AGILE:开启LLM Agent强化学习的创新框架
在大语言模型(LLMs)蓬勃发展的今天,基于LLMs构建的智能体成为研究热点。但如何将各组件整合优化仍是难题。本文提出的AGILE框架给出了创新解法,它不仅统一多组件,还让智能体性能超越GPT-4。想知道它是如何做到的吗?快来一探究竟!
论文标题
AGILE: A Novel Reinforcement Learning Framework of LLM Agents
来源
arXiv:2405.14751v2 [cs.LG] 5 Nov 2024
https://arxiv.org/abs/2405.14751
文章核心
研究背景
大语言模型(LLMs)展现出强大能力,推动了基于LLMs的智能体(LLM agents)发展,但目前尚不清楚如何将规划、反思、工具使用等组件整合到统一框架并进行端到端优化。
研究问题
- 缺乏统一框架整合和优化LLM智能体的多个组件,如规划、反思、工具使用等,各组件间协同工作机制不明确。
- 现有复杂问答(QA)基准测试无法全面评估智能体结合所有模块和能力的表现,难以反映智能体在实际应用中的综合能力。
- 大语言模型存在幻觉、缺乏长尾知识等问题,在智能体中如何有效利用人类专家知识提升性能,同时平衡准确性和人力成本是挑战。
主要贡献
- 提出新强化学习框架:设计AGILE(AGent that Interacts and Learns from Environments)框架,实现智能体端到端学习。该框架让智能体可主动向人类专家寻求建议,处理复杂问题时能保证准确性,并从人类学习中提升适应新任务的能力。
- 开发新基准数据集:创建ProductQA数据集,包含88,229个问答对,涉及26个QA任务,涵盖多种问题类型,可全面评估智能体处理历史信息、使用工具、与人交互、自我评估和反思等能力。
- 验证框架有效性:在ProductQA、MedMCQA和HotPotQA等多个任务上实验,结果表明基于7B和13B LLMs且经近端策略优化算法(PPO)训练的AGILE智能体性能优于GPT-4智能体。
方法论精要
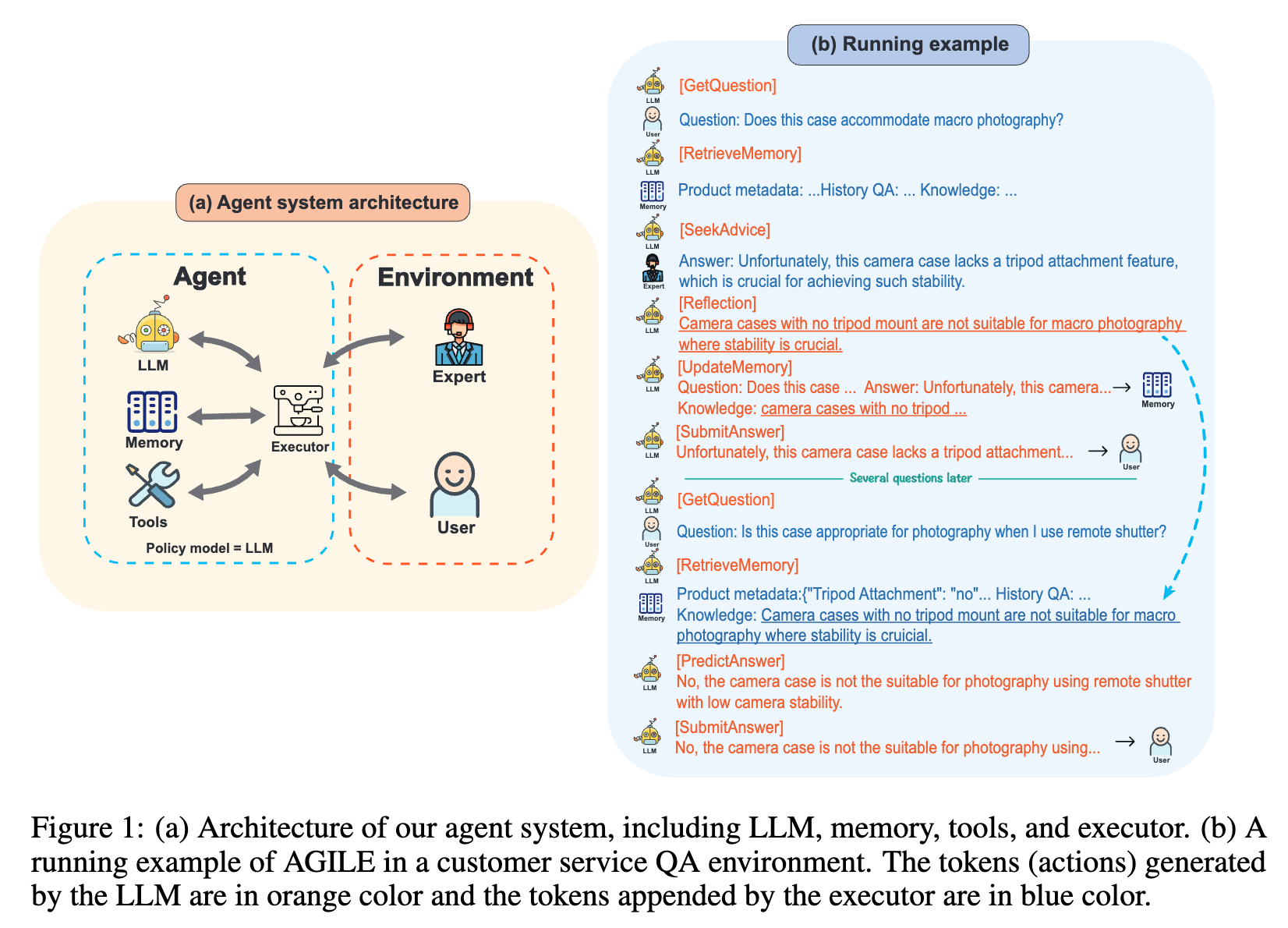
1. 核心算法/框架:AGILE框架由LLM、记忆、工具和执行器四个模块构成。将智能体构建视为强化学习问题,LLM作为策略模型,执行器根据LLM指令实现状态转换,环境给出奖励,通过这种方式实现智能体与环境的交互和学习。
2. 关键参数设计原理:在策略学习中,无论是模仿学习(IL)还是强化学习(RL),都将损失计算限定在动作令牌上,并使用当前LLM上下文$ c_{i} 作为注意力掩码。对于长轨迹问题, ∗ ∗ 通过将轨迹划分为较小片段,并提出会话级优化算法 ∗ ∗ ,引入代理奖励 作为注意力掩码。对于长轨迹问题,**通过将轨迹划分为较小片段,并提出会话级优化算法**,引入代理奖励 作为注意力掩码。对于长轨迹问题,∗∗通过将轨迹划分为较小片段,并提出会话级优化算法∗∗,引入代理奖励 \overline{r}{k}\left(\tau{i}\right) $ ,简化优化过程。

3. 创新性技术组合:结合LLM、记忆、工具和执行器,使智能体具备推理、规划、反思和寻求建议等能力。例如,智能体可利用记忆模块检索历史信息,使用工具模块进行产品搜索等操作,遇到难题时向专家寻求建议并通过反思积累知识。
4. 实验验证方式:在ProductQA、MedMCQA和HotPotQA三个复杂QA任务上评估AGILE智能体。选择GPT-3.5、GPT-4等作为基线模型,对比直接提示模型回答(如gpt3.5-prompt、gpt4-prompt)和在AGILE框架内提示模型回答(如agile-gpt3.5-prompt、agile-gpt4-prompt)的结果。同时,通过调整寻求建议成本、进行消融研究等方式验证框架和各模块的有效性。
实验洞察
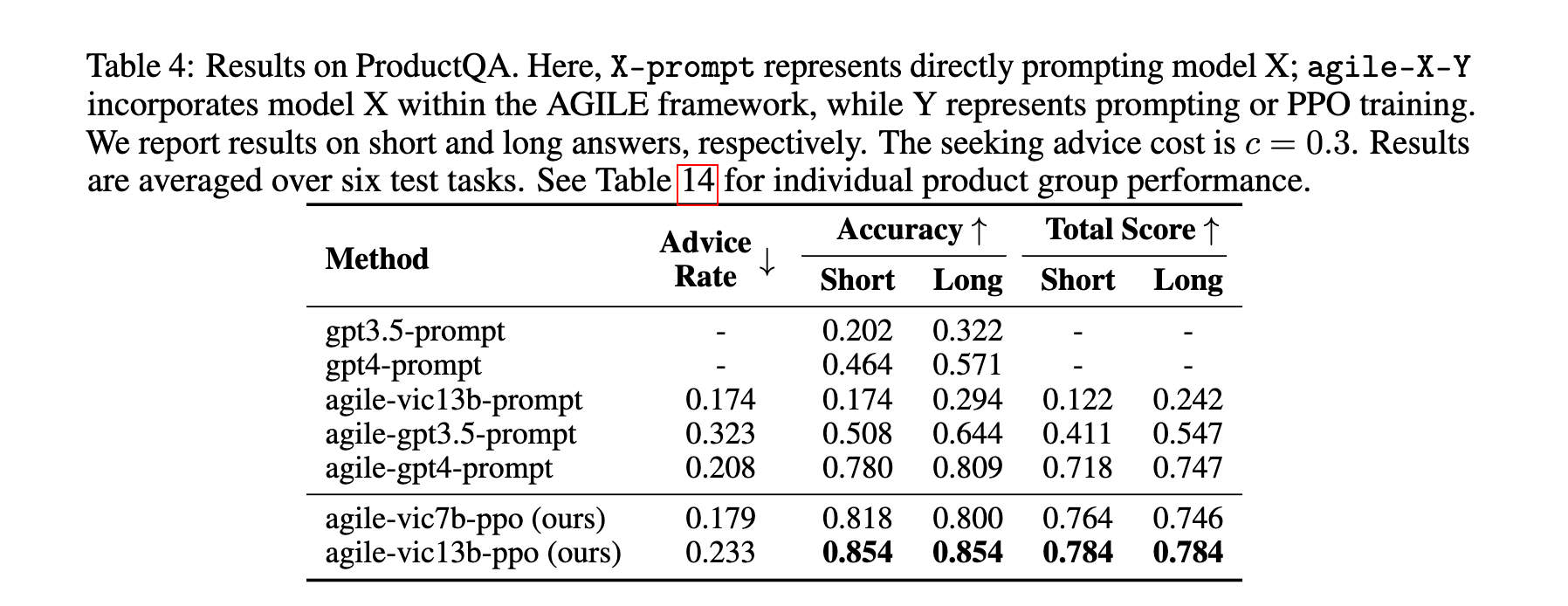
1. 性能优势:在ProductQA数据集上,agile-vic13b-ppo相比agile-gpt4-prompt,短答案平均总得分相对提高9.2%,长答案提高5.0%;在MedMCQA数据集上,agile-mek7b-ppo准确率达到85.2%,相比基线模型Meerkat-7b-prompt提升31.8%,超过当前最优模型gpt4-Medprompt(79.1%);在HotPotQA数据集上,agile-vic13b-ppo准确率为67.5%,相比最强基线ReAct-gpt4-prompt提升40.0%。
2. 消融研究:在ProductQA数据集上的消融实验表明,禁用寻求建议功能导致准确率下降10.7%,总得分降低5.0%;移除工具使用功能使寻求建议频率增加25.9%,总得分降低9.3%;去除记忆或反思能力也会使寻求建议频率上升,总得分下降,验证了各核心模块的重要性。
本文由AI辅助完成。