改进的山地无人机路径规划灰狼优化算法(I-GWO)
针对无人机(UAV)路径规划中灰狼优化收敛速度慢、易陷入局部最优的问题,提出一种多策略融合的改进灰狼优化(I-GWO)。改进算法在初始化阶段增加种群对抗策略,加快第一时段收敛速度,优化控制因子计算,提高算法收敛精度。同时,在位置更新阶段引入柯西分布逆累积分布函数和切线飞行算子,防止算法停滞在局部最优。实验结果表明,I-GWO相比其他算法具有更高的收敛精度和速度。
1、原始的灰狼优化算法
灰狼是一种群居动物,每群约有5-12只狼,具有严格的社会等级制度。头狼(称为α狼),也称为头狼,负责领导整个狼群的狩猎和休息活动。第二等级的狼(称为β狼)协助α狼管理狼群。第三等级的狼(称为δ狼)负责侦查和保护狼群。最低等级的狼(称为ω狼)维护狼群的稳定。同时,ω狼必须遵循高等级狼的命令。α狼、β狼和δ狼是主要的猎手,ω狼是追随者。狼群的狩猎过程分为三个阶段:(1)追逐猎物(2)围捕猎物(3)探索和寻找猎物。
A. 追逐阶段
狼群中的每只狼都是一个可行的解决方案。更新每只狼位置的公式如下:
X ( t + 1 ) = X ( t ) − A ⋅ ∣ C ⋅ X α ( t ) − X ( t ) ∣ X(t + 1) = X(t) - A \cdot |C \cdot X_\alpha(t) - X(t)| X(t+1)=X(t)−A⋅∣C⋅Xα(t)−X(t)∣
其中参数 X p ( t ) X_p(t) Xp(t)是头狼的位置, X ( t ) X(t) X(t)是当前狼的位置, X ( t + 1 ) X(t + 1) X(t+1)是更新后狼的位置。参数 A A A和 C C C用于调节狼的捕食行为,计算公式如下:
A = 2 a ⋅ r 1 − a A = 2a \cdot r_1 - a A=2a⋅r1−a
C = 2 ⋅ r 2 C = 2 \cdot r_2 C=2⋅r2
其中 r 1 r_1 r1和 r 2 r_2 r2是[0, 1]之间的随机数, a a a随着迭代次数的减少而减小,用于描述算法探索阶段向开发阶段的过渡,公式如下:
a = 2 ⋅ ( 1 − t T max ) a = 2 \cdot \left(1 - \frac{t}{T_{\text{max}}}\right) a=2⋅(1−Tmaxt)
B. 围捕阶段
每只狼接近其猎物时,前三只狼的公式如下:
X 1 = X α ( t ) − A ⋅ ∣ C ⋅ X α ( t ) − X ( t ) ∣ X 2 = X β ( t ) − A ⋅ ∣ C ⋅ X β ( t ) − X ( t ) ∣ X 3 = X δ ( t ) − A ⋅ ∣ C ⋅ X δ ( t ) − X ( t ) ∣ X ( t + 1 ) = X 1 + X 2 + X 3 3 \begin{align*} X_1 &= X_\alpha(t) - A \cdot |C \cdot X_\alpha(t) - X(t)| \\ X_2 &= X_\beta(t) - A \cdot |C \cdot X_\beta(t) - X(t)| \\ X_3 &= X_\delta(t) - A \cdot |C \cdot X_\delta(t) - X(t)| \\ X(t + 1) &= \frac{X_1 + X_2 + X_3}{3} \end{align*} X1X2X3X(t+1)=Xα(t)−A⋅∣C⋅Xα(t)−X(t)∣=Xβ(t)−A⋅∣C⋅Xβ(t)−X(t)∣=Xδ(t)−A⋅∣C⋅Xδ(t)−X(t)∣=3X1+X2+X3
其中 X α X_\alpha Xα、 X β X_\beta Xβ、 X δ X_\delta Xδ分别是头狼、β狼和δ狼的位置。
C. 探索和搜索阶段
在整个狼群捕食阶段, A A A控制狼与其猎物之间的距离以及狼的整体行为。 C C C可以被视为自然中障碍物对狼捕食的影响。根据公式(3),可以看出 C C C在[0, 2]之间随机振荡。根据公式(2),已知 A A A的范围在[-2a, 2a]之间。当 ∣ A ∣ < 1 |A| < 1 ∣A∣<1时,狼进入探索阶段,当 ∣ A ∣ > 1 |A| > 1 ∣A∣>1时,狼进入开发阶段。
2. 改进的灰狼优化(I-GWO)
A. 种群对抗策略
在灰狼种群的初始化过程中,假设灰狼种群的大小为 N N N,搜索空间为 D D D,狼在空间中的位置可以表示为:
X i j = b + r × ( a − b ) X_{ij} = b + r \times (a - b) Xij=b+r×(a−b)
其中 i ∈ [ 1 , N ] , j ∈ [ 1 , D ] i \in [1, N], j \in [1, D] i∈[1,N],j∈[1,D],“a”和“b”是变量的上界和下界。 r r r是[0, 1]之间的随机数。整个种群的初始化公式如下:
P = [ X 11 ⋯ X 1 D ⋮ ⋱ ⋮ X N 1 ⋯ X N D ] P = \begin{bmatrix} X_{11} & \cdots & X_{1D} \\ \vdots & \ddots & \vdots \\ X_{N1} & \cdots & X_{ND} \end{bmatrix} P= X11⋮XN1⋯⋱⋯X1D⋮XND
为了提高算法的收敛速度和准确性,在种群的初始化阶段提出了改进的种群对抗策略。该策略通过使用 f 1 ( □ ) f_1(\square) f1(□)和 f 2 ( □ ) f_2(\square) f2(□)生成两个种群 P P P和 P ′ P' P′,并比较每个个体的适应度值,其中适应度函数为 f 1 ( □ ) = f 1 ( X 1 i , X 2 i ⋯ X D i ) f_1(\square) = f_1(X_{1i}, X_{2i} \cdots X_{Di}) f1(□)=f1(X1i,X2i⋯XDi)和 f 2 ( □ ) = f 2 ( X 1 i , X 2 i ⋯ X D i ) f_2(\square) = f_2(X_{1i}, X_{2i} \cdots X_{Di}) f2(□)=f2(X1i,X2i⋯XDi)。最终选择适应度值最高的个体。
X i j = { X i p , f i ( □ ) ≤ f i ( □ ) X i p ′ , f i ( □ ) > f i ( □ ) X_{ij} = \begin{cases} X_{ip}, & f_i(\square) \leq f_i(\square) \\ X_{ip'}, & f_i(\square) > f_i(\square) \end{cases} Xij={Xip,Xip′,fi(□)≤fi(□)fi(□)>fi(□)
其中 X i p X_{ip} Xip是 X 1 i X_{1i} X1i到 X D i X_{Di} XDi中选择的位置, X i p ′ X_{ip'} Xip′是 Y 1 i Y_{1i} Y1i到 Y D i Y_{Di} YDi中选择的位置。该算法通过引入改进的种群对抗策略,具有更快的收敛速度和更高的准确性。
改进的种群对抗策略的流程图如图1所示。
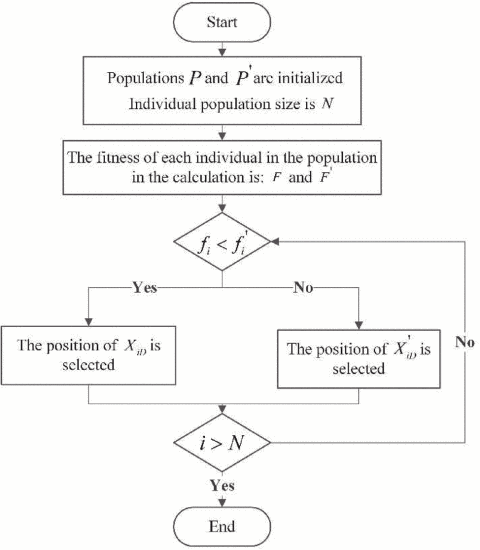
图1. 种群对抗策略流程图
B. 余弦策略
在GWO算法中,收敛因子 A A A控制算法的全局搜索能力和局部探索能力。当 ∣ A ∣ > 1 |A| > 1 ∣A∣>1时,狼远离猎物,算法执行全局探索。当 ∣ A ∣ < 1 |A| < 1 ∣A∣<1时,狼攻击猎物,算法执行局部探索。
公式(4)中控制因子 a a a的值控制着算法收敛的速度和准确性(选择远离还是攻击当前猎物),其值应与算法的搜索过程(通过迭代选择远离还是攻击当前猎物)紧密相关。为了提高算法的搜索性能,搜索范围在早期阶段应尽可能大,以增加找到全局最优解的可能性,后期阶段的搜索范围应尽可能小,以加快收敛速度。因此,引入余弦函数以更好地满足计算需求。计算公式如下:
a = 1 + cos ( π ⋅ t T max ) a = 1 + \cos\left(\pi \cdot \frac{t}{T_{\text{max}}}\right) a=1+cos(π⋅Tmaxt)
上述改进的参数 a a a在早期阶段变化较小,在后期阶段快速收敛(见图2)。收敛因子 a a a的值在早期阶段较大,有利于扩大搜索空间,避免算法陷入局部最优。后期阶段的快速减小提高了算法的局部开发能力,有利于提高收敛速度和准确性。
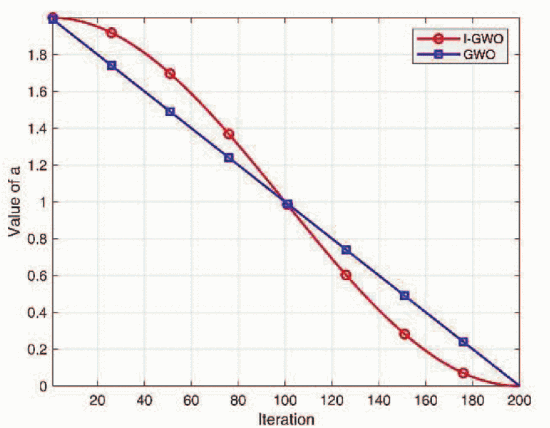
图2. 收敛因子
C. 柯西分布逆累积分布函数
柯西分布逆累积分布函数是柯西分布函数的反函数,公式如下:
F − 1 ( p , x 0 , γ ) = x 0 + γ tan ( π ⋅ ( p − 1 2 ) ) F^{-1}(p, x_0, \gamma) = x_0 + \gamma \tan\left(\pi \cdot \left(p - \frac{1}{2}\right)\right) F−1(p,x0,γ)=x0+γtan(π⋅(p−21))
柯西分布逆累积分布函数具有以下性质:
- 没有数学期望和方差。2. 当 x 0 x_0 x0给定时,函数值主要分布在 x 0 x_0 x0周围。3. 存在偏离 x 0 x_0 x0的小概率。
在狼群中的每个个体根据公式(8)完成位置更新后,狼群中每个个体的位置根据柯西分布逆累积分布函数再次更新和重新分配。总体而言,狼群中的个体仍然分布在其原始位置附近,但有可能有一两只狼会脱离狼群并扩大搜索范围以寻找其他猎物。
因此,公式(13)中的 x 0 x_0 x0应设为1。然后改进的位置更新公式如下:
X i j new = X i j ⋅ F i − 1 ( p , 1 , γ ) X_{ij}^{\text{new}} = X_{ij} \cdot F_i^{-1}(p, 1, \gamma) Xijnew=Xij⋅Fi−1(p,1,γ)
在狼群再次根据函数更新其位置后,靠近原值的灰狼可以提高算法的局部开发能力。同时,远离狼群的灰狼可以提高算法的全局搜索能力。与原始GWO相比,改进算法增加了对原始位置的小局部搜索。这种局部搜索策略可以降低算法陷入局部最优的概率,同时提高算法的局部开发能力。
D. 切线飞行策略
近年来,飞行类策略被广泛应用于改进优化算法。例如,Lévy飞行基于Lévy飞行函数,应用于 cuckoo 优化算法[24]。螺旋飞行源自鲸鱼优化算法,具有更好的空间搜索能力[22]。它们基本上符合公式(15)中的位置更新公式:
X ( t + 1 ) = X ( t ) + s t e p ⋅ d X(t + 1) = X(t) + step \cdot d X(t+1)=X(t)+step⋅d
其中“step”是移动的步长,“d”是移动的方向。不同的飞行游走策略具有不同的步长公式和方向确定策略。为了解决飞行游走策略中随机步长和方向过度随机的问题,提出了切线飞行策略。切线飞行策略来自切线搜索算法[23],公式如下:
X ( t + 1 ) = X ( t ) + s t e p ⋅ tan ( θ ) X(t + 1) = X(t) + step \cdot \tan(\theta) X(t+1)=X(t)+step⋅tan(θ)
其中 c c c是[0, 1]之间的随机数。参数 θ \theta θ控制更新值的方向。当 θ \theta θ接近 π / 2 \pi/2 π/2时,切线值较大,更新值远离原值,有利于空间搜索和跳出局部最优。当 θ \theta θ的值进一步远离 π / 2 \pi/2 π/2时,切线值较小,有利于局部开发并加速算法收敛速度。参数“step”如下:
s t e p = 10 ⋅ k ⋅ t ln ( 20 + 1 ) k = ± 1 t = a − b \begin{align*} step &= \frac{10 \cdot k \cdot t}{\ln(20 + 1)} \\ k &= \pm 1 \\ t &= a - b \end{align*} stepkt=ln(20+1)10⋅k⋅t=±1=a−b
其中 t t t是向量或矩阵 a a a和 b b b的欧几里得范数。在算法的数学建模中, a a a是狼的位置, b b b是ω狼的位置。该策略弥补了原始GWO在位置更新后无法应对陷入局部最优的缺陷。与原始GWO相比,通过控制 X ( t ) X(t) X(t)移动的步长和方向,提高了算法跳出局部最优的收敛精度。
E. 改进的灰狼优化伪代码
改进的灰狼优化(I-GWO)的伪代码由表1给出。
表1. I-GWO的伪代码

UAV路径规划
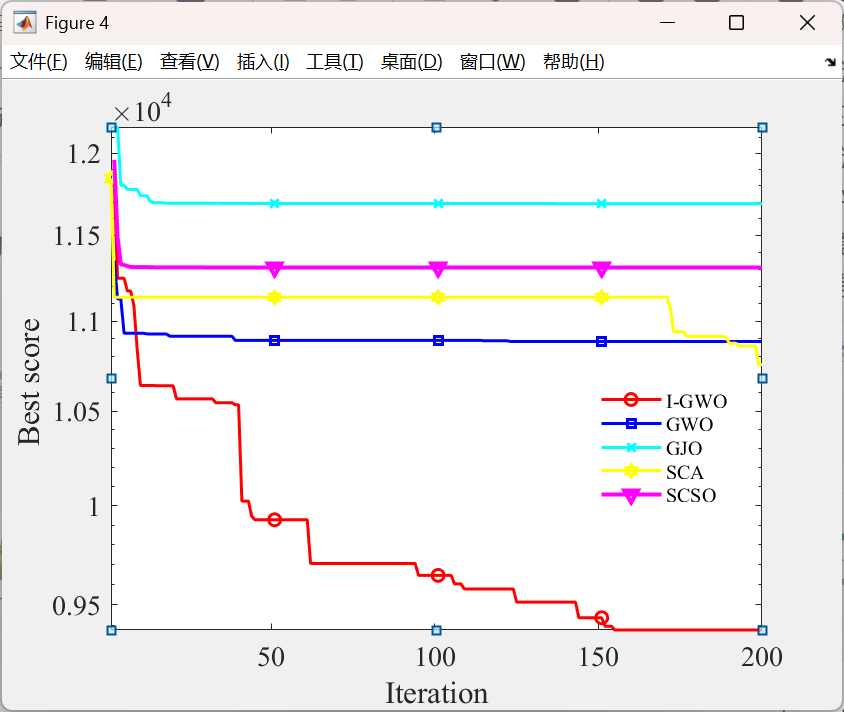
为了验证I-GWO求解UA V路径规划问题的性能,在以英特尔酷睿i5-1340P为GPU、Windows 11为操作系统的计算机上用Matlab2022b进行了UA V仿真实验,在所有实验中最大迭代次数和维数相同,在所有实验中最大迭代次数Tmax=200和维数dim=10相同,实验结果还与GWO、GJO、正弦余弦算法(SCA)和沙猫群优化(SCSO)进行了比较。为了尽可能精确地模拟现实情景,本实验在模拟真实山体环境的基础上构建不同半径、高度、位置的障碍物,每次实验共构建两个山体模型,根据障碍物数量的差异,山体模型的具体信息见表II。
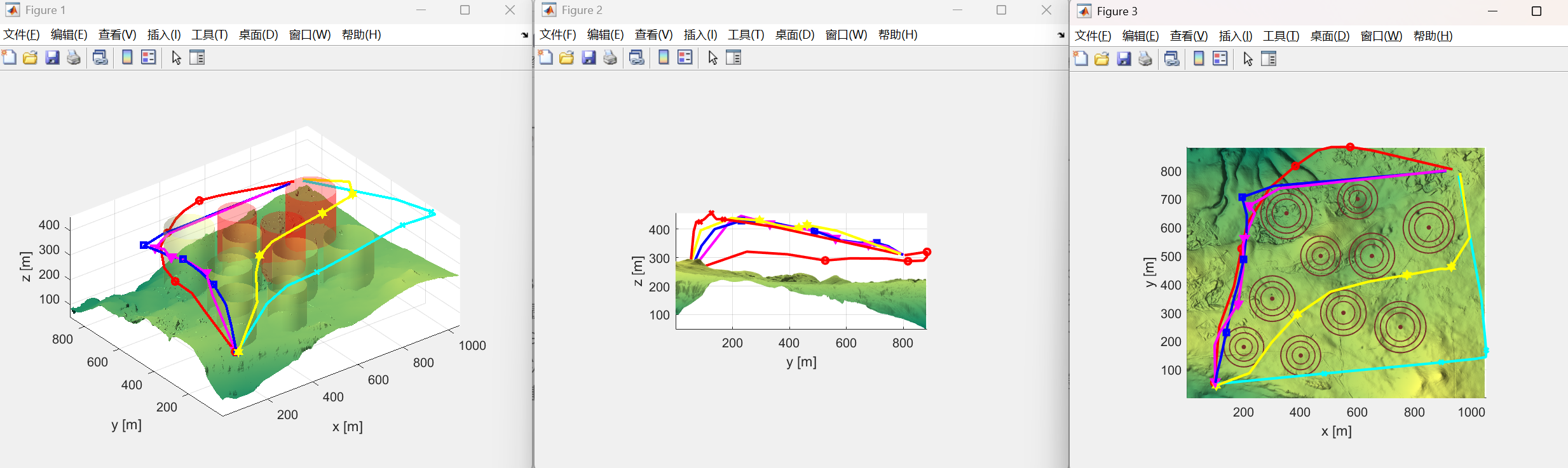
表二.山区信息