取值范围相对较小的情况。
步骤
- 找出最大值和最小值:遍历数组,找出其中的最大值
max和最小值min。 - 统计元素出现次数:创建一个长度为
max - min + 1的计数数组count,统计每个元素出现的次数。 - 计算累计次数:对计数数组
count进行累加操作,使得count[i]表示小于等于i + min的元素的个数。 - 排序元素:根据累计次数数组,将元素依次放入结果数组中。
代码实现
#include <iostream>
#include <vector>
#include <algorithm>std::vector<int> counting_sort(const std::vector<int>& arr) {if (arr.empty()) {return arr;}// 找出最大值和最小值int min_val = *std::min_element(arr.begin(), arr.end());int max_val = *std::max_element(arr.begin(), arr.end());// 计数数组std::vector<int> count(max_val - min_val + 1, 0);// 统计元素出现次数for (int num : arr) {count[num - min_val]++;}std::vector<int> result;// 根据计数数组重构排序后的数组for (int i = 0; i < count.size(); ++i) {for (int j = 0; j < count[i]; ++j) {result.push_back(i + min_val);}}return result;
}
复杂度分析
- 时间复杂度: O ( n + k ) O(n + k) O(n+k),其中
n是数组的长度,k是数组中元素的取值范围。 - 空间复杂度: O ( k ) O(k) O(k),主要用于计数数组。
2.2 桶排序(Bucket Sort)
原理
桶排序的基本思想是将数组元素分配到多个桶中,每个桶再分别进行排序(可以使用其他排序算法,如插入排序),最后将各个桶中的元素依次合并起来。它适用于数据均匀分布的情况。
步骤
- 确定桶的数量和范围:根据数组的最大值和最小值,确定桶的数量和每个桶的范围。
- 分配元素到桶中:遍历数组,将每个元素放入对应的桶中。
- 对每个桶进行排序:对每个桶中的元素使用其他排序算法进行排序。
- 合并桶中的元素:将各个桶中的元素依次合并起来,得到最终的排序结果。
代码实现
#include <iostream>
#include <vector>
#include <algorithm>std::vector<double> bucket_sort(const std::vector<double>& arr) {if (arr.empty()) {return arr;}// 确定桶的数量int num_buckets = 10;// 初始化桶std::vector<std::vector<double>> buckets(num_buckets);// 找出最大值和最小值double min_val = *std::min_element(arr.begin(), arr.end());double max_val = *std::max_element(arr.begin(), arr.end());// 计算每个桶的范围double bucket_range = (max_val - min_val) / num_buckets;// 分配元素到桶中for (double num : arr) {int index = (bucket_range != 0) ? static_cast<int>((num - min_val) / bucket_range) : 0;if (index >= num_buckets) {index = num_buckets - 1;}buckets[index].push_back(num);}std::vector<double> result;// 对每个桶进行排序并合并for (auto& bucket : buckets) {std::sort(bucket.begin(), bucket.end());result.insert(result.end(), bucket.begin(), bucket.end());}return result;
}
复杂度分析
- 时间复杂度:平均情况下为 O ( n + k ) O(n + k) O(n+k),其中
n是数组的长度,k是桶的数量。最坏情况下为 O ( n 2 ) O(n^2) O(n2)。 - 空间复杂度: O ( n + k ) O(n + k) O(n+k),主要用于存储桶和排序结果。
2.3 基数排序(Radix Sort)
原理
基数排序是一种多关键字排序算法,它通过多次对元素的每一位进行排序,从最低位到最高位,逐步确定元素的顺序。该算法适用于整数排序。
步骤
- 确定最大位数:找出数组中最大的元素,确定其位数。
- 按位排序:从最低位开始,依次对每一位进行计数排序。
代码实现
#include <iostream>
#include <vector>void counting_sort_for_radix(std::vector<int>& arr, int exp) {int n = arr.size();std::vector<int> output(n);std::vector<int> count(10, 0);// 统计每个位上的元素出现次数for (int i = 0; i < n; ++i) {int index = (arr[i] / exp) % 10;count[index]++;}// 计算累计次数for (int i = 1; i < 10; ++i) {count[i] += count[i - 1];}// 排序元素for (int i = n - 1; i >= 0; --i) {int index = (arr[i] / exp) % 10;output[count[index] - 1] = arr[i];count[index]--;}// 将排序结果复制回原数组for (int i = 0; i < n; ++i) {arr[i] = output[i];}
}std::vector<int> radix_sort(std::vector<int> arr) {if (arr.empty()) {return arr;}// 找出最大元素int max_num = *std::max_element(arr.begin(), arr.end());// 确定最大位数for (int exp = 1; max_num / exp > 0; exp *= 10) {counting_sort_for_radix(arr, exp);}return arr;
}
复杂度分析
- 时间复杂度: O ( d ( n + k ) ) O(d(n + k)) O(d(n+k)),其中
n是数组的长度,k是基数(通常为 10),d是最大元素的位数。 - 空间复杂度: O ( n + k ) O(n + k) O(n+k),主要用于计数数组和输出数组。
总结
非比较排序算法在特定场景下具有较高的效率,但它们通常对数据有一定的要求,如数据范围、数据分布等。在实际应用中,需要根据数据的特点选择合适的排序算法。
3. 排序算法复杂度及稳定性分析
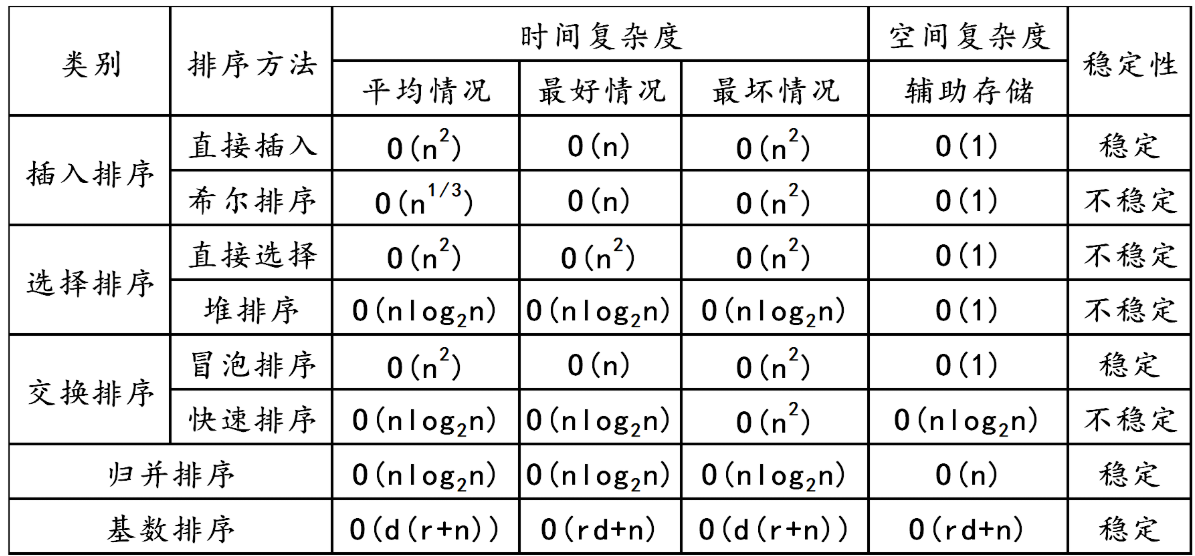
常见排序算法的时间复杂度、空间复杂度及稳定性分析如下:
3.1 比较排序
- 冒泡排序
- 时间复杂度:
- 最好情况为 O ( n ) O(n) O(n),当数组已经有序时,只需进行一次遍历,比较 n − 1 n - 1 n−1 次,无需交换元素。
- 最坏情况为 O ( n 2 ) O(n^2) O(n2),当数组逆序时,需要进行 n − 1 n - 1 n−1 趟排序,第 i i i 趟需要比较 n − i n - i n−i 次,总共比较次数为 ∑ i = 1 n − 1 ( n − i ) = n ( n − 1 ) 2 \sum_{i = 1}^{n - 1}(n - i)=\frac{n(n - 1)}{2} ∑i=1n−1(n−i)=2n(n−1),交换次数也为 O ( n 2 ) O(n^2) O(n2)。
- 平均时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( 1 ) O(1) O(1),因为只需常数级别的额外空间来进行元素交换。
- 稳定性:稳定。在比较相邻元素时,如果相等则不交换,相同元素的相对顺序不会改变。
- 时间复杂度:
- 插入排序
- 时间复杂度:
- 最好情况为 O ( n ) O(n) O(n),数组有序时,每次插入都只需比较一次,无需移动元素。
- 最坏情况为 O ( n 2 ) O(n^2) O(n2),数组逆序时,第 i i i 个元素插入时需要比较 i i i 次,移动 i i i 个位置,总共比较和移动次数都为 ∑ i = 1 n − 1 i = n ( n − 1 ) 2 \sum_{i = 1}^{n - 1}i=\frac{n(n - 1)}{2} ∑i=1n−1i=2n(n−1)。
- 平均时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 空间复杂度: O ( 1 ) O(1) O(1),仅需要常数级别的额外空间。
- 稳定性:稳定。在插入元素时,会将相同元素保持原来的相对顺序。
- 时间复杂度:
- 选择排序
- 时间复杂度:
- 无论最好、最坏还是平均情况,时间复杂度都是 O ( n 2 ) O(n^2) O(n2)。因为每一趟都需要遍历未排序部分找到最小(或最大)元素,总共需要 n − 1 n - 1 n−1 趟,比较次数为 ∑ i = 1 n − 1 ( n − i ) = n ( n − 1 ) 2 \sum_{i = 1}^{n - 1}(n - i)=\frac{n(n - 1)}{2} ∑i=1n−1(n−i)=2n(n−1),交换次数为 n − 1 n - 1 n−1 次。
- 空间复杂度: O ( 1 ) O(1) O(1),只需常数级别的额外空间用于交换元素。
- 稳定性:不稳定。例如序列
5,8,5,2,9,选择最小元素2与第一个5交换后,两个5的相对顺序发生了改变。
- 时间复杂度:
- 归并排序
- 时间复杂度:
- 无论最好、最坏还是平均情况,时间复杂度都是 O ( n l o g n ) O(nlogn) O(nlogn)。归并排序将数组不断分成两半,直到每个子数组只有一个元素,然后再将子数组合并,合并操作的时间复杂度为 O ( n ) O(n) O(n),而划分的层数为 l o g n logn logn,所以总的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
- 空间复杂度: O ( n ) O(n) O(n),需要额外的 O ( n ) O(n) O(n) 空间来存储临时数组用于合并操作。
- 稳定性:稳定。在合并过程中,如果两个子数组中有相同的元素,会先将前面子数组中的元素放入临时数组,保证相同元素的相对顺序不变。
- 时间复杂度:
- 快速排序
- 时间复杂度:
- 最好情况为 O ( n l o g n ) O(nlogn) O(nlogn),每次划分都能将数组均匀分成两部分,划分次数为 l o g n logn logn,每次划分需要 O ( n ) O(n) O(n) 的时间,所以时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
- 最坏情况为 O ( n 2 ) O(n^2) O(n2),当数组已经有序或逆序时,每次划分只能将数组分成一个元素和 n − 1 n - 1 n−1 个元素的两部分,需要进行 n − 1 n - 1 n−1 次划分,每次划分需要 O ( n ) O(n) O(n) 的时间,所以时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
- 平均时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
- 空间复杂度:
- 最好情况为 O ( l o g n ) O(logn) O(logn),因为只需 O ( l o g n ) O(logn) O(logn) 的栈空间来存储递归调用的信息。
- 最坏情况为 O ( n ) O(n) O(n),当出现最坏的划分情况时,递归深度达到 n n n。
- 稳定性:不稳定。例如序列
5,8,5,2,9,以第一个5为枢轴进行划分时,两个5的相对顺序可能会改变。
- 时间复杂度:
- 堆排序
- 时间复杂度:
- 无论最好、最坏还是平均情况,时间复杂度都是 O ( n l o g n ) O(nlogn) O(nlogn)。建堆的时间复杂度为 O ( n ) O(n) O(n),然后进行 n − 1 n - 1 n−1 次调整堆的操作,每次调整堆的时间复杂度为 O ( l o g n ) O(logn) O(logn),所以总的时间复杂度为 O ( n l o g n ) O(nlogn) O(nlogn)。
- 空间复杂度: O ( 1 ) O(1) O(1),只需要常数级别的额外空间。
- 稳定性:不稳定。在调整堆的过程中,相同元素的相对顺序可能会改变。
- 时间复杂度:
3.2 非比较排序
- 计数排序
- 时间复杂度: O ( n + k ) O(n + k) O(n+k),其中 n n n 是数组元素个数, k k k 是数组中元素的取值范围。需要遍历数组两次,第一次统计每个元素出现的次数,第二次根据统计结果将元素放回原数组。
- 空间复杂度: O ( k ) O(k) O(k),需要额外的空间来存储每个元素的出现次数。
- 稳定性:稳定。在将元素放回原数组时,相同元素会按照原来的顺序依次放入。
- 桶排序
- 时间复杂度:
- 平均情况为 O ( n + k ) O(n + k) O(n+k),其中 n n n 是数组元素个数, k k k 是桶的个数。将元素分配到桶中以及对每个桶内的元素进行排序(通常采用简单排序算法)的时间复杂度为 O ( n ) O(n) O(n),而遍历桶的时间复杂度为 O ( k ) O(k) O(k)。
- 最坏情况为 O ( n 2 ) O(n^2) O(n2),当所有元素都分配到同一个桶中时,退化为简单排序算法。
- 空间复杂度: O ( n + k ) O(n + k) O(n+k),需要额外的空间来存储桶和桶内的元素。
- 稳定性:稳定。如果桶内采用稳定的排序算法,那么桶排序就是稳定的。
- 时间复杂度:
- 基数排序
- 时间复杂度: O ( d ( n + k ) ) O(d(n + k)) O(d(n+k)),其中 d d d 是数字的位数, n n n 是数组元素个数, k k k 是基数(通常为 10)。需要对每个位数进行 d d d 次排序,每次排序的时间复杂度为 O ( n + k ) O(n + k) O(n+k)。
- 空间复杂度: O ( n + k ) O(n + k) O(n+k),需要额外的空间来存储桶和临时数组。
- 稳定性:稳定。在按位排序的过程中,相同元素的相对顺序不会改变。
当你看到这里的时候,我相信你对排序已经有了较为明确的认知了,缺的只是如何更好的去应用了,那么咱们C++再见咯…
请大家看我超喜欢拍的一张海边日出!!!
