【东枫电子】AI-RAN:人工智能 - 无线接入网络
太原市东枫电子科技有限公司,翻译
文章目录
- 1.概述
- 1.1 什么是AI-RAN?
- 1.2 为什么是AI-RAN?
- 1.3 AI-RAN有哪些好处?
- 1.4 为什么 AI-RAN 会给通信服务提供商 (CoSP) 带来变革?
- 1.5 AIRAN 的构建模块是什么?
- 2. 参考架构
- 2.1 是否有一个明确的参考架构用于部署 AI-RAN?
- 2.2 什么是 NVIDIA 的 AI-RAN 参考架构 (RA)?它如何保障基础设施投资的未来发展?
- 3. 交换机和网卡
- 3.1 为什么 AI-RAN 使用特定类型的交换机和网卡?
- 3.2 什么是软件定义的前传接口?
- 3.3 AI-for-RAN 的关键网络考虑因素是什么?
- 3.4 AI-and-RAN 的关键网络考虑因素是什么?
- 3.5 AI-on-RAN 的关键网络考虑因素是什么?
- 3.6 如何在单个网卡 (NIC) 上组合前传、中传、回传和 AI 流量?
- 4. C-RAN 和 D-RAN
- 4.1 AI-RAN 可以同时部署在 C-RAN 和 D-RAN 环境中吗?
- 4.2 可以使用单块网卡部署 D-RAN 吗?
1.概述
1.1 什么是AI-RAN?
AI-RAN(人工智能 - 无线接入网络)是一项将人工智能完全集成到无线接入网络硬件和软件中的技术,旨在实现全新的人工智能服务和盈利机会,并在网络利用率、频谱效率和性能方面带来革命性提升。
AI-RAN 的底层基础设施基于完全同构的通用加速计算平台构建,无需任何 RAN 专用硬件组件,因此可以同时运行蜂窝和人工智能工作负载,并为每个工作负载提供确定性的性能。它体现了云原生原则,例如按需扩展、多租户以及两种工作负载的容器化。
AI-RAN 的软件完全基于软件定义和人工智能原生原则构建,以实现人工智能和 RAN 工作负载的容器化和加速,确保充分利用底层加速计算基础设施的优势。
凭借这种加速且统一的软硬件基础,AI-RAN 能够在共享、分布式和加速的云基础设施上部署 5G/6G RAN 和人工智能工作负载。它将 RAN 基础设施从单一用途转变为多用途云基础设施。
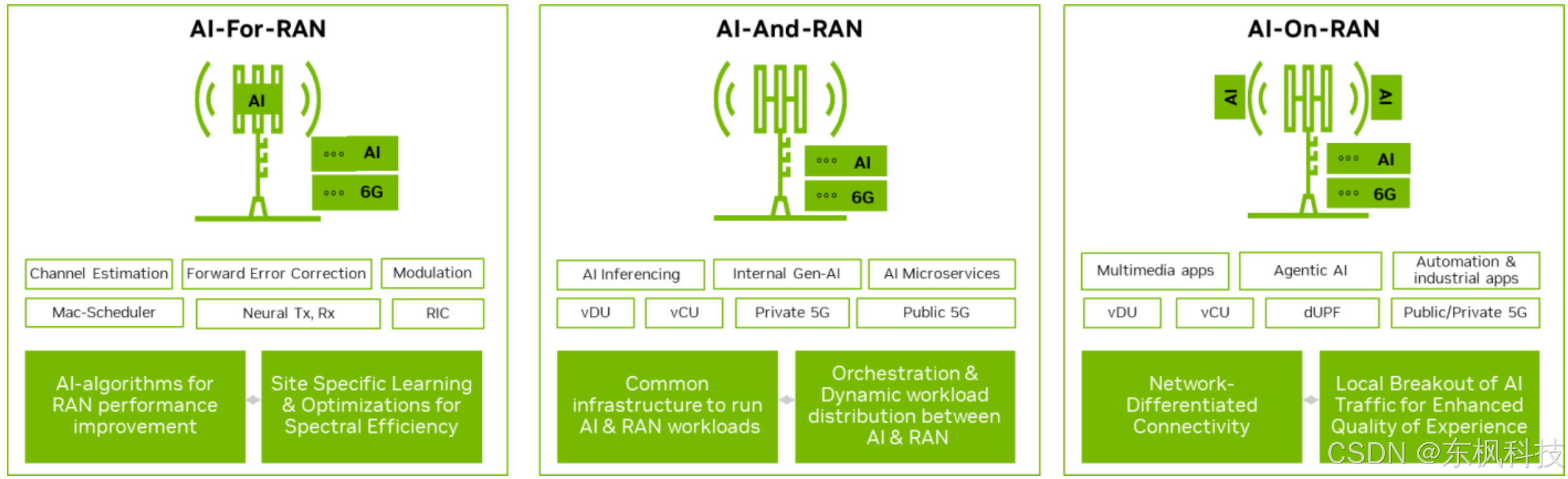
正如 AI-RAN 联盟(一个由电信公司和学术界组成的社区,其使命是推动 AI-RAN 的创新和应用)所概述的,将 AI 集成到 RAN 中有三个具体领域。
- AI 和 RAN(也称为 AI with RAN):使用通用的共享基础设施来运行 AI 和工作负载,目标是最大限度地提高利用率,降低总拥有成本 (TCO),并创造新的 AI 驱动的收入机会。
- AI for RAN:通过将 AI/ML 模型、算法和神经网络嵌入到无线信号处理层,提升 RAN 功能,从而提高频谱效率、无线覆盖范围、容量和性能。
- AI on RAN:在网络边缘启用 RAN 上的 AI 服务,以提高运营效率并为移动用户提供新的服务。这将使 RAN 从成本中心转变为收入来源。
AI-RAN 通过利用完全软件定义的通用平台架构,实现 Open-RAN 的目标,该架构支持开放接口,为 RAN 提供灵活性、互操作性和成本效益。
1.2 为什么是AI-RAN?
AI-RAN 为电信行业将 AI 技术的快速发展融入蜂窝电信发展路线图奠定了技术基础。
AI 和生成式 AI 应用的激增对蜂窝网络提出了更高的要求,推动了对边缘 AI 推理的需求,并需要新的方法来处理这些工作负载。
与此同时,基于 AI 的无线电信号处理技术的进步与传统技术相比,正在展现出令人瞩目的成果,并有望在无线电效率和性能方面实现变革性提升。
随着行业开启 6G 之旅,与基于专用硬件(无论是定制专用集成电路 (ASIC) 还是带有嵌入式加速器的片上系统 (SoC))的传统 RAN 系统相比,基于通用商用现货 (COTS) 服务器和软件定义加速构建的 AI-RAN 能够提供更强大的功能,高效处理日益增长的 AI 和非 AI 流量。
AI-RAN 通过托管 AI 工作负载创造了新的收入机会,并将 AI 集成到 RAN 的运营中,以优化网络性能、自动化管理任务并增强整体用户体验。
1.3 AI-RAN有哪些好处?
AI-RAN 能够在共享、分布式和加速的云基础设施上部署 5G RAN 和 AI 工作负载,从而解决通信服务提供商 (CoSP) 长期以来面临的两大关键挑战:
- 平均基础设施利用率低,导致投资回报率 (ROI) 较低。
- 纯 RAN 服务的盈利空间有限,因为它被视为一项基础的可访问服务,但流量正在增长,而获取新的频谱或基站来满足不断增长的流量需求成本高昂。
AI-RAN 的核心使命是通过为 CoSP 提供以下关键优势,最大化服务提供商的投资回报率:
- 最大限度地利用其基础设施,从而降低总体拥有成本 (TCO)。
- 通过托管 AI 服务提供新的盈利机会,从而增加收入。
- 使用嵌入到无线电信号处理中的 AI 技术,提高频谱效率、能源效率和性能。
- 确保其基础设施投资面向未来。
1.4 为什么 AI-RAN 会给通信服务提供商 (CoSP) 带来变革?
AI-RAN 对通信服务提供商 (CoSP) 具有变革性意义,因为它:
- 为 RAN 提供最高的小区密度、吞吐量和频谱效率,同时
确保 RAN 工作负载达到运营商级的确定性性能。 - 使通信服务提供商能够动态地将未使用的 RAN 容量分配给 AI 工作负载,
从而通过新的盈利机会提高整体投资回报率。 - 提高满载系统的能效。
- 通过在共享加速硬件平台上采用持续集成/持续交付 (CI/CD) 方法,通过新软件版本部署持续改进(RAN 和 AI),为通信服务提供商的基础设施投资提供面向未来的保障,包括未来软件升级到 6G。
1.5 AIRAN 的构建模块是什么?
AI-RAN 的关键构建模块包括:
- 多用途云原生基础设施 - 支持任何 RAN、任何云原生网络功能 (CNF)、任何基于业务支持系统/运营支持系统 (BSS/OSS) 的内部 AI 工作负载或任何外部 AI 工作负载。
- 使用 COTS 服务器的软件定义架构 - 无固定功能或专用硬件。
- 通用加速 - 可加速多种工作负载。
- 多租户和多工作负载设计;AI 和 RAN 均为一等公民,各自根据需求提供确定性性能。
- 可扩展且可互换的基础设施;相同的服务器可通过软件重新配置优化用于任何工作负载,并且相同的同质基础设施可用于任何部署场景,包括集中式 RAN (C-RAN)、分布式 RAN (D-RAN) 和大规模多输入多输出 (mMIMO) 变体,无需为每个用例定制基础设施。
2. 参考架构
2.1 是否有一个明确的参考架构用于部署 AI-RAN?
AI-RAN 是一个完全软件定义的通用解决方案,其中 AI 和 RAN 工作负载均被视为“一等公民”。任何为该系统设计的硬件平台都应能够独立加速和支持每个工作负载,同时支持 AI-and-RAN、AI-for-RAN 和 AI-on-RAN 功能。
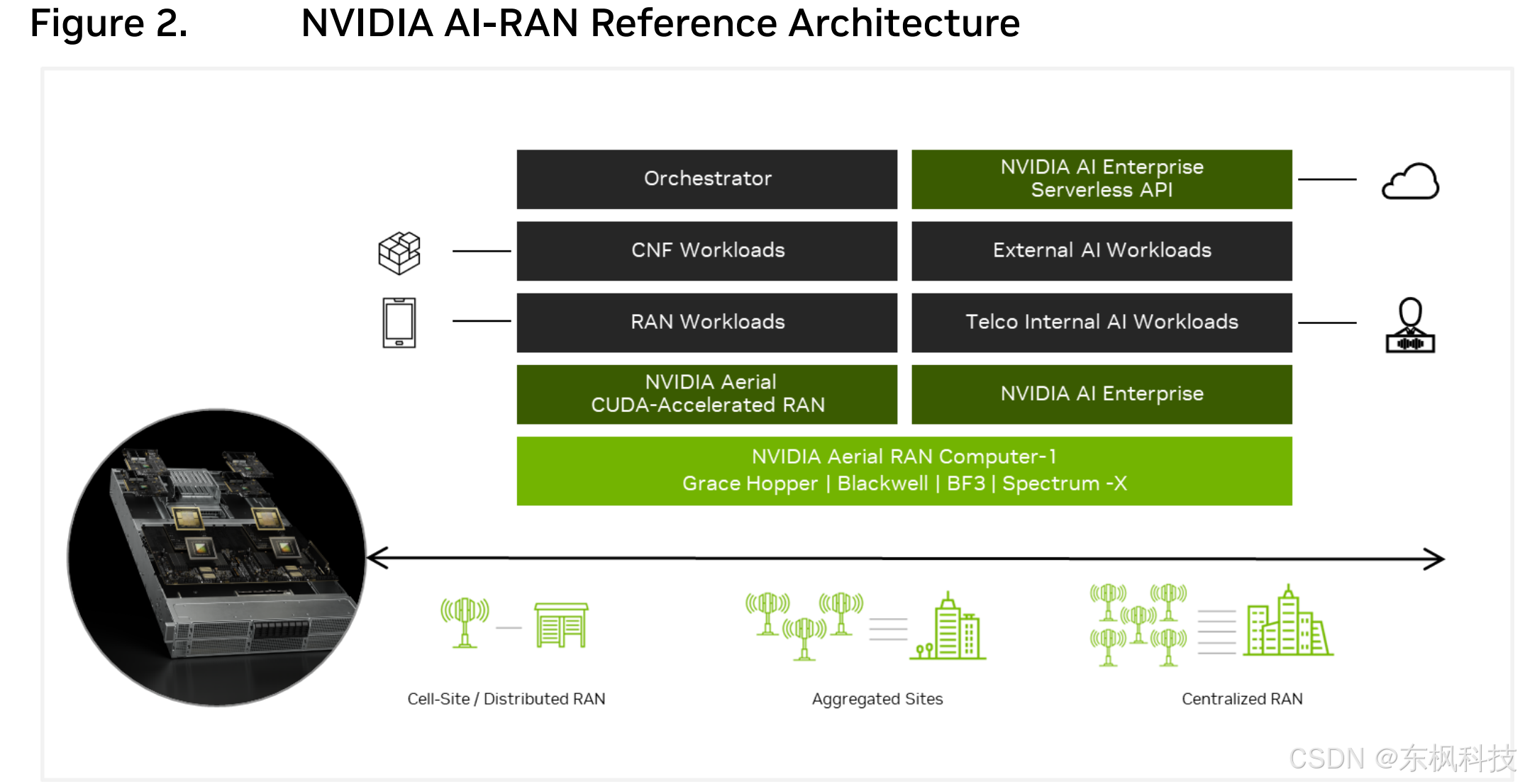
NVIDIA 与合作伙伴携手定义、构建和验证了 NVIDIA 云合作伙伴 (NCP) 电信参考架构 (RA)。该 RA 的目标是创建一个蓝图,以推动通信服务提供商 (COSP) 客户快速部署 AI-RAN。
该 RA 的关键要素包括:
- 标准机架式电信服务器。
- 基于 NVIDIA MGX GH200 的原始设备制造商 (OEM) 服务器平台。
- 符合 Spectrum X 标准的前传聚合交换机和网络接口控制器 (NIC) - Spectrum 交换机和 Bluefield 3 (BF3) 数据处理单元 (DPU) - 支持 RAN 前传的时序要求和优化的 AI 以太网功能。
下文将详细解释此参考架构 (RA)(图 2)的设计。NVIDIA 已构建并验证了此 RA。此外,我们的一些合作伙伴已成功利用 NCP Telco RA 进行 AI-RAN 现场试验。
NVIDIA AI Enterprise 无服务器应用程序编程接口 (API) 是实现通过 AIRAN 基础设施按需处理外部 AI 工作负载的关键组件,该接口可以从其他数据中心获取工作负载。
2.2 什么是 NVIDIA 的 AI-RAN 参考架构 (RA)?它如何保障基础设施投资的未来发展?
基于 NVIDIA MGX GH200 服务器、NVIDIA BF3、CX7/CX8 网卡和 Spectrum-X 交换结构构建的 AI-RAN 完全可编程且可扩展。它能够适应 AI 应用不断发展的格局,并通过在同一硬件上进行软件升级来应对未来 6G 网络的演进。
AI-RAN 参考架构构建于 AI 和 RAN 融合的高性能、可扩展性和模块化基本原则之上。
为了指导 AI-RAN 部署,图 3 [1] 展示了一个解决方案蓝图,该蓝图包含一个标准数据中心机架,其中的 AI-RAN 服务器包含 CPU、GPU、数据处理单元 (DPU)、固态硬盘 (SSD) 和基于以太网交换机的网络结构。
该示意图为通信服务提供商 (CoSP) 部署下一代软件定义和加速的 AI-RAN 数据中心提供了参考架构,从而同时满足 AI 和 RAN 工作负载的计算需求。
云原生加速计算是该参考架构的核心,能够根据运营商分布式数据中心(例如中心局和移动交换局)随时间推移产生的 RAN 流量和 AI 工作负载,快速部署具有不同扩展程度和计算需求的 AI-RAN 系统。
该端到端 AI-RAN 部署蓝图包含关键组件,例如无线单元 (RU)、前传 (FH) 网络、分布式单元 (DU) 以及可选的集中式单元 (CU) 和核心网 (CN),所有这些组件均在 AI-RAN 服务器上运行。
请注意,为简单起见,图 3 描绘了将 RU 连接到单个 AI-RAN 服务器(即多对一映射)的前传网络拓扑,而在实际部署中,RU 和 AI-RAN 服务器之间的连接将是多对多的。
为了在同一基础设施中实现 AI 和 RAN 流量的无缝传输,网络结构被分为两部分:计算结构(RU 和 AI-RAN 服务器之间)和融合结构(AI-RAN 服务器和互联网之间)。
计算结构通过前传在 AI-RAN 服务器之间分配 RAN 工作负载,即东西向 (E-W) 流量。融合结构通过中传/回传(南北向 (NS) 流量)承载往返于 AI-RAN 服务器的 RAN 和 AI 工作负载,并为非来自无线网络的 AI 流量提供到有线网络的连接。
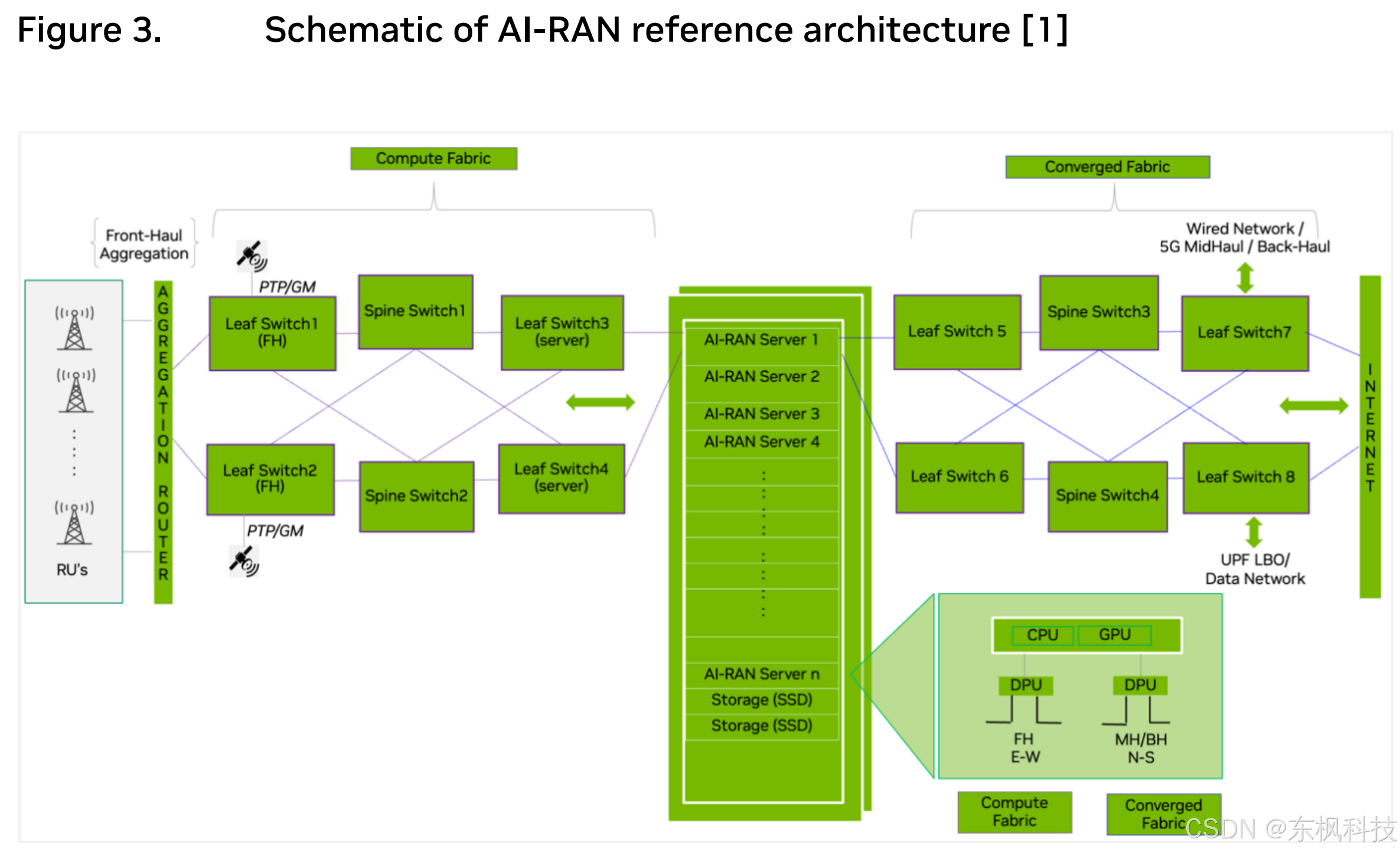
图 3 展示了这两种结构,它们都采用最小的两主干四叶树形拓扑结构,
这种结构在实际部署中可以进一步扩展。在计算结构中,来自 RU 的前传连接在基站/传输聚合路由器中聚合,并通过“主干-叶”网络结构连接到 AI-RAN 服务器。这种双交换层架构通常用于数据中心网络拓扑,以实现可扩展性、冗余性、性能和简化的网络管理。
在典型的主干-叶网状结构中,叶交换机直接连接到网络边缘端点(例如,服务器和其他边缘设备),并在发送到主干层之前聚合来自这些端点的流量;而主干交换机则构成网络结构的核心,在叶交换机之间路由流量。计算结构包含两种类型的叶交换机,即前传叶对交换机,用作 RU 的接入点(叶交换机 1-2 和服务器叶对交换机 3-4),将主干层连接到边缘 AI-RAN 服务器。
每个前传叶交换机通过精确时间协议大师 (PTP/GM) 分发时间,PTP/GM 是网络计算结构内时间同步的主要来源。利用 PTP 协议,前传叶交换机根据 O-RAN 前传规范,通过低层拆分配置 3 (LLS-C3) 同步拓扑将精确时间信息分发给连接到前传网络的 RU 以及 AIRAN 服务器中的 DU。前传/服务器叶交换机通过主干层互连创建的网状拓扑在计算结构中创建了高度可扩展且冗余的网络架构。
每个 AI-RAN 服务器在前端(即朝向前传网络)连接到计算结构,而其后端连接到通过主干交换机网状互连的融合网络叶交换机对(即叶交换机 5-8),这些叶交换机对(即主干交换机 3-4)。融合交换矩阵将 AI-RAN 服务器连接到中传、回传或互联网,具体取决于 AI-RAN 服务器是仅承载用户平面 (DU)、DU 和用户单元 (CU) 组合,还是 DU、CU 和核心网络 (CN) 组合。例如,仅承载用户平面 (DU) 的 AI-RAN 服务器可以通过中传连接到用户平面 (CU),而共同承载用户平面 (DU) 和用户单元 (CU) 的 AI-RAN 服务器可以通过回传连接到用户平面功能本地分支 (UPF LBO) 或核心网络 (CN) 中的 UPF。另一方面,在 AI-RAN 服务器上运行的集中式 DU+CU+CN 将通过融合交换矩阵连接到互联网(通过 N6 接口),如图 3 所示。
接下来,放大图 3 中的 AI-RAN 服务器,探索基于这些服务器构建的软件堆栈,以在同一平台上支持 AI 和 RAN 多租户。
图 2 展示了软件堆栈的各个组件。它被设计为云原生,并配备商用级云操作系统(例如 Kubernetes),提供动态资源编排和基础设施管理。云操作系统托管计算平台和应用程序编程接口 (API) 模型,例如计算统一设备架构 (CUDA),以及网络平台和 API 模型,例如数据中心基础设施片上架构 (DOCA),以便在加速计算的帮助下高效运行各种 RAN 和 AI 应用。
对于 RAN 堆栈,DU、CU 和 CN 由支持众多单元和 RAN 应用的服务管理和编排 (SMO) 实体进行编排;而对于 AI 堆栈,各种软件组件在 API 集群代理下协同工作,用于监控和管理 Kubernetes 集群中的 AI 服务器工作负载。对于 AI 堆栈,基本构建模块包括 AI 应用软件框架和 AI 推理微服务(例如 NVIDIA 推理微服务 (NIM) 和 NeMO 框架),以及用于将这些组件与在该平台上原生运行或通过无服务器 API 运行的各种 AI 应用程序(例如文本、语音、视频、图像)连接的行业标准 API。
一个包罗万象的端到端 (E2E) 编排器可同时与 RAN SMO 和 API 集群代理协同工作,以跟踪资源利用率并在同一共享硬件上编排 RAN 工作负载和 AI 推理请求,从而实现多租户,同时满足 RAN 所需的服务质量和体验质量要求。借助 AI-RAN 参考架构和相关软件堆栈,网络运营商可以获得完整的 AI-RAN 部署蓝图,以便在同一基础架构中将 AI 与 RAN 结合,从而满足各种用例场景。
3. 交换机和网卡
3.1 为什么 AI-RAN 使用特定类型的交换机和网卡?
当 AI-RAN 部署在多租户数据中心以同时托管 C-RAN 和 AI 服务时,它会利用 NVIDIA Spectrum-X 技术实现高性能网络结构。

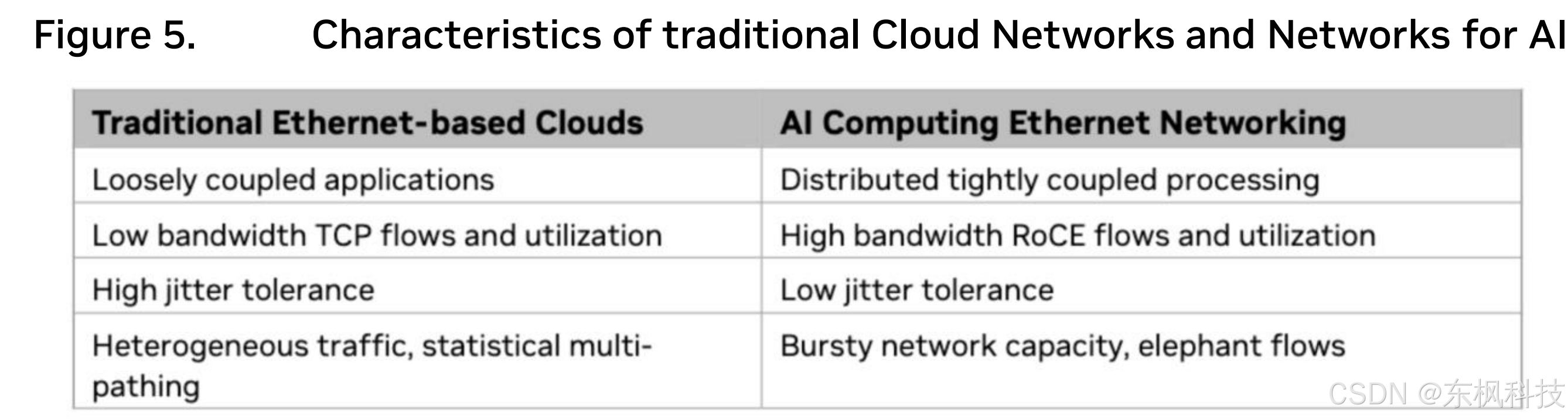
Spectrum-X 网络平台搭载 Spectrum-4 交换机和 BF3 SuperNIC,是全球首个专为人工智能打造的以太网架构,相比传统以太网架构,其生成式人工智能网络性能提升了 1.6 倍。该平台针对人工智能计算进行了优化,而人工智能计算的网络架构与云计算不同。图 5 突出显示了基于以太网的云计算与人工智能计算以太网网络需求之间的差异。
此外,Spectrum Switch 结合 NVIDIA BF3 为 AI-RAN 实现以下功能:
- 具有精确时间协议 (PTP) 的前传网络,用于将 RU 连接到云托管的 DU。
- 软件定义的前传功能,可在同一基础架构上弹性编排 RAN 和 AI 功能。
- 介质访问控制 (MAC) 地址重新映射,确保 DU 的无缝迁移。
- 借助加速 Linux 桥接器和支持 PTP 冗余的增强型 NIC 固件,为 AI 和 RAN 流量提供以太网虚拟专用网 (EVPN) 多宿主和主动-主动冗余。
- 安全卸载和服务功能链。
- 中传网络(面向 CU)和回传网络(面向 5GC)。
- 人工智能以太网(数据中心内的东西向网络流量以及往返互联网的南北向网络流量)——具有低延迟、数据平面加速、拥塞控制等功能,适用于 RAN 和 AI 应用。
- 高效存储网络 - 400Gb/s 融合以太网远程直接内存访问 (RDMA) (RoCE)、RoCE 自适应路由和数据包重新排序。
AI-RAN 涵盖 C-RAN 和 D-RAN 部署。
AI-RAN 作为 D-RAN 部署时可能无法充分利用 Spectrum-X 的全部性能,如上所述。典型的 D-RAN 部署由基站中的一台服务器(或少量服务器)组成,并且通常处于功率和散热受限的环境。
D-RAN 网络需要 PTP 和精确的 FH 流量调度。此外,当平台在 RAN 中的利用率不足时,它可以用于运行一些 AI 功能,通常是 AI 推理功能。
对于 D-RAN,NVIDIA 提供两种网络解决方案:
- BF3 DPU
- ConnectX7 NIC,具体取决于部署的规模和性能考虑。
3.2 什么是软件定义的前传接口?
用于 AI-RAN 部署的网络接口卡 (NIC) 需要能够支持高性能 AI 网络,以及支持 RAN 时序和各种 RAN 配置。这种软件定义的多用途接口可以简化网络管理和软件升级,从而支持 1.1 节中描述的所有三个 AI-RAN 用例。
AI 正日益被集成到所有垂直行业中并得到应用。应用程序正在快速发展以使用 Agentic AI,它具有自主决策、适应和采取行动的能力。它旨在在有限的人工监督下工作,并能够执行复杂的任务。自动驾驶汽车、工业机器人、实时语言翻译、XR 摄像头等应用都需要低延迟和确定性处理来提供高质量的体验。
我们对 AI-RAN 的愿景是通过将 5G RAN 和 AI 堆栈紧密集成在电信边缘数据中心(汇聚站点、移动交换局 (MSO) 和中心局 (CO))中,从而处理通过无线网络传输的 AI 流量。这种新架构利用 5G 分布式用户平面功能 (dUPF),高效地将 AI 流量桥接到 AI 推理堆栈,并采用 NVIDIA 无服务器 API 和 NVIDIA NIM(网络接口模块)——图 6。
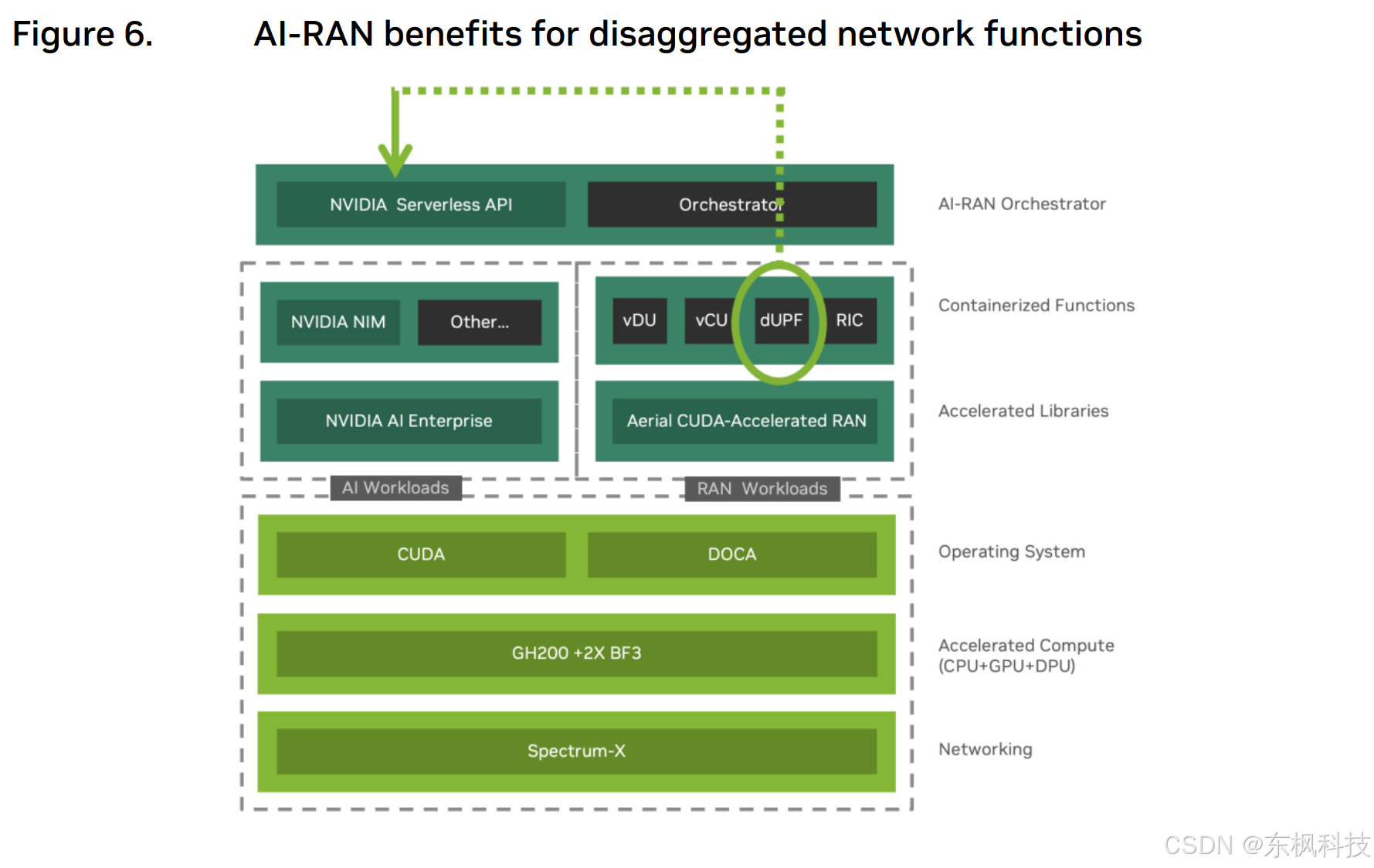
因此,AI-RAN 为电信运营商开启了新的机遇——将其分布式数据中心(MSO、CO 和接入点 (POP))转换为 AI-RAN 数据中心,并通过结合 RAN 和 AI 服务,为融入 AI 的新兴应用提供低延迟和确定性体验,从而创造独特价值。而这些应用在当今的集中式 AI 基础设施中难以实现。
这只能在精心设计的基础设施上实现,该基础设施包含以下组件:MGX GH200 服务器、Spectrum 交换机和 BF3 DPU,以及它们的关键功能如上所述。在接下来的章节中,我们将探讨三种 AI-RAN 用例(即 AI for RAN、AI and RAN 以及 AI on RAN)的关键网络考量因素。
3.3 AI-for-RAN 的关键网络考虑因素是什么?
有很多机会可以利用 AI 来提升 RAN 的频谱效率,例如信道估计/预测、干扰管理、波束成形、基于深度强化学习 (DRL) 的调制和编码方案 (MCS) 选择等等。这些只能通过嵌入式加速硬件和软件计算能力来实现,这些计算能力在第一层是完全可编程的,例如 NVIDIA AI Aerial 平台下用于无线电信号处理的 NVIDIA CUDA 加速库。
如果 L1 处理由固定功能加速器执行,则无法实现下一代 AI 驱动的 L1 优化。例如,用于波束成形或动态频谱共享的 AI 模型需要持续的软件更新和高性能计算能力。集成定制 ASIC 的专用 RAN 加速器无法支持这些新兴的 AI 模型,因为它们是为静态功能设计的,无法适应强化学习等迭代式 AI 更新。
AI-for-RAN 创新正在不断取得诸多进展,其中包括 AI-RAN 联盟在 2025 年世界移动通信大会 (MWC) 上认可的一些最新演示。这些创新的显著公开案例包括:
- 软银携手 NVIDIA 富士通 演示 AI 在 RAN 中的性能提升,
- Deepsig 使用 NVIDIA 平台展示 6G AI 原生空口
- 是德科技、三星和 NVIDIA 使用 NVIDIA 平台推进 AI-For-RAN
这些创新是频谱效率可能实现变革性提升的早期证据。专用 RAN 加速器无法支持这些持续创新,因为这些加速器不具备可编程性,无法集成这些新技术,而且其开发速度也超过了定制硬件的多年周期。
3.4 AI-and-RAN 的关键网络考虑因素是什么?
NVIDIA 的 NCP 电信参考架构基于 MGX GH200 服务器和 BF3 DPU 构建,允许将 5G RAN、dUPF 和 AI 应用程序部署在由 Kubernetes 管理的同一平台上。这带来了巨大的 TCO 优势,因为平台资源(CPU、GPU、DPU/NIC)可以动态分配给 RAN 和 AI 功能,从而提高其利用率并释放新的 AI 盈利能力。NVIDIA 的 Spectrum-X 与 BlueField-3 DPU 相结合,通过以下方式优化 AI-RAN 性能:
- 优先级和服务质量 (QoS):利用 AI 驱动的流量管理,对延迟敏感的 RAN 流量进行优先级排序,并确保高优先级的 AI 工作负载。
- 提高带宽利用率:从 50-60% 提高到 97% 以上,加快推理工作负载的数据传输速度。
- 降低延迟:先进的拥塞控制可最大限度地减少瓶颈,确保实时响应。
- 提高 GPU 利用率:高效的网络管理可最大限度地利用 GPU 执行 AI 和 RAN 任务。这包括软件定义的前传。
- 降低令牌间延迟:Spectrum-X 提供的更高带宽和更优化的存储性能可降低令牌间延迟。
- 加速存储访问:与传统的 RoCE v2 协议相比,Spectrum-X 可将读取带宽提高高达 48%,写入带宽提高高达 41%。这项增强功能可加快对
推理任务至关重要的数据检索和存储操作,尤其适用于检索增强生成 (RAG) 等技术。
专用 RAN 加速器和网卡 (NIC) 缺乏这些关键功能。
3.5 AI-on-RAN 的关键网络考虑因素是什么?
随着企业应用集成越来越多的 AI 功能并越来越多地在移动网络上运行,在分布式电信数据中心高效处理“AI 流量”对于提供最佳质量和用户体验至关重要。在此架构中,dUPF 用于识别 AI 流量并将其桥接到 AI 推理软件(例如 NVIDIA NIM)。
专用 RAN 加速卡不具备高效 dUPF(GTP 隧道封装/解封装、数据包分类、接收端缩放 (RSS) 和 QoS(计量/标记/监管))所需的功能和灵活性。
AI 代理是消费者和企业应用的下一个前沿领域。代理型 AI 工作负载需要对加速计算硬件和软件堆栈进行优化,以最大限度地降低推理任务的计算延迟。
这些 Agentic AI 优化无法通过专用 RAN 加速器和 NIC 实现,因为它们不是为 AI 工作负载构建的。
3.6 如何在单个网卡 (NIC) 上组合前传、中传、回传和 AI 流量?
在单个网卡(例如单个 BF3)上组合前传 (FH)、中传 (MH)、回传 (BH) 和 AI 流量时,需要考虑以下重要因素:
- 系统吞吐量要求 – 单个 BF3 支持两个 200G 吞吐量端口。了解服务器上 FH、MH/BH 和 AI 应用之间将处理多少总流量至关重要。典型的 4T4R 部署通常使用一个 200G 端口用于 FH,另一个 200G 端口用于 MH/BH 和 AI 流量。
- 容错、冗余和服务保障 – 前传的容错和冗余是通信服务提供商 (COSP) 的关键考虑因素。 NVIDIA 的 NCP 电信参考架构 (RA) 采用 EVPN 多宿主技术,配备两个 BF3 网卡,每个 BF3 网卡上都有一个专用于 RAN FH 的端口,以实现强大的容错能力和服务保障。如下图所示,两个网卡上的 FH 端口均配置为 Active/Active 模式,并为 vDU 应用程序提供单一接口。即使其中一个端口发生故障,vDU 应用程序仍可保持与无线电的连接 - 图 6。
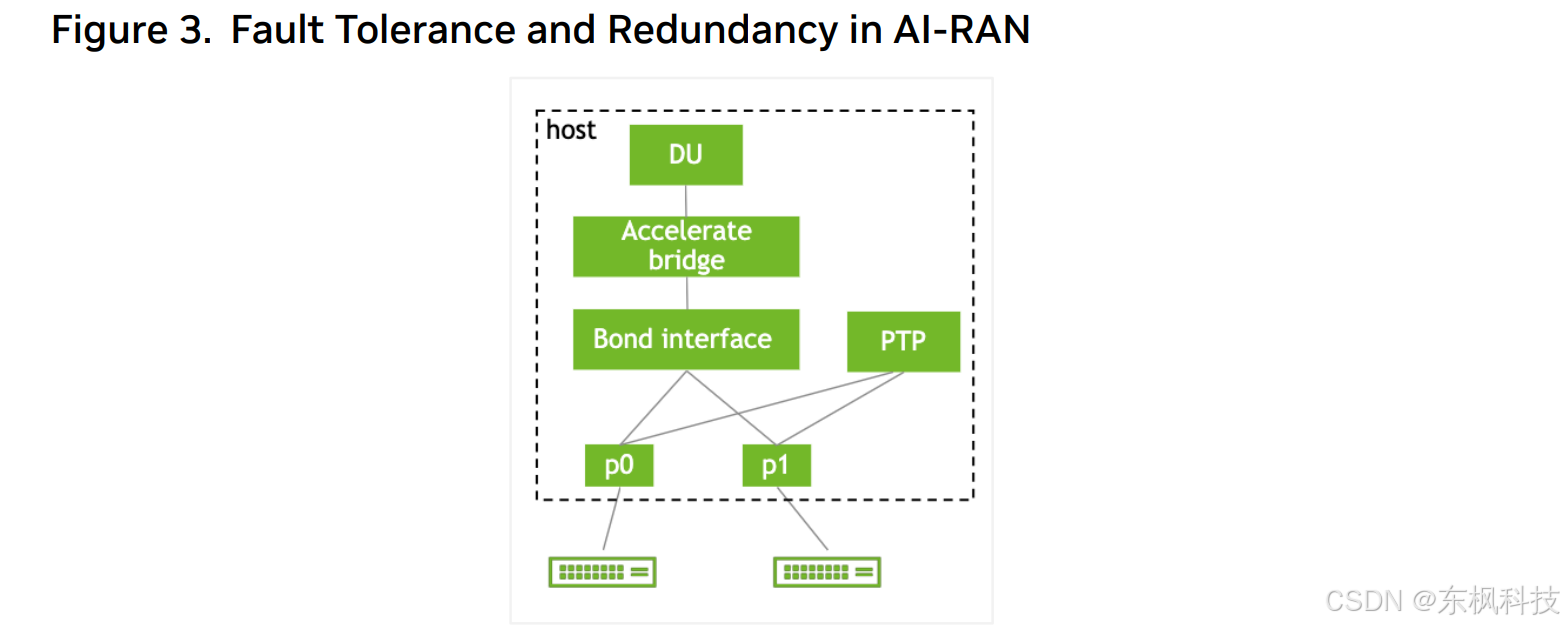
- 由于 FH 需要“精确调度”而导致的网络性能下降——
由于 FH 流量的同步和定时要求,NIC 需要使用一种名为“电信配置文件”的特殊配置。这使得 NIC 能够通过 PTP 定时同步对 FH 流量进行精确调度。当在同一 NIC 上组合 MH/BH 和 AI 流量时,MH/BH 和 AI 流量的性能会略有下降。我们估计性能下降幅度约为 10%。我们相信这种轻微的性能下降不会对整体系统性能造成重大影响。
4. C-RAN 和 D-RAN
4.1 AI-RAN 可以同时部署在 C-RAN 和 D-RAN 环境中吗?
AI-RAN 是一种可扩展的软件架构,涵盖 C-RAN 和 D-RAN 部署。这种可扩展性和软件复用是 AI-RAN 的关键属性和价值主张。
NVIDIA 推荐在托管 C-RAN 的数据中心使用 MGX GH200 和 GB200 服务器。
模块化 MGX 服务器可以支持数据中心内 2KW 到 34KW 或更高功率的服务器机架的供电和制冷能力。未来,许多通信服务提供商 (COSP) 正在积极考虑采用液冷 (LC) 技术的更高密度机架。
对于 D-RAN,NVIDIA 推荐使用 MGX GH200 或 MGX Grace C1 服务器,并配备 PCIe 连接的 GPU 卡(例如 L4 或 L40S),具体取决于 1) RAN 容量和覆盖范围要求以及 2) AI 和边缘计算应用。这确保了 AI-RAN 能够满足 D-RAN 部署中的散热、功耗和成本考虑。
Grace C1 服务器系统可设计为电信短深度服务器,总功耗为 250-300W,可承受高达 55C 的室外温度。
4.2 可以使用单块网卡部署 D-RAN 吗?
D-RAN 部署可以使用单块网卡,例如 NVIDIA BF3 和 CX7,其中一个端口 (200G) 支持前传(FrontHaul,无线网络),另一个端口 (200G) 支持中传/回传和 AI 工作负载。
实际部署需要仔细评估各种因素,例如:小区容量、吞吐量、带宽、AI 和 RAN 工作负载的 QoS、扇出需求、容错能力和冗余要求等。
NVIDIA 已宣布推出下一代 ConnectX8 (CX8) 网卡。CX8 将于 2025 年下半年上市,届时也可用于 C-RAN 和 D-RAN 部署。