阿里Qwen3 8款模型全面开源,免费商用,成本仅为 DeepSeek-R1 的三分之一
想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
想快速掌握自动编程技术吗?叶老师专业培训来啦!这里用Cline把自然语言变代码,再靠DeepSeek生成逻辑严谨、注释清晰的优质代码。叶梓老师视频号上直播分享《用deepseek实现自动编程》限时回放。
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
2025年4月29日,阿里巴巴集团旗下的阿里云发布了通义千问系列第三代模型Qwen3,并宣布全面开源其8款不同规模的大语言模型。这一举措不仅标志着中国企业在全球AI开源生态中的技术领先地位,更通过多样化的模型架构、混合推理机制和多语言支持,重新定义了开源大模型的性能边界与商业应用可能性。
Qwen3系列模型的技术架构与性能突破
1. 混合架构:MoE与Dense模型的协同创新
Qwen3系列包含2款混合专家(Mixture of Experts, MoE)模型和6款稠密(Dense)模型,覆盖从0.6B到235B的参数规模,形成全场景适配的模型矩阵:
- MoE模型:
- Qwen3-235B-A22B:总参数2350亿,推理时仅激活220亿参数,动态选择专家处理任务,实现高精度与低成本的平衡。
- Qwen3-30B-A3B:总参数300亿,激活参数30亿,效率较前代提升10倍,性能超越Qwen2.5-32B。
- Dense模型:
包含Qwen3-32B、14B、8B、4B、1.7B、0.6B,其中Qwen3-32B以一半参数超越Qwen2.5-72B的性能。
2. 混合推理机制:快思考与慢思考的无缝切换
Qwen3首创“混合推理模型”,在同一模型中集成两种模式:
- 快思考模式(非推理) :适用于简单问题,以低算力快速响应(如问答、短文本生成),显存占用仅为同类模型的1/3。
- 慢思考模式(深度推理) :对复杂任务(数学证明、代码生成)进行多步骤分析,通过四阶段后训练优化,支持高达256K上下文窗口。
用户可通过“思考预算”功能动态控制推理深度,在效果与成本间灵活权衡。
3. 性能指标:全面超越行业标杆
在多项基准测试中,Qwen3展现出全球开源模型的顶尖水平:
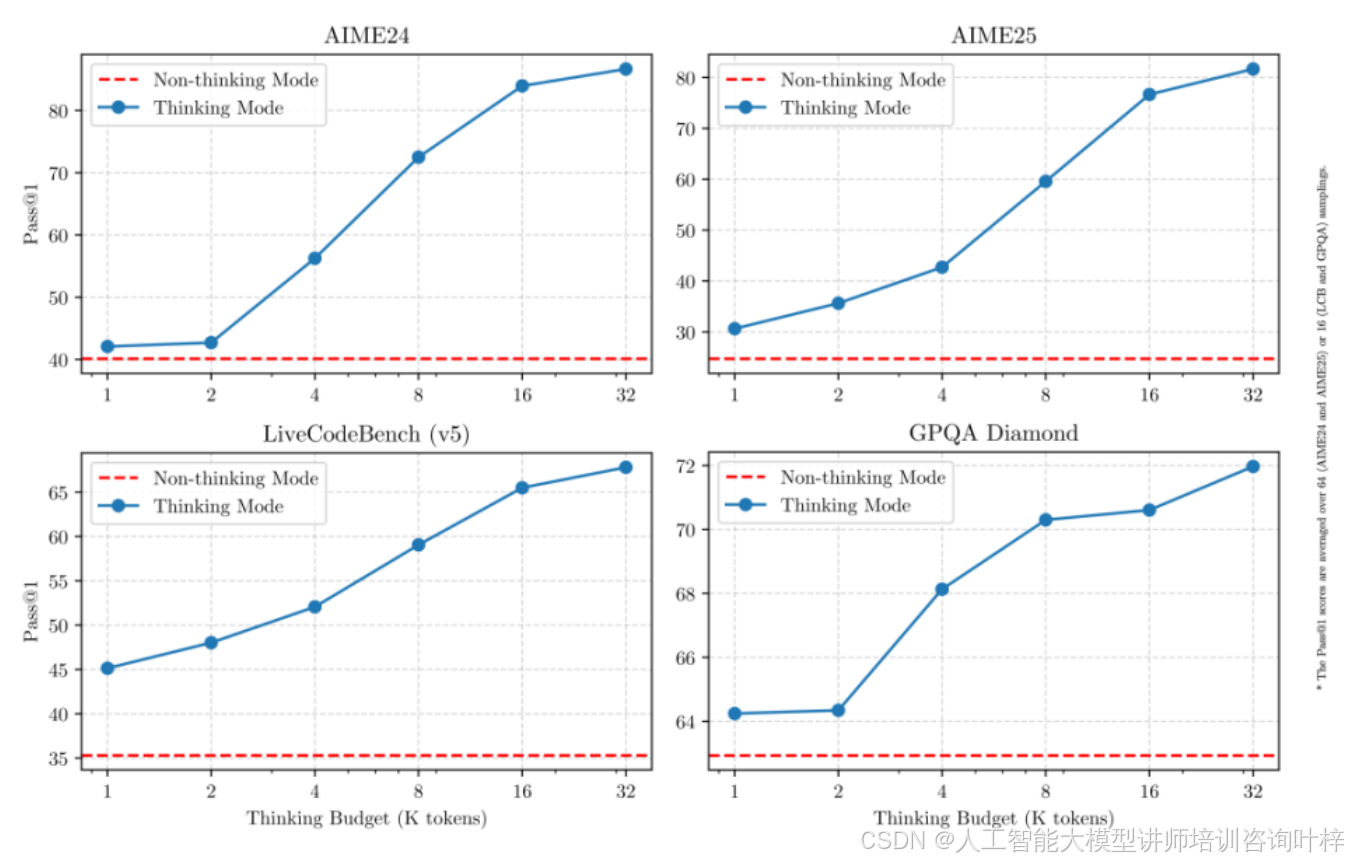
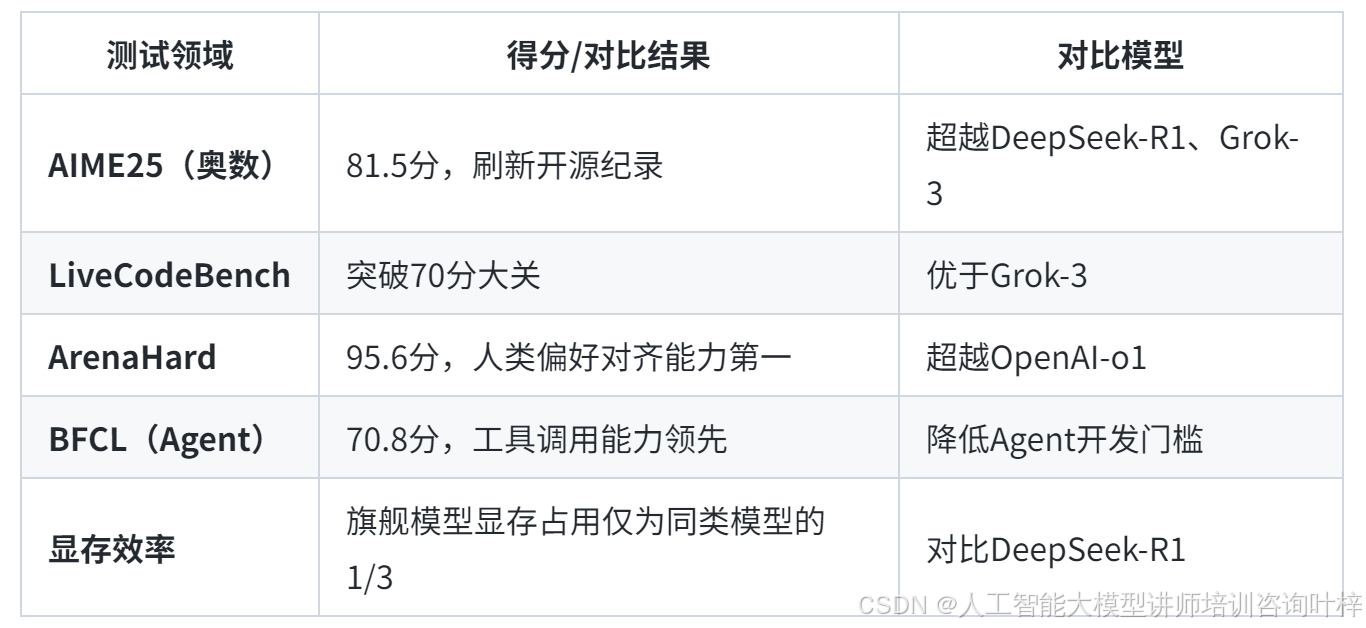
8款开源模型的差异化定位与核心特性
1. 旗舰级MoE模型:Qwen3-235B-A22B
- 参数规模:总参数235B,激活参数22B,支持动态专家选择。
- 应用场景:企业级复杂任务处理(如金融建模、多语言客服系统),支持MCP协议实现与外部工具的深度集成。
- 成本优势:部署成本仅为DeepSeek-R1满血版的25%-35%。
2. 轻量级MoE模型:Qwen3-30B-A3B
- 参数规模:总参数30B,激活参数3B,效率较前代提升10倍。
- 应用场景:边缘计算设备(如智能手机、IoT终端),支持本地化Agent调用。
3. Dense模型矩阵:从0.6B到32B的全覆盖
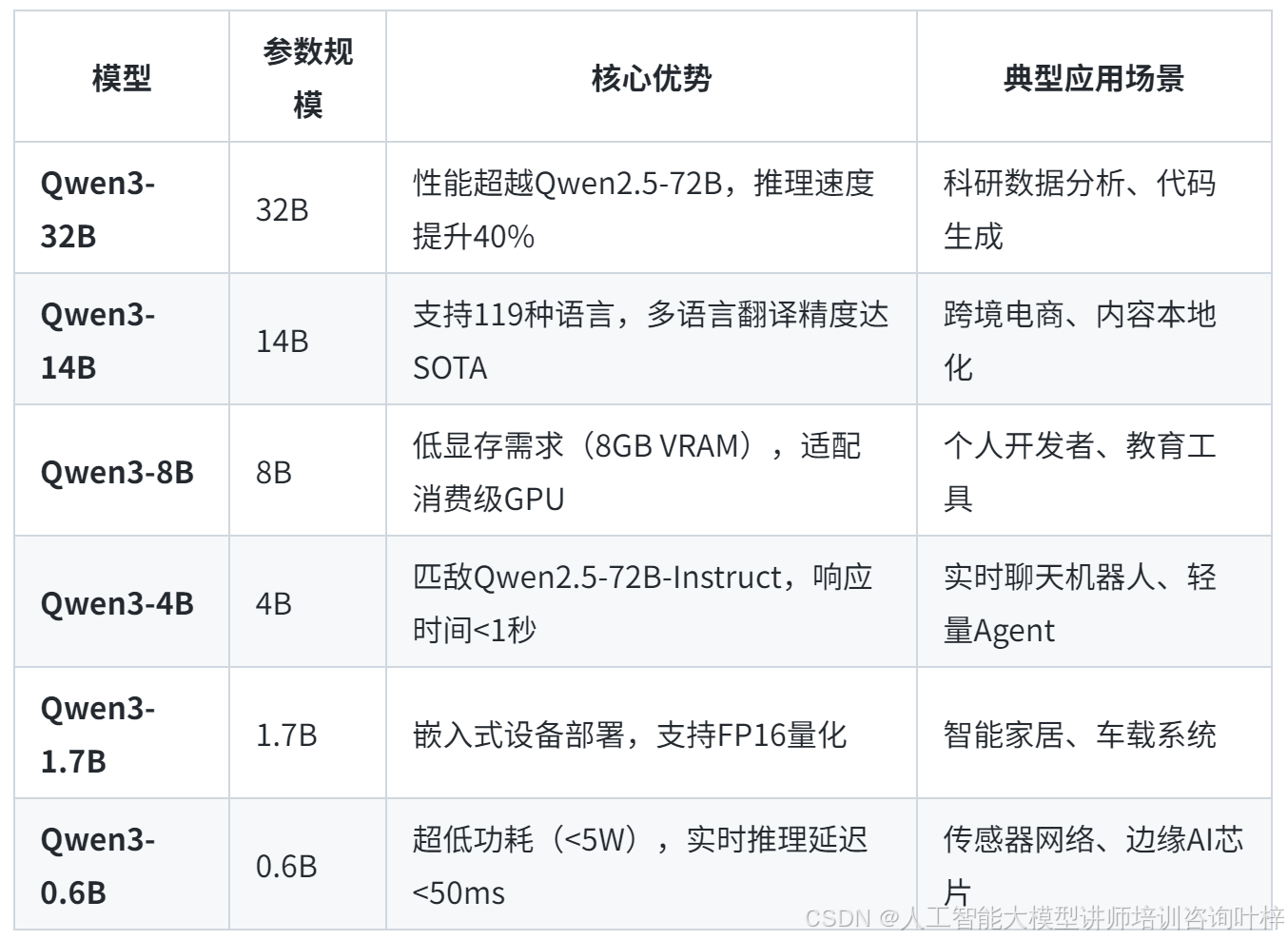
与同类模型的对比分析
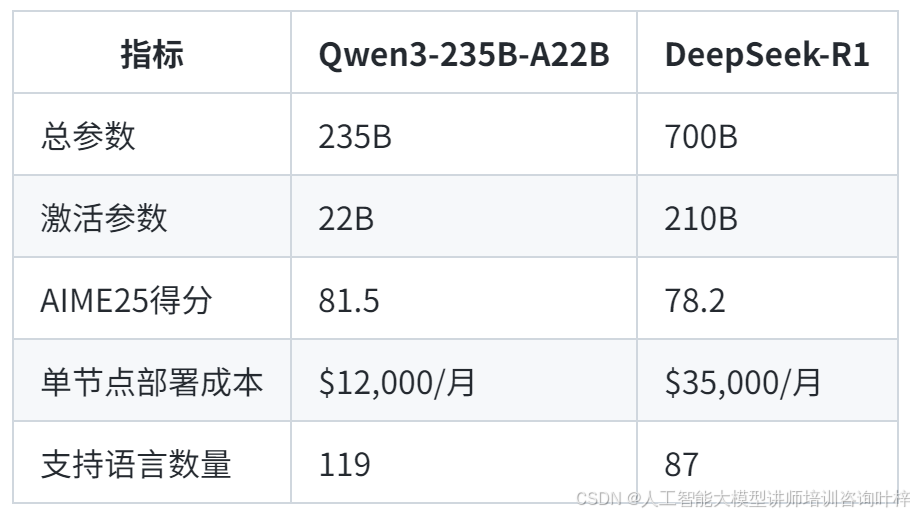
Qwen3以1/3参数量实现性能反超,部署成本降低65%-75%。
Qwen3覆盖119种语言(包括粤语、闽南语等方言),训练数据中非英语占比达42%,远超Grok-3的35%。在低资源语言(如斯瓦希里语)的机器翻译任务中,Qwen3-14B的BLEU得分较Grok-3提升28%。
它采用Apache 2.0许可证,允许免费商用、修改与二次分发,仅需保留版权声明。相比此前Qwen系列的“研究协议”,此举大幅降低企业合规风险,推动模型在医疗、金融等敏感领域的落地。
GitHub:https://qwenlm.github.io/blog/qwen3/
Hugging Face:https://huggingface.co/spaces/Qwen/Qwen3-Demo
ModelScope:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
在线:https://chat.qwen.ai